 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cooperative Multi-Agent Policies with Partial Reward Decoupling
Dec 23, 2021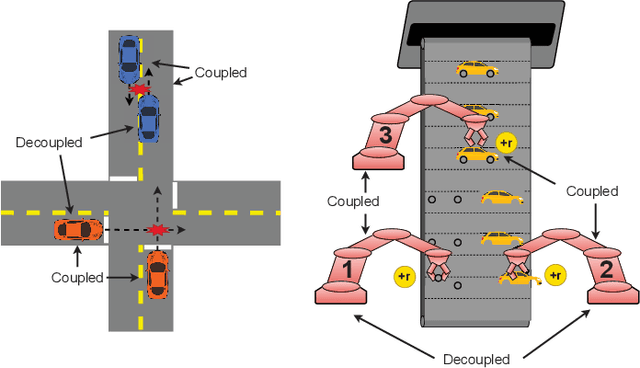
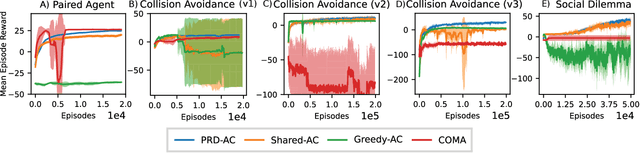
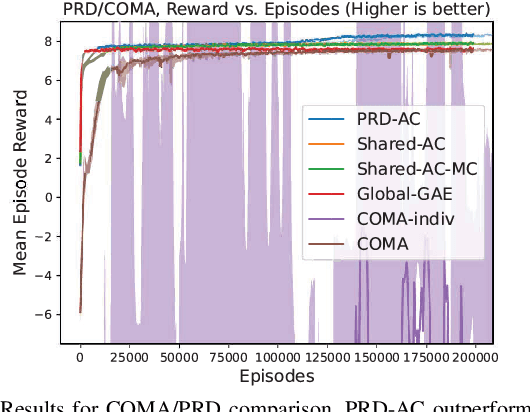
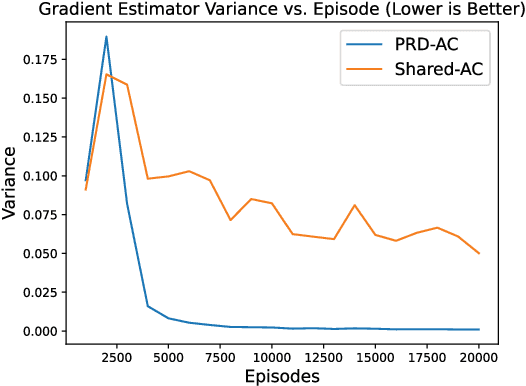
One of the preeminent obstacles to scaling multi-agent reinforcement learning to large numbers of agents is assigning credit to individual agents' actions. In this paper, we address this credit assignment problem with an approach that we call \textit{partial reward decoupling} (PRD), which attempts to decompose large cooperative multi-agent RL problems into decoupled subproblems involving subsets of agents, thereby simplifying credit assignment. We empirically demonstrate that decomposing the RL problem using PRD in an actor-critic algorithm results in lower variance policy gradient estimates, which improves data efficiency, learning stability, and asymptotic performance across a wide array of multi-agent RL tasks, compared to various other actor-critic approaches. Additionally, we relate our approach to counterfactual multi-agent policy gradient (COMA), a state-of-the-art MARL algorithm, and empirically show that our approach outperforms COMA by making better use of information in agents' reward streams, and by enabling recent advances in advantage estimation to be used.
An Experimental Design Perspective on Model-Based Reinforcement Learning
Dec 09, 2021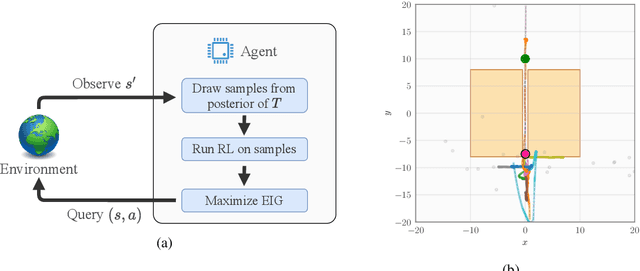
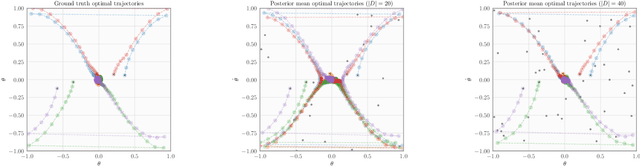

In many practical applications of RL, it is expensive to observe state transitions from the environment. For example, in the problem of plasma control for nuclear fusion, computing the next state for a given state-action pair requires querying an expensive transition function which can lead to many hours of computer simulation or dollars of scientific research. Such expensive data collection prohibits application of standard RL algorithms which usually require a large number of observations to learn. In this work, we address the problem of efficiently learning a policy while making a minimal number of state-action queries to the transition function. In particular, we leverage ideas from Bayesian optimal experimental design to guide the selection of state-action queries for efficient learning. We propose an acquisition function that quantifies how much information a state-action pair would provide about the optimal solution to a Markov decision process. At each iteration, our algorithm maximizes this acquisition function, to choose the most informative state-action pair to be queried, thus yielding a data-efficient RL approach. We experiment with a variety of simulated continuous control problems and show that our approach learns an optimal policy with up to $5$ -- $1,000\times$ less data than model-based RL baselines and $10^3$ -- $10^5\times$ less data than model-free RL baselines. We also provide several ablated comparisons which point to substantial improvements arising from the principled method of obtaining data.
Uncertainty Toolbox: an Open-Source Library for Assessing, Visualizing, and Improving Uncertainty Quantification
Sep 21, 2021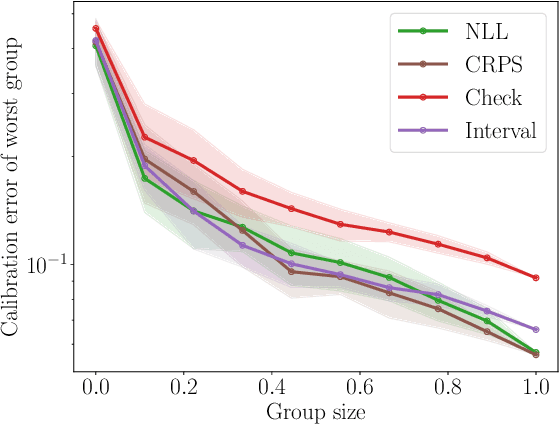
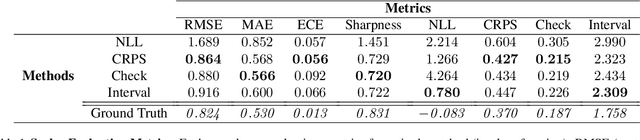
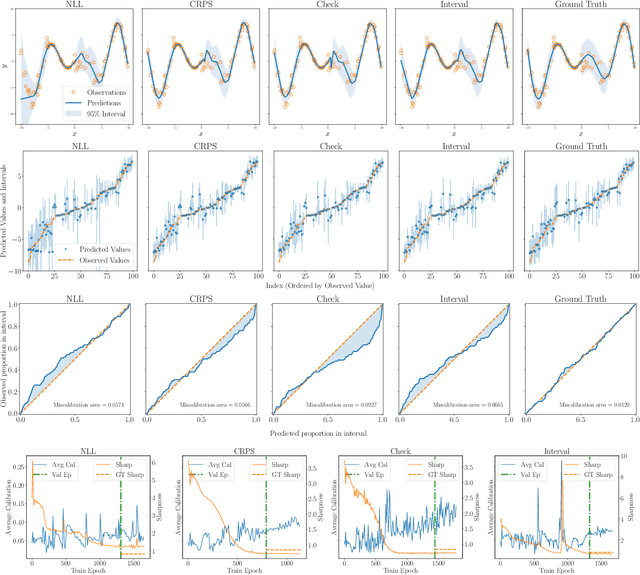
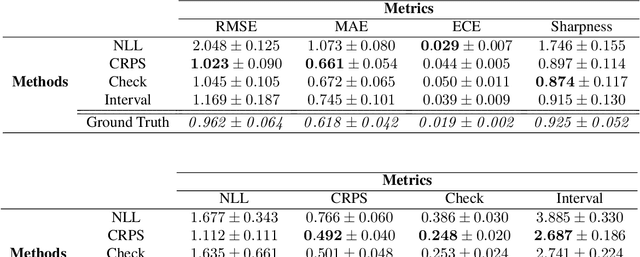
With increasing deployment of machine learning systems in various real-world tasks, there is a greater need for accurate quantification of predictive uncertainty. While the common goal in uncertainty quantification (UQ) in machine learning is to approximate the true distribution of the target data, many works in UQ tend to be disjoint in the evaluation metrics utilized, and disparate implementations for each metric lead to numerical results that are not directly comparable across different works. To address this, we introduce Uncertainty Toolbox, an open-source python library that helps to assess, visualize, and improve UQ. Uncertainty Toolbox additionally provides pedagogical resources, such as a glossary of key terms and an organized collection of key paper references. We hope that this toolbox is useful for accelerating and uniting research efforts in uncertainty in machine learning.
SBEVNet: End-to-End Deep Stereo Layout Estimation
May 25, 2021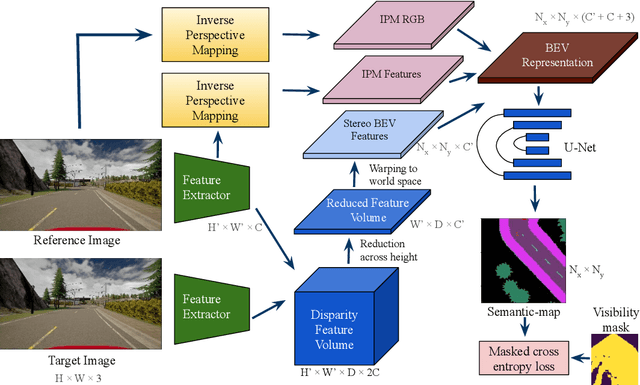
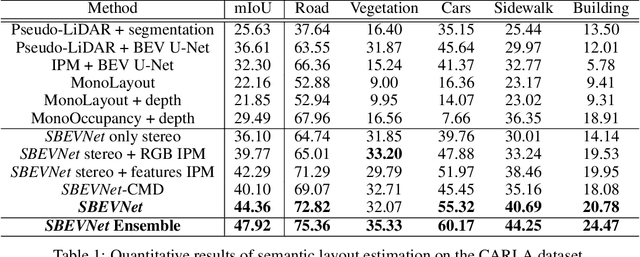
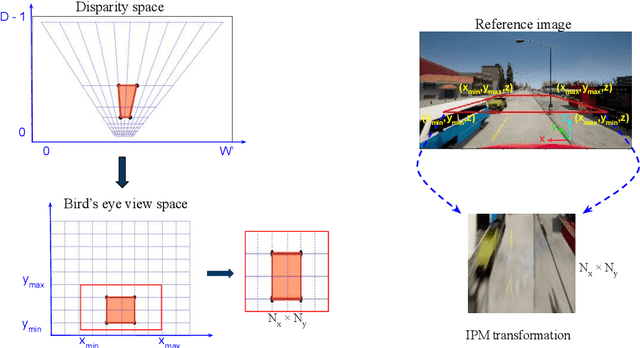
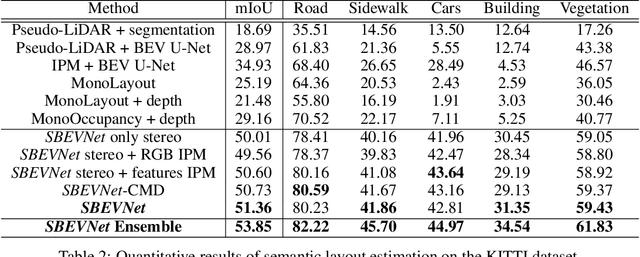
Accurate layout estimation is crucial for planning and navigation in robotics applications, such as self-driving. In this paper, we introduce the Stereo Bird's Eye ViewNetwork (SBEVNet), a novel supervised end-to-end framework for estimation of bird's eye view layout from a pair of stereo images. Although our network reuses some of the building blocks from the state-of-the-art deep learning networks for disparity estimation, we show that explicit depth estimation is neither sufficient nor necessary. Instead, the learning of a good internal bird's eye view feature representation is effective for layout estimation. Specifically, we first generate a disparity feature volume using the features of the stereo images and then project it to the bird's eye view coordinates. This gives us coarse-grained information about the scene structure. We also apply inverse perspective mapping (IPM) to map the input images and their features to the bird's eye view. This gives us fine-grained texture information. Concatenating IPM features with the projected feature volume creates a rich bird's eye view representation which is useful for spatial reasoning. We use this representation to estimate the BEV semantic map. Additionally, we show that using the IPM features as a supervisory signal for stereo features can give an improvement in performance. We demonstrate our approach on two datasets:the KITTI dataset and a synthetically generated dataset from the CARLA simulator. For both of these datasets, we establish state-of-the-art performance compared to baseline techniques.
Affordance-based Reinforcement Learning for Urban Driving
Jan 15, 2021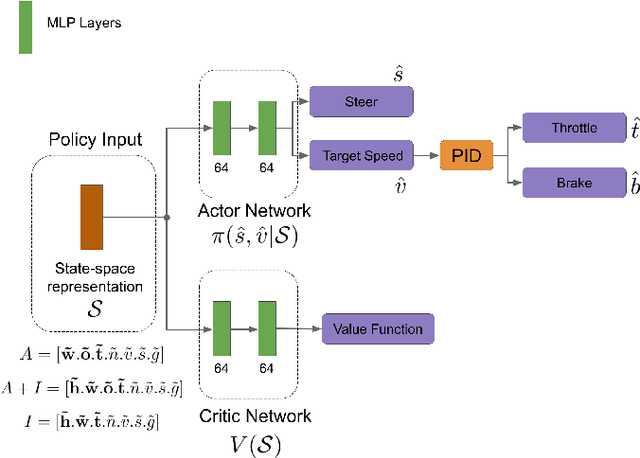
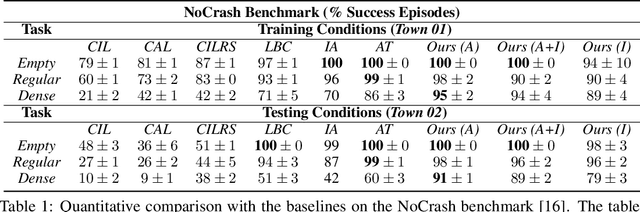
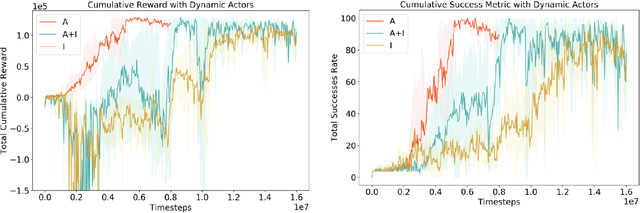
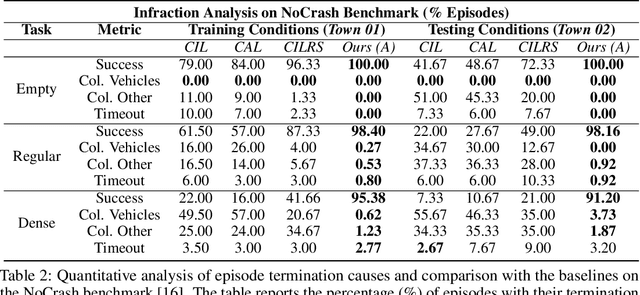
Traditional autonomous vehicle pipelines that follow a modular approach have been very successful in the past both in academia and industry, which has led to autonomy deployed on road. Though this approach provides ease of interpretation, its generalizability to unseen environments is limited and hand-engineering of numerous parameters is required, especially in the prediction and planning systems. Recently, deep reinforcement learning has been shown to learn complex strategic games and perform challenging robotic tasks, which provides an appealing framework for learning to drive. In this work, we propose a deep reinforcement learning framework to learn optimal control policy using waypoints and low-dimensional visual representations, also known as affordances. We demonstrate that our agents when trained from scratch learn the tasks of lane-following, driving around inter-sections as well as stopping in front of other actors or traffic lights even in the dense traffic setting. We note that our method achieves comparable or better performance than the baseline methods on the original and NoCrash benchmarks on the CARLA simulator.
Beyond Pinball Loss: Quantile Methods for Calibrated Uncertainty Quantification
Dec 04, 2020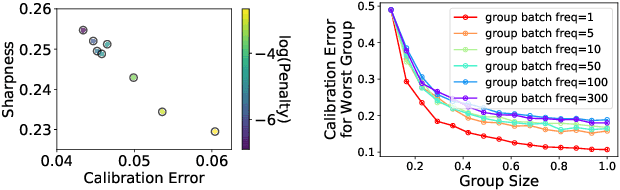
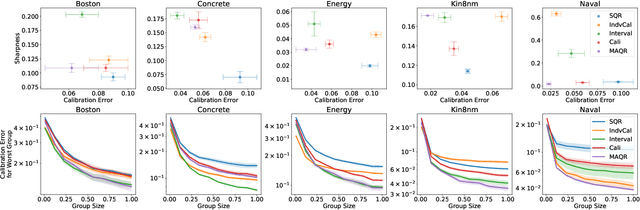
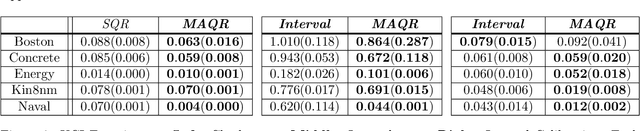
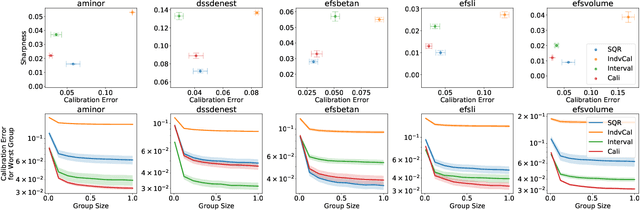
Among the many ways of quantifying uncertainty in a regression setting, specifying the full quantile function is attractive, as quantiles are amenable to interpretation and evaluation. A model that predicts the true conditional quantiles for each input, at all quantile levels, presents a correct and efficient representation of the underlying uncertainty. To achieve this, many current quantile-based methods focus on optimizing the so-called pinball loss. However, this loss restricts the scope of applicable regression models, limits the ability to target many desirable properties (e.g. calibration, sharpness, centered intervals), and may produce poor conditional quantiles. In this work, we develop new quantile methods that address these shortcomings. In particular, we propose methods that can apply to any class of regression model, allow for selecting a Pareto-optimal trade-off between calibration and sharpness, optimize for calibration of centered intervals, and produce more accurate conditional quantiles. We provide a thorough experimental evaluation of our methods, which includes a high dimensional uncertainty quantification task in nuclear fusion.
Multi-Agent Active Search using Realistic Depth-Aware Noise Model
Nov 09, 2020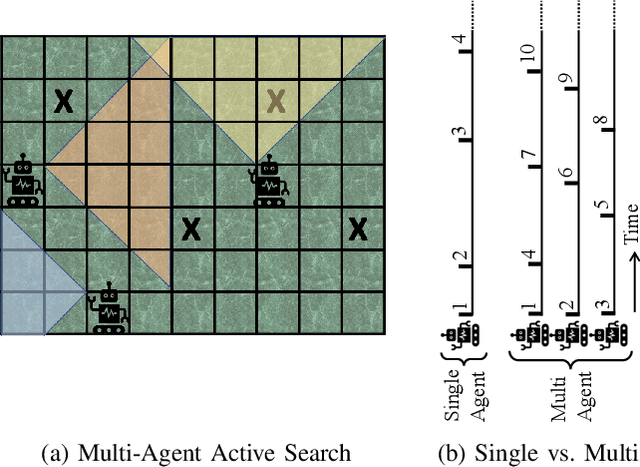
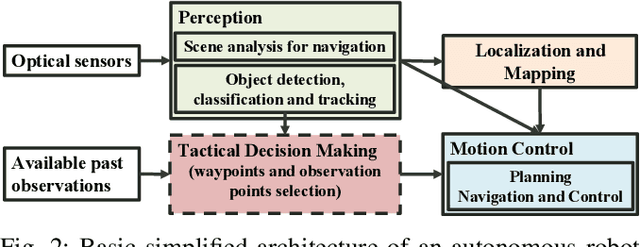
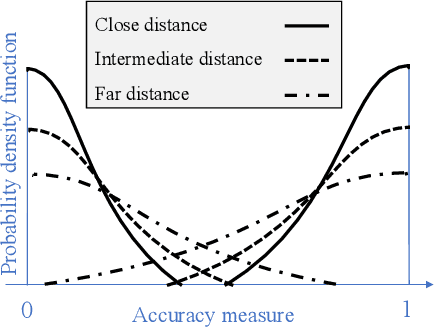
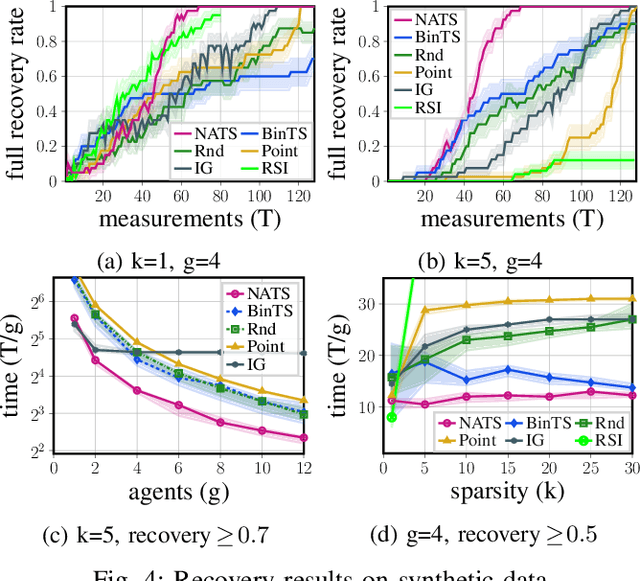
The search for objects of interest in an unknown environment by making data-collection decisions (i.e., active search or active sensing) has robotics applications in many fields, including the search and rescue of human survivors following disasters, detecting gas leaks or locating and preventing animal poachers. Existing algorithms often prioritize the location accuracy of objects of interest while other practical issues such as the reliability of object detection as a function of distance and lines of sight remain largely ignored. An additional challenge is that in many active search scenarios, communication infrastructure may be damaged, unreliable, or unestablished, making centralized control of multiple search agents impractical. We present an algorithm called Noise-Aware Thompson Sampling (NATS) that addresses these issues for multiple ground-based robot agents performing active search considering two sources of sensory information from monocular optical imagery and sonar tracking. NATS utilizes communications between robot agents in a decentralized manner that is robust to intermittent loss of communication links. Additionally, it takes into account object detection uncertainty from depth as well as environmental occlusions. Using simulation results, we show that NATS significantly outperforms existing methods such as information-greedy policies or exhaustive search. We demonstrate the real-world viability of NATS using a photo-realistic environment created in the Unreal Engine 4 game development platform with the AirSim plugin.
Behavior Planning at Urban Intersections through Hierarchical Reinforcement Learning
Nov 09, 2020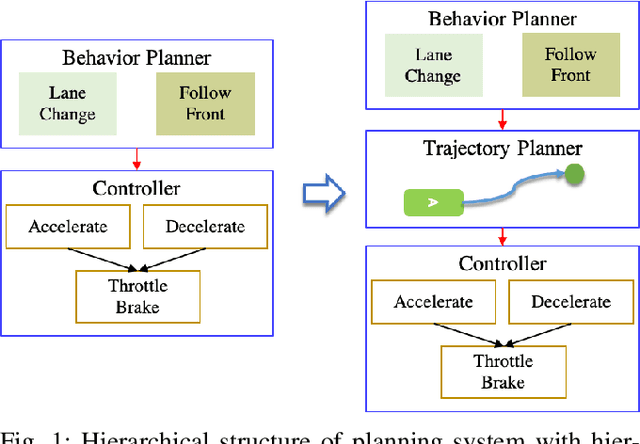
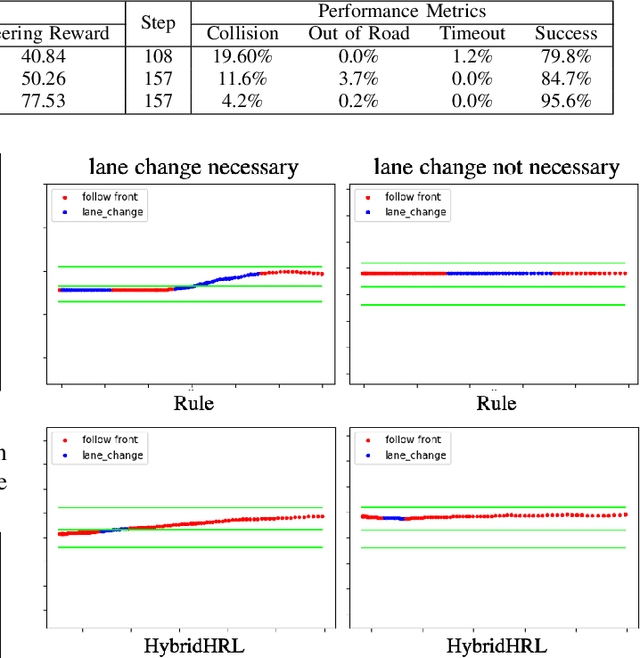
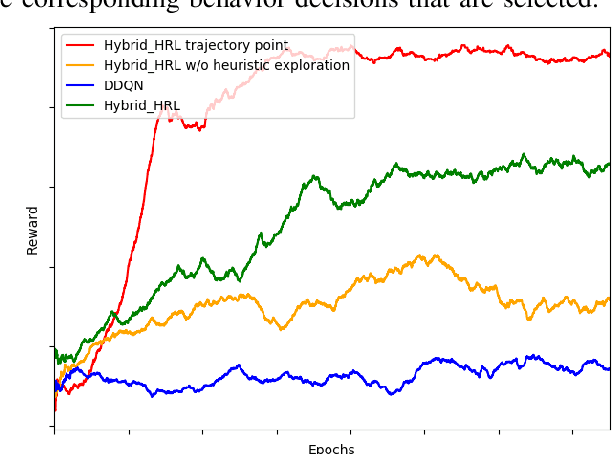
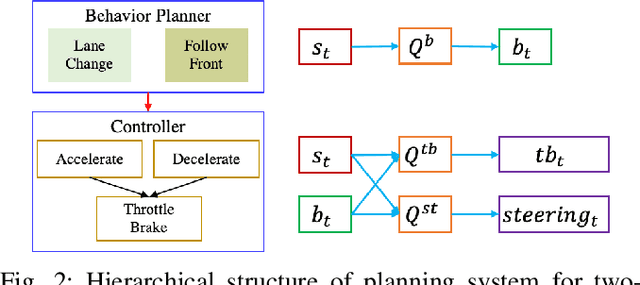
For autonomous vehicles, effective behavior planning is crucial to ensure safety of the ego car. In many urban scenarios, it is hard to create sufficiently general heuristic rules, especially for challenging scenarios that some new human drivers find difficult. In this work, we propose a behavior planning structure based on reinforcement learning (RL) which is capable of performing autonomous vehicle behavior planning with a hierarchical structure in simulated urban environments. Application of the hierarchical structure allows the various layers of the behavior planning system to be satisfied. Our algorithms can perform better than heuristic-rule-based methods for elective decisions such as when to turn left between vehicles approaching from the opposite direction or possible lane-change when approaching an intersection due to lane blockage or delay in front of the ego car. Such behavior is hard to evaluate as correct or incorrect, but for some aggressive expert human drivers handle such scenarios effectively and quickly. On the other hand, compared to traditional RL methods, our algorithm is more sample-efficient, due to the use of a hybrid reward mechanism and heuristic exploration during the training process. The results also show that the proposed method converges to an optimal policy faster than traditional RL methods.
Interactive Visualization for Debugging RL
Aug 18, 2020
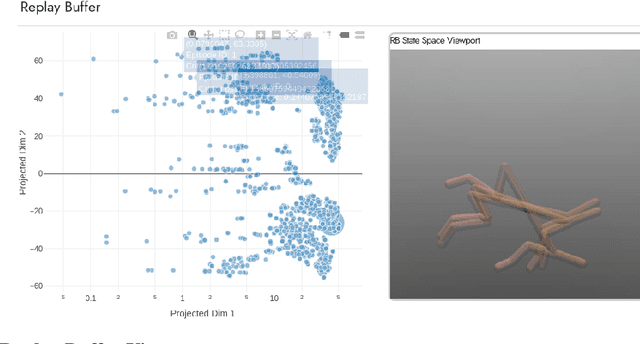
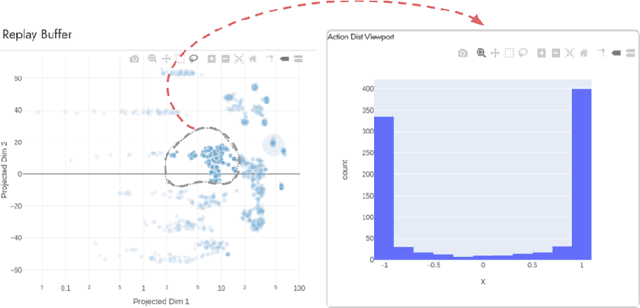
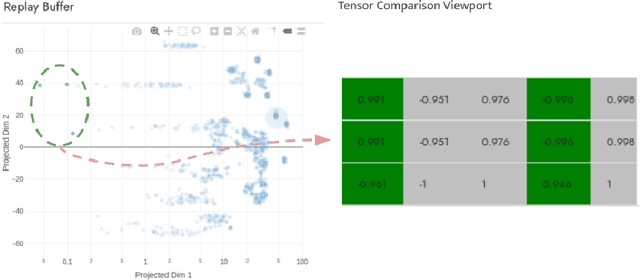
Visualization tools for supervised learning allow users to interpret, introspect, and gain an intuition for the successes and failures of their models. While reinforcement learning practitioners ask many of the same questions, existing tools are not applicable to the RL setting as these tools address challenges typically found in the supervised learning regime. In this work, we design and implement an interactive visualization tool for debugging and interpreting RL algorithms. Our system addresses many features missing from previous tools such as (1) tools for supervised learning often are not interactive; (2) while debugging RL policies researchers use state representations that are different from those seen by the agent; (3) a framework designed to make the debugging RL policies more conducive. We provide an example workflow of how this system could be used, along with ideas for future extensions.
Vizarel: A System to Help Better Understand RL Agents
Jul 10, 2020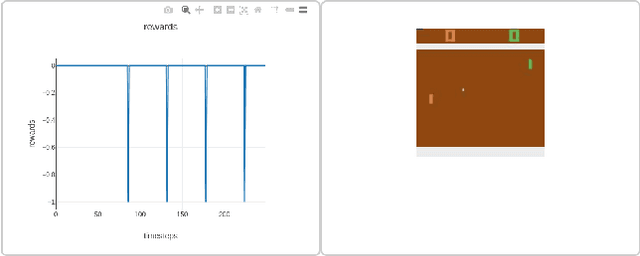
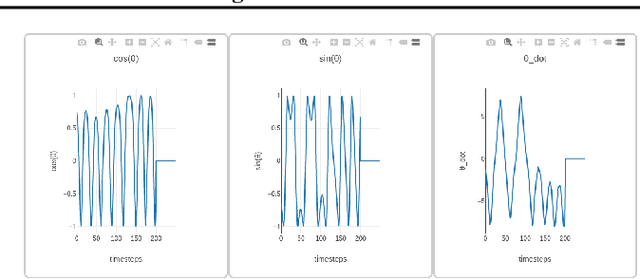
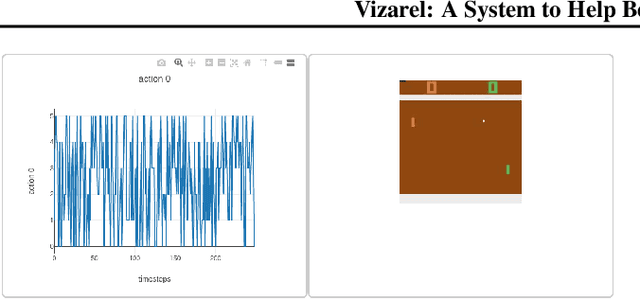
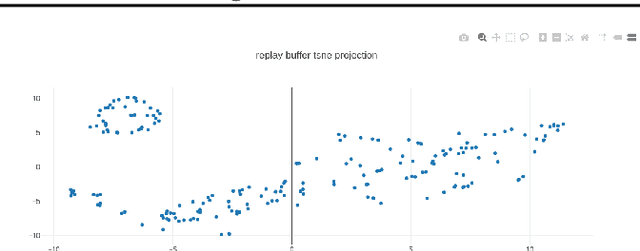
Visualization tools for supervised learning have allowed users to interpret, introspect, and gain intuition for the successes and failures of their models. While reinforcement learning practitioners ask many of the same questions, existing tools are not applicable to the RL setting. In this work, we describe our initial attempt at constructing a prototype of these ideas, through identifying possible features that such a system should encapsulate. Our design is motivated by envisioning the system to be a platform on which to experiment with interpretable reinforcement learning.