 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-RED: Unsupervised 3D Shape Retrieval and Deformation for Partial Point Clouds
Aug 11, 2023



In this paper, we propose U-RED, an Unsupervised shape REtrieval and Deformation pipeline that takes an arbitrary object observation as input, typically captured by RGB images or scans, and jointly retrieves and deforms the geometrically similar CAD models from a pre-established database to tightly match the target. Considering existing methods typically fail to handle noisy partial observations, U-RED is designed to address this issue from two aspects. First, since one partial shape may correspond to multiple potential full shapes, the retrieval method must allow such an ambiguous one-to-many relationship. Thereby U-RED learns to project all possible full shapes of a partial target onto the surface of a unit sphere. Then during inference, each sampling on the sphere will yield a feasible retrieval. Second, since real-world partial observations usually contain noticeable noise, a reliable learned metric that measures the similarity between shapes is necessary for stable retrieval. In U-RED, we design a novel point-wise residual-guided metric that allows noise-robust comparison. Extensive experiments on the synthetic datasets PartNet, ComplementMe and the real-world dataset Scan2CAD demonstrate that U-RED surpasses existing state-of-the-art approaches by 47.3%, 16.7% and 31.6% respectively under Chamfer Distance.
Achieving RGB-D level Segmentation Performance from a Single ToF Camera
Jun 30, 2023



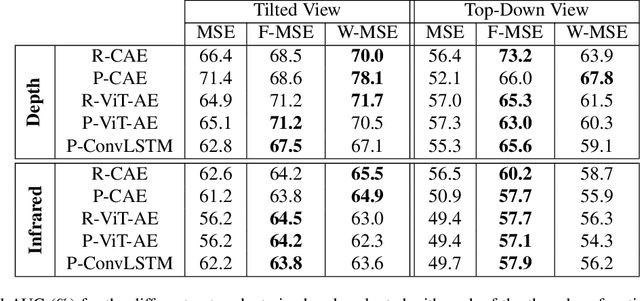
Depth is a very important modality in computer vision, typically used as complementary information to RGB, provided by RGB-D cameras. In this work, we show that it is possible to obtain the same level of accuracy as RGB-D cameras on a semantic segmentation task using infrared (IR) and depth images from a single Time-of-Flight (ToF) camera. In order to fuse the IR and depth modalities of the ToF camera, we introduce a method utilizing depth-specific convolutions in a multi-task learning framework. In our evaluation on an in-car segmentation dataset, we demonstrate the competitiveness of our method against the more costly RGB-D approaches.
RC-BEVFusion: A Plug-In Module for Radar-Camera Bird's Eye View Feature Fusion
May 25, 2023



Radars and cameras belong to the most frequently used sensors for advanced driver assistance systems and automated driving research. However, there has been surprisingly little research on radar-camera fusion with neural networks. One of the reasons is a lack of large-scale automotive datasets with radar and unmasked camera data, with the exception of the nuScenes dataset. Another reason is the difficulty of effectively fusing the sparse radar point cloud on the bird's eye view (BEV) plane with the dense images on the perspective plane. The recent trend of camera-based 3D object detection using BEV features has enabled a new type of fusion, which is better suited for radars. In this work, we present RC-BEVFusion, a modular radar-camera fusion network on the BEV plane. We propose BEVFeatureNet, a novel radar encoder branch, and show that it can be incorporated into several state-of-the-art camera-based architectures. We show significant performance gains of up to 28% increase in the nuScenes detection score, which is an important step in radar-camera fusion research. Without tuning our model for the nuScenes benchmark, we achieve the best result among all published methods in the radar-camera fusion category.
OPA-3D: Occlusion-Aware Pixel-Wise Aggregation for Monocular 3D Object Detection
Nov 02, 2022



Despite monocular 3D object detection having recently made a significant leap forward thanks to the use of pre-trained depth estimators for pseudo-LiDAR recovery, such two-stage methods typically suffer from overfitting and are incapable of explicitly encapsulating the geometric relation between depth and object bounding box. To overcome this limitation, we instead propose OPA-3D, a single-stage, end-to-end, Occlusion-Aware Pixel-Wise Aggregation network that to jointly estimate dense scene depth with depth-bounding box residuals and object bounding boxes, allowing a two-stream detection of 3D objects, leading to significantly more robust detections. Thereby, the geometry stream denoted as the Geometry Stream, combines visible depth and depth-bounding box residuals to recover the object bounding box via explicit occlusion-aware optimization. In addition, a bounding box based geometry projection scheme is employed in an effort to enhance distance perception. The second stream, named as the Context Stream, directly regresses 3D object location and size. This novel two-stream representation further enables us to enforce cross-stream consistency terms which aligns the outputs of both streams, improving the overall performance. Extensive experiments on the public benchmark demonstrate that OPA-3D outperforms state-of-the-art methods on the main Car category, whilst keeping a real-time inference speed. We plan to release all codes and trained models soon.
Unsupervised Anomaly Detection from Time-of-Flight Depth Images
Apr 12, 2022

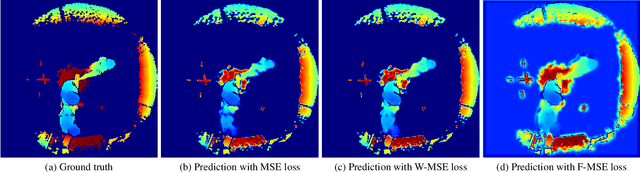
Video anomaly detection (VAD) addresses the problem of automatically finding anomalous events in video data. The primary data modalities on which current VAD systems work on are monochrome or RGB images. Using depth data in this context instead is still hardly explored in spite of depth images being a popular choice in many other computer vision research areas and the increasing availability of inexpensive depth camera hardware. We evaluate the application of existing autoencoder-based methods on depth video and propose how the advantages of using depth data can be leveraged by integration into the loss function. Training is done unsupervised using normal sequences without need for any additional annotations. We show that depth allows easy extraction of auxiliary information for scene analysis in the form of a foreground mask and demonstrate its beneficial effect on the anomaly detection performance through evaluation on a large public dataset, for which we are also the first ones to present results on.
ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Mar 29, 2022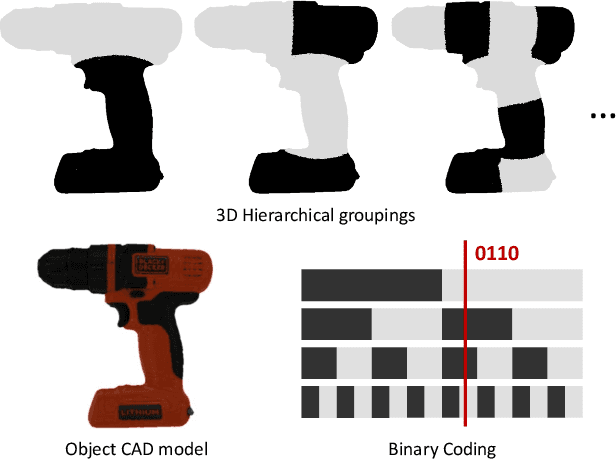
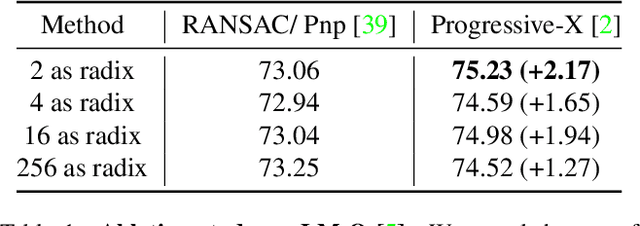
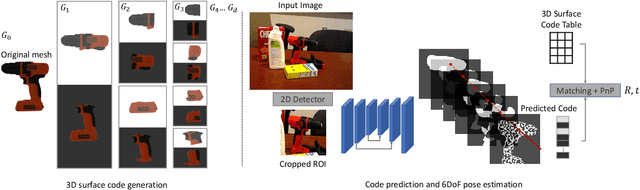

Establishing correspondences from image to 3D has been a key task of 6DoF object pose estimation for a long time. To predict pose more accurately, deeply learned dense maps replaced sparse templates. Dense methods also improved pose estimation in the presence of occlusion. More recently researchers have shown improvements by learning object fragments as segmentation. In this work, we present a discrete descriptor, which can represent the object surface densely. By incorporating a hierarchical binary grouping, we can encode the object surface very efficiently. Moreover, we propose a coarse to fine training strategy, which enables fine-grained correspondence prediction. Finally, by matching predicted codes with object surface and using a PnP solver, we estimate the 6DoF pose. Results on the public LM-O and YCB-V datasets show major improvement over the state of the art w.r.t. ADD(-S) metric, even surpassing RGB-D based methods in some cases.
IKEA Object State Dataset: A 6DoF object pose estimation dataset and benchmark for multi-state assembly objects
Nov 16, 2021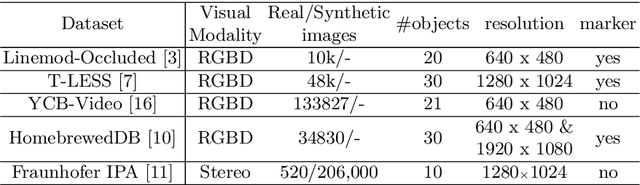


Utilizing 6DoF(Degrees of Freedom) pose information of an object and its components is critical for object state detection tasks. We present IKEA Object State Dataset, a new dataset that contains IKEA furniture 3D models, RGBD video of the assembly process, the 6DoF pose of furniture parts and their bounding box. The proposed dataset will be available at https://github.com/mxllmx/IKEAObjectStateDataset.
PlaneRecNet: Multi-Task Learning with Cross-Task Consistency for Piece-Wise Plane Detection and Reconstruction from a Single RGB Image
Oct 21, 2021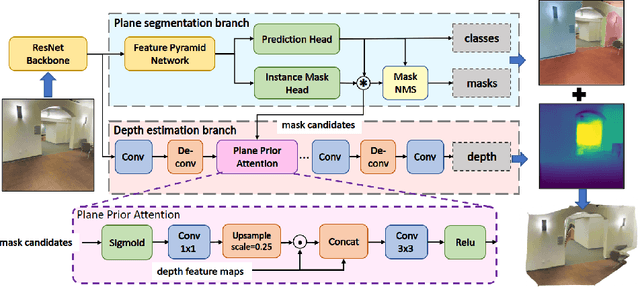

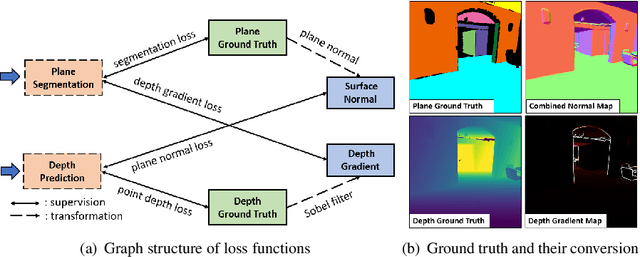

Piece-wise 3D planar reconstruction provides holistic scene understanding of man-made environments, especially for indoor scenarios. Most recent approaches focused on improving the segmentation and reconstruction results by introducing advanced network architectures but overlooked the dual characteristics of piece-wise planes as objects and geometric models. Different from other existing approaches, we start from enforcing cross-task consistency for our multi-task convolutional neural network, PlaneRecNet, which integrates a single-stage instance segmentation network for piece-wise planar segmentation and a depth decoder to reconstruct the scene from a single RGB image. To achieve this, we introduce several novel loss functions (geometric constraint) that jointly improve the accuracy of piece-wise planar segmentation and depth estimation. Meanwhile, a novel Plane Prior Attention module is used to guide depth estimation with the awareness of plane instances. Exhaustive experiments are conducted in this work to validate the effectiveness and efficiency of our method.
TIMo -- A Dataset for Indoor Building Monitoring with a Time-of-Flight Camera
Aug 27, 2021
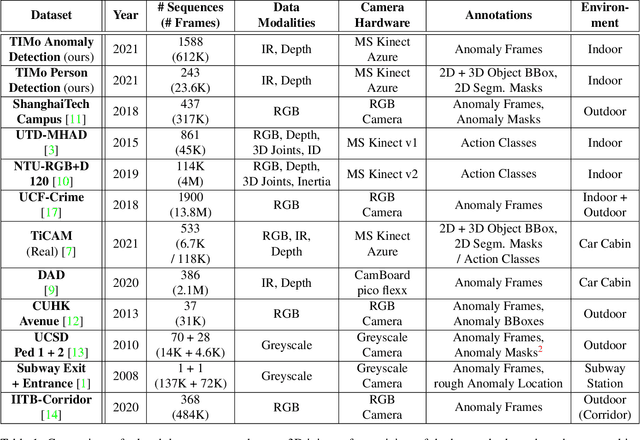

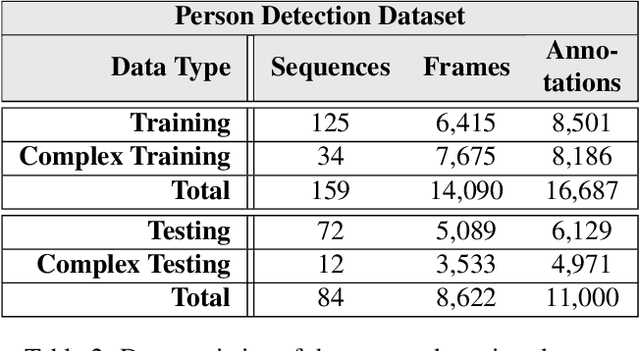
We present TIMo (Time-of-flight Indoor Monitoring), a dataset for video-based monitoring of indoor spaces captured using a time-of-flight (ToF) camera. The resulting depth videos feature people performing a set of different predefined actions, for which we provide detailed annotations. Person detection for people counting and anomaly detection are the two targeted applications. Most existing surveillance video datasets provide either grayscale or RGB videos. Depth information, on the other hand, is still a rarity in this class of datasets in spite of being popular and much more common in other research fields within computer vision. Our dataset addresses this gap in the landscape of surveillance video datasets. The recordings took place at two different locations with the ToF camera set up either in a top-down or a tilted perspective on the scene. The dataset is publicly available at https://vizta-tof.kl.dfki.de/timo-dataset-overview/.
Deployment of Deep Neural Networks for Object Detection on Edge AI Devices with Runtime Optimization
Aug 18, 2021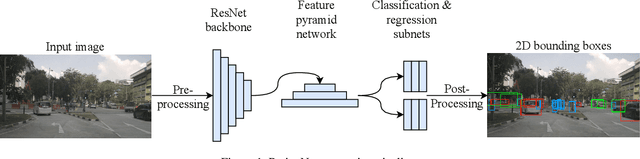

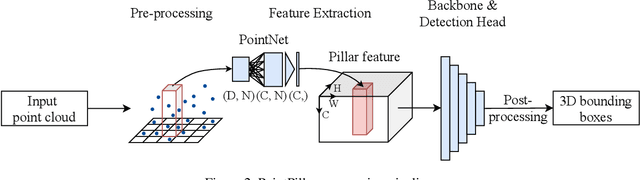
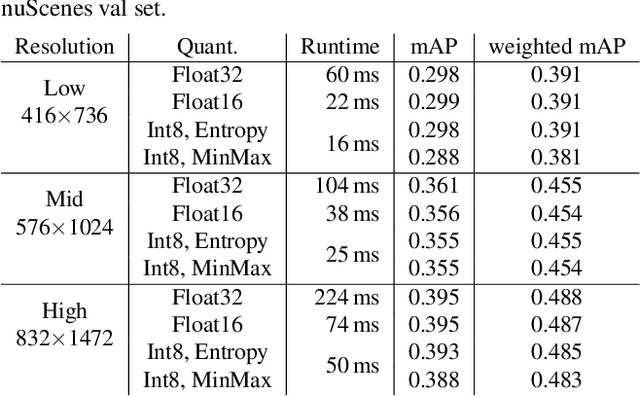
Deep neural networks have proven increasingly important for automotive scene understanding with new algorithms offering constant improvements of the detection performance. However, there is little emphasis on experiences and needs for deployment in embedded environments. We therefore perform a case study of the deployment of two representative object detection networks on an edge AI platform. In particular, we consider RetinaNet for image-based 2D object detection and PointPillars for LiDAR-based 3D object detection. We describe the modifications necessary to convert the algorithms from a PyTorch training environment to the deployment environment taking into account the available tools. We evaluate the runtime of the deployed DNN using two different libraries, TensorRT and TorchScript. In our experiments, we observe slight advantages of TensorRT for convolutional layers and TorchScript for fully connected layers. We also study the trade-off between runtime and performance, when selecting an optimized setup for deployment, and observe that quantization significantly reduces the runtime while having only little impact on the detection performance.