 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUTS: Generalized Uncertainty-Aware Thompson Sampling for Multi-Agent Active Search
Apr 04, 2023



Robotic solutions for quick disaster response are essential to ensure minimal loss of life, especially when the search area is too dangerous or too vast for human rescuers. We model this problem as an asynchronous multi-agent active-search task where each robot aims to efficiently seek objects of interest (OOIs) in an unknown environment. This formulation addresses the requirement that search missions should focus on quick recovery of OOIs rather than full coverage of the search region. Previous approaches fail to accurately model sensing uncertainty, account for occlusions due to foliage or terrain, or consider the requirement for heterogeneous search teams and robustness to hardware and communication failures. We present the Generalized Uncertainty-aware Thompson Sampling (GUTS) algorithm, which addresses these issues and is suitable for deployment on heterogeneous multi-robot systems for active search in large unstructured environments. We show through simulation experiments that GUTS consistently outperforms existing methods such as parallelized Thompson Sampling and exhaustive search, recovering all OOIs in 80% of all runs. In contrast, existing approaches recover all OOIs in less than 40% of all runs. We conduct field tests using our multi-robot system in an unstructured environment with a search area of approximately 75,000 sq. m. Our system demonstrates robustness to various failure modes, achieving full recovery of OOIs (where feasible) in every field run, and significantly outperforming our baseline.
Near-optimal Policy Identification in Active Reinforcement Learning
Dec 19, 2022



Many real-world reinforcement learning tasks require control of complex dynamical systems that involve both costly data acquisition processes and large state spaces. In cases where the transition dynamics can be readily evaluated at specified states (e.g., via a simulator), agents can operate in what is often referred to as planning with a \emph{generative model}. We propose the AE-LSVI algorithm for best-policy identification, a novel variant of the kernelized least-squares value iteration (LSVI) algorithm that combines optimism with pessimism for active exploration (AE). AE-LSVI provably identifies a near-optimal policy \emph{uniformly} over an entire state space and achieves polynomial sample complexity guarantees that are independent of the number of states. When specialized to the recently introduced offline contextual Bayesian optimization setting, our algorithm achieves improved sample complexity bounds. Experimentally, we demonstrate that AE-LSVI outperforms other RL algorithms in a variety of environments when robustness to the initial state is required.
Exploration via Planning for Information about the Optimal Trajectory
Oct 06, 2022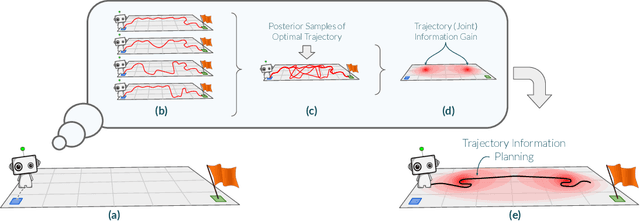

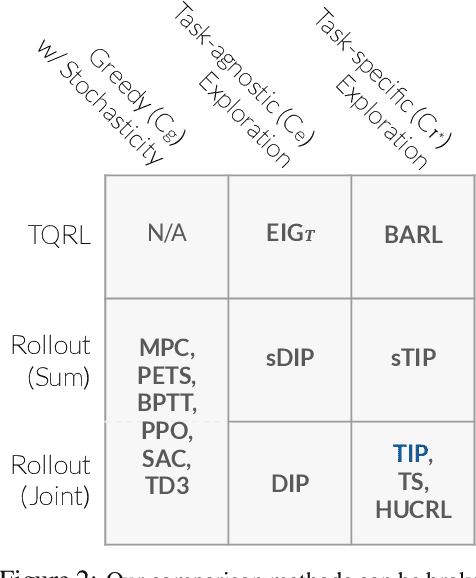
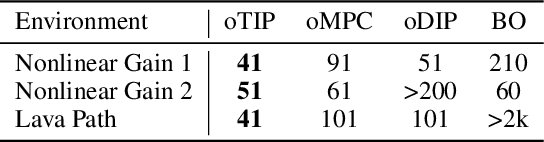
Many potential applications of reinforcement learning (RL) are stymied by the large numbers of samples required to learn an effective policy. This is especially true when applying RL to real-world control tasks, e.g. in the sciences or robotics, where executing a policy in the environment is costly. In popular RL algorithms, agents typically explore either by adding stochasticity to a reward-maximizing policy or by attempting to gather maximal information about environment dynamics without taking the given task into account. In this work, we develop a method that allows us to plan for exploration while taking both the task and the current knowledge about the dynamics into account. The key insight to our approach is to plan an action sequence that maximizes the expected information gain about the optimal trajectory for the task at hand. We demonstrate that our method learns strong policies with 2x fewer samples than strong exploration baselines and 200x fewer samples than model free methods on a diverse set of low-to-medium dimensional control tasks in both the open-loop and closed-loop control settings.
Cost Aware Asynchronous Multi-Agent Active Search
Oct 05, 2022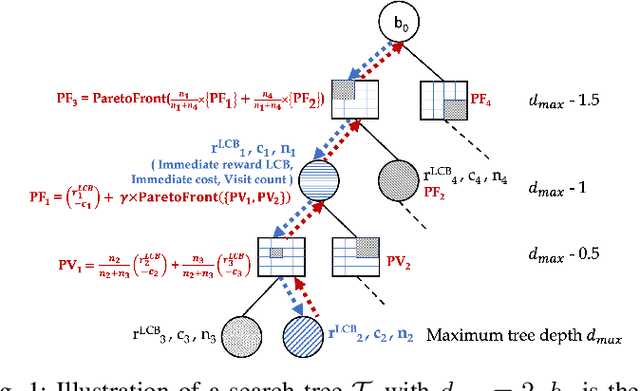
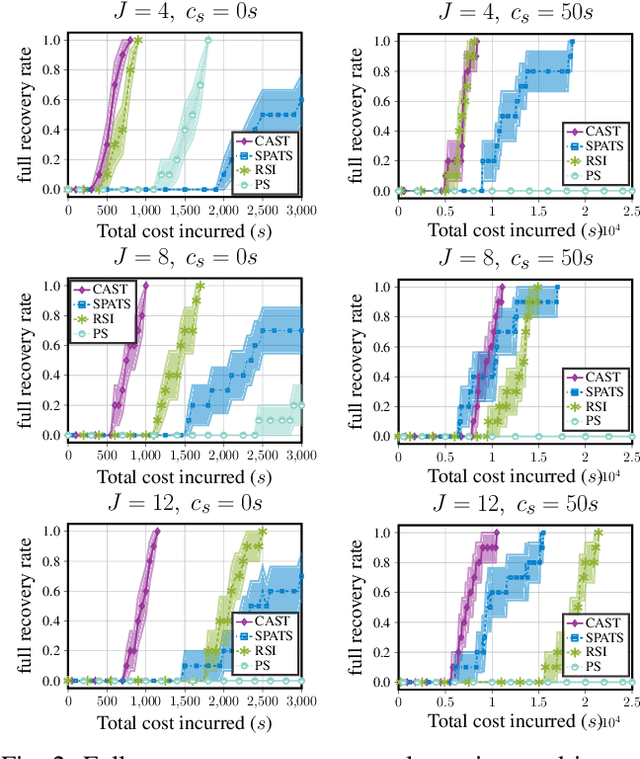
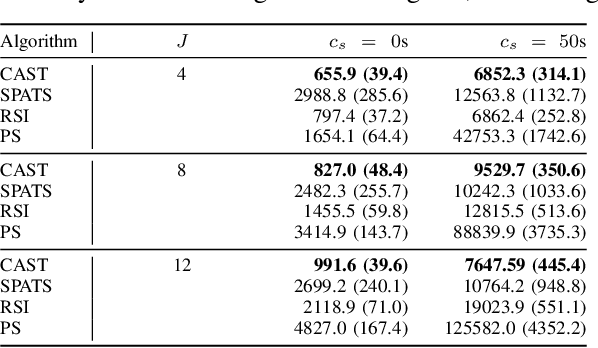
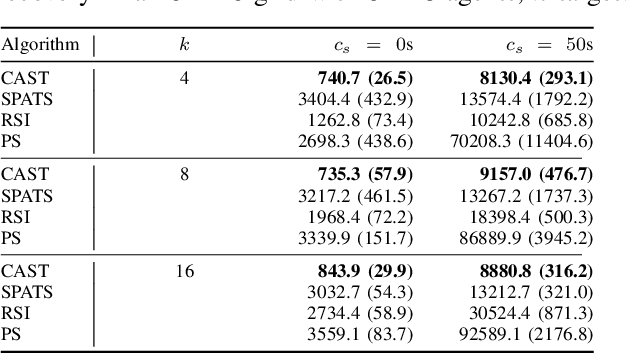
Multi-agent active search requires autonomous agents to choose sensing actions that efficiently locate targets. In a realistic setting, agents also must consider the costs that their decisions incur. Previously proposed active search algorithms simplify the problem by ignoring uncertainty in the agent's environment, using myopic decision making, and/or overlooking costs. In this paper, we introduce an online active search algorithm to detect targets in an unknown environment by making adaptive cost-aware decisions regarding the agent's actions. Our algorithm combines principles from Thompson Sampling (for search space exploration and decentralized multi-agent decision making), Monte Carlo Tree Search (for long horizon planning) and pareto-optimal confidence bounds (for multi-objective optimization in an unknown environment) to propose an online lookahead planner that removes all the simplifications. We analyze the algorithm's performance in simulation to show its efficacy in cost aware active search.
Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning
Jul 21, 2022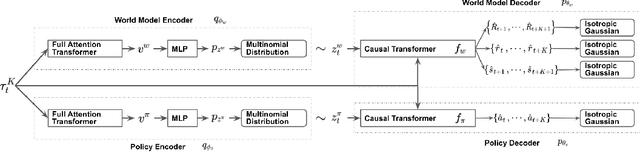


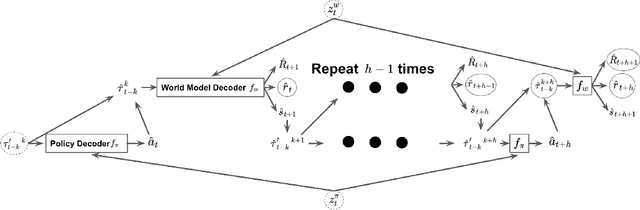
Impressive results in natural language processing (NLP) based on the Transformer neural network architecture have inspired researchers to explore viewing offline reinforcement learning (RL) as a generic sequence modeling problem. Recent works based on this paradigm have achieved state-of-the-art results in several of the mostly deterministic offline Atari and D4RL benchmarks. However, because these methods jointly model the states and actions as a single sequencing problem, they struggle to disentangle the effects of the policy and world dynamics on the return. Thus, in adversarial or stochastic environments, these methods lead to overly optimistic behavior that can be dangerous in safety-critical systems like autonomous driving. In this work, we propose a method that addresses this optimism bias by explicitly disentangling the policy and world models, which allows us at test time to search for policies that are robust to multiple possible futures in the environment. We demonstrate our method's superior performance on a variety of autonomous driving tasks in simulation.
How Useful are Gradients for OOD Detection Really?
May 20, 2022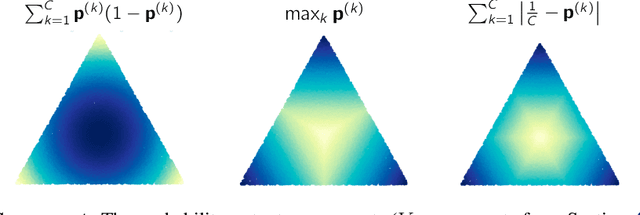
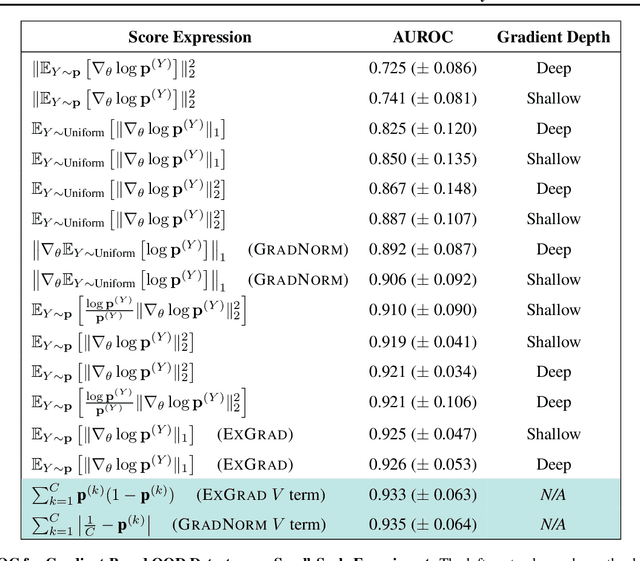
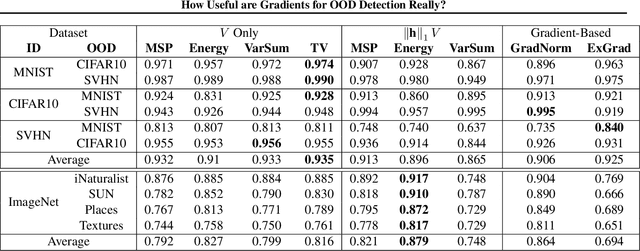
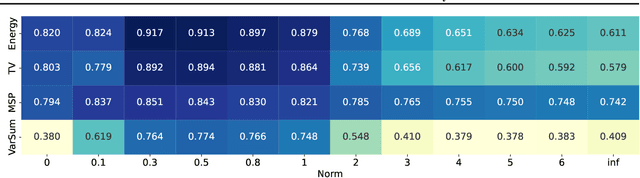
One critical challenge in deploying highly performant machine learning models in real-life applications is out of distribution (OOD) detection. Given a predictive model which is accurate on in distribution (ID) data, an OOD detection system will further equip the model with the option to defer prediction when the input is novel and the model has little confidence in prediction. There has been some recent interest in utilizing the gradient information in pre-trained models for OOD detection. While these methods have shown competitive performance, there are misconceptions about the true mechanism underlying them, which conflate their performance with the necessity of gradients. In this work, we provide an in-depth analysis and comparison of gradient based methods and elucidate the key components that warrant their OOD detection performance. We further propose a general, non-gradient based method of OOD detection which improves over previous baselines in both performance and computational efficiency.
BATS: Best Action Trajectory Stitching
Apr 26, 2022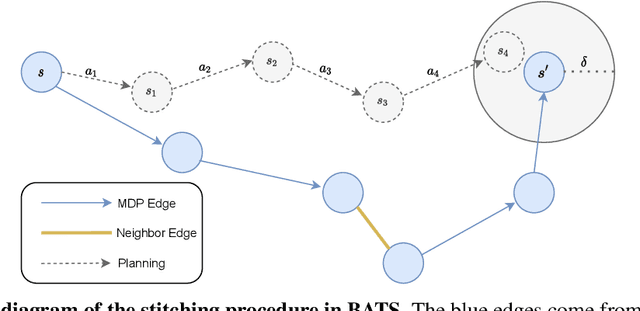

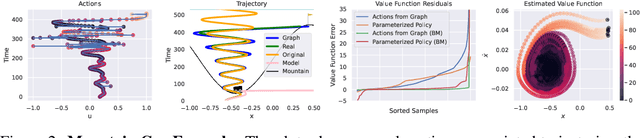
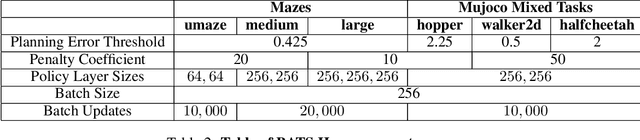
The problem of offline reinforcement learning focuses on learning a good policy from a log of environment interactions. Past efforts for developing algorithms in this area have revolved around introducing constraints to online reinforcement learning algorithms to ensure the actions of the learned policy are constrained to the logged data. In this work, we explore an alternative approach by planning on the fixed dataset directly. Specifically, we introduce an algorithm which forms a tabular Markov Decision Process (MDP) over the logged data by adding new transitions to the dataset. We do this by using learned dynamics models to plan short trajectories between states. Since exact value iteration can be performed on this constructed MDP, it becomes easy to identify which trajectories are advantageous to add to the MDP. Crucially, since most transitions in this MDP come from the logged data, trajectories from the MDP can be rolled out for long periods with confidence. We prove that this property allows one to make upper and lower bounds on the value function up to appropriate distance metrics. Finally, we demonstrate empirically how algorithms that uniformly constrain the learned policy to the entire dataset can result in unwanted behavior, and we show an example in which simply behavior cloning the optimal policy of the MDP created by our algorithm avoids this problem.
Multi-Agent Active Search using Detection and Location Uncertainty
Mar 09, 2022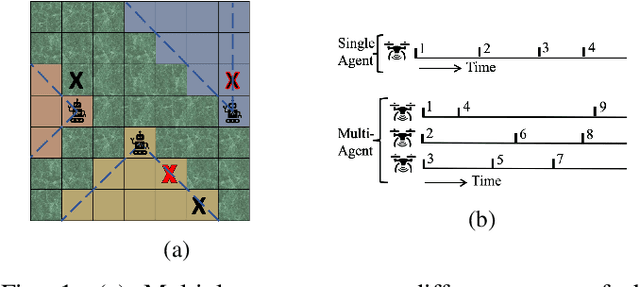
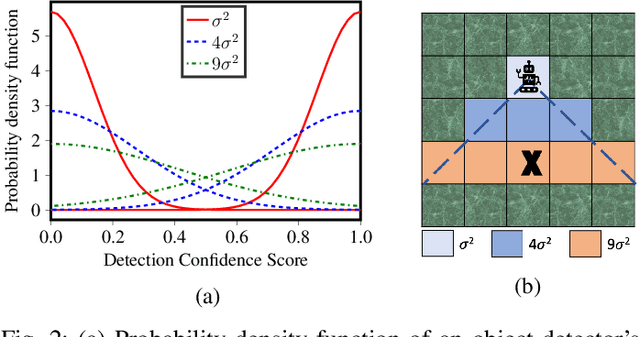
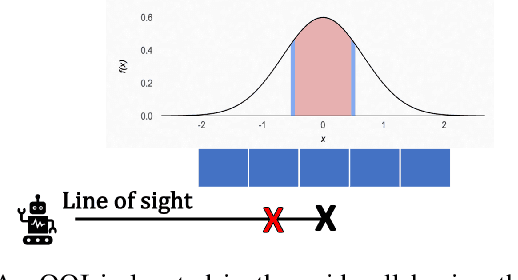
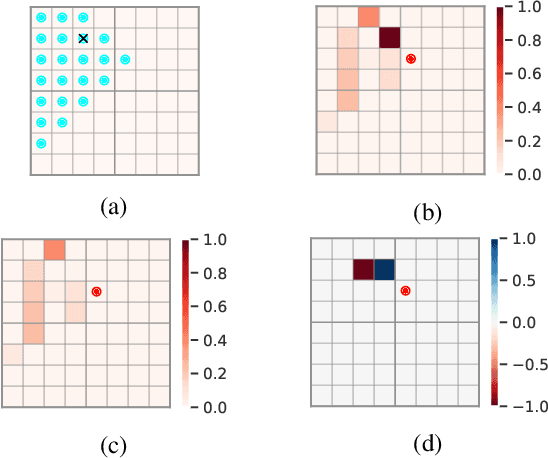
Active search refers to the task of autonomous robots (agents) detecting objects of interest (targets) in a search space using decision making algorithms that adapt to the history of their observations. It has important applications in search and rescue missions, wildlife patrolling and environment monitoring. Active search algorithms must contend with two types of uncertainty: detection uncertainty and location uncertainty. Prior work has typically focused on one of these while ignoring or engineering away the other. The more common approach in robotics is to focus on location uncertainty and remove detection uncertainty by thresholding the detection probability to zero or one. On the other hand, it is common in the sparse signal processing literature to assume the target location is accurate and focus on the uncertainty of its detection. In this work, we propose an inference method to jointly handle both target detection and location uncertainty. We then build a decision making algorithm on this inference method that uses Thompson sampling to enable efficient active search in both the single agent and multi-agent settings. We perform experiments in simulation over varying number of agents and targets to show that our inference and decision making algorithms outperform competing baselines that only account for either target detection or location uncertainty.
Robust Reinforcement Learning via Genetic Curriculum
Feb 17, 2022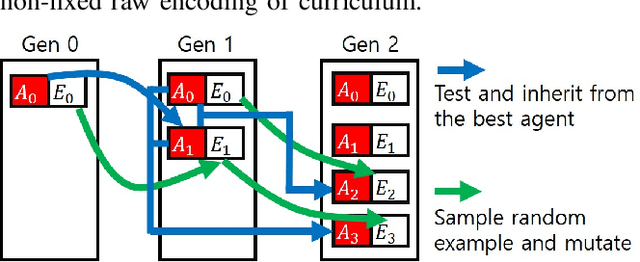
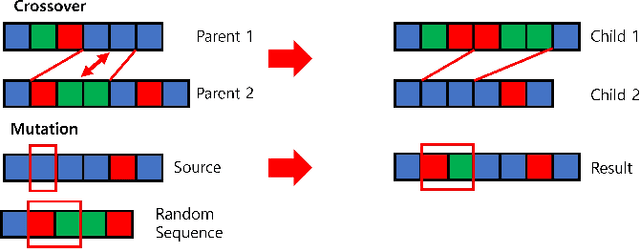

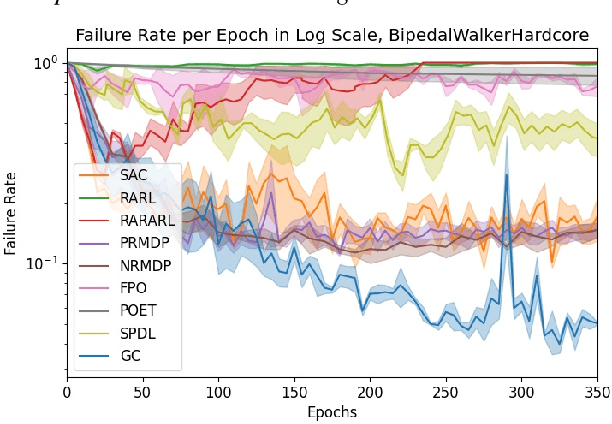
Achieving robust performance is crucial when applying deep reinforcement learning (RL) in safety critical systems. Some of the state of the art approaches try to address the problem with adversarial agents, but these agents often require expert supervision to fine tune and prevent the adversary from becoming too challenging to the trainee agent. While other approaches involve automatically adjusting environment setups during training, they have been limited to simple environments where low-dimensional encodings can be used. Inspired by these approaches, we propose genetic curriculum, an algorithm that automatically identifies scenarios in which the agent currently fails and generates an associated curriculum to help the agent learn to solve the scenarios and acquire more robust behaviors. As a non-parametric optimizer, our approach uses a raw, non-fixed encoding of scenarios, reducing the need for expert supervision and allowing our algorithm to adapt to the changing performance of the agent. Our empirical studies show improvement in robustness over the existing state of the art algorithms, providing training curricula that result in agents being 2 - 8x times less likely to fail without sacrificing cumulative reward. We include an ablation study and share insights on why our algorithm outperforms prior approaches.
UGV-UAV Object Geolocation in Unstructured Environments
Jan 14, 2022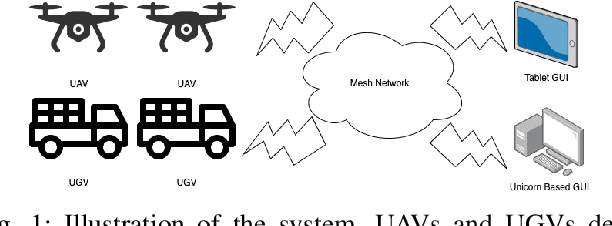


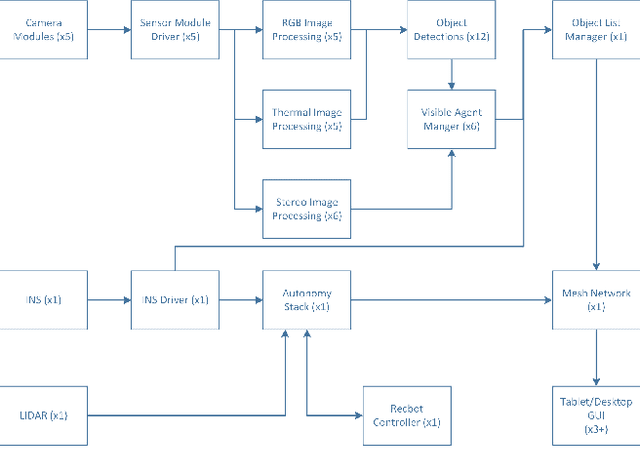
A robotic system of multiple unmanned ground vehicles (UGVs) and unmanned aerial vehicles (UAVs) has the potential for advancing autonomous object geolocation performance. Much research has focused on algorithmic improvements on individual components, such as navigation, motion planning, and perception. In this paper, we present a UGV-UAV object detection and geolocation system, which performs perception, navigation, and planning autonomously in real scale in unstructured environment. We designed novel sensor pods equipped with multispectral (visible, near-infrared, thermal), high resolution (181.6 Mega Pixels), stereo (near-infrared pair), wide field of view (192 degree HFOV) array. We developed a novel on-board software-hardware architecture to process the high volume sensor data in real-time, and we built a custom AI subsystem composed of detection, tracking, navigation, and planning for autonomous objects geolocation in real-time. This research is the first real scale demonstration of such high speed data processing capability. Our novel modular sensor pod can boost relevant computer vision and machine learning research. Our novel hardware-software architecture is a solid foundation for system-level and component-level research. Our system is validated through data-driven offline tests as well as a series of field tests in unstructured environments. We present quantitative results as well as discussions on key robotic system level challenges which manifest when we build and test the system. This system is the first step toward a UGV-UAV cooperative reconnaissance system in the future.