 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing Change Detection via Weak Temporal Supervision
Jan 05, 2026Semantic change detection in remote sensing aims to identify land cover changes between bi-temporal image pairs. Progress in this area has been limited by the scarcity of annotated datasets, as pixel-level annotation is costly and time-consuming. To address this, recent methods leverage synthetic data or generate artificial change pairs, but out-of-domain generalization remains limited. In this work, we introduce a weak temporal supervision strategy that leverages additional temporal observations of existing single-temporal datasets, without requiring any new annotations. Specifically, we extend single-date remote sensing datasets with new observations acquired at different times and train a change detection model by assuming that real bi-temporal pairs mostly contain no change, while pairing images from different locations to generate change examples. To handle the inherent noise in these weak labels, we employ an object-aware change map generation and an iterative refinement process. We validate our approach on extended versions of the FLAIR and IAILD aerial datasets, achieving strong zero-shot and low-data regime performance across different benchmarks. Lastly, we showcase results over large areas in France, highlighting the scalability potential of our method.
LamiGauss: Pitching Radiative Gaussian for Sparse-View X-ray Laminography Reconstruction
Sep 17, 2025
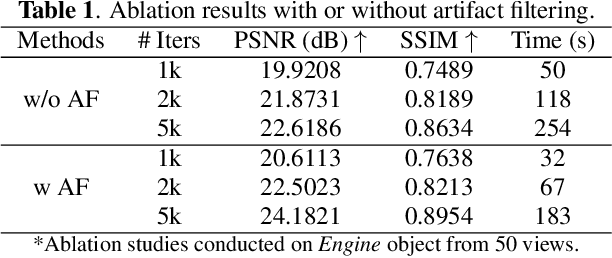


X-ray Computed Laminography (CL) is essential for non-destructive inspection of plate-like structures in applications such as microchips and composite battery materials, where traditional computed tomography (CT) struggles due to geometric constraints. However, reconstructing high-quality volumes from laminographic projections remains challenging, particularly under highly sparse-view acquisition conditions. In this paper, we propose a reconstruction algorithm, namely LamiGauss, that combines Gaussian Splatting radiative rasterization with a dedicated detector-to-world transformation model incorporating the laminographic tilt angle. LamiGauss leverages an initialization strategy that explicitly filters out common laminographic artifacts from the preliminary reconstruction, preventing redundant Gaussians from being allocated to false structures and thereby concentrating model capacity on representing the genuine object. Our approach effectively optimizes directly from sparse projections, enabling accurate and efficient reconstruction with limited data. Extensive experiments on both synthetic and real datasets demonstrate the effectiveness and superiority of the proposed method over existing techniques. LamiGauss uses only 3$\%$ of full views to achieve superior performance over the iterative method optimized on a full dataset.
From Orthomosaics to Raw UAV Imagery: Enhancing Palm Detection and Crown-Center Localization
Sep 15, 2025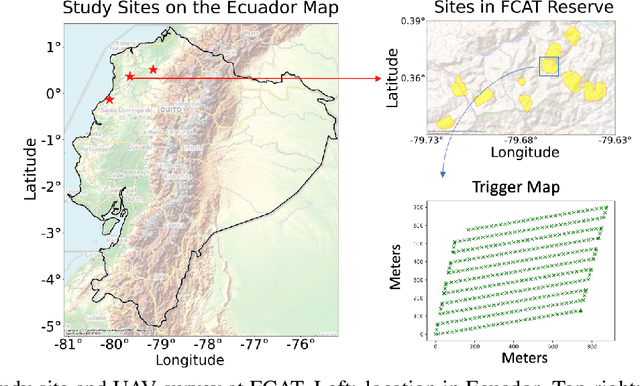
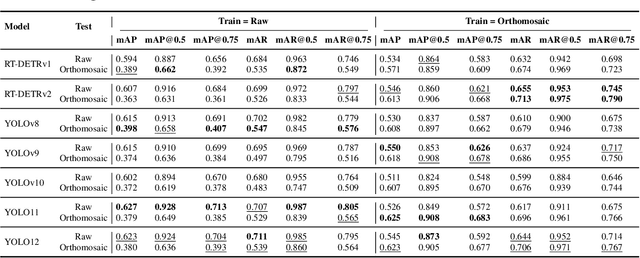
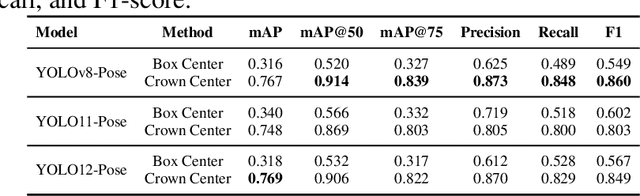

Accurate mapping of individual trees is essential for ecological monitoring and forest management. Orthomosaic imagery from unmanned aerial vehicles (UAVs) is widely used, but stitching artifacts and heavy preprocessing limit its suitability for field deployment. This study explores the use of raw UAV imagery for palm detection and crown-center localization in tropical forests. Two research questions are addressed: (1) how detection performance varies across orthomosaic and raw imagery, including within-domain and cross-domain transfer, and (2) to what extent crown-center annotations improve localization accuracy beyond bounding-box centroids. Using state-of-the-art detectors and keypoint models, we show that raw imagery yields superior performance in deployment-relevant scenarios, while orthomosaics retain value for robust cross-domain generalization. Incorporating crown-center annotations in training further improves localization and provides precise tree positions for downstream ecological analyses. These findings offer practical guidance for UAV-based biodiversity and conservation monitoring.
Improving OCR using internal document redundancy
Aug 20, 2025Current OCR systems are based on deep learning models trained on large amounts of data. Although they have shown some ability to generalize to unseen data, especially in detection tasks, they can struggle with recognizing low-quality data. This is particularly evident for printed documents, where intra-domain data variability is typically low, but inter-domain data variability is high. In that context, current OCR methods do not fully exploit each document's redundancy. We propose an unsupervised method by leveraging the redundancy of character shapes within a document to correct imperfect outputs of a given OCR system and suggest better clustering. To this aim, we introduce an extended Gaussian Mixture Model (GMM) by alternating an Expectation-Maximization (EM) algorithm with an intra-cluster realignment process and normality statistical testing. We demonstrate improvements in documents with various levels of degradation, including recovered Uruguayan military archives and 17th to mid-20th century European newspapers.
An Active Contour Model for Silhouette Vectorization using Bézier Curves
May 08, 2025In this paper, we propose an active contour model for silhouette vectorization using cubic B\'ezier curves. Among the end points of the B\'ezier curves, we distinguish between corner and regular points where the orientation of the tangent vector is prescribed. By minimizing the distance of the B\'ezier curves to the silhouette boundary, the active contour model optimizes the location of the B\'ezier curves end points, the orientation of the tangent vectors in the regular points, and the estimation of the B\'ezier curve parameters. This active contour model can use the silhouette vectorization obtained by any method as an initial guess. The proposed method significantly reduces the average distance between the silhouette boundary and its vectorization obtained by the world-class graphic software Inkscape, Adobe Illustrator, and a curvature-based vectorization method, which we introduce for comparison. Our method also allows us to impose additional regularity on the B\'ezier curves by reducing their lengths.
Detection and Geographic Localization of Natural Objects in the Wild: A Case Study on Palms
Feb 18, 2025



Palms are ecologically and economically indicators of tropical forest health, biodiversity, and human impact that support local economies and global forest product supply chains. While palm detection in plantations is well-studied, efforts to map naturally occurring palms in dense forests remain limited by overlapping crowns, uneven shading, and heterogeneous landscapes. We develop PRISM (Processing, Inference, Segmentation, and Mapping), a flexible pipeline for detecting and localizing palms in dense tropical forests using large orthomosaic images. Orthomosaics are created from thousands of aerial images and spanning several to hundreds of gigabytes. Our contributions are threefold. First, we construct a large UAV-derived orthomosaic dataset collected across 21 ecologically diverse sites in western Ecuador, annotated with 8,830 bounding boxes and 5,026 palm center points. Second, we evaluate multiple state-of-the-art object detectors based on efficiency and performance, integrating zero-shot SAM 2 as the segmentation backbone, and refining the results for precise geographic mapping. Third, we apply calibration methods to align confidence scores with IoU and explore saliency maps for feature explainability. Though optimized for palms, PRISM is adaptable for identifying other natural objects, such as eastern white pines. Future work will explore transfer learning for lower-resolution datasets (0.5 to 1m).
SGSST: Scaling Gaussian Splatting StyleTransfer
Dec 04, 2024



Applying style transfer to a full 3D environment is a challenging task that has seen many developments since the advent of neural rendering. 3D Gaussian splatting (3DGS) has recently pushed further many limits of neural rendering in terms of training speed and reconstruction quality. This work introduces SGSST: Scaling Gaussian Splatting Style Transfer, an optimization-based method to apply style transfer to pretrained 3DGS scenes. We demonstrate that a new multiscale loss based on global neural statistics, that we name SOS for Simultaneously Optimized Scales, enables style transfer to ultra-high resolution 3D scenes. Not only SGSST pioneers 3D scene style transfer at such high image resolutions, it also produces superior visual quality as assessed by thorough qualitative, quantitative and perceptual comparisons.
Structure Tensor Representation for Robust Oriented Object Detection
Nov 15, 2024



Oriented object detection predicts orientation in addition to object location and bounding box. Precisely predicting orientation remains challenging due to angular periodicity, which introduces boundary discontinuity issues and symmetry ambiguities. Inspired by classical works on edge and corner detection, this paper proposes to represent orientation in oriented bounding boxes as a structure tensor. This representation combines the strengths of Gaussian-based methods and angle-coder solutions, providing a simple yet efficient approach that is robust to angular periodicity issues without additional hyperparameters. Extensive evaluations across five datasets demonstrate that the proposed structure tensor representation outperforms previous methods in both fully-supervised and weakly supervised tasks, achieving high precision in angular prediction with minimal computational overhead. Thus, this work establishes structure tensors as a robust and modular alternative for encoding orientation in oriented object detection. We make our code publicly available, allowing for seamless integration into existing object detectors.
Bilateral Signal Warping for Left Ventricular Hypertrophy Diagnosis
Nov 13, 2024



Left Ventricular Hypertrophy (LVH) is a major cardiovascular risk factor, linked to heart failure, arrhythmia, and sudden cardiac death, often resulting from chronic stress like hypertension. Electrocardiography (ECG), while varying in sensitivity, is widely accessible and cost-effective for detecting LVH-related morphological changes. This work introduces a bilateral signal warping (BSW) approach to improve ECG-based LVH diagnosis. Our method creates a library of heartbeat prototypes from patients with consistent ECG patterns. After preprocessing to eliminate baseline wander and detect R peaks, we apply BSW to cluster heartbeats, generating prototypes for both normal and LVH classes. We compare each new record to these references to support diagnosis. Experimental results show promising potential for practical application in clinical settings.
Efficient single image non-uniformity correction algorithm
Nov 07, 2024This paper introduces a new way to correct the non-uniformity (NU) in uncooled infrared-type images. The main defect of these uncooled images is the lack of a column (resp. line) time-dependent cross-calibration, resulting in a strong column (resp. line) and time dependent noise. This problem can be considered as a 1D flicker of the columns inside each frame. Thus, classic movie deflickering algorithms can be adapted, to equalize the columns (resp. the lines). The proposed method therefore applies to the series formed by the columns of an infrared image a movie deflickering algorithm. The obtained single image method works on static images, and therefore requires no registration, no camera motion compensation, and no closed aperture sensor equalization. Thus, the method has only one camera dependent parameter, and is landscape independent. This simple method will be compared to a state of the art total variation single image correction on raw real and simulated images. The method is real time, requiring only two operations per pixel. It involves no test-pattern calibration and produces no "ghost artifacts".
* arXiv admin note: substantial text overlap with arXiv:2411.03615