 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrow, Assess, Compress: Adaptive Backbone Scaling for Memory-Efficient Class Incremental Learning
Mar 09, 2026Class Incremental Learning (CIL) poses a fundamental challenge: maintaining a balance between the plasticity required to learn new tasks and the stability needed to prevent catastrophic forgetting. While expansion-based methods effectively mitigate forgetting by adding task-specific parameters, they suffer from uncontrolled architectural growth and memory overhead. In this paper, we propose a novel dynamic scaling framework that adaptively manages model capacity through a cyclic "GRow, Assess, ComprEss" (GRACE) strategy. Crucially, we supplement backbone expansion with a novel saturation assessment phase that evaluates the utilization of the model's capacity. This assessment allows the framework to make informed decisions to either expand the architecture or compress the backbones into a streamlined representation, preventing parameter explosion. Experimental results demonstrate that our approach achieves state-of-the-art performance across multiple CIL benchmarks, while reducing memory footprint by up to a 73% compared to purely expansionist models.
Mixture of Predefined Experts: Maximizing Data Usage on Vertical Federated Learning
Feb 13, 2026Vertical Federated Learning (VFL) has emerged as a critical paradigm for collaborative model training in privacy-sensitive domains such as finance and healthcare. However, most existing VFL frameworks rely on the idealized assumption of full sample alignment across participants, a premise that rarely holds in real-world scenarios. To bridge this gap, this work introduces Split-MoPE, a novel framework that integrates Split Learning with a specialized Mixture of Predefined Experts (MoPE) architecture. Unlike standard Mixture of Experts (MoE), where routing is learned dynamically, MoPE uses predefined experts to process specific data alignments, effectively maximizing data usage during both training and inference without requiring full sample overlap. By leveraging pretrained encoders for target data domains, Split-MoPE achieves state-of-the-art performance in a single communication round, significantly reducing the communication footprint compared to multi-round end-to-end training. Furthermore, unlike existing proposals that address sample misalignment, this novel architecture provides inherent robustness against malicious or noisy participants and offers per-sample interpretability by quantifying each collaborator's contribution to each prediction. Extensive evaluations on vision (CIFAR-10/100) and tabular (Breast Cancer Wisconsin) datasets demonstrate that Split-MoPE consistently outperforms state-of-the-art systems such as LASER and Vertical SplitNN, particularly in challenging scenarios with high data missingness.
Ali-AUG: Innovative Approaches to Labeled Data Augmentation using One-Step Diffusion Model
Oct 24, 2024



This paper introduces Ali-AUG, a novel single-step diffusion model for efficient labeled data augmentation in industrial applications. Our method addresses the challenge of limited labeled data by generating synthetic, labeled images with precise feature insertion. Ali-AUG utilizes a stable diffusion architecture enhanced with skip connections and LoRA modules to efficiently integrate masks and images, ensuring accurate feature placement without affecting unrelated image content. Experimental validation across various industrial datasets demonstrates Ali-AUG's superiority in generating high-quality, defect-enhanced images while maintaining rapid single-step inference. By offering precise control over feature insertion and minimizing required training steps, our technique significantly enhances data augmentation capabilities, providing a powerful tool for improving the performance of deep learning models in scenarios with limited labeled data. Ali-AUG is especially useful for use cases like defective product image generation to train AI-based models to improve their ability to detect defects in manufacturing processes. Using different data preparation strategies, including Classification Accuracy Score (CAS) and Naive Augmentation Score (NAS), we show that Ali-AUG improves model performance by 31% compared to other augmentation methods and by 45% compared to models without data augmentation. Notably, Ali-AUG reduces training time by 32% and supports both paired and unpaired datasets, enhancing flexibility in data preparation.
Towards Active Participant-Centric Vertical Federated Learning: Some Representations May Be All You Need
Oct 23, 2024Vertical Federated Learning (VFL) enables collaborative model training across different participants with distinct features and common samples, while preserving data privacy. Existing VFL methodologies often struggle with realistic data partitions, typically incurring high communication costs and significant operational complexity. In this work, we introduce a novel simplified approach to VFL, Active Participant-Centric VFL (APC-VFL), that, to the best of our knowledge, is the first to require only a single communication round between participants, and allows the active participant to do inference in a non collaborative fashion. This method integrates unsupervised representation learning with knowledge distillation to achieve comparable accuracy to traditional VFL methods based on vertical split learning in classical settings, reducing required communication rounds by up to $4200\times$, while being more flexible. Our approach also shows improvements compared to non-federated local models, as well as a comparable VFL proposal, VFedTrans, offering an efficient and flexible solution for collaborative learning.
Quantum artificial vision for defect detection in manufacturing
Aug 09, 2022
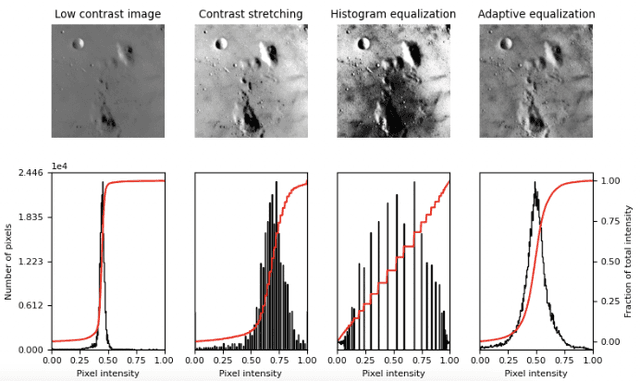
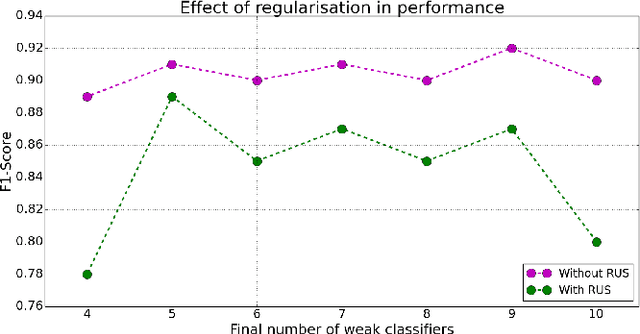

In this paper we consider several algorithms for quantum computer vision using Noisy Intermediate-Scale Quantum (NISQ) devices, and benchmark them for a real problem against their classical counterparts. Specifically, we consider two approaches: a quantum Support Vector Machine (QSVM) on a universal gate-based quantum computer, and QBoost on a quantum annealer. The quantum vision systems are benchmarked for an unbalanced dataset of images where the aim is to detect defects in manufactured car pieces. We see that the quantum algorithms outperform their classical counterparts in several ways, with QBoost allowing for larger problems to be analyzed with present-day quantum annealers. Data preprocessing, including dimensionality reduction and contrast enhancement, is also discussed, as well as hyperparameter tuning in QBoost. To the best of our knowledge, this is the first implementation of quantum computer vision systems for a problem of industrial relevance in a manufacturing production line.