 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Topological Motion Primitives for Knot Planning
Sep 05, 2020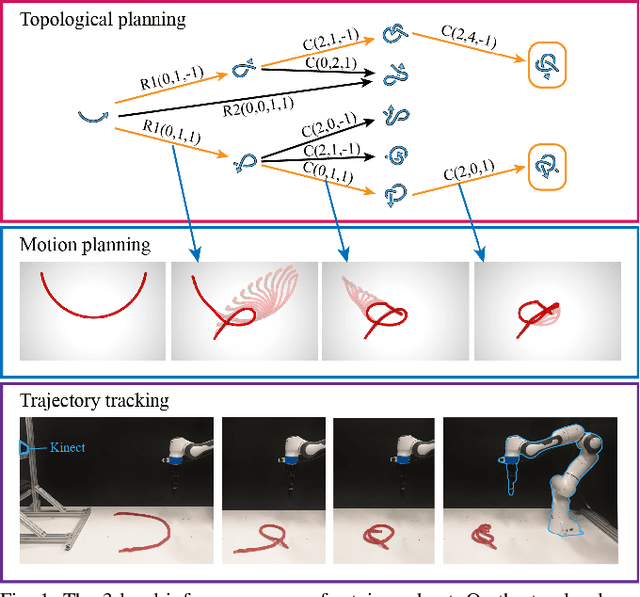
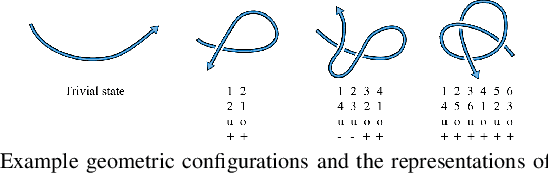
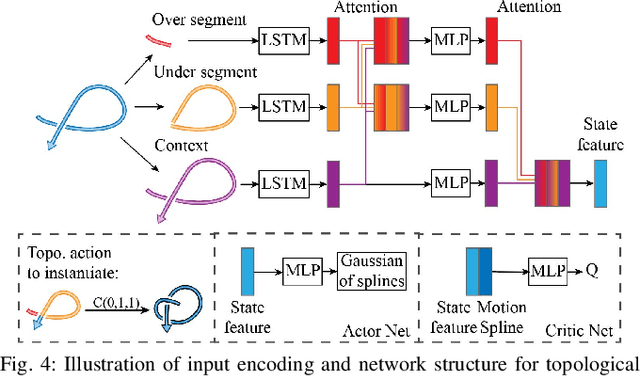
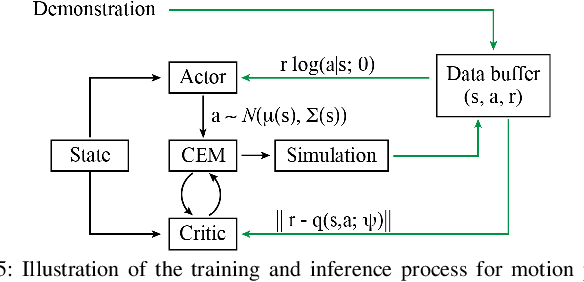
In this paper, we approach the challenging problem of motion planning for knot tying. We propose a hierarchical approach in which the top layer produces a topological plan and the bottom layer translates this plan into continuous robot motion. The top layer decomposes a knotting task into sequences of abstract topological actions based on knot theory. The bottom layer translates each of these abstract actions into robot motion trajectories through learned topological motion primitives. To adapt each topological action to the specific rope geometry, the motion primitives take the observed rope configuration as input. We train the motion primitives by imitating human demonstrations and reinforcement learning in simulation. To generalize human demonstrations of simple knots into more complex knots, we observe similarities in the motion strategies of different topological actions and design the neural network structure to exploit such similarities. We demonstrate that our learned motion primitives can be used to efficiently generate motion plans for tying the overhand knot. The motion plan can then be executed on a real robot using visual tracking and Model Predictive Control. We also demonstrate that our learned motion primitives can be composed to tie a more complex pentagram-like knot despite being only trained on human demonstrations of simpler knots.
Learning User-Preferred Mappings for Intuitive Robot Control
Jul 22, 2020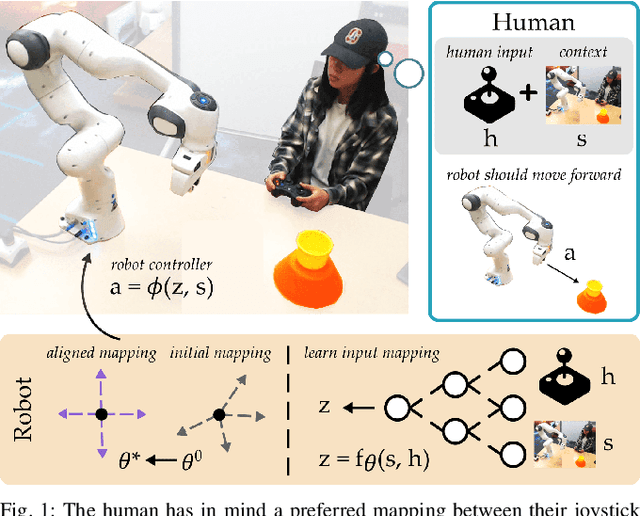
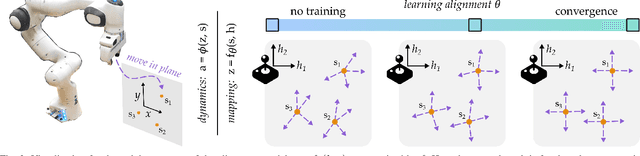
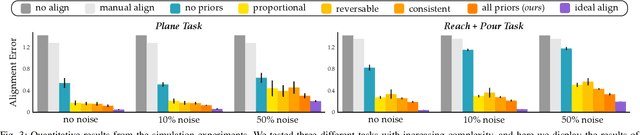
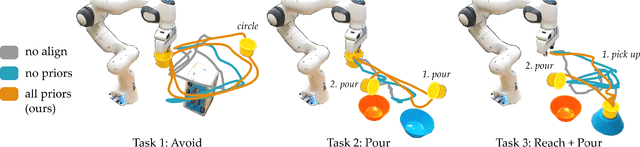
When humans control drones, cars, and robots, we often have some preconceived notion of how our inputs should make the system behave. Existing approaches to teleoperation typically assume a one-size-fits-all approach, where the designers pre-define a mapping between human inputs and robot actions, and every user must adapt to this mapping over repeated interactions. Instead, we propose a personalized method for learning the human's preferred or preconceived mapping from a few robot queries. Given a robot controller, we identify an alignment model that transforms the human's inputs so that the controller's output matches their expectations. We make this approach data-efficient by recognizing that human mappings have strong priors: we expect the input space to be proportional, reversable, and consistent. Incorporating these priors ensures that the robot learns an intuitive mapping from few examples. We test our learning approach in robot manipulation tasks inspired by assistive settings, where each user has different personal preferences and physical capabilities for teleoperating the robot arm. Our simulated and experimental results suggest that learning the mapping between inputs and robot actions improves objective and subjective performance when compared to manually defined alignments or learned alignments without intuitive priors. The supplementary video showing these user studies can be found at: https://youtu.be/rKHka0_48-Q.
Dynamic Multi-Robot Task Allocation under Uncertainty and Temporal Constraints
May 29, 2020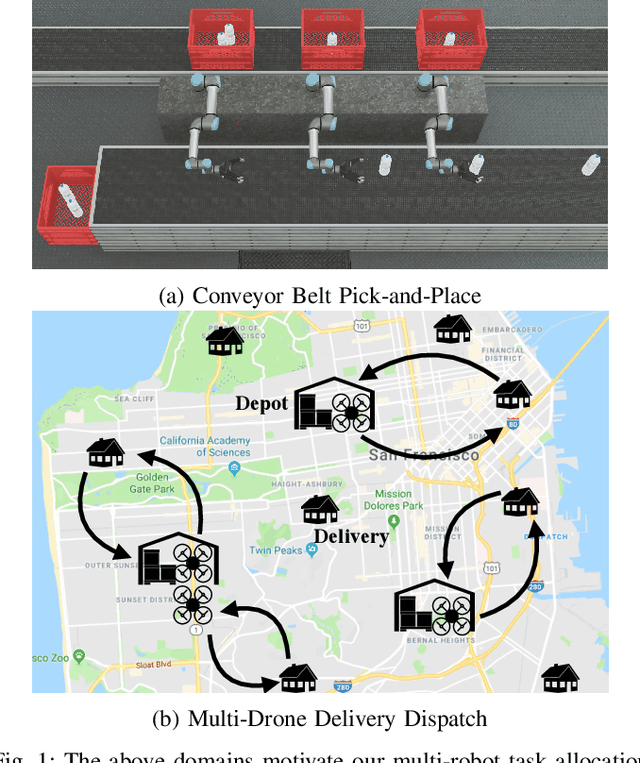
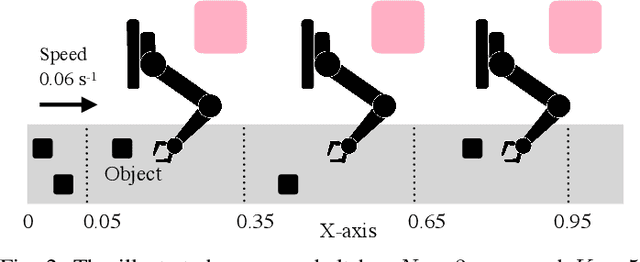
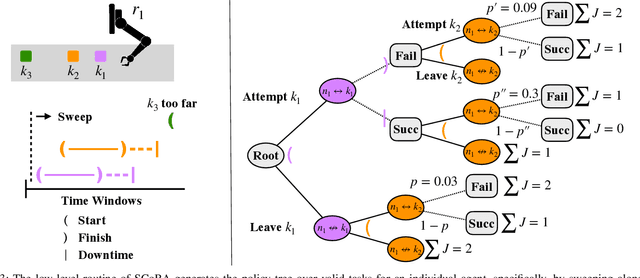
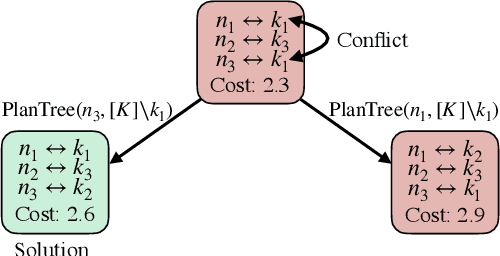
We consider the problem of dynamically allocating tasks to multiple agents under time window constraints and task completion uncertainty. Our objective is to minimize the number of unsuccessful tasks at the end of the operation horizon. We present a multi-robot allocation algorithm that decouples the key computational challenges of sequential decision-making under uncertainty and multi-agent coordination and addresses them in a hierarchical manner. The lower layer computes policies for individual agents using dynamic programming with tree search, and the upper layer resolves conflicts in individual plans to obtain a valid multi-agent allocation. Our algorithm, Stochastic Conflict-Based Allocation (SCoBA), is optimal in expectation and complete under some reasonable assumptions. In practice, SCoBA is computationally efficient enough to interleave planning and execution online. On the metric of successful task completion, SCoBA consistently outperforms a number of baseline methods and shows strong competitive performance against an oracle with complete lookahead. It also scales well with the number of tasks and agents. We validate our results over a wide range of simulations on two distinct domains: multi-arm conveyor belt pick-and-place and multi-drone delivery dispatch in a city.
Probabilistic 3D Multi-Object Tracking for Autonomous Driving
Jan 16, 2020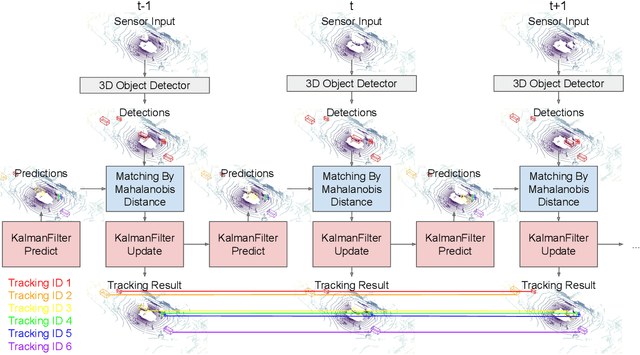
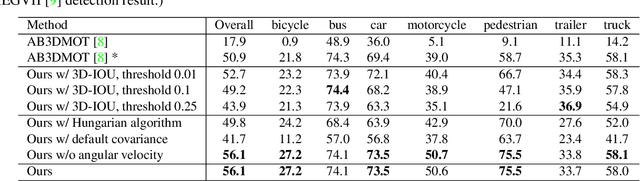

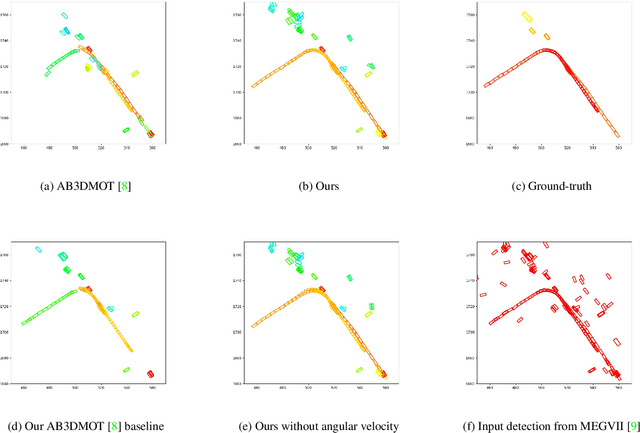
3D multi-object tracking is a key module in autonomous driving applications that provides a reliable dynamic representation of the world to the planning module. In this paper, we present our on-line tracking method, which made the first place in the NuScenes Tracking Challenge, held at the AI Driving Olympics Workshop at NeurIPS 2019. Our method estimates the object states by adopting a Kalman Filter. We initialize the state covariance as well as the process and observation noise covariance with statistics from the training set. We also use the stochastic information from the Kalman Filter in the data association step by measuring the Mahalanobis distance between the predicted object states and current object detections. Our experimental results on the NuScenes validation and test set show that our method outperforms the AB3DMOT baseline method by a large margin in the Average Multi-Object Tracking Accuracy (AMOTA) metric.
Self-Supervised Learning of State Estimation for Manipulating Deformable Linear Objects
Nov 14, 2019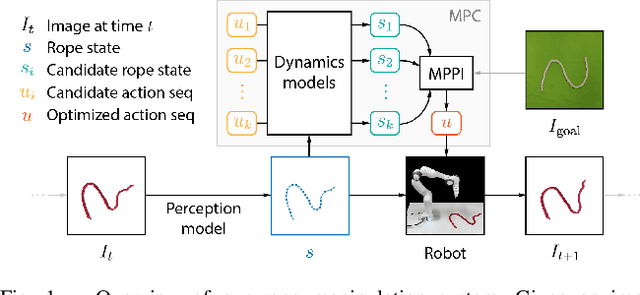
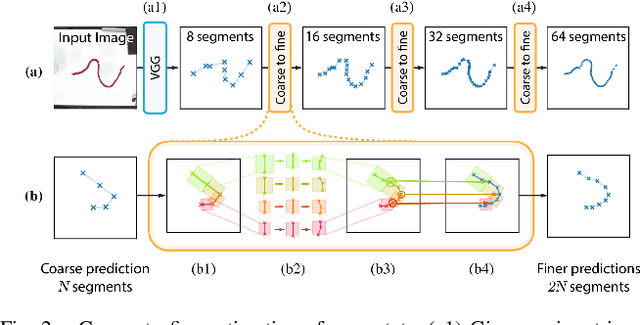
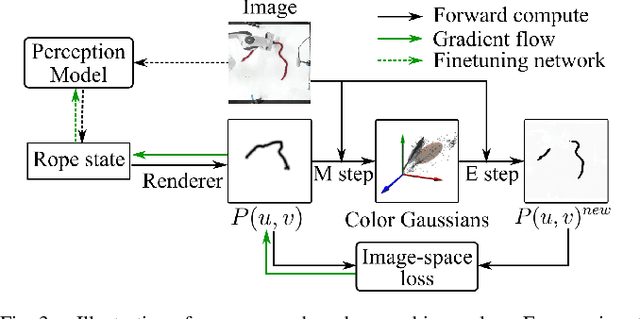
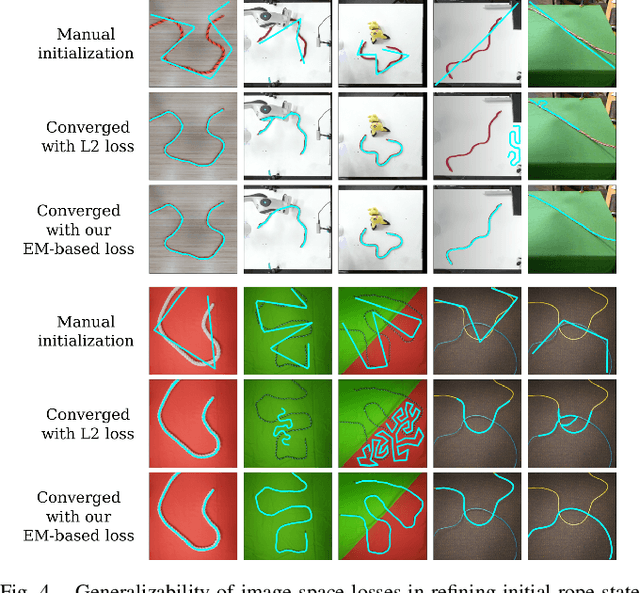
We demonstrate model-based, visual robot manipulation of linear deformable objects. Our approach is based on a state-space representation of the physical system that the robot aims to control. This choice has multiple advantages, including the ease of incorporating physical priors in the dynamics model and perception model, and the ease of planning manipulation actions. In addition, physical states can naturally represent object instances of different appearances. Therefore, dynamics in the state space can be learned in one setting and directly used in other visually different settings. This is in contrast to dynamics learned in pixel space or latent space, where generalization to visual differences are not guaranteed. Challenges in taking the state-space approach are the estimation of the high-dimensional state of a deformable object from raw images, where annotations are very expensive on real data, and finding a dynamics model that is both accurate, generalizable, and efficient to compute. We are the first to demonstrate self-supervised training of rope state estimation on real images, without requiring expensive annotations. This is achieved by our novel differentiable renderer and image loss, which are generalizable across a wide range of visual appearances. With estimated rope states, we train a fast and differentiable neural network dynamics model that encodes the physics of mass-spring systems. Our method has a higher accuracy in predicting future states compared to models that do not involve explicit state estimation and do not use any physics prior. We also show that our approach achieves more efficient manipulation, both in simulation and on a real robot, when used within a model predictive controller.
Object-Centric Task and Motion Planning in Dynamic Environments
Nov 12, 2019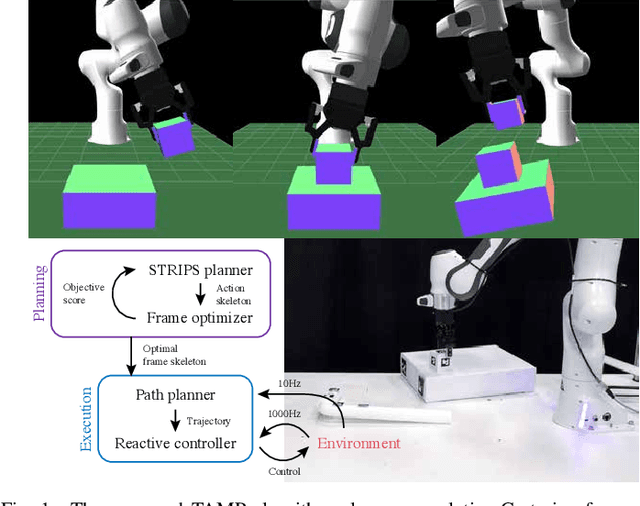
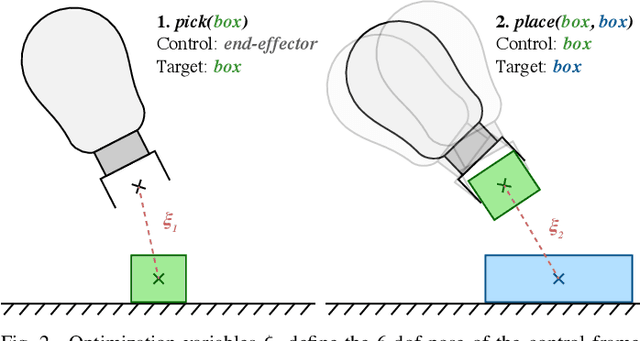
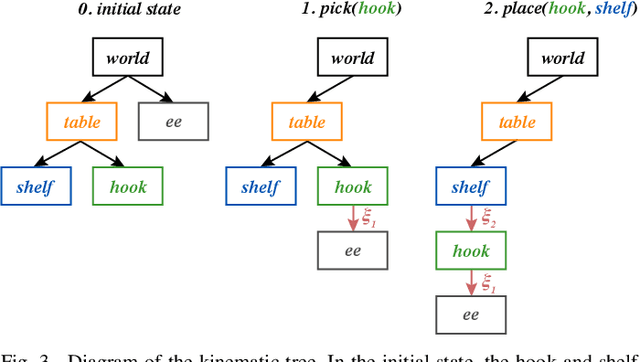
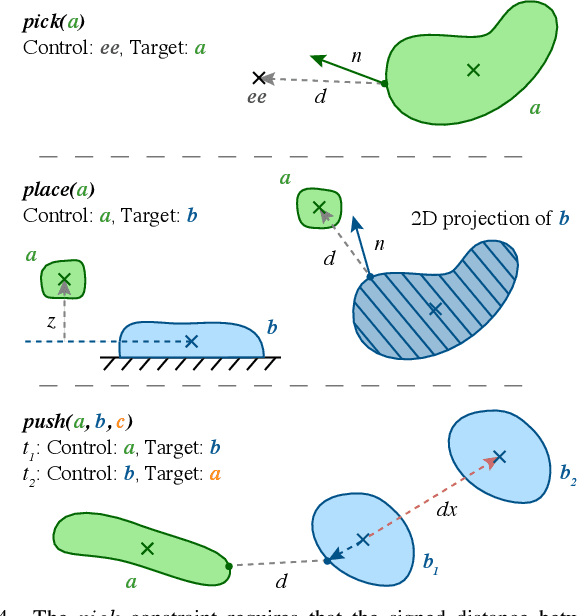
We address the problem of applying Task and Motion Planning (TAMP) in real world environments. TAMP combines symbolic and geometric reasoning to produce sequential manipulation plans, typically specified as joint-space trajectories, which are valid only as long as the environment is static and perception and control are highly accurate. In case of any changes in the environment, slow re-planning is required. We propose a TAMP algorithm that optimizes over Cartesian frames defined relative to target objects. The resulting plan then remains valid even if the objects are moving and can be executed by reactive controllers that adapt to these changes in real time. We apply our TAMP framework to a torque-controlled robot in a pick and place setting and demonstrate its ability to adapt to changing environments, inaccurate perception, and imprecise control, both in simulation and the real world.
Accurate Vision-based Manipulation through Contact Reasoning
Nov 08, 2019
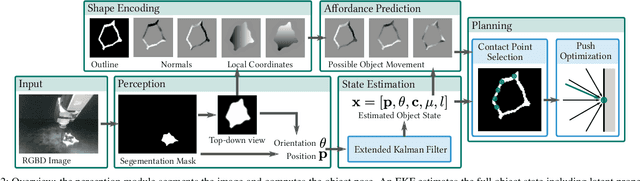
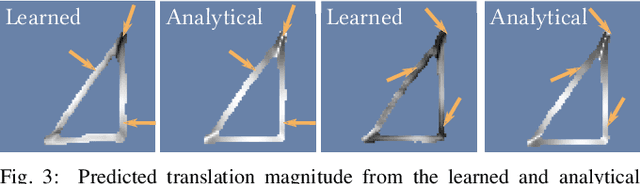
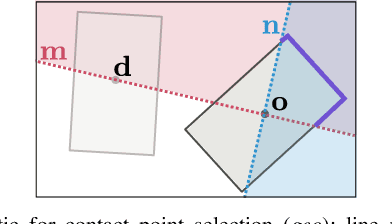
Planning contact interactions is one of the core challenges of many robotic tasks. Optimizing contact locations while taking dynamics into account is computationally costly and in only partially observed environments, executing contact-based tasks often suffers from low accuracy. We present an approach that addresses these two challenges for the problem of vision-based manipulation. First, we propose to disentangle contact from motion optimization. Thereby, we improve planning efficiency by focusing computation on promising contact locations. Second, we use a hybrid approach for perception and state estimation that combines neural networks with a physically meaningful state representation. In simulation and real-world experiments on the task of planar pushing, we show that our method is more efficient and achieves a higher manipulation accuracy than previous vision-based approaches.
Learning to Scaffold the Development of Robotic Manipulation Skills
Nov 03, 2019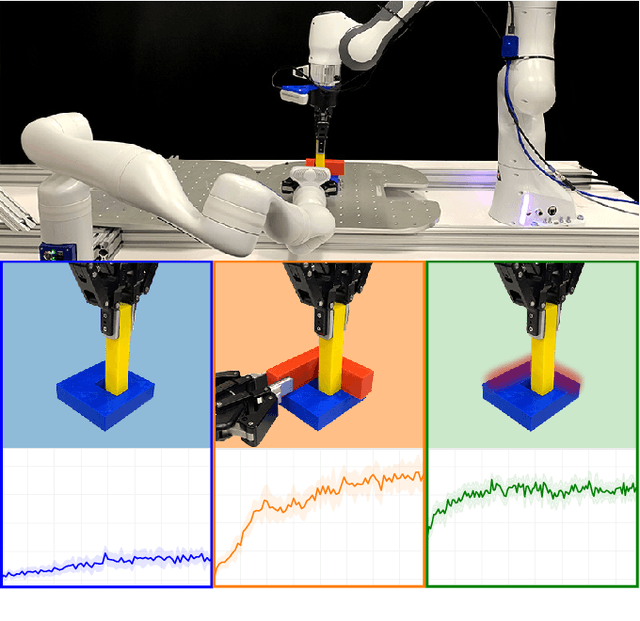
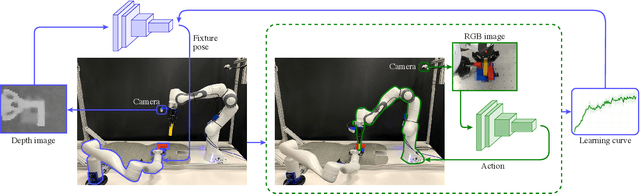
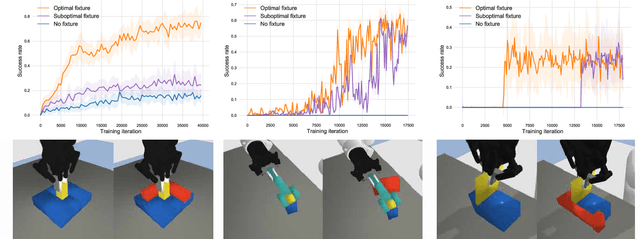
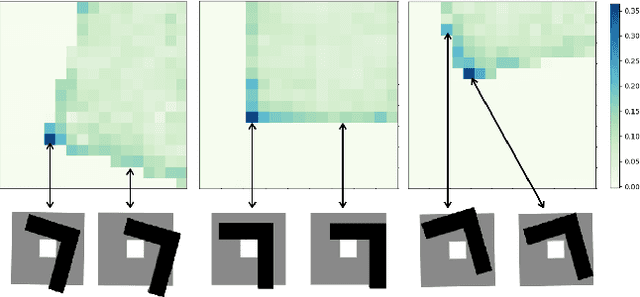
Learning contact-rich, robotic manipulation skills is a challenging problem due to the high-dimensionality of the state and action space as well as uncertainty from noisy sensors and inaccurate motor control. To combat these factors and achieve more robust manipulation, humans actively exploit contact constraints in the environment. By adopting a similar strategy, robots can also achieve more robust manipulation. In this paper, we enable a robot to autonomously modify its environment and thereby discover how to ease manipulation skill learning. Specifically, we provide the robot with fixtures that it can freely place within the environment. These fixtures provide hard constraints that limit the outcome of robot actions. Thereby, they funnel uncertainty from perception and motor control and scaffold manipulation skill learning. We propose a learning system that consists of two learning loops. In the outer loop, the robot positions the fixture in the workspace. In the inner loop, the robot learns a manipulation skill and after a fixed number of episodes, returns the reward to the outer loop. Thereby, the robot is incentivised to place the fixture such that the inner loop quickly achieves a high reward. We demonstrate our framework both in simulation and in the real world on three tasks: peg insertion, wrench manipulation and shallow-depth insertion. We show that manipulation skill learning is dramatically sped up through this way of scaffolding.
Learning from My Partner's Actions: Roles in Decentralized Robot Teams
Oct 28, 2019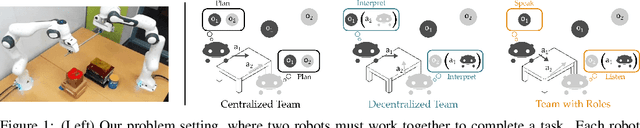

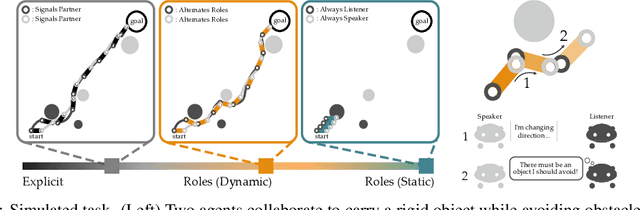

When teams of robots collaborate to complete a task, communication is often necessary. Like humans, robot teammates should implicitly communicate through their actions: but interpreting our partner's actions is typically difficult, since a given action may have many different underlying reasons. Here we propose an alternate approach: instead of not being able to infer whether an action is due to exploration, exploitation, or communication, we define separate roles for each agent. Because each role defines a distinct reason for acting (e.g., only exploit, only communicate), teammates now correctly interpret the meaning behind their partner's actions. Our results suggest that leveraging and alternating roles leads to performance comparable to teams that explicitly exchange messages. You can find more images and videos of our experimental setups at http://ai.stanford.edu/blog/learning-from-partners/.
Learning Task-Oriented Grasping from Human Activity Datasets
Oct 25, 2019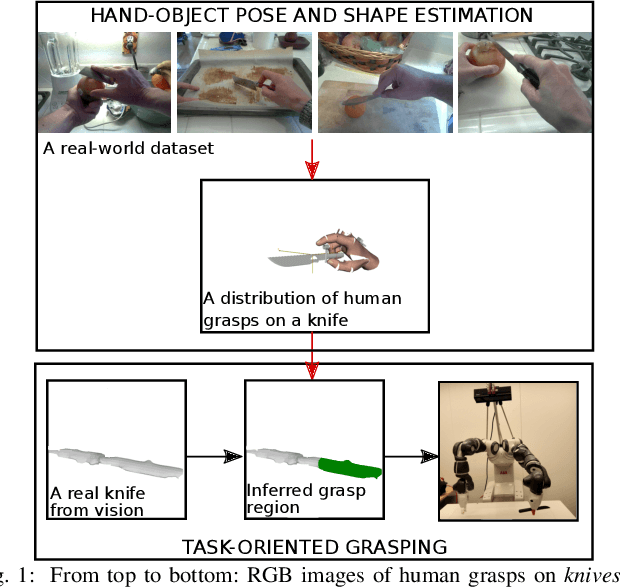
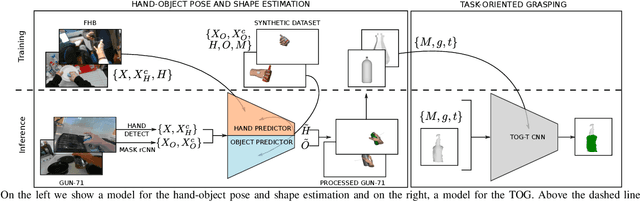
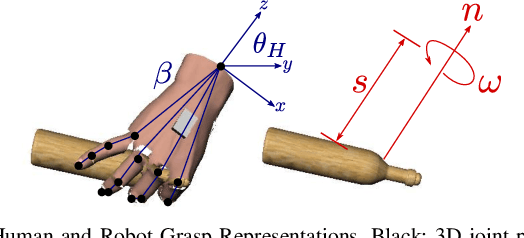
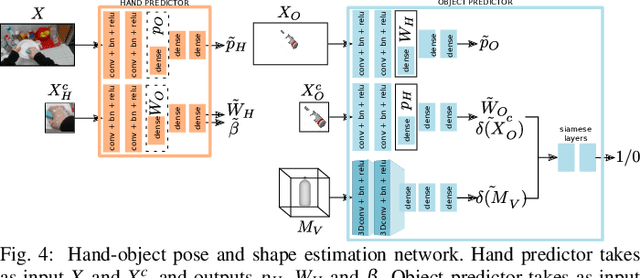
We propose to leverage a real-world, human activity RGB datasets to teach a robot {\em Task-Oriented Grasping} (TOG). On the one hand, RGB-D datasets that contain hands and objects in interaction often lack annotations due to the manual effort in obtaining them. On the other hand, RGB datasets are often annotated with labels that do not provide enough information to infer a 6D robotic grasp pose. However, they contain examples of grasps on a variety of objects for many different tasks. Thereby, they provide a much richer source of supervision than RGB-D datasets. We propose a model that takes as input an RGB image and outputs a hand pose and configuration as well as an object pose and a shape. We follow the insight that jointly estimating hand and object poses increases accuracy compared to estimating these quantities independently of each other. Quantitative experiments show that training an object pose predictor with the hand pose information (and vice versa) is better than training without this information. Given the trained model, we process an RGB dataset to automatically obtain training data for a TOG model. This model takes as input an object point cloud and a task and outputs a suitable region for grasping, given the task. Qualitative experiments show that our model can successfully process a real-world dataset. Experiments with a robot demonstrate that this data allows a robot to learn task-oriented grasping on novel objects.