 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour GAN is Secretly an Energy-based Model and You Should use Discriminator Driven Latent Sampling
Mar 24, 2020
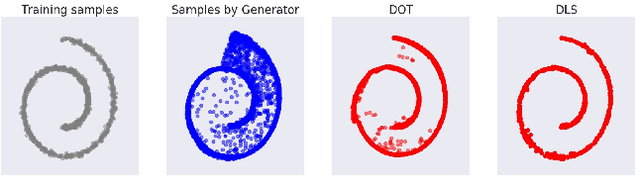
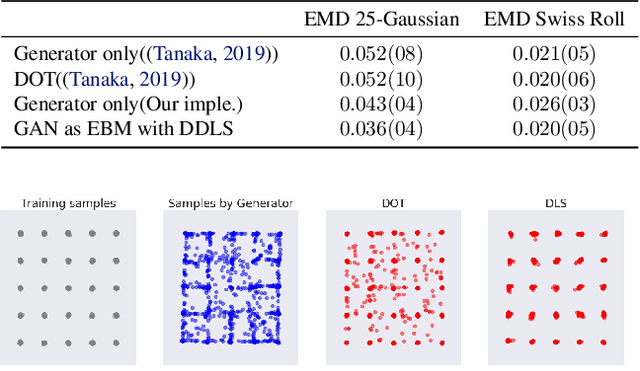

We show that the sum of the implicit generator log-density $\log p_g$ of a GAN with the logit score of the discriminator defines an energy function which yields the true data density when the generator is imperfect but the discriminator is optimal, thus making it possible to improve on the typical generator (with implicit density $p_g$). To make that practical, we show that sampling from this modified density can be achieved by sampling in latent space according to an energy-based model induced by the sum of the latent prior log-density and the discriminator output score. This can be achieved by running a Langevin MCMC in latent space and then applying the generator function, which we call Discriminator Driven Latent Sampling~(DDLS). We show that DDLS is highly efficient compared to previous methods which work in the high-dimensional pixel space and can be applied to improve on previously trained GANs of many types. We evaluate DDLS on both synthetic and real-world datasets qualitatively and quantitatively. On CIFAR-10, DDLS substantially improves the Inception Score of an off-the-shelf pre-trained SN-GAN~\citep{sngan} from $8.22$ to $9.09$ which is even comparable to the class-conditional BigGAN~\citep{biggan} model. This achieves a new state-of-the-art in unconditional image synthesis setting without introducing extra parameters or additional training.
Using a thousand optimization tasks to learn hyperparameter search strategies
Mar 11, 2020
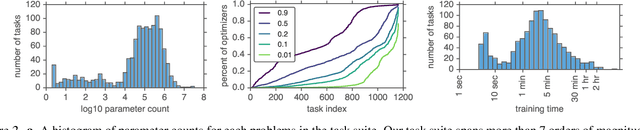
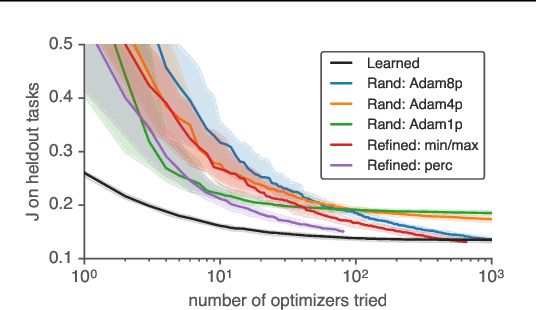
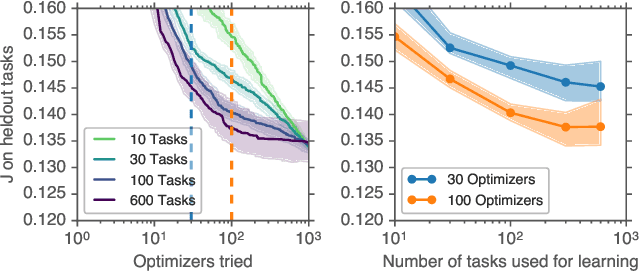
We present TaskSet, a dataset of tasks for use in training and evaluating optimizers. TaskSet is unique in its size and diversity, containing over a thousand tasks ranging from image classification with fully connected or convolutional neural networks, to variational autoencoders, to non-volume preserving flows on a variety of datasets. As an example application of such a dataset we explore meta-learning an ordered list of hyperparameters to try sequentially. By learning this hyperparameter list from data generated using TaskSet we achieve large speedups in sample efficiency over random search. Next we use the diversity of the TaskSet and our method for learning hyperparameter lists to empirically explore the generalization of these lists to new optimization tasks in a variety of settings including ImageNet classification with Resnet50 and LM1B language modeling with transformers. As part of this work we have opensourced code for all tasks, as well as ~29 million training curves for these problems and the corresponding hyperparameters.
The large learning rate phase of deep learning: the catapult mechanism
Mar 04, 2020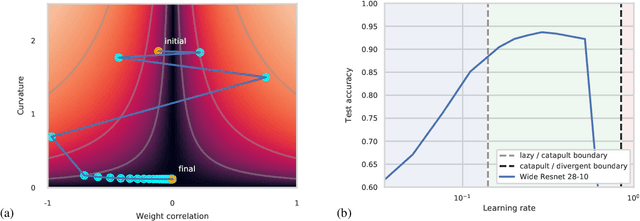
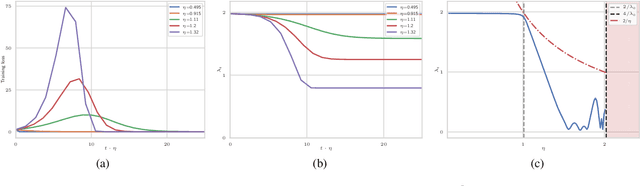
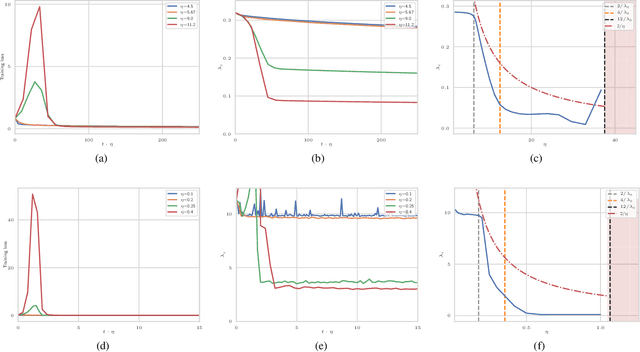
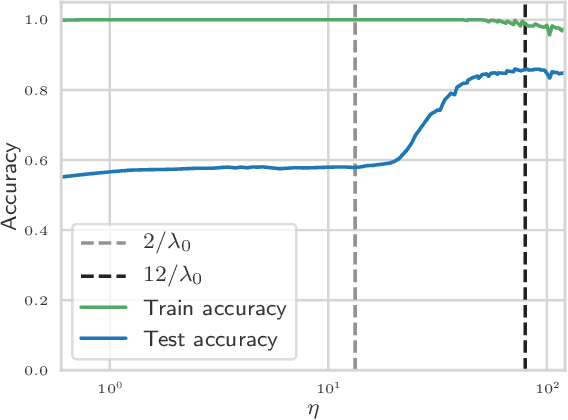
The choice of initial learning rate can have a profound effect on the performance of deep networks. We present a class of neural networks with solvable training dynamics, and confirm their predictions empirically in practical deep learning settings. The networks exhibit sharply distinct behaviors at small and large learning rates. The two regimes are separated by a phase transition. In the small learning rate phase, training can be understood using the existing theory of infinitely wide neural networks. At large learning rates the model captures qualitatively distinct phenomena, including the convergence of gradient descent dynamics to flatter minima. One key prediction of our model is a narrow range of large, stable learning rates. We find good agreement between our model's predictions and training dynamics in realistic deep learning settings. Furthermore, we find that the optimal performance in such settings is often found in the large learning rate phase. We believe our results shed light on characteristics of models trained at different learning rates. In particular, they fill a gap between existing wide neural network theory, and the nonlinear, large learning rate, training dynamics relevant to practice.
On the infinite width limit of neural networks with a standard parameterization
Jan 25, 2020
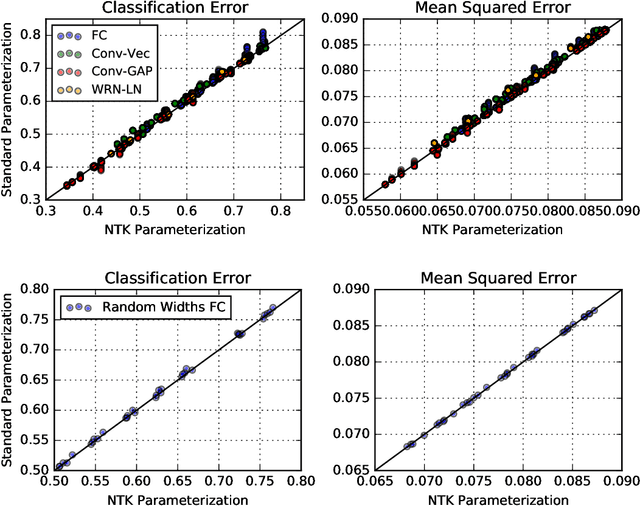
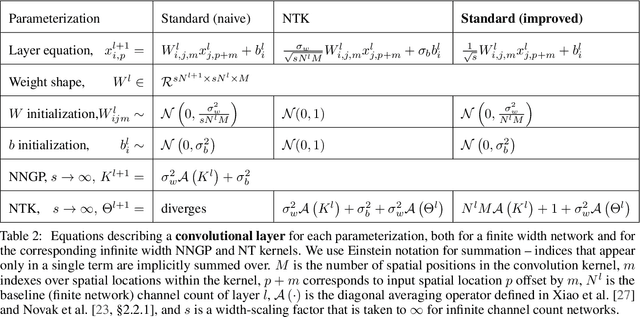
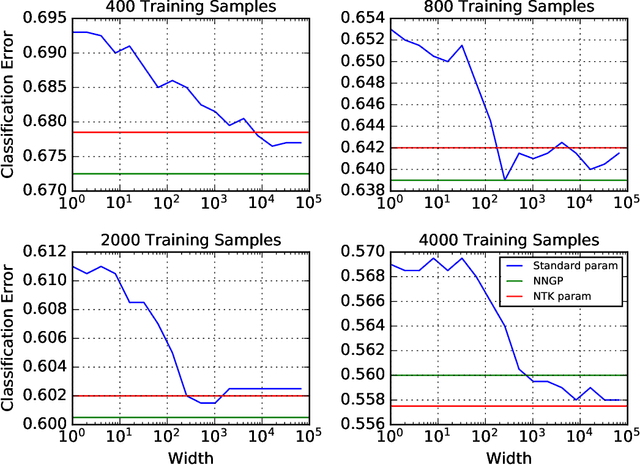
There are currently two parameterizations used to derive fixed kernels corresponding to infinite width neural networks, the NTK (Neural Tangent Kernel) parameterization and the naive standard parameterization. However, the extrapolation of both of these parameterizations to infinite width is problematic. The standard parameterization leads to a divergent neural tangent kernel while the NTK parameterization fails to capture crucial aspects of finite width networks such as: the dependence of training dynamics on relative layer widths, the relative training dynamics of weights and biases, and a nonstandard learning rate scale. Here we propose an improved extrapolation of the standard parameterization that preserves all of these properties as width is taken to infinity and yields a well-defined neural tangent kernel. We show experimentally that the resulting kernels typically achieve similar accuracy to those resulting from an NTK parameterization, but with better correspondence to the parameterization of typical finite width networks. Additionally, with careful tuning of width parameters, the improved standard parameterization kernels can outperform those stemming from an NTK parameterization. We release code implementing this improved standard parameterization as part of the Neural Tangents library at https://github.com/google/neural-tangents.
Neural Tangents: Fast and Easy Infinite Neural Networks in Python
Dec 05, 2019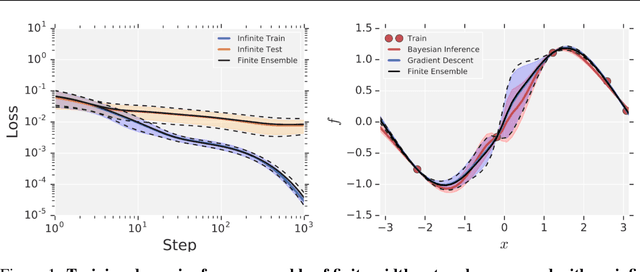
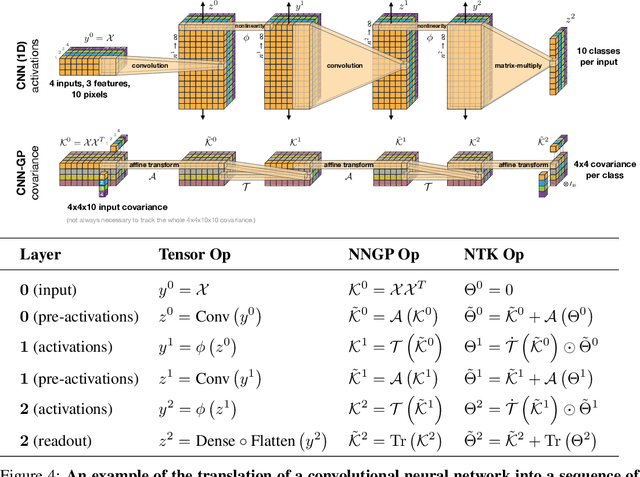
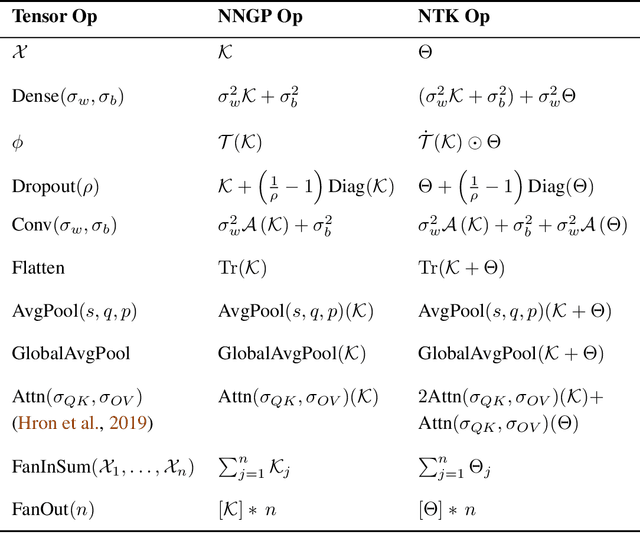
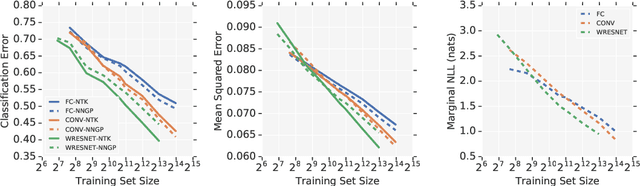
Neural Tangents is a library designed to enable research into infinite-width neural networks. It provides a high-level API for specifying complex and hierarchical neural network architectures. These networks can then be trained and evaluated either at finite-width as usual or in their infinite-width limit. Infinite-width networks can be trained analytically using exact Bayesian inference or using gradient descent via the Neural Tangent Kernel. Additionally, Neural Tangents provides tools to study gradient descent training dynamics of wide but finite networks in either function space or weight space. The entire library runs out-of-the-box on CPU, GPU, or TPU. All computations can be automatically distributed over multiple accelerators with near-linear scaling in the number of devices. Neural Tangents is available at www.github.com/google/neural-tangents. We also provide an accompanying interactive Colab notebook.
Neural reparameterization improves structural optimization
Sep 14, 2019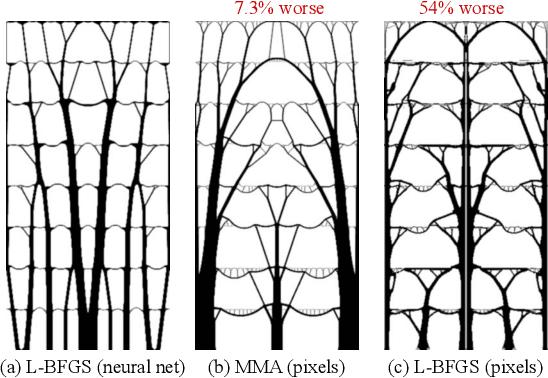
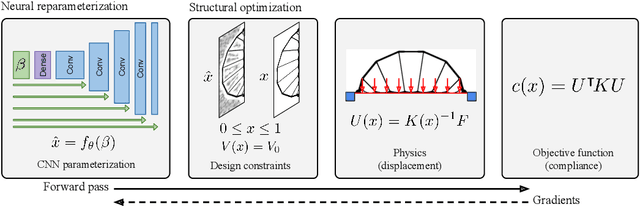
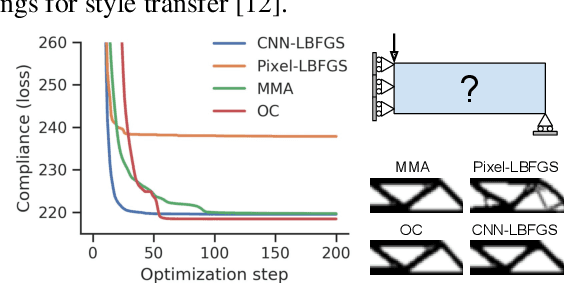
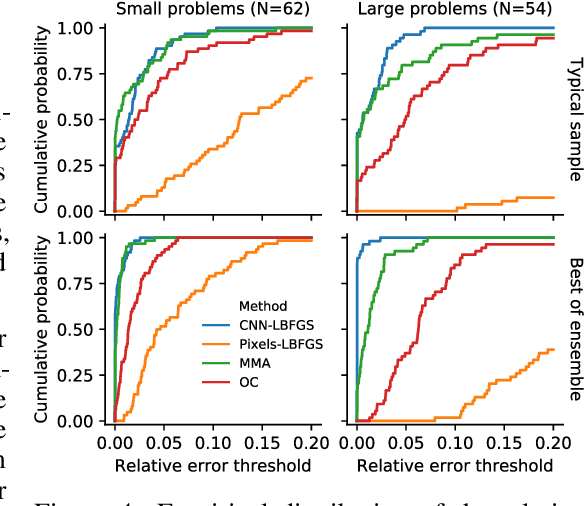
Structural optimization is a popular method for designing objects such as bridge trusses, airplane wings, and optical devices. Unfortunately, the quality of solutions depends heavily on how the problem is parameterized. In this paper, we propose using the implicit bias over functions induced by neural networks to improve the parameterization of structural optimization. Rather than directly optimizing densities on a grid, we instead optimize the parameters of a neural network which outputs those densities. This reparameterization leads to different and often better solutions. On a selection of 116 structural optimization tasks, our approach produces the best design 50% more often than the best baseline method.
Using learned optimizers to make models robust to input noise
Jun 08, 2019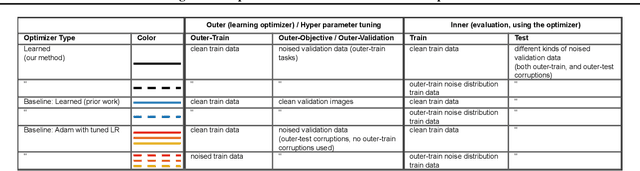
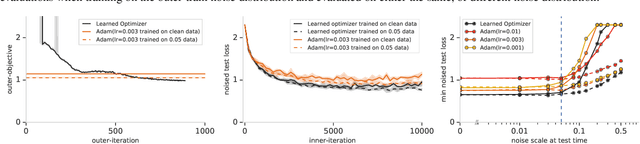
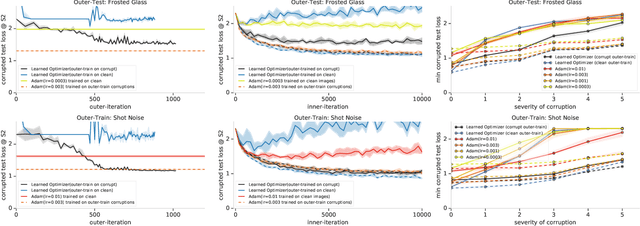
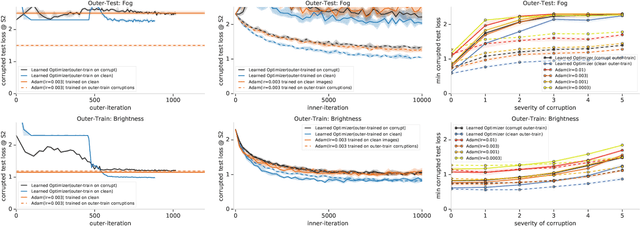
State-of-the art vision models can achieve superhuman performance on image classification tasks when testing and training data come from the same distribution. However, when models are tested on corrupted images (e.g. due to scale changes, translations, or shifts in brightness or contrast), performance degrades significantly. Here, we explore the possibility of meta-training a learned optimizer that can train image classification models such that they are robust to common image corruptions. Specifically, we are interested training models that are more robust to noise distributions not present in the training data. We find that a learned optimizer meta-trained to produce models which are robust to Gaussian noise trains models that are more robust to Gaussian noise at other scales compared to traditional optimizers like Adam. The effect of meta-training is more complicated when targeting a more general set of noise distributions, but led to improved performance on half of held-out corruption tasks. Our results suggest that meta-learning provides a novel approach for studying and improving the robustness of deep learning models.
The Effect of Network Width on Stochastic Gradient Descent and Generalization: an Empirical Study
May 09, 2019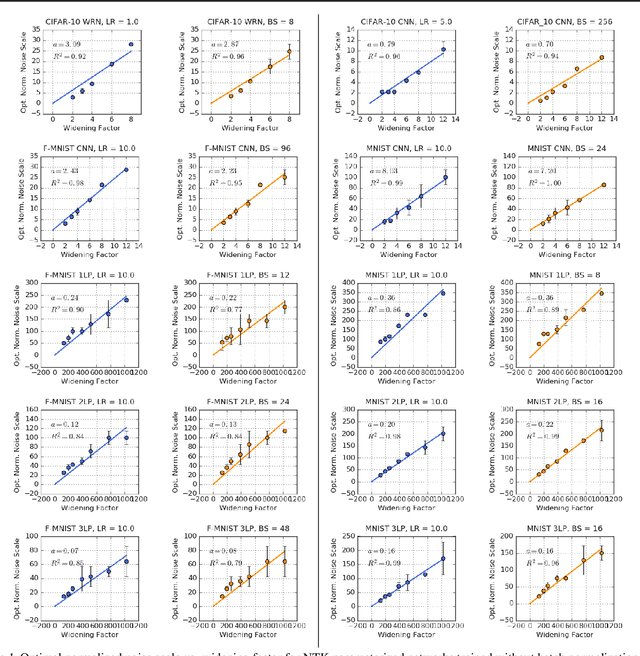
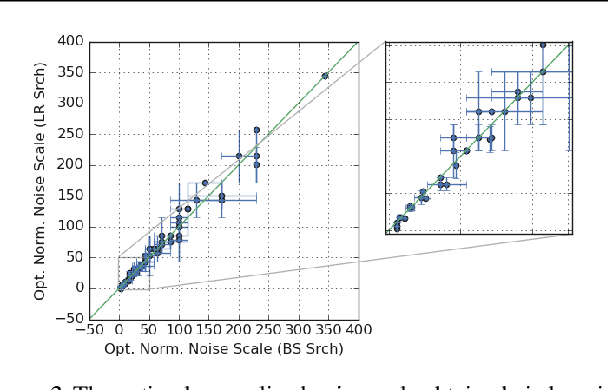
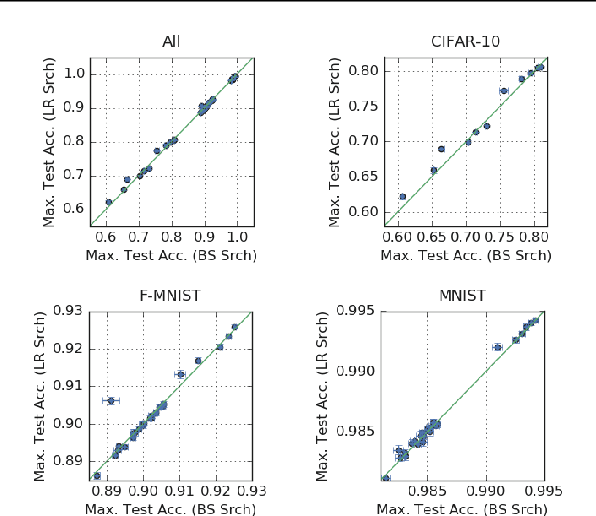

We investigate how the final parameters found by stochastic gradient descent are influenced by over-parameterization. We generate families of models by increasing the number of channels in a base network, and then perform a large hyper-parameter search to study how the test error depends on learning rate, batch size, and network width. We find that the optimal SGD hyper-parameters are determined by a "normalized noise scale," which is a function of the batch size, learning rate, and initialization conditions. In the absence of batch normalization, the optimal normalized noise scale is directly proportional to width. Wider networks, with their higher optimal noise scale, also achieve higher test accuracy. These observations hold for MLPs, ConvNets, and ResNets, and for two different parameterization schemes ("Standard" and "NTK"). We observe a similar trend with batch normalization for ResNets. Surprisingly, since the largest stable learning rate is bounded, the largest batch size consistent with the optimal normalized noise scale decreases as the width increases.
A RAD approach to deep mixture models
Mar 18, 2019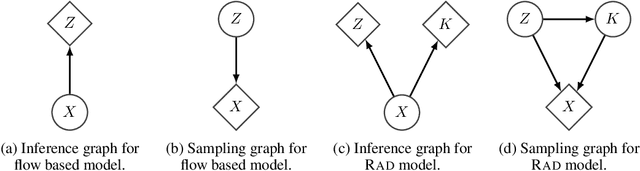
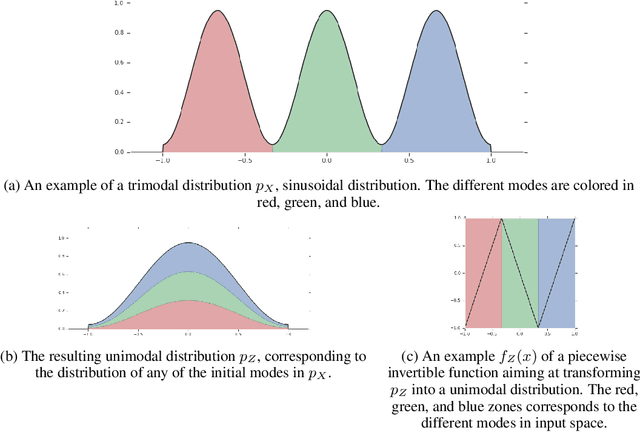
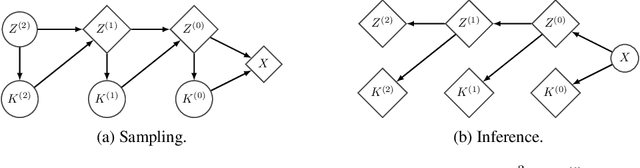
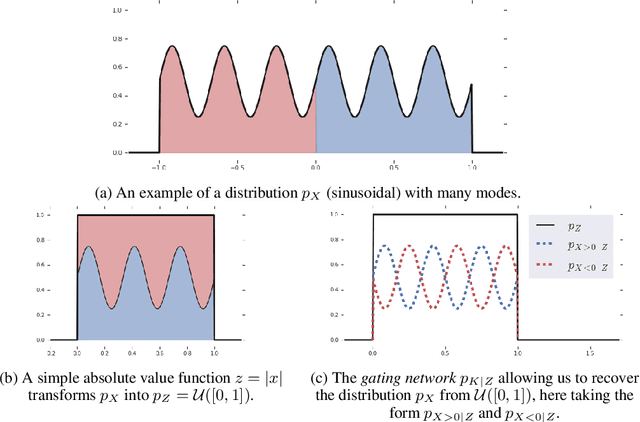
Flow based models such as Real NVP are an extremely powerful approach to density estimation. However, existing flow based models are restricted to transforming continuous densities over a continuous input space into similarly continuous distributions over continuous latent variables. This makes them poorly suited for modeling and representing discrete structures in data distributions, for example class membership or discrete symmetries. To address this difficulty, we present a normalizing flow architecture which relies on domain partitioning using locally invertible functions, and possesses both real and discrete valued latent variables. This Real and Discrete (RAD) approach retains the desirable normalizing flow properties of exact sampling, exact inference, and analytically computable probabilities, while at the same time allowing simultaneous modeling of both continuous and discrete structure in a data distribution.
A Mean Field Theory of Batch Normalization
Mar 05, 2019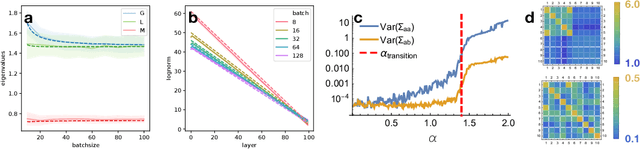
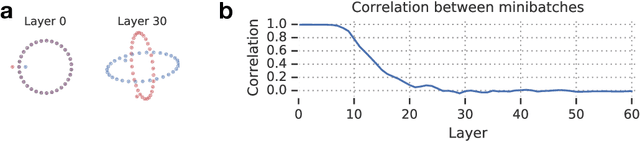
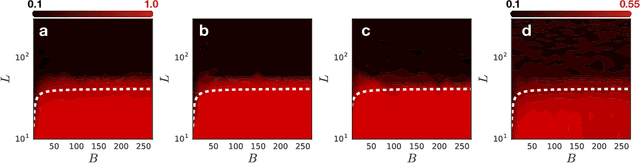
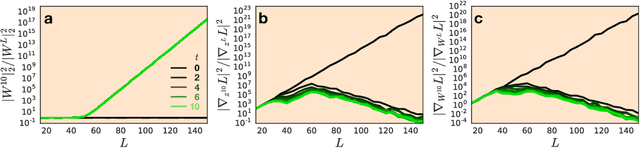
We develop a mean field theory for batch normalization in fully-connected feedforward neural networks. In so doing, we provide a precise characterization of signal propagation and gradient backpropagation in wide batch-normalized networks at initialization. Our theory shows that gradient signals grow exponentially in depth and that these exploding gradients cannot be eliminated by tuning the initial weight variances or by adjusting the nonlinear activation function. Indeed, batch normalization itself is the cause of gradient explosion. As a result, vanilla batch-normalized networks without skip connections are not trainable at large depths for common initialization schemes, a prediction that we verify with a variety of empirical simulations. While gradient explosion cannot be eliminated, it can be reduced by tuning the network close to the linear regime, which improves the trainability of deep batch-normalized networks without residual connections. Finally, we investigate the learning dynamics of batch-normalized networks and observe that after a single step of optimization the networks achieve a relatively stable equilibrium in which gradients have dramatically smaller dynamic range. Our theory leverages Laplace, Fourier, and Gegenbauer transforms and we derive new identities that may be of independent interest.