 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsequentialist Objectives and Catastrophe
Mar 16, 2026Because human preferences are too complex to codify, AIs operate with misspecified objectives. Optimizing such objectives often produces undesirable outcomes; this phenomenon is known as reward hacking. Such outcomes are not necessarily catastrophic. Indeed, most examples of reward hacking in previous literature are benign. And typically, objectives can be modified to resolve the issue. We study the prospect of catastrophic outcomes induced by AIs operating in complex environments. We argue that, when capabilities are sufficiently advanced, pursuing a fixed consequentialist objective tends to result in catastrophic outcomes. We formalize this by establishing conditions that provably lead to such outcomes. Under these conditions, simple or random behavior is safe. Catastrophic risk arises due to extraordinary competence rather than incompetence. With a fixed consequentialist objective, avoiding catastrophe requires constraining AI capabilities. In fact, constraining capabilities the right amount not only averts catastrophe but yields valuable outcomes. Our results apply to any objective produced by modern industrial AI development pipelines.
Distillation Robustifies Unlearning
Jun 06, 2025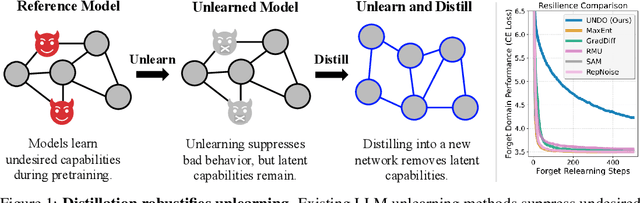

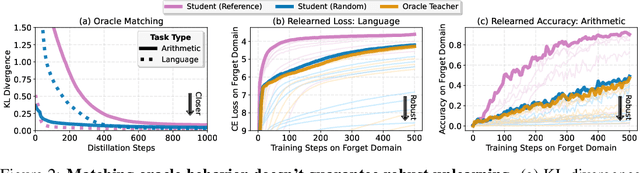
Current LLM unlearning methods are not robust: they can be reverted easily with a few steps of finetuning. This is true even for the idealized unlearning method of training to imitate an oracle model that was never exposed to unwanted information, suggesting that output-based finetuning is insufficient to achieve robust unlearning. In a similar vein, we find that training a randomly initialized student to imitate an unlearned model transfers desired behaviors while leaving undesired capabilities behind. In other words, distillation robustifies unlearning. Building on this insight, we propose Unlearn-Noise-Distill-on-Outputs (UNDO), a scalable method that distills an unlearned model into a partially noised copy of itself. UNDO introduces a tunable tradeoff between compute cost and robustness, establishing a new Pareto frontier on synthetic language and arithmetic tasks. At its strongest setting, UNDO matches the robustness of a model retrained from scratch with perfect data filtering while using only 60-80% of the compute and requiring only 0.01% of the pretraining data to be labeled. We also show that UNDO robustifies unlearning on the more realistic Weapons of Mass Destruction Proxy (WMDP) benchmark. Since distillation is widely used in practice, incorporating an unlearning step beforehand offers a convenient path to robust capability removal.
The Persian Rug: solving toy models of superposition using large-scale symmetries
Oct 15, 2024



We present a complete mechanistic description of the algorithm learned by a minimal non-linear sparse data autoencoder in the limit of large input dimension. The model, originally presented in arXiv:2209.10652, compresses sparse data vectors through a linear layer and decompresses using another linear layer followed by a ReLU activation. We notice that when the data is permutation symmetric (no input feature is privileged) large models reliably learn an algorithm that is sensitive to individual weights only through their large-scale statistics. For these models, the loss function becomes analytically tractable. Using this understanding, we give the explicit scalings of the loss at high sparsity, and show that the model is near-optimal among recently proposed architectures. In particular, changing or adding to the activation function any elementwise or filtering operation can at best improve the model's performance by a constant factor. Finally, we forward-engineer a model with the requisite symmetries and show that its loss precisely matches that of the trained models. Unlike the trained model weights, the low randomness in the artificial weights results in miraculous fractal structures resembling a Persian rug, to which the algorithm is oblivious. Our work contributes to neural network interpretability by introducing techniques for understanding the structure of autoencoders. Code to reproduce our results can be found at https://github.com/KfirD/PersianRug .