 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
What Language Model to Train if You Have One Million GPU Hours?
Nov 08, 2022



The crystallization of modeling methods around the Transformer architecture has been a boon for practitioners. Simple, well-motivated architectural variations can transfer across tasks and scale, increasing the impact of modeling research. However, with the emergence of state-of-the-art 100B+ parameters models, large language models are increasingly expensive to accurately design and train. Notably, it can be difficult to evaluate how modeling decisions may impact emergent capabilities, given that these capabilities arise mainly from sheer scale alone. In the process of building BLOOM--the Big Science Large Open-science Open-access Multilingual language model--our goal is to identify an architecture and training setup that makes the best use of our 1,000,000 A100-GPU-hours budget. Specifically, we perform an ablation study at the billion-parameter scale comparing different modeling practices and their impact on zero-shot generalization. In addition, we study the impact of various popular pre-training corpora on zero-shot generalization. We also study the performance of a multilingual model and how it compares to the English-only one. Finally, we consider the scaling behaviour of Transformers to choose the target model size, shape, and training setup. All our models and code are open-sourced at https://huggingface.co/bigscience .
Two-Turn Debate Doesn't Help Humans Answer Hard Reading Comprehension Questions
Oct 19, 2022
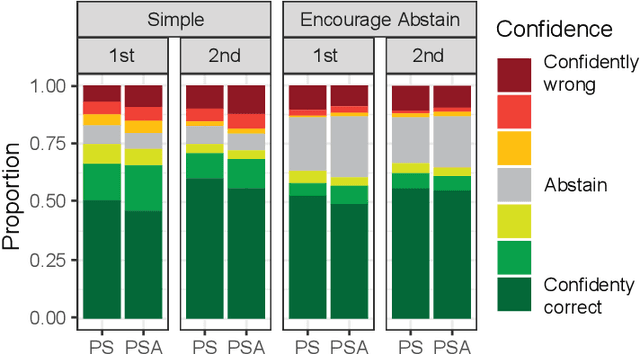
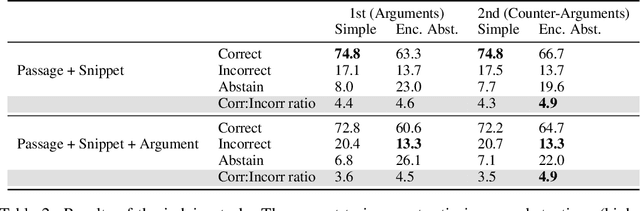
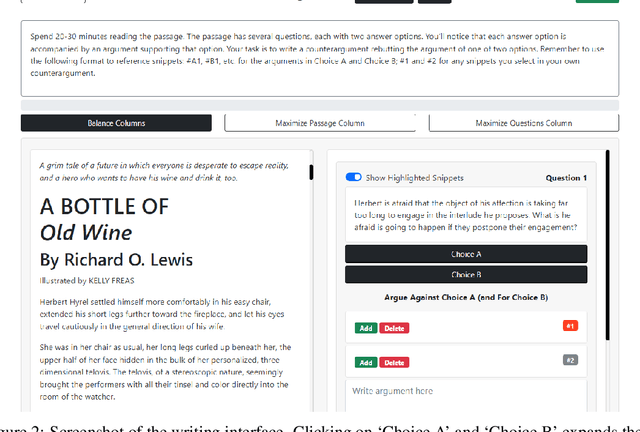
The use of language-model-based question-answering systems to aid humans in completing difficult tasks is limited, in part, by the unreliability of the text these systems generate. Using hard multiple-choice reading comprehension questions as a testbed, we assess whether presenting humans with arguments for two competing answer options, where one is correct and the other is incorrect, allows human judges to perform more accurately, even when one of the arguments is unreliable and deceptive. If this is helpful, we may be able to increase our justified trust in language-model-based systems by asking them to produce these arguments where needed. Previous research has shown that just a single turn of arguments in this format is not helpful to humans. However, as debate settings are characterized by a back-and-forth dialogue, we follow up on previous results to test whether adding a second round of counter-arguments is helpful to humans. We find that, regardless of whether they have access to arguments or not, humans perform similarly on our task. These findings suggest that, in the case of answering reading comprehension questions, debate is not a helpful format.
EleutherAI: Going Beyond "Open Science" to "Science in the Open"
Oct 12, 2022Over the past two years, EleutherAI has established itself as a radically novel initiative aimed at both promoting open-source research and conducting research in a transparent, openly accessible and collaborative manner. EleutherAI's approach to research goes beyond transparency: by doing research entirely in public, anyone in the world can observe and contribute at every stage. Our work has been received positively and has resulted in several high-impact projects in Natural Language Processing and other fields. In this paper, we describe our experience doing public-facing machine learning research, the benefits we believe this approach brings, and the pitfalls we have encountered.
What Do NLP Researchers Believe? Results of the NLP Community Metasurvey
Aug 26, 2022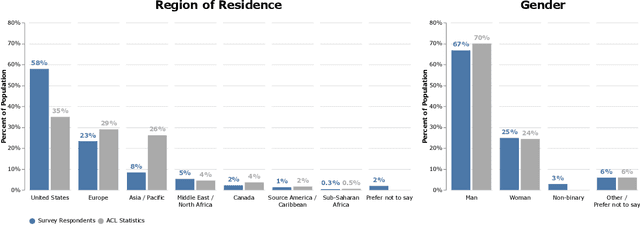

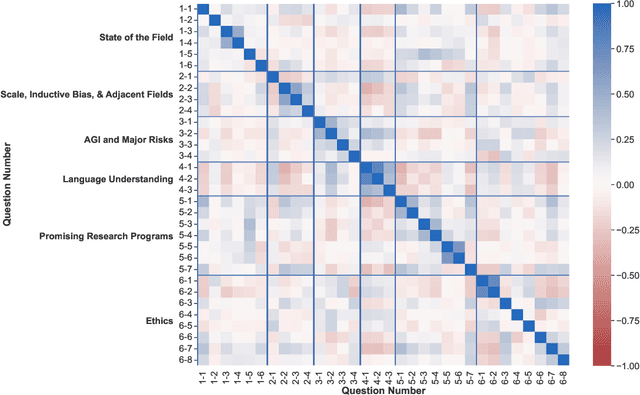
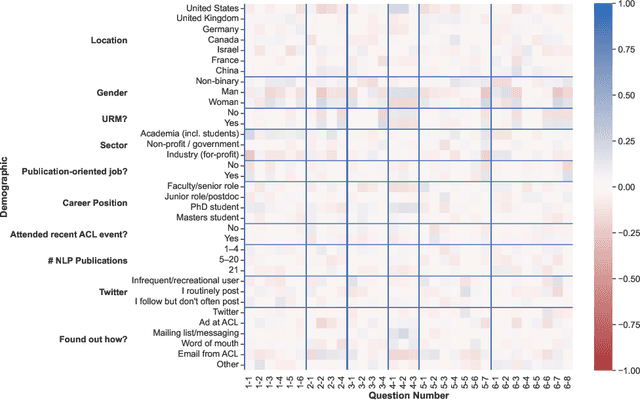
We present the results of the NLP Community Metasurvey. Run from May to June 2022, the survey elicited opinions on controversial issues, including industry influence in the field, concerns about AGI, and ethics. Our results put concrete numbers to several controversies: For example, respondents are split almost exactly in half on questions about the importance of artificial general intelligence, whether language models understand language, and the necessity of linguistic structure and inductive bias for solving NLP problems. In addition, the survey posed meta-questions, asking respondents to predict the distribution of survey responses. This allows us not only to gain insight on the spectrum of beliefs held by NLP researchers, but also to uncover false sociological beliefs where the community's predictions don't match reality. We find such mismatches on a wide range of issues. Among other results, the community greatly overestimates its own belief in the usefulness of benchmarks and the potential for scaling to solve real-world problems, while underestimating its own belief in the importance of linguistic structure, inductive bias, and interdisciplinary science.
Investigating Efficiently Extending Transformers for Long Input Summarization
Aug 08, 2022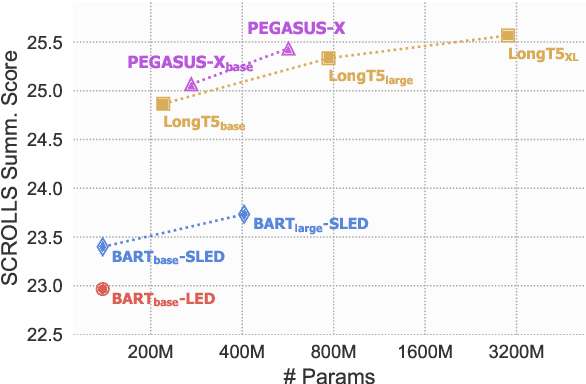

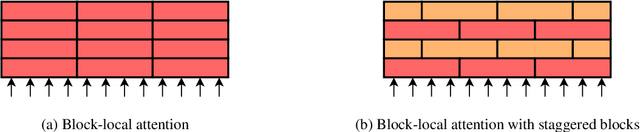
While large pretrained Transformer models have proven highly capable at tackling natural language tasks, handling long sequence inputs continues to be a significant challenge. One such task is long input summarization, where inputs are longer than the maximum input context of most pretrained models. Through an extensive set of experiments, we investigate what model architectural changes and pretraining paradigms can most efficiently adapt a pretrained Transformer for long input summarization. We find that a staggered, block-local Transformer with global encoder tokens strikes a good balance of performance and efficiency, and that an additional pretraining phase on long sequences meaningfully improves downstream summarization performance. Based on our findings, we introduce PEGASUS-X, an extension of the PEGASUS model with additional long input pretraining to handle inputs of up to 16K tokens. PEGASUS-X achieves strong performance on long input summarization tasks comparable with much larger models while adding few additional parameters and not requiring model parallelism to train.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
SQuALITY: Building a Long-Document Summarization Dataset the Hard Way
May 23, 2022

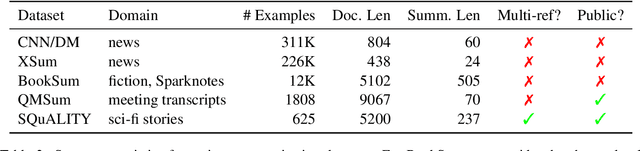

Summarization datasets are often assembled either by scraping naturally occurring public-domain summaries -- which are nearly always in difficult-to-work-with technical domains -- or by using approximate heuristics to extract them from everyday text -- which frequently yields unfaithful summaries. In this work, we turn to a slower but more straightforward approach to developing summarization benchmark data: We hire highly-qualified contractors to read stories and write original summaries from scratch. To amortize reading time, we collect five summaries per document, with the first giving an overview and the subsequent four addressing specific questions. We use this protocol to collect SQuALITY, a dataset of question-focused summaries built on the same public-domain short stories as the multiple-choice dataset QuALITY (Pang et al., 2021). Experiments with state-of-the-art summarization systems show that our dataset is challenging and that existing automatic evaluation metrics are weak indicators of quality.
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Apr 14, 2022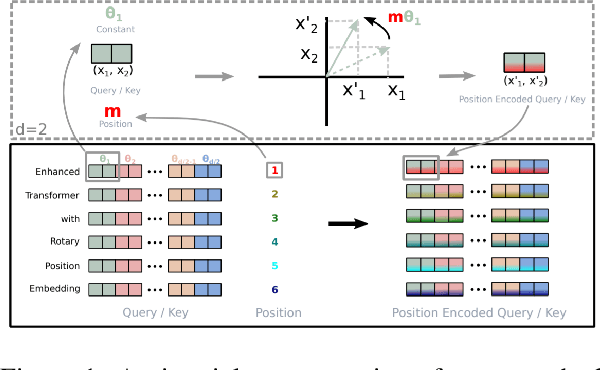
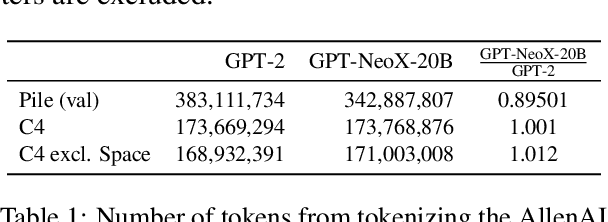

We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe \model{}'s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.
Single-Turn Debate Does Not Help Humans Answer Hard Reading-Comprehension Questions
Apr 13, 2022
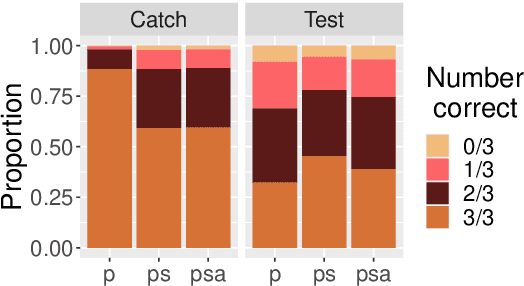
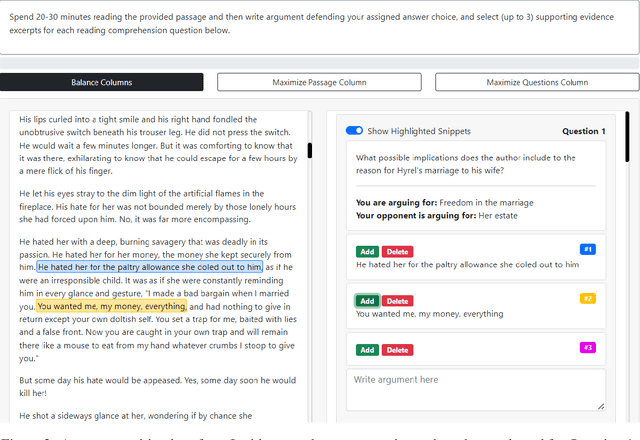
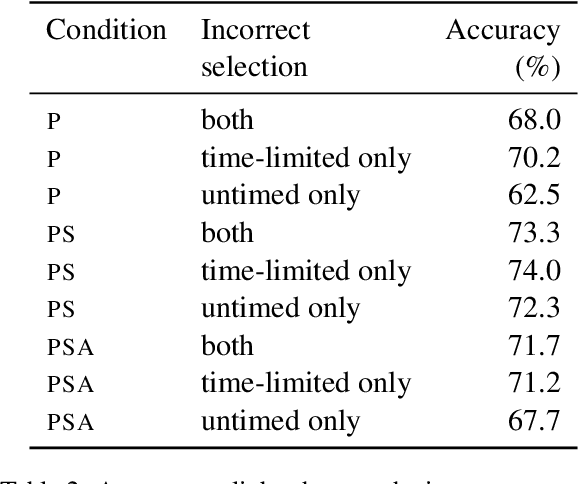
Current QA systems can generate reasonable-sounding yet false answers without explanation or evidence for the generated answer, which is especially problematic when humans cannot readily check the model's answers. This presents a challenge for building trust in machine learning systems. We take inspiration from real-world situations where difficult questions are answered by considering opposing sides (see Irving et al., 2018). For multiple-choice QA examples, we build a dataset of single arguments for both a correct and incorrect answer option in a debate-style set-up as an initial step in training models to produce explanations for two candidate answers. We use long contexts -- humans familiar with the context write convincing explanations for pre-selected correct and incorrect answers, and we test if those explanations allow humans who have not read the full context to more accurately determine the correct answer. We do not find that explanations in our set-up improve human accuracy, but a baseline condition shows that providing human-selected text snippets does improve accuracy. We use these findings to suggest ways of improving the debate set up for future data collection efforts.