 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph-Enhanced Zero-Shot Topic Classification: A Multi-Strategy Comparative Study
May 28, 2026Multi-label topic classification without labeled training data is a challenging task, specially when documents contain complex relational information. We present a zero-shot multi-label topic classification framework and systematically investigate how per-article knowledge graph augmentation affects its performance. The base framework classifies topics in documents without labeled training data and has four variants: article-only classification, keyword-enhanced classification, and self-consistency decoding variants of both. Then, we augment each base variant with per article knowledge graph. This graph is extracted from the input document through a pipeline similar to KGGen based on subject-predicate-object triples. We test all eight methods, four base and four graph augmented on fifteen LLMs and eight multi-label datasets across different domains. For the base framework, keyword-enhanced classification (AK) is the best performing method, and six out of fifteen LLMs surpass the sentence-encoder baseline. Graph augmentation has positive and negative impacts on small and large models, respectively. This shows that larger models already contain enough relational information from pretraining. Furthermore, the self-consistency decoding variant does not show performance improvements in any experiment while increasing computation costs about fivefold.
ConceptM$^3$oE: Concept-Guided Multimodal Mixture of Experts for Interpretable Computational Pathology
May 27, 2026Healthcare models are transitioning from unimodal prediction toward multimodal reasoning over heterogeneous diagnostic inputs. In computational pathology, for complex tumor subtypes where morphology alone can be challenging to distinguish, pathology reports and molecular measurements may provide additional diagnostic evidence alongside whole-slide images, yet existing models often fail to clarify how diverse signals assemble into recognizable diagnostic concepts. We propose ConceptM$^3$oE (Concept Multimodal MoE), which embeds concept formation directly within interaction-aware mixture-of-experts (MoE) pathways. The architecture decomposes evidence into modality-specific, redundant, and synergistic experts, which are then projected into structured concept bottlenecks mapping latent features to a hierarchy of morphology and biomarker concepts. To prevent the information loss typical of interpretable bottlenecks, we utilize residual pathways within each expert to allow task-relevant signals to flow both through the concepts and directly to the final task prediction, so that high performance is maintained alongside interpretability. Across an institutional pediatric brain tumor cohort and a public glioma cohort, the framework delivers competitive performance to unconstrained models while producing reasoning traces validated by an independent neuropathologist. In data-limited regimes, ConceptM$^3$oE improves limited-data performance, increasing macro-F1 from 56.41% to 66.70% at small training sizes compared to non-concept-informed baselines, while also showing faster training convergence consistent with the regularizing effect of concept learning. This work offers a scalable path toward high-performance medical AI that is inherently verifiable and better aligned with the complex decision-making of clinical practice.
Clinically-Informed Modeling for Pediatric Brain Tumor Classification from Whole-Slide Histopathology Images
Apr 22, 2026Accurate diagnosis of pediatric brain tumors, starting with histopathology, presents unique challenges for deep learning, including severe data scarcity, class imbalance, and fine-grained morphologic overlap across diagnostically distinct subtypes. While pathology foundation models have advanced patch-level representation learning, their effective adaptation to weakly supervised pediatric brain tumor classification under limited data remains underexplored. In this work, we introduce an expert-guided contrastive fine-tuning framework for pediatric brain tumor diagnosis from whole-slide images (WSI). Our approach integrates contrastive learning into slide-level multiple instance learning (MIL) to explicitly regularize the geometry of slide-level representations during downstream fine-tuning. We propose both a general supervised contrastive setting and an expert-guided variant that incorporates clinically informed hard negatives targeting diagnostically confusable subtypes. Through comprehensive experiments on pediatric brain tumor WSI classification under realistic low-sample and class-imbalanced conditions, we demonstrate that contrastive fine-tuning yields measurable improvements in fine-grained diagnostic distinctions. Our experimental analyses reveal complementary strengths across different contrastive strategies, with expert-guided hard negatives promoting more compact intra-class representations and improved inter-class separation. This work highlights the importance of explicitly shaping slide-level representations for robust fine-grained classification in data-scarce pediatric pathology settings.
PathMoE: Interpretable Multimodal Interaction Experts for Pediatric Brain Tumor Classification
Mar 02, 2026Accurate classification of pediatric central nervous system tumors remains challenging due to histological complexity and limited training data. While pathology foundation models have advanced whole-slide image (WSI) analysis, they often fail to leverage the rich, complementary information found in clinical text and tissue microarchitecture. To this end, we propose PathMoE, an interpretable multimodal framework that integrates H\&E slides, pathology reports, and nuclei-level cell graphs via an interaction-aware mixture-of-experts architecture built on state-of-the-art foundation models for each modality. By training specialized experts to capture modality uniqueness, redundancy, and synergy, PathMoE employs an input-dependent gating mechanism that dynamically weights these interactions, providing sample-level interpretability. We evaluate our framework on two dataset-specific classification tasks on an internal pediatric brain tumor dataset (PBT) and external TCGA datasets. PathMoE improves macro-F1 from 0.762 to 0.799 (+0.037) on PBT when integrating WSI, text, and graph modalities; on TCGA, augmenting WSI with graph knowledge improves macro-F1 from 0.668 to 0.709 (+0.041). These results demonstrate significant performance gains over state-of-the-art image-only baselines while revealing the specific modality interactions driving individual predictions. This interpretability is particularly critical for rare tumor subtypes, where transparent model reasoning is essential for clinical trust and diagnostic validation.
Ground Reaction Force Estimation via Time-aware Knowledge Distillation
Jun 12, 2025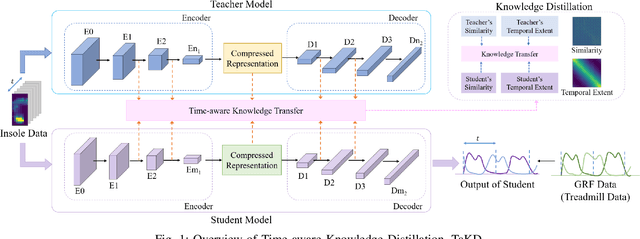



Human gait analysis with wearable sensors has been widely used in various applications, such as daily life healthcare, rehabilitation, physical therapy, and clinical diagnostics and monitoring. In particular, ground reaction force (GRF) provides critical information about how the body interacts with the ground during locomotion. Although instrumented treadmills have been widely used as the gold standard for measuring GRF during walking, their lack of portability and high cost make them impractical for many applications. As an alternative, low-cost, portable, wearable insole sensors have been utilized to measure GRF; however, these sensors are susceptible to noise and disturbance and are less accurate than treadmill measurements. To address these challenges, we propose a Time-aware Knowledge Distillation framework for GRF estimation from insole sensor data. This framework leverages similarity and temporal features within a mini-batch during the knowledge distillation process, effectively capturing the complementary relationships between features and the sequential properties of the target and input data. The performance of the lightweight models distilled through this framework was evaluated by comparing GRF estimations from insole sensor data against measurements from an instrumented treadmill. Empirical results demonstrated that Time-aware Knowledge Distillation outperforms current baselines in GRF estimation from wearable sensor data.
Intra-class Patch Swap for Self-Distillation
May 20, 2025Knowledge distillation (KD) is a valuable technique for compressing large deep learning models into smaller, edge-suitable networks. However, conventional KD frameworks rely on pre-trained high-capacity teacher networks, which introduce significant challenges such as increased memory/storage requirements, additional training costs, and ambiguity in selecting an appropriate teacher for a given student model. Although a teacher-free distillation (self-distillation) has emerged as a promising alternative, many existing approaches still rely on architectural modifications or complex training procedures, which limit their generality and efficiency. To address these limitations, we propose a novel framework based on teacher-free distillation that operates using a single student network without any auxiliary components, architectural modifications, or additional learnable parameters. Our approach is built on a simple yet highly effective augmentation, called intra-class patch swap augmentation. This augmentation simulates a teacher-student dynamic within a single model by generating pairs of intra-class samples with varying confidence levels, and then applying instance-to-instance distillation to align their predictive distributions. Our method is conceptually simple, model-agnostic, and easy to implement, requiring only a single augmentation function. Extensive experiments across image classification, semantic segmentation, and object detection show that our method consistently outperforms both existing self-distillation baselines and conventional teacher-based KD approaches. These results suggest that the success of self-distillation could hinge on the design of the augmentation itself. Our codes are available at https://github.com/hchoi71/Intra-class-Patch-Swap.
Topological Persistence Guided Knowledge Distillation for Wearable Sensor Data
Jul 07, 2024



Deep learning methods have achieved a lot of success in various applications involving converting wearable sensor data to actionable health insights. A common application areas is activity recognition, where deep-learning methods still suffer from limitations such as sensitivity to signal quality, sensor characteristic variations, and variability between subjects. To mitigate these issues, robust features obtained by topological data analysis (TDA) have been suggested as a potential solution. However, there are two significant obstacles to using topological features in deep learning: (1) large computational load to extract topological features using TDA, and (2) different signal representations obtained from deep learning and TDA which makes fusion difficult. In this paper, to enable integration of the strengths of topological methods in deep-learning for time-series data, we propose to use two teacher networks, one trained on the raw time-series data, and another trained on persistence images generated by TDA methods. The distilled student model utilizes only the raw time-series data at test-time. This approach addresses both issues. The use of KD with multiple teachers utilizes complementary information, and results in a compact model with strong supervisory features and an integrated richer representation. To assimilate desirable information from different modalities, we design new constraints, including orthogonality imposed on feature correlation maps for improving feature expressiveness and allowing the student to easily learn from the teacher. Also, we apply an annealing strategy in KD for fast saturation and better accommodation from different features, while the knowledge gap between the teachers and student is reduced. Finally, a robust student model is distilled, which uses only the time-series data as an input, while implicitly preserving topological features.
* Engineering Applications of Artificial Intelligence 130, 107719
Polynomial Implicit Neural Representations For Large Diverse Datasets
Mar 20, 2023



Implicit neural representations (INR) have gained significant popularity for signal and image representation for many end-tasks, such as superresolution, 3D modeling, and more. Most INR architectures rely on sinusoidal positional encoding, which accounts for high-frequency information in data. However, the finite encoding size restricts the model's representational power. Higher representational power is needed to go from representing a single given image to representing large and diverse datasets. Our approach addresses this gap by representing an image with a polynomial function and eliminates the need for positional encodings. Therefore, to achieve a progressively higher degree of polynomial representation, we use element-wise multiplications between features and affine-transformed coordinate locations after every ReLU layer. The proposed method is evaluated qualitatively and quantitatively on large datasets like ImageNet. The proposed Poly-INR model performs comparably to state-of-the-art generative models without any convolution, normalization, or self-attention layers, and with far fewer trainable parameters. With much fewer training parameters and higher representative power, our approach paves the way for broader adoption of INR models for generative modeling tasks in complex domains. The code is available at \url{https://github.com/Rajhans0/Poly_INR}
Leveraging Angular Distributions for Improved Knowledge Distillation
Feb 27, 2023



Knowledge distillation as a broad class of methods has led to the development of lightweight and memory efficient models, using a pre-trained model with a large capacity (teacher network) to train a smaller model (student network). Recently, additional variations for knowledge distillation, utilizing activation maps of intermediate layers as the source of knowledge, have been studied. Generally, in computer vision applications, it is seen that the feature activation learned by a higher capacity model contains richer knowledge, highlighting complete objects while focusing less on the background. Based on this observation, we leverage the dual ability of the teacher to accurately distinguish between positive (relevant to the target object) and negative (irrelevant) areas. We propose a new loss function for distillation, called angular margin-based distillation (AMD) loss. AMD loss uses the angular distance between positive and negative features by projecting them onto a hypersphere, motivated by the near angular distributions seen in many feature extractors. Then, we create a more attentive feature that is angularly distributed on the hypersphere by introducing an angular margin to the positive feature. Transferring such knowledge from the teacher network enables the student model to harness the higher discrimination of positive and negative features for the teacher, thus distilling superior student models. The proposed method is evaluated for various student-teacher network pairs on four public datasets. Furthermore, we show that the proposed method has advantages in compatibility with other learning techniques, such as using fine-grained features, augmentation, and other distillation methods.
* Neurocomputing, Volume 518, 21 January 2023, Pages 466-481
Understanding the Role of Mixup in Knowledge Distillation: An Empirical Study
Nov 09, 2022



Mixup is a popular data augmentation technique based on creating new samples by linear interpolation between two given data samples, to improve both the generalization and robustness of the trained model. Knowledge distillation (KD), on the other hand, is widely used for model compression and transfer learning, which involves using a larger network's implicit knowledge to guide the learning of a smaller network. At first glance, these two techniques seem very different, however, we found that "smoothness" is the connecting link between the two and is also a crucial attribute in understanding KD's interplay with mixup. Although many mixup variants and distillation methods have been proposed, much remains to be understood regarding the role of a mixup in knowledge distillation. In this paper, we present a detailed empirical study on various important dimensions of compatibility between mixup and knowledge distillation. We also scrutinize the behavior of the networks trained with a mixup in the light of knowledge distillation through extensive analysis, visualizations, and comprehensive experiments on image classification. Finally, based on our findings, we suggest improved strategies to guide the student network to enhance its effectiveness. Additionally, the findings of this study provide insightful suggestions to researchers and practitioners that commonly use techniques from KD. Our code is available at https://github.com/hchoi71/MIX-KD.