 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Abilities of Large Language Models
Jun 15, 2022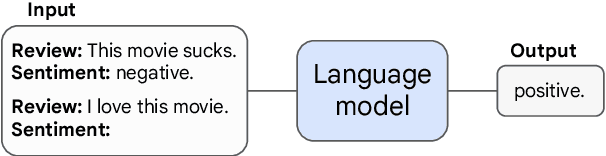
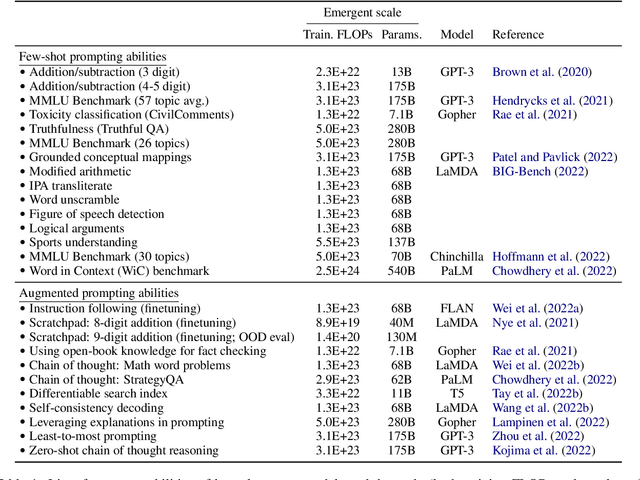
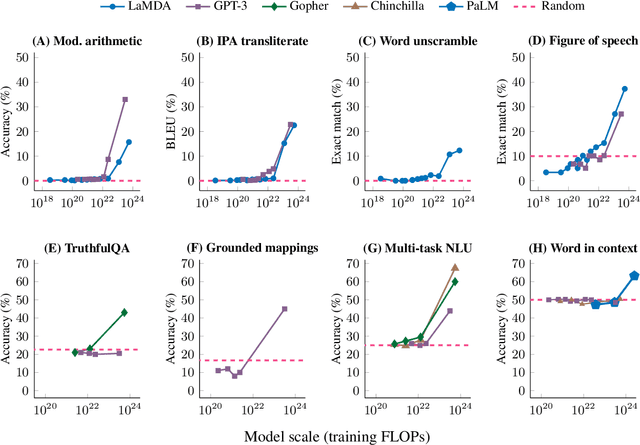
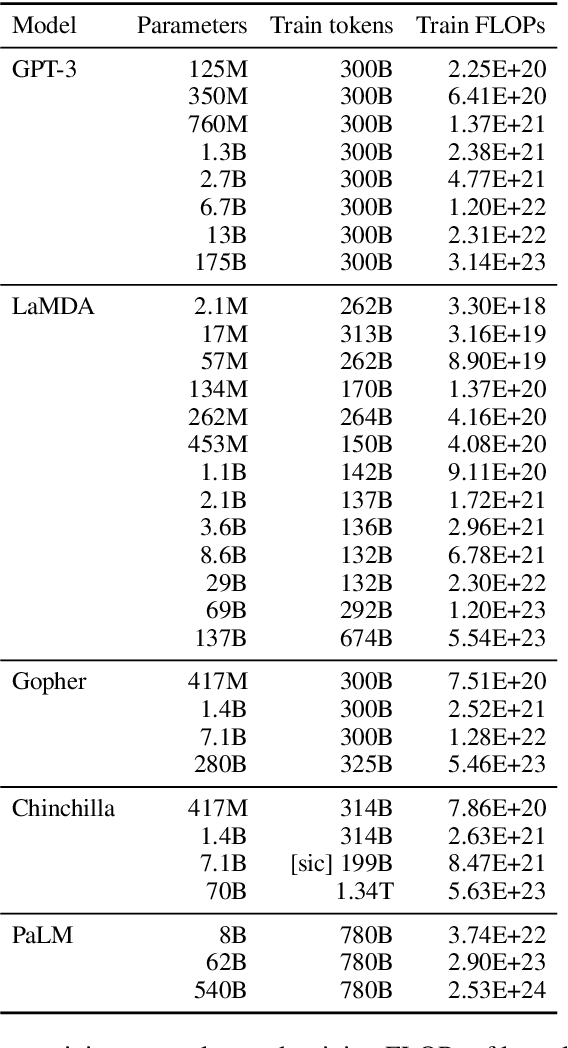
Scaling up language models has been shown to predictably improve performance and sample efficiency on a wide range of downstream tasks. This paper instead discusses an unpredictable phenomenon that we refer to as emergent abilities of large language models. We consider an ability to be emergent if it is not present in smaller models but is present in larger models. Thus, emergent abilities cannot be predicted simply by extrapolating the performance of smaller models. The existence of such emergence implies that additional scaling could further expand the range of capabilities of language models.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
May 21, 2022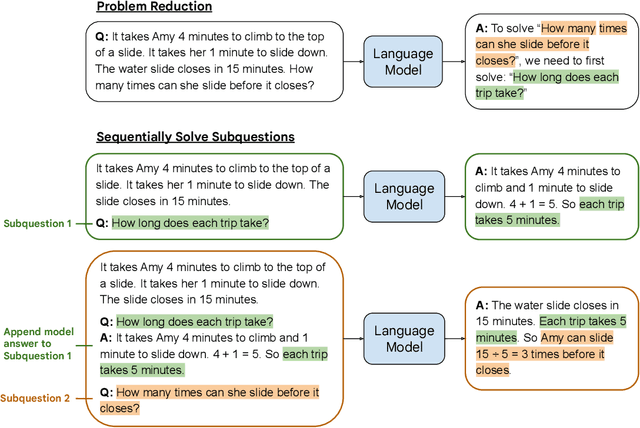



We propose a novel prompting strategy, least-to-most prompting, that enables large language models to better perform multi-step reasoning tasks. Least-to-most prompting first reduces a complex problem into a list of subproblems, and then sequentially solves the subproblems, whereby solving a given subproblem is facilitated by the model's answers to previously solved subproblems. Experiments on symbolic manipulation, compositional generalization and numerical reasoning demonstrate that least-to-most prompting can generalize to examples that are harder than those seen in the prompt context, outperforming other prompting-based approaches by a large margin. A notable empirical result is that the GPT-3 code-davinci-002 model with least-to-most-prompting can solve the SCAN benchmark with an accuracy of 99.7% using 14 examples. As a comparison, the neural-symbolic models in the literature specialized for solving SCAN are trained with the full training set of more than 15,000 examples.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Apr 06, 2022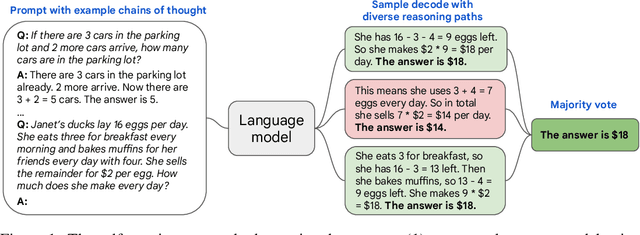
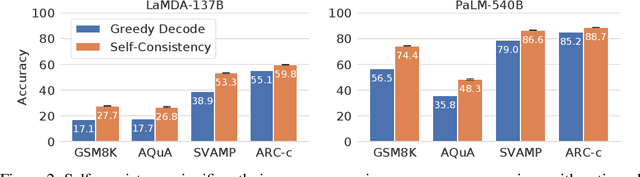
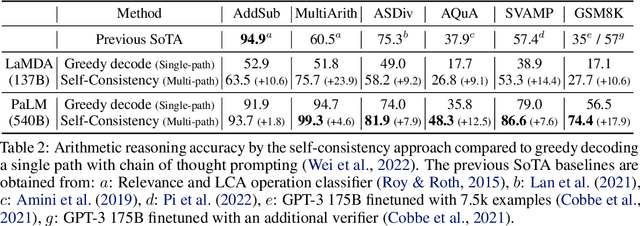
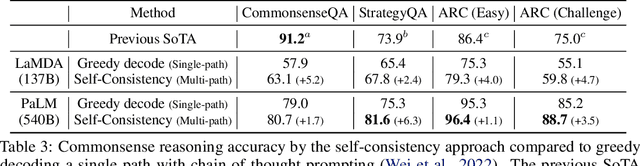
We explore a simple ensemble strategy, self-consistency, that significantly improves the reasoning accuracy of large language models. The idea is to sample a diverse set of reasoning paths from a language model via chain of thought prompting then return the most consistent final answer in the set. We evaluate self-consistency on a range of arithmetic and commonsense reasoning benchmarks, and find that it robustly improves accuracy across a variety of language models and model scales without the need for additional training or auxiliary models. When combined with a recent large language model, PaLM-540B, self-consistency increases performance to state-of-the-art levels across several benchmark reasoning tasks, including GSM8K (56.5% -> 74.4%), SVAMP (79.0% -> 86.6%), AQuA (35.8% -> 48.3%), StrategyQA (75.3% -> 81.6%) and ARC-challenge (85.2% -> 88.7%).
Chain of Thought Prompting Elicits Reasoning in Large Language Models
Jan 28, 2022



Although scaling up language model size has reliably improved performance on a range of NLP tasks, even the largest models currently struggle with certain reasoning tasks such as math word problems, symbolic manipulation, and commonsense reasoning. This paper explores the ability of language models to generate a coherent chain of thought -- a series of short sentences that mimic the reasoning process a person might have when responding to a question. Experiments show that inducing a chain of thought via prompting can enable sufficiently large language models to better perform reasoning tasks that otherwise have flat scaling curves.
Calibrating Histopathology Image Classifiers using Label Smoothing
Jan 28, 2022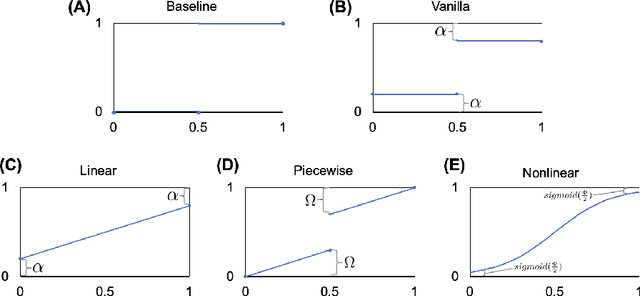
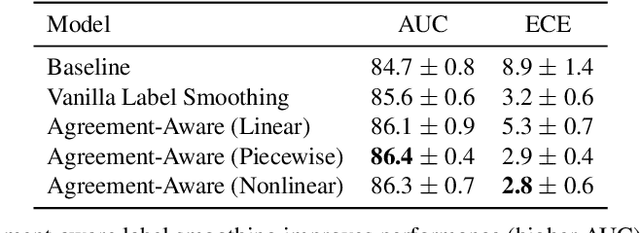
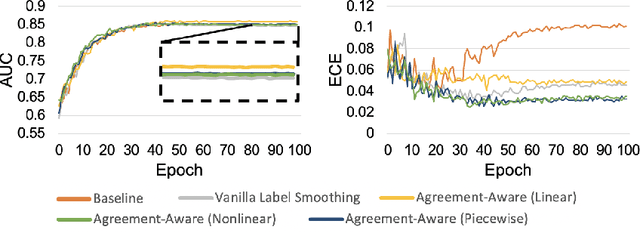

The classification of histopathology images fundamentally differs from traditional image classification tasks because histopathology images naturally exhibit a range of diagnostic features, resulting in a diverse range of annotator agreement levels. However, examples with high annotator disagreement are often either assigned the majority label or discarded entirely when training histopathology image classifiers. This widespread practice often yields classifiers that do not account for example difficulty and exhibit poor model calibration. In this paper, we ask: can we improve model calibration by endowing histopathology image classifiers with inductive biases about example difficulty? We propose several label smoothing methods that utilize per-image annotator agreement. Though our methods are simple, we find that they substantially improve model calibration, while maintaining (or even improving) accuracy. For colorectal polyp classification, a common yet challenging task in gastrointestinal pathology, we find that our proposed agreement-aware label smoothing methods reduce calibration error by almost 70%. Moreover, we find that using model confidence as a proxy for annotator agreement also improves calibration and accuracy, suggesting that datasets without multiple annotators can still benefit from our proposed label smoothing methods via our proposed confidence-aware label smoothing methods. Given the importance of calibration (especially in histopathology image analysis), the improvements from our proposed techniques merit further exploration and potential implementation in other histopathology image classification tasks.
A Recipe For Arbitrary Text Style Transfer with Large Language Models
Sep 16, 2021



In this paper, we leverage large language models (LMs) to perform zero-shot text style transfer. We present a prompting method that we call augmented zero-shot learning, which frames style transfer as a sentence rewriting task and requires only a natural language instruction, without model fine-tuning or exemplars in the target style. Augmented zero-shot learning is simple and demonstrates promising results not just on standard style transfer tasks such as sentiment, but also on arbitrary transformations such as "make this melodramatic" or "insert a metaphor."
Good-Enough Example Extrapolation
Sep 15, 2021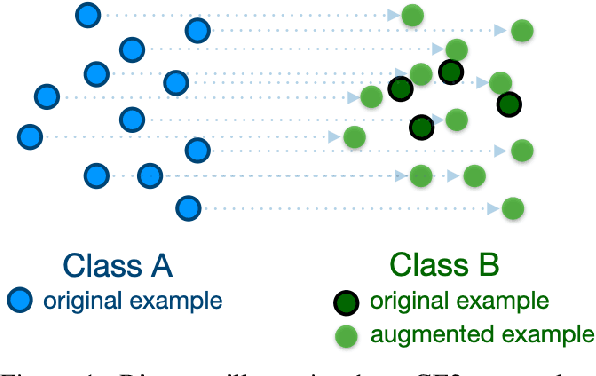

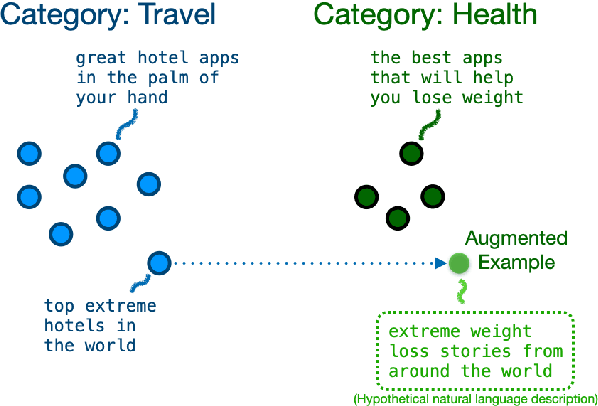

This paper asks whether extrapolating the hidden space distribution of text examples from one class onto another is a valid inductive bias for data augmentation. To operationalize this question, I propose a simple data augmentation protocol called "good-enough example extrapolation" (GE3). GE3 is lightweight and has no hyperparameters. Applied to three text classification datasets for various data imbalance scenarios, GE3 improves performance more than upsampling and other hidden-space data augmentation methods.
Frequency Effects on Syntactic Rule Learning in Transformers
Sep 14, 2021
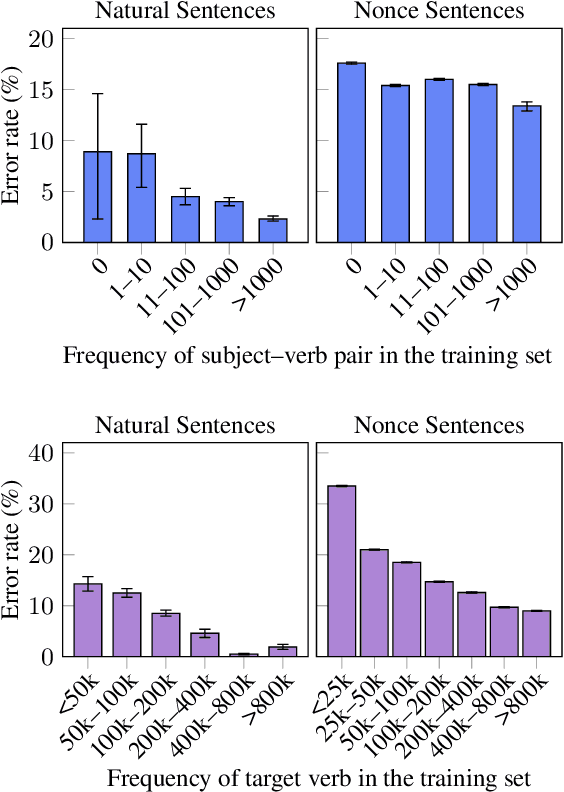
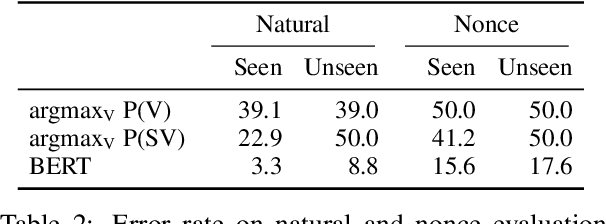
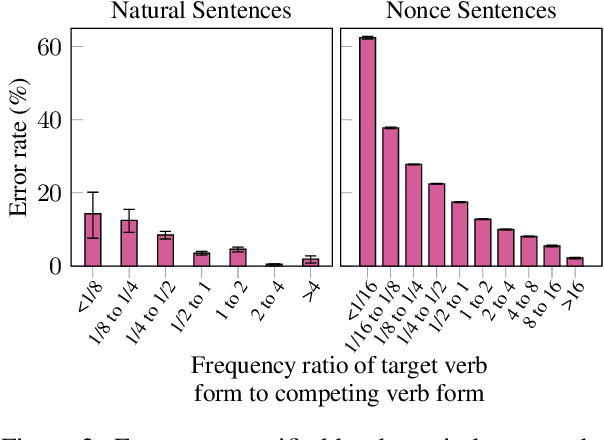
Pre-trained language models perform well on a variety of linguistic tasks that require symbolic reasoning, raising the question of whether such models implicitly represent abstract symbols and rules. We investigate this question using the case study of BERT's performance on English subject-verb agreement. Unlike prior work, we train multiple instances of BERT from scratch, allowing us to perform a series of controlled interventions at pre-training time. We show that BERT often generalizes well to subject-verb pairs that never occurred in training, suggesting a degree of rule-governed behavior. We also find, however, that performance is heavily influenced by word frequency, with experiments showing that both the absolute frequency of a verb form, as well as the frequency relative to the alternate inflection, are causally implicated in the predictions BERT makes at inference time. Closer analysis of these frequency effects reveals that BERT's behavior is consistent with a system that correctly applies the SVA rule in general but struggles to overcome strong training priors and to estimate agreement features (singular vs. plural) on infrequent lexical items.