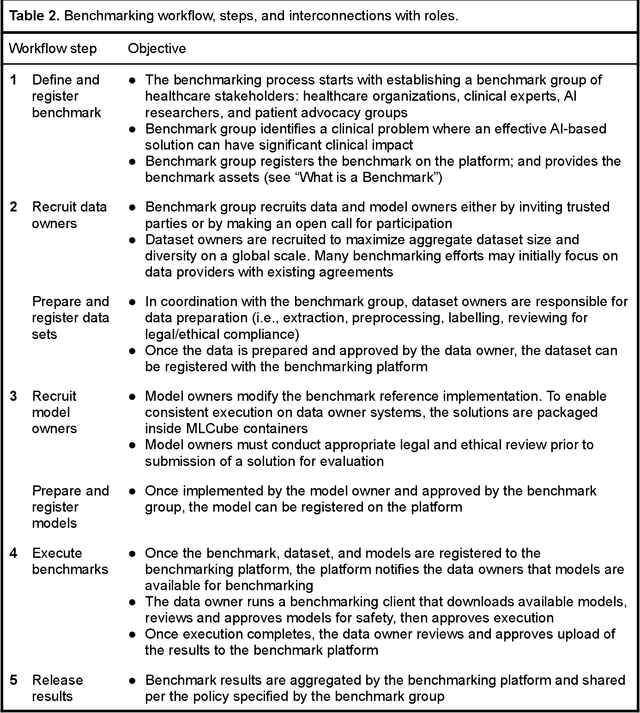
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Knowledge-Augmented Meta-Learning for Few-Shot Classification
Jul 25, 2022
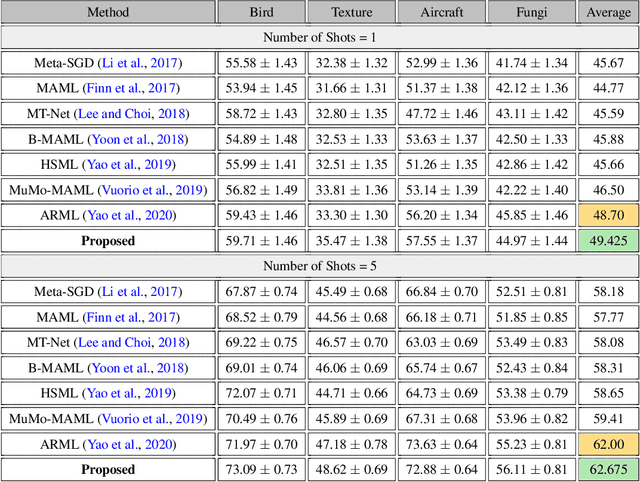
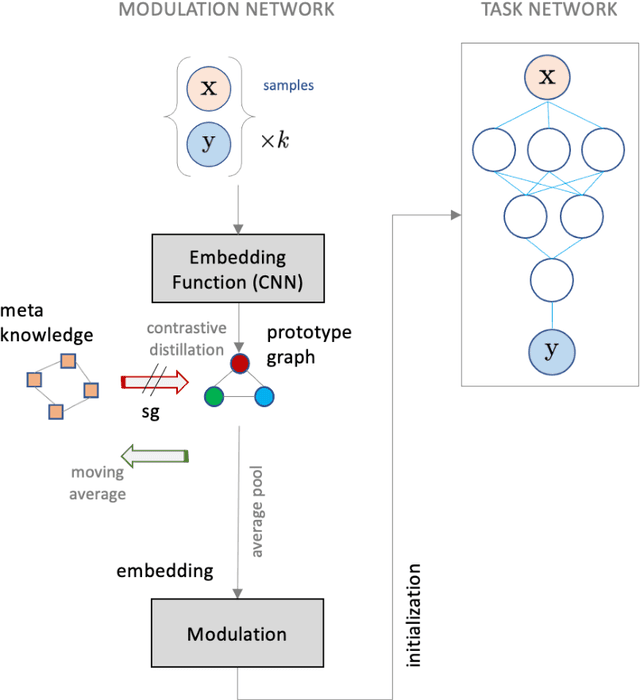
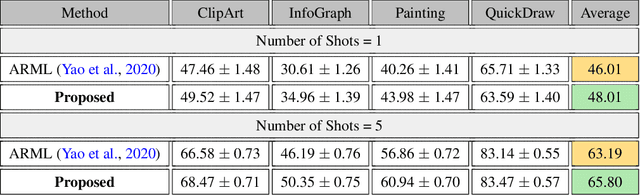
Model agnostic meta-learning algorithms aim to infer priors from several observed tasks that can then be used to adapt to a new task with few examples. Given the inherent diversity of tasks arising in existing benchmarks, recent methods use separate, learnable structure, such as hierarchies or graphs, for enabling task-specific adaptation of the prior. While these approaches have produced significantly better meta learners, our goal is to improve their performance when the heterogeneous task distribution contains challenging distribution shifts and semantic disparities. To this end, we introduce CAML (Contrastive Knowledge-Augmented Meta Learning), a novel approach for knowledge-enhanced few-shot learning that evolves a knowledge graph to effectively encode historical experience, and employs a contrastive distillation strategy to leverage the encoded knowledge for task-aware modulation of the base learner. Using standard benchmarks, we evaluate the performance of CAML in different few-shot learning scenarios. In addition to the standard few-shot task adaptation, we also consider the more challenging multi-domain task adaptation and few-shot dataset generalization settings in our empirical studies. Our results shows that CAML consistently outperforms best known approaches and achieves improved generalization.
Single Model Uncertainty Estimation via Stochastic Data Centering
Jul 14, 2022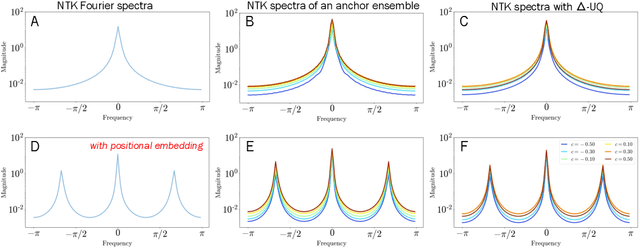
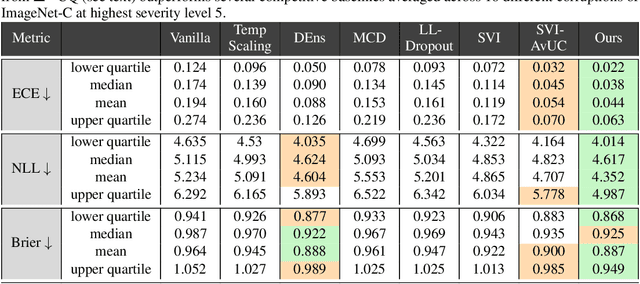

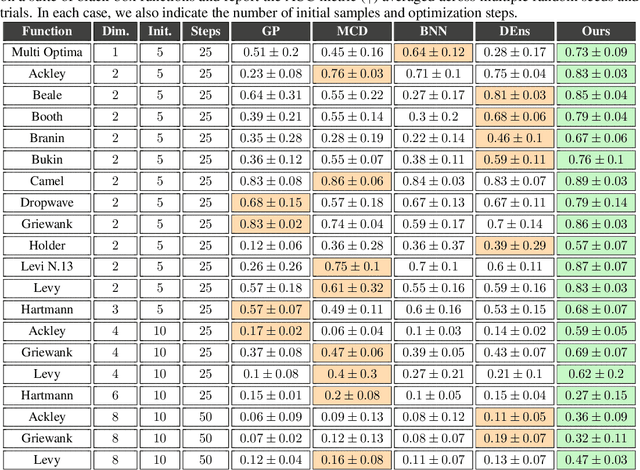
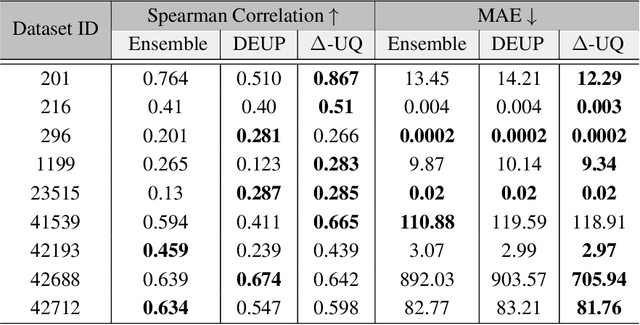
We are interested in estimating the uncertainties of deep neural networks, which play an important role in many scientific and engineering problems. In this paper, we present a striking new finding that an ensemble of neural networks with the same weight initialization, trained on datasets that are shifted by a constant bias gives rise to slightly inconsistent trained models, where the differences in predictions are a strong indicator of epistemic uncertainties. Using the neural tangent kernel (NTK), we demonstrate that this phenomena occurs in part because the NTK is not shift-invariant. Since this is achieved via a trivial input transformation, we show that it can therefore be approximated using just a single neural network -- using a technique that we call $\Delta-$UQ -- that estimates uncertainty around prediction by marginalizing out the effect of the biases. We show that $\Delta-$UQ's uncertainty estimates are superior to many of the current methods on a variety of benchmarks -- outlier rejection, calibration under distribution shift, and sequential design optimization of black box functions.
Revisiting Inlier and Outlier Specification for Improved Out-of-Distribution Detection
Jul 12, 2022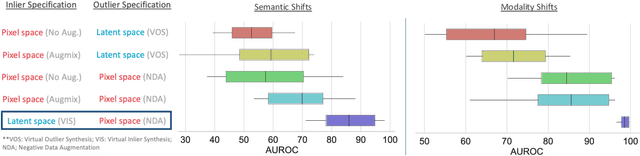
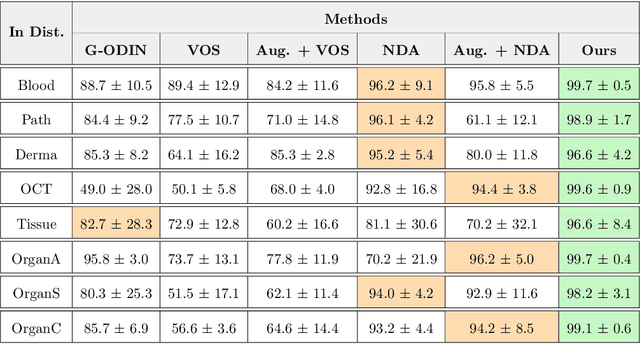
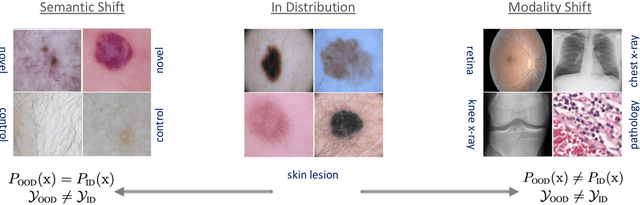
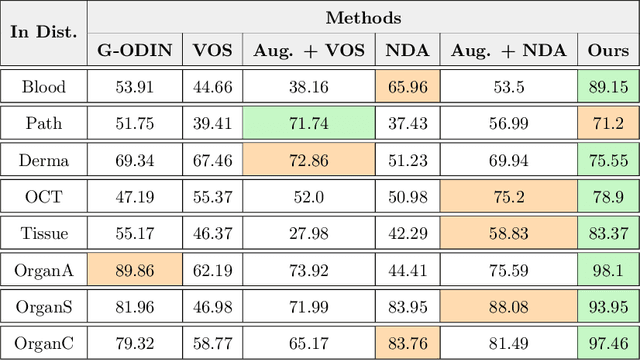
Accurately detecting out-of-distribution (OOD) data with varying levels of semantic and covariate shifts with respect to the in-distribution (ID) data is critical for deployment of safe and reliable models. This is particularly the case when dealing with highly consequential applications (e.g. medical imaging, self-driving cars, etc). The goal is to design a detector that can accept meaningful variations of the ID data, while also rejecting examples from OOD regimes. In practice, this dual objective can be realized by enforcing consistency using an appropriate scoring function (e.g., energy) and calibrating the detector to reject a curated set of OOD data (referred to as outlier exposure or shortly OE). While OE methods are widely adopted, assembling representative OOD datasets is both costly and challenging due to the unpredictability of real-world scenarios, hence the recent trend of designing OE-free detectors. In this paper, we make a surprising finding that controlled generalization to ID variations and exposure to diverse (synthetic) outlier examples are essential to simultaneously improving semantic and modality shift detection. In contrast to existing methods, our approach samples inliers in the latent space, and constructs outlier examples via negative data augmentation. Through a rigorous empirical study on medical imaging benchmarks (MedMNIST, ISIC2019 and NCT), we demonstrate significant performance gains ($15\% - 35\%$ in AUROC) over existing OE-free, OOD detection approaches under both semantic and modality shifts.
Domain Alignment Meets Fully Test-Time Adaptation
Jul 09, 2022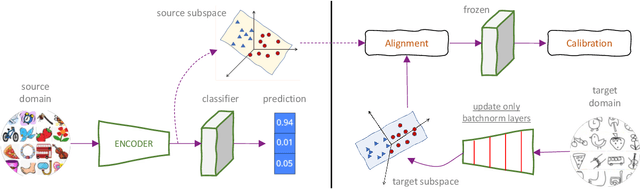

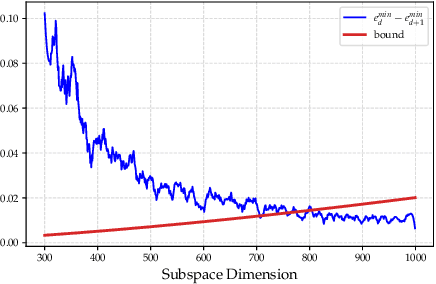
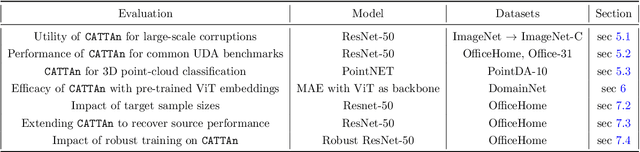
A foundational requirement of a deployed ML model is to generalize to data drawn from a testing distribution that is different from training. A popular solution to this problem is to adapt a pre-trained model to novel domains using only unlabeled data. In this paper, we focus on a challenging variant of this problem, where access to the original source data is restricted. While fully test-time adaptation (FTTA) and unsupervised domain adaptation (UDA) are closely related, the advances in UDA are not readily applicable to TTA, since most UDA methods require access to the source data. Hence, we propose a new approach, CATTAn, that bridges UDA and FTTA, by relaxing the need to access entire source data, through a novel deep subspace alignment strategy. With a minimal overhead of storing the subspace basis set for the source data, CATTAn enables unsupervised alignment between source and target data during adaptation. Through extensive experimental evaluation on multiple 2D and 3D vision benchmarks (ImageNet-C, Office-31, OfficeHome, DomainNet, PointDA-10) and model architectures, we demonstrate significant gains in FTTA performance. Furthermore, we make a number of crucial findings on the utility of the alignment objective even with inherently robust models, pre-trained ViT representations and under low sample availability in the target domain.
Out of Distribution Detection via Neural Network Anchoring
Jul 08, 2022
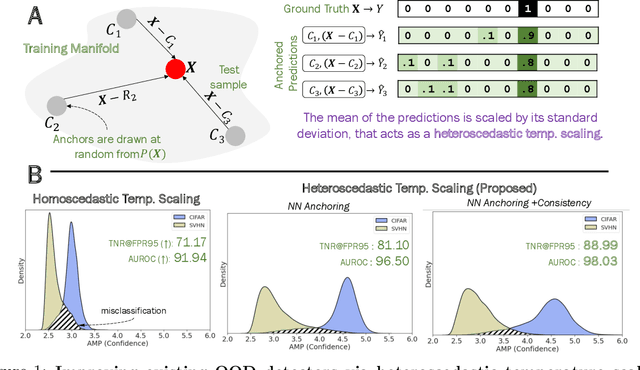

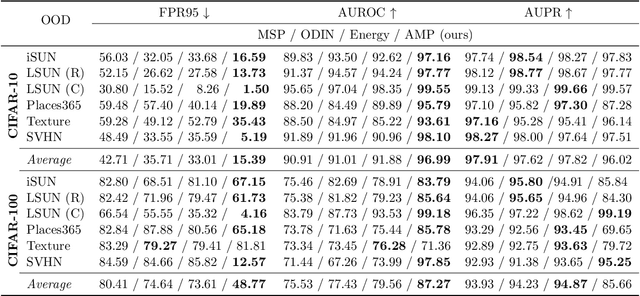
Our goal in this paper is to exploit heteroscedastic temperature scaling as a calibration strategy for out of distribution (OOD) detection. Heteroscedasticity here refers to the fact that the optimal temperature parameter for each sample can be different, as opposed to conventional approaches that use the same value for the entire distribution. To enable this, we propose a new training strategy called anchoring that can estimate appropriate temperature values for each sample, leading to state-of-the-art OOD detection performance across several benchmarks. Using NTK theory, we show that this temperature function estimate is closely linked to the epistemic uncertainty of the classifier, which explains its behavior. In contrast to some of the best-performing OOD detection approaches, our method does not require exposure to additional outlier datasets, custom calibration objectives, or model ensembling. Through empirical studies with different OOD detection settings -- far OOD, near OOD, and semantically coherent OOD - we establish a highly effective OOD detection approach. Code and models can be accessed here -- https://github.com/rushilanirudh/AMP
Improving Diversity with Adversarially Learned Transformations for Domain Generalization
Jun 15, 2022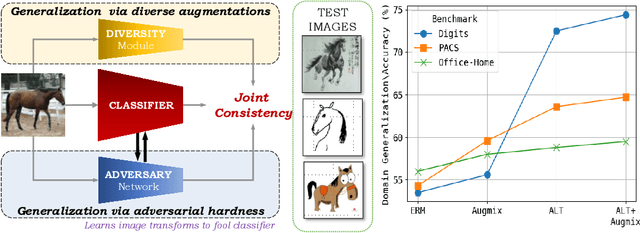
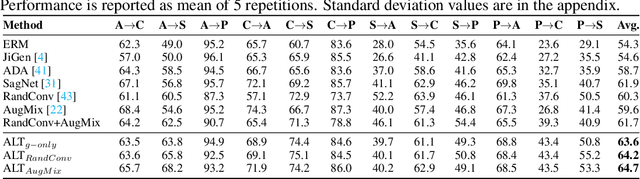
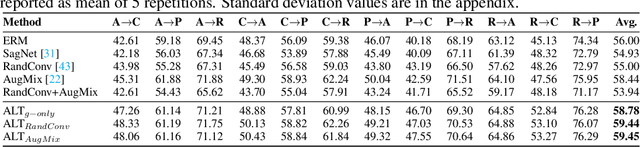
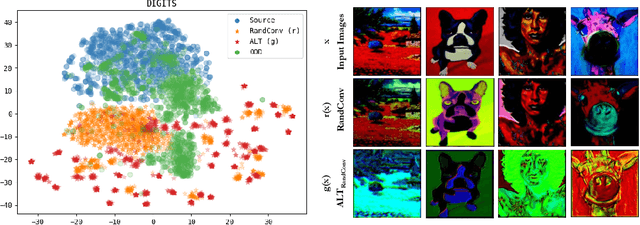
To be successful in single source domain generalization, maximizing diversity of synthesized domains has emerged as one of the most effective strategies. Many of the recent successes have come from methods that pre-specify the types of diversity that a model is exposed to during training, so that it can ultimately generalize well to new domains. However, na\"ive diversity based augmentations do not work effectively for domain generalization either because they cannot model large domain shift, or because the span of transforms that are pre-specified do not cover the types of shift commonly occurring in domain generalization. To address this issue, we present a novel framework that uses adversarially learned transformations (ALT) using a neural network to model plausible, yet hard image transformations that fool the classifier. This network is randomly initialized for each batch and trained for a fixed number of steps to maximize classification error. Further, we enforce consistency between the classifier's predictions on the clean and transformed images. With extensive empirical analysis, we find that this new form of adversarial transformations achieve both objectives of diversity and hardness simultaneously, outperforming all existing techniques on competitive benchmarks for single source domain generalization. We also show that ALT can naturally work with existing diversity modules to produce highly distinct, and large transformations of the source domain leading to state-of-the-art performance.
Improving Multi-Domain Generalization through Domain Re-labeling
Dec 17, 2021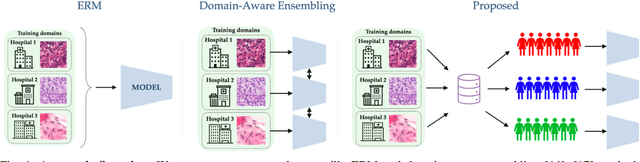
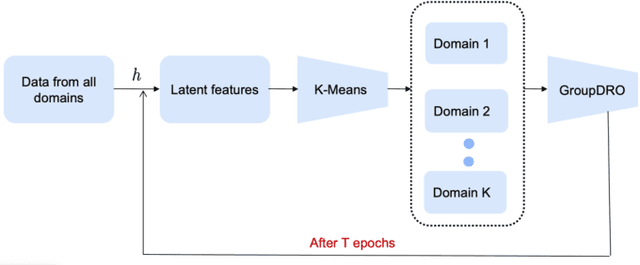
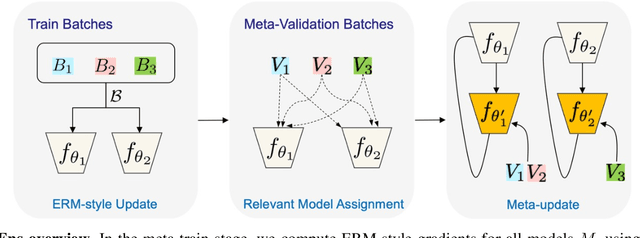
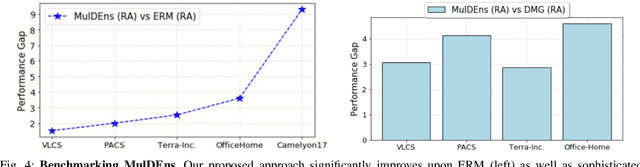
Domain generalization (DG) methods aim to develop models that generalize to settings where the test distribution is different from the training data. In this paper, we focus on the challenging problem of multi-source zero-shot DG, where labeled training data from multiple source domains is available but with no access to data from the target domain. Though this problem has become an important topic of research, surprisingly, the simple solution of pooling all source data together and training a single classifier is highly competitive on standard benchmarks. More importantly, even sophisticated approaches that explicitly optimize for invariance across different domains do not necessarily provide non-trivial gains over ERM. In this paper, for the first time, we study the important link between pre-specified domain labels and the generalization performance. Using a motivating case-study and a new variant of a distributional robust optimization algorithm, GroupDRO++, we first demonstrate how inferring custom domain groups can lead to consistent improvements over the original domain labels that come with the dataset. Subsequently, we introduce a general approach for multi-domain generalization, MulDEns, that uses an ERM-based deep ensembling backbone and performs implicit domain re-labeling through a meta-optimization algorithm. Using empirical studies on multiple standard benchmarks, we show that MulDEns does not require tailoring the augmentation strategy or the training process specific to a dataset, consistently outperforms ERM by significant margins, and produces state-of-the-art generalization performance, even when compared to existing methods that exploit the domain labels.
Geometric Priors for Scientific Generative Models in Inertial Confinement Fusion
Nov 24, 2021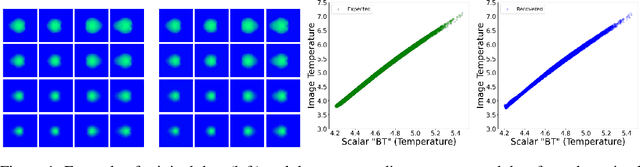
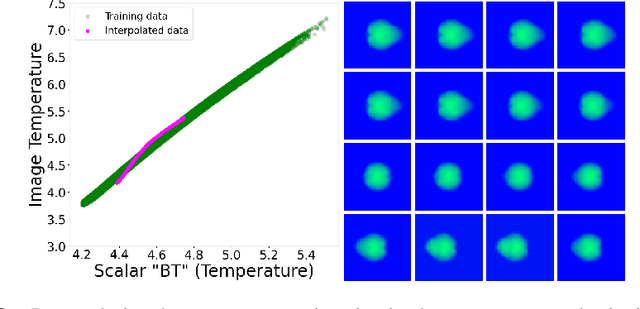

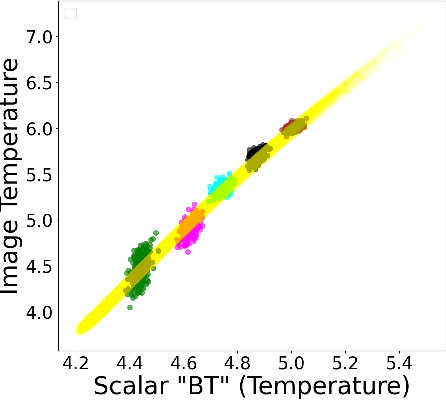
In this paper, we develop a Wasserstein autoencoder (WAE) with a hyperspherical prior for multimodal data in the application of inertial confinement fusion. Unlike a typical hyperspherical generative model that requires computationally inefficient sampling from distributions like the von Mis Fisher, we sample from a normal distribution followed by a projection layer before the generator. Finally, to determine the validity of the generated samples, we exploit a known relationship between the modalities in the dataset as a scientific constraint, and study different properties of the proposed model.
MedPerf: Open Benchmarking Platform for Medical Artificial Intelligence using Federated Evaluation
Oct 08, 2021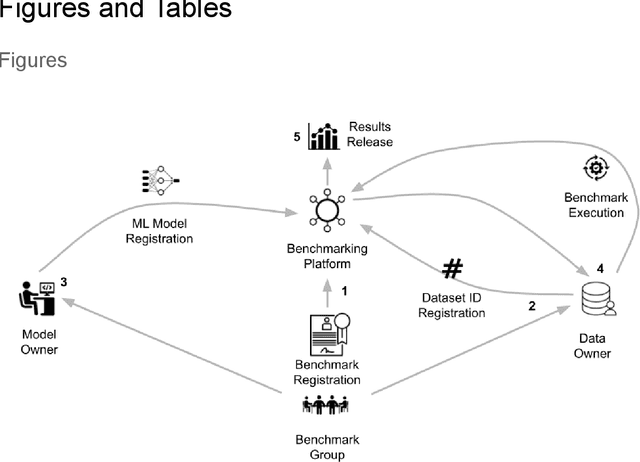
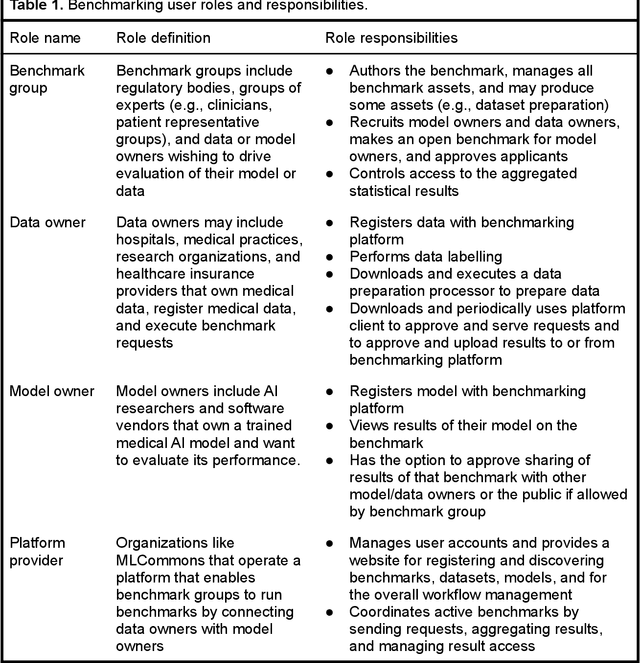
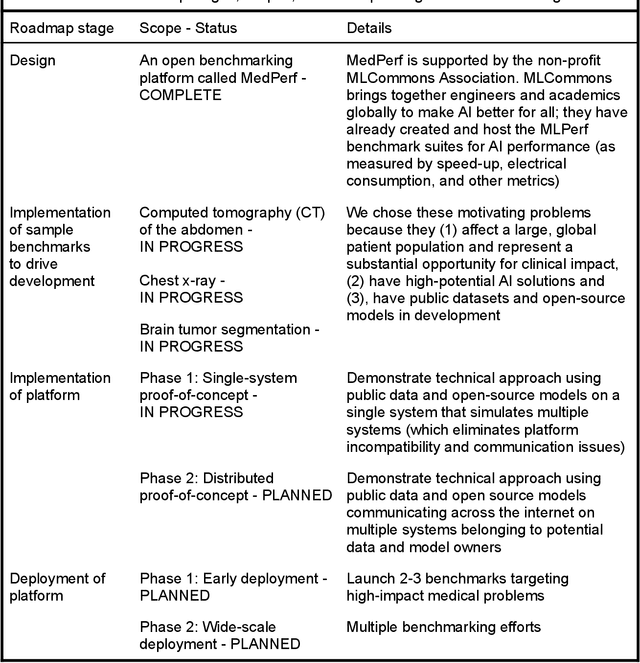
Medical AI has tremendous potential to advance healthcare by supporting the evidence-based practice of medicine, personalizing patient treatment, reducing costs, and improving provider and patient experience. We argue that unlocking this potential requires a systematic way to measure the performance of medical AI models on large-scale heterogeneous data. To meet this need, we are building MedPerf, an open framework for benchmarking machine learning in the medical domain. MedPerf will enable federated evaluation in which models are securely distributed to different facilities for evaluation, thereby empowering healthcare organizations to assess and verify the performance of AI models in an efficient and human-supervised process, while prioritizing privacy. We describe the current challenges healthcare and AI communities face, the need for an open platform, the design philosophy of MedPerf, its current implementation status, and our roadmap. We call for researchers and organizations to join us in creating the MedPerf open benchmarking platform.
$Δ$-UQ: Accurate Uncertainty Quantification via Anchor Marginalization
Oct 05, 2021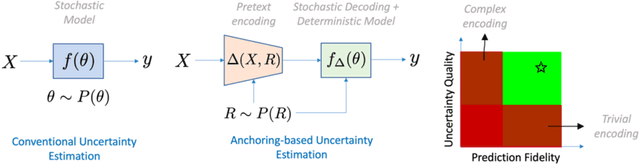
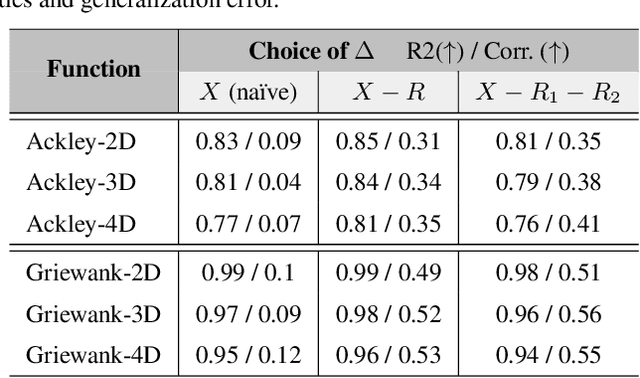
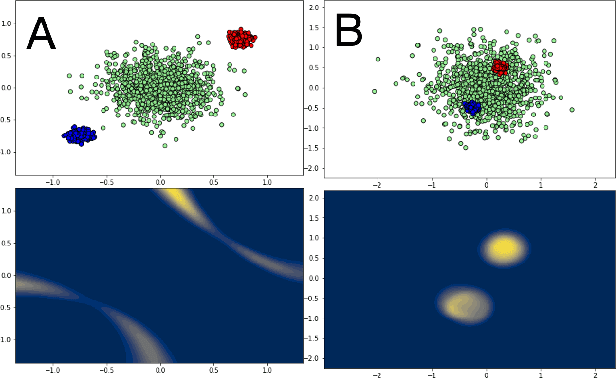
We present $\Delta$-UQ -- a novel, general-purpose uncertainty estimator using the concept of anchoring in predictive models. Anchoring works by first transforming the input into a tuple consisting of an anchor point drawn from a prior distribution, and a combination of the input sample with the anchor using a pretext encoding scheme. This encoding is such that the original input can be perfectly recovered from the tuple -- regardless of the choice of the anchor. Therefore, any predictive model should be able to predict the target response from the tuple alone (since it implicitly represents the input). Moreover, by varying the anchors for a fixed sample, we can estimate uncertainty in the prediction even using only a single predictive model. We find this uncertainty is deeply connected to improper sampling of the input data, and inherent noise, enabling us to estimate the total uncertainty in any system. With extensive empirical studies on a variety of use-cases, we demonstrate that $\Delta$-UQ outperforms several competitive baselines. Specifically, we study model fitting, sequential model optimization, model based inversion in the regression setting and out of distribution detection, & calibration under distribution shifts for classification.