 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead, Tag, and Parse All at Once, or Fully-neural Dependency Parsing
Jun 05, 2017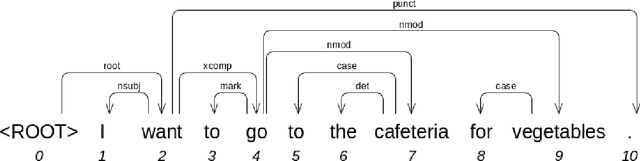

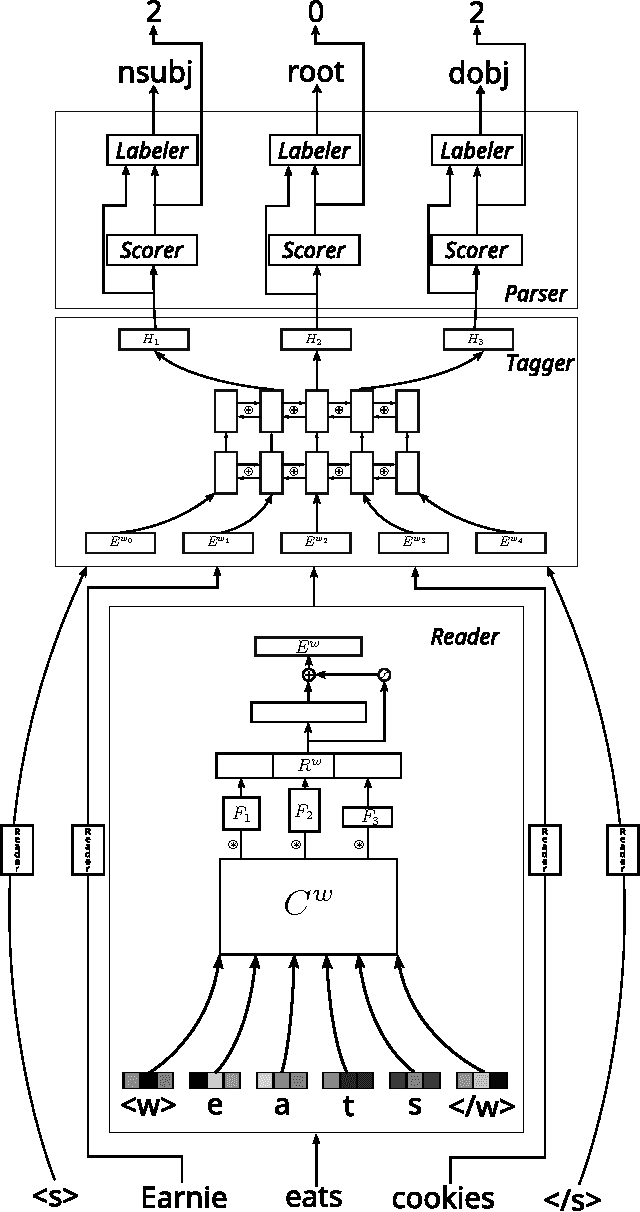
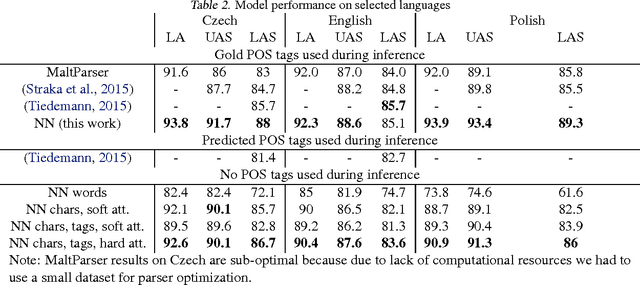
We present a dependency parser implemented as a single deep neural network that reads orthographic representations of words and directly generates dependencies and their labels. Unlike typical approaches to parsing, the model doesn't require part-of-speech (POS) tagging of the sentences. With proper regularization and additional supervision achieved with multitask learning we reach state-of-the-art performance on Slavic languages from the Universal Dependencies treebank: with no linguistic features other than characters, our parser is as accurate as a transition- based system trained on perfect POS tags.
On Multilingual Training of Neural Dependency Parsers
May 29, 2017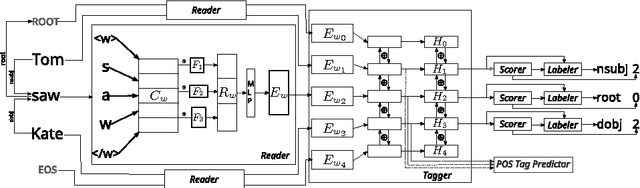
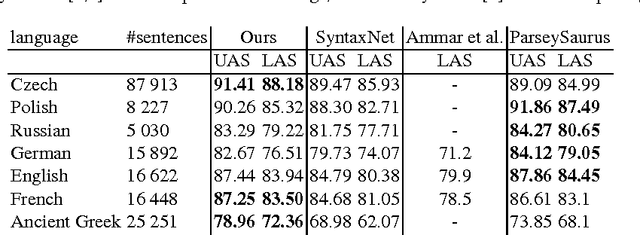
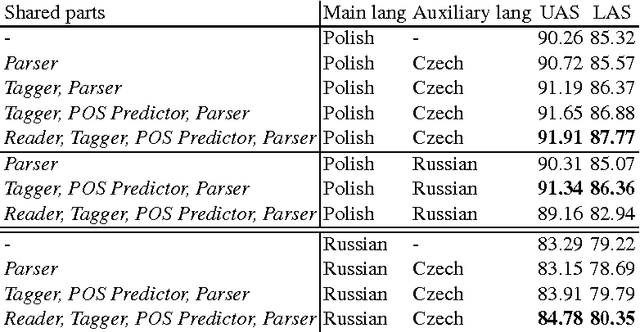

We show that a recently proposed neural dependency parser can be improved by joint training on multiple languages from the same family. The parser is implemented as a deep neural network whose only input is orthographic representations of words. In order to successfully parse, the network has to discover how linguistically relevant concepts can be inferred from word spellings. We analyze the representations of characters and words that are learned by the network to establish which properties of languages were accounted for. In particular we show that the parser has approximately learned to associate Latin characters with their Cyrillic counterparts and that it can group Polish and Russian words that have a similar grammatical function. Finally, we evaluate the parser on selected languages from the Universal Dependencies dataset and show that it is competitive with other recently proposed state-of-the art methods, while having a simple structure.
Regularizing Neural Networks by Penalizing Confident Output Distributions
Jan 23, 2017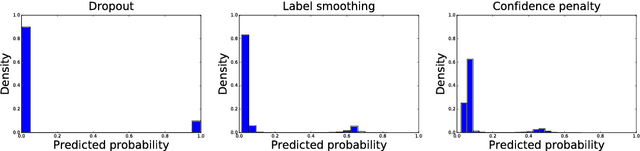
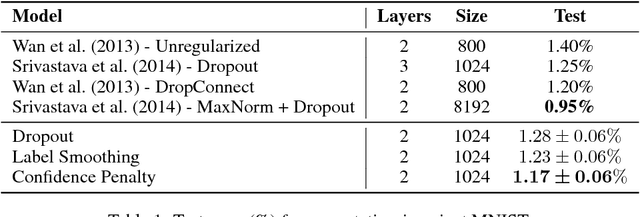
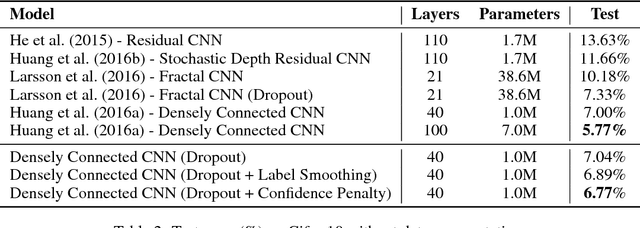
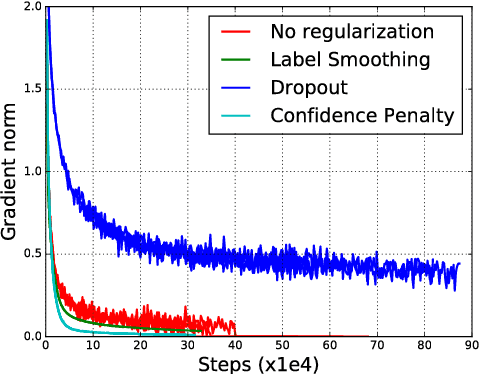
We systematically explore regularizing neural networks by penalizing low entropy output distributions. We show that penalizing low entropy output distributions, which has been shown to improve exploration in reinforcement learning, acts as a strong regularizer in supervised learning. Furthermore, we connect a maximum entropy based confidence penalty to label smoothing through the direction of the KL divergence. We exhaustively evaluate the proposed confidence penalty and label smoothing on 6 common benchmarks: image classification (MNIST and Cifar-10), language modeling (Penn Treebank), machine translation (WMT'14 English-to-German), and speech recognition (TIMIT and WSJ). We find that both label smoothing and the confidence penalty improve state-of-the-art models across benchmarks without modifying existing hyperparameters, suggesting the wide applicability of these regularizers.
Towards better decoding and language model integration in sequence to sequence models
Dec 08, 2016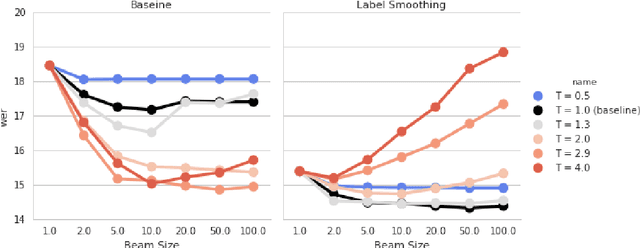

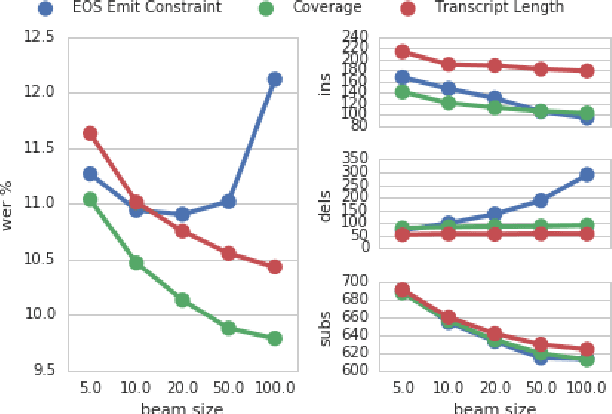
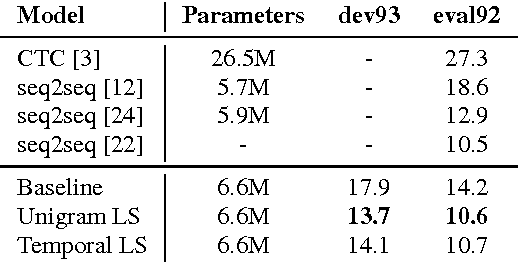
The recently proposed Sequence-to-Sequence (seq2seq) framework advocates replacing complex data processing pipelines, such as an entire automatic speech recognition system, with a single neural network trained in an end-to-end fashion. In this contribution, we analyse an attention-based seq2seq speech recognition system that directly transcribes recordings into characters. We observe two shortcomings: overconfidence in its predictions and a tendency to produce incomplete transcriptions when language models are used. We propose practical solutions to both problems achieving competitive speaker independent word error rates on the Wall Street Journal dataset: without separate language models we reach 10.6% WER, while together with a trigram language model, we reach 6.7% WER.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
End-to-End Attention-based Large Vocabulary Speech Recognition
Mar 14, 2016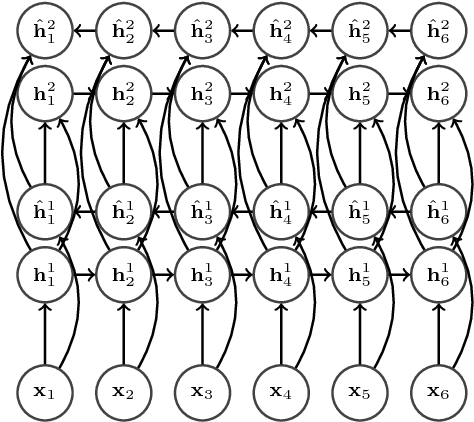
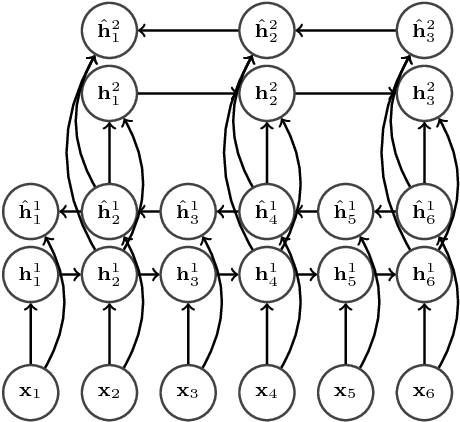
Many of the current state-of-the-art Large Vocabulary Continuous Speech Recognition Systems (LVCSR) are hybrids of neural networks and Hidden Markov Models (HMMs). Most of these systems contain separate components that deal with the acoustic modelling, language modelling and sequence decoding. We investigate a more direct approach in which the HMM is replaced with a Recurrent Neural Network (RNN) that performs sequence prediction directly at the character level. Alignment between the input features and the desired character sequence is learned automatically by an attention mechanism built into the RNN. For each predicted character, the attention mechanism scans the input sequence and chooses relevant frames. We propose two methods to speed up this operation: limiting the scan to a subset of most promising frames and pooling over time the information contained in neighboring frames, thereby reducing source sequence length. Integrating an n-gram language model into the decoding process yields recognition accuracies similar to other HMM-free RNN-based approaches.
Task Loss Estimation for Sequence Prediction
Jan 19, 2016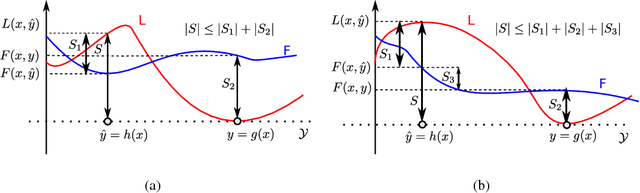
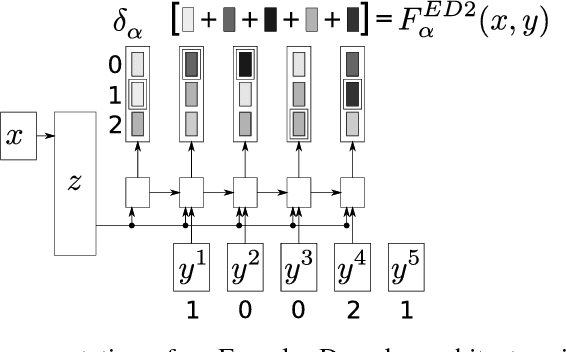
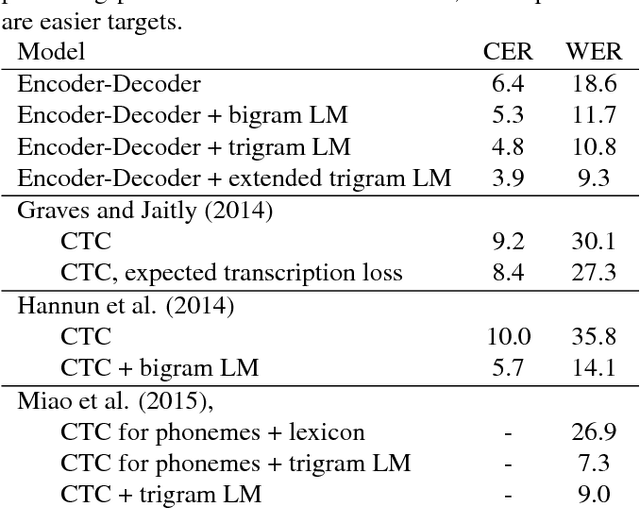
Often, the performance on a supervised machine learning task is evaluated with a emph{task loss} function that cannot be optimized directly. Examples of such loss functions include the classification error, the edit distance and the BLEU score. A common workaround for this problem is to instead optimize a emph{surrogate loss} function, such as for instance cross-entropy or hinge loss. In order for this remedy to be effective, it is important to ensure that minimization of the surrogate loss results in minimization of the task loss, a condition that we call emph{consistency with the task loss}. In this work, we propose another method for deriving differentiable surrogate losses that provably meet this requirement. We focus on the broad class of models that define a score for every input-output pair. Our idea is that this score can be interpreted as an estimate of the task loss, and that the estimation error may be used as a consistent surrogate loss. A distinct feature of such an approach is that it defines the desirable value of the score for every input-output pair. We use this property to design specialized surrogate losses for Encoder-Decoder models often used for sequence prediction tasks. In our experiment, we benchmark on the task of speech recognition. Using a new surrogate loss instead of cross-entropy to train an Encoder-Decoder speech recognizer brings a significant ~13% relative improvement in terms of Character Error Rate (CER) in the case when no extra corpora are used for language modeling.
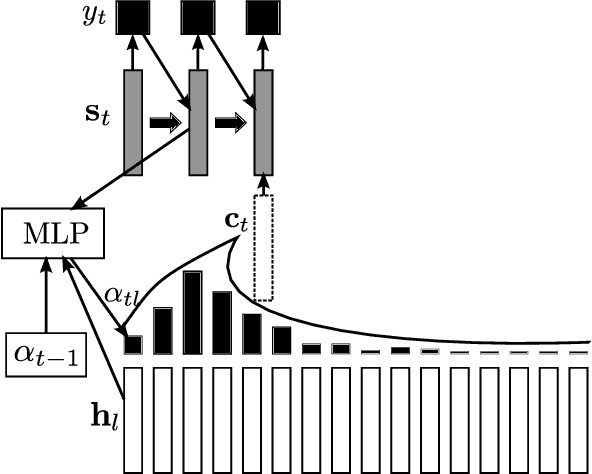
Attention-Based Models for Speech Recognition
Jun 24, 2015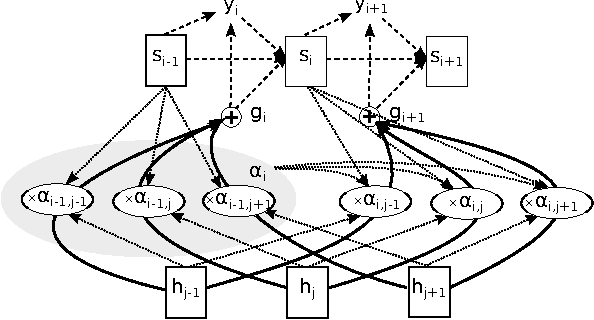

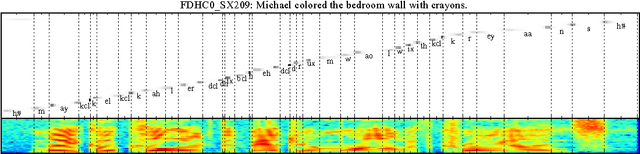
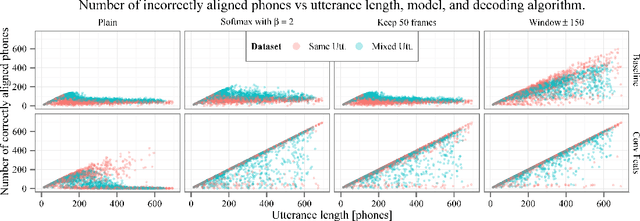
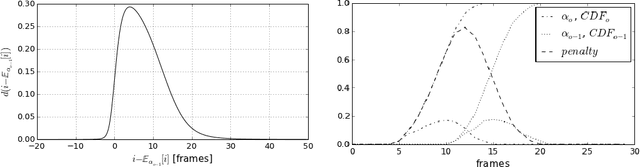
Recurrent sequence generators conditioned on input data through an attention mechanism have recently shown very good performance on a range of tasks in- cluding machine translation, handwriting synthesis and image caption gen- eration. We extend the attention-mechanism with features needed for speech recognition. We show that while an adaptation of the model used for machine translation in reaches a competitive 18.7% phoneme error rate (PER) on the TIMIT phoneme recognition task, it can only be applied to utterances which are roughly as long as the ones it was trained on. We offer a qualitative explanation of this failure and propose a novel and generic method of adding location-awareness to the attention mechanism to alleviate this issue. The new method yields a model that is robust to long inputs and achieves 18% PER in single utterances and 20% in 10-times longer (repeated) utterances. Finally, we propose a change to the at- tention mechanism that prevents it from concentrating too much on single frames, which further reduces PER to 17.6% level.
Blocks and Fuel: Frameworks for deep learning
Jun 01, 2015We introduce two Python frameworks to train neural networks on large datasets: Blocks and Fuel. Blocks is based on Theano, a linear algebra compiler with CUDA-support. It facilitates the training of complex neural network models by providing parametrized Theano operations, attaching metadata to Theano's symbolic computational graph, and providing an extensive set of utilities to assist training the networks, e.g. training algorithms, logging, monitoring, visualization, and serialization. Fuel provides a standard format for machine learning datasets. It allows the user to easily iterate over large datasets, performing many types of pre-processing on the fly.
End-to-end Continuous Speech Recognition using Attention-based Recurrent NN: First Results
Dec 04, 2014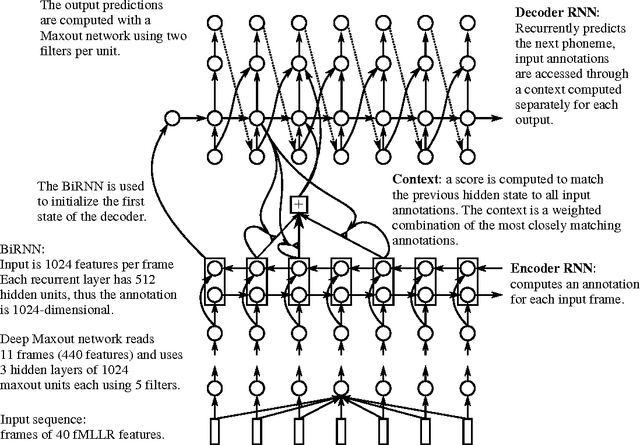
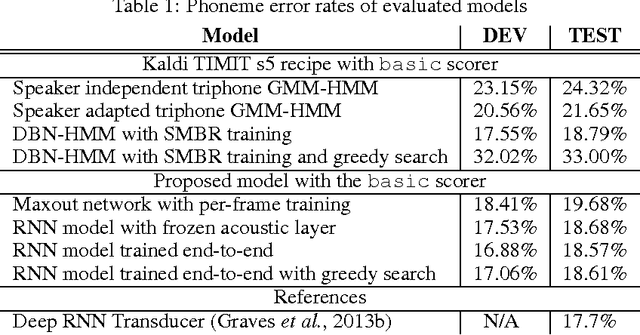
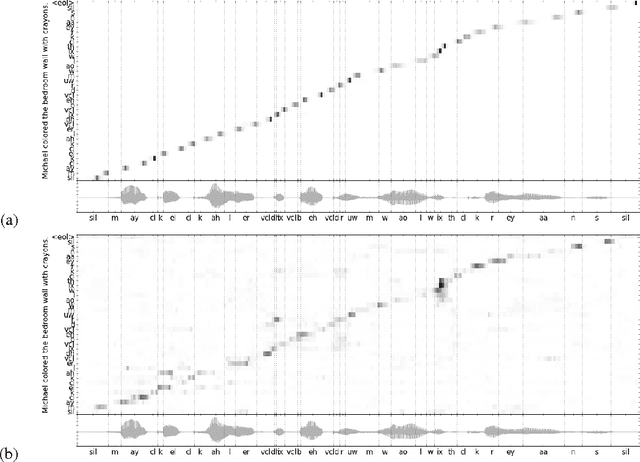
We replace the Hidden Markov Model (HMM) which is traditionally used in in continuous speech recognition with a bi-directional recurrent neural network encoder coupled to a recurrent neural network decoder that directly emits a stream of phonemes. The alignment between the input and output sequences is established using an attention mechanism: the decoder emits each symbol based on a context created with a subset of input symbols elected by the attention mechanism. We report initial results demonstrating that this new approach achieves phoneme error rates that are comparable to the state-of-the-art HMM-based decoders, on the TIMIT dataset.