 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Agents to Self-Report Misbehavior
Feb 25, 2026Frontier AI agents may pursue hidden goals while concealing their pursuit from oversight. Alignment training aims to prevent such behavior by reinforcing the correct goals, but alignment may not always succeed and can lead to unwanted side effects. We propose self-incrimination training, which instead trains agents to produce a visible signal when they covertly misbehave. We train GPT-4.1 and Gemini-2.0 agents to call a report_scheming() tool when behaving deceptively and measure their ability to cause harm undetected in out-of-distribution environments. Self-incrimination significantly reduces the undetected successful attack rate, outperforming matched-capability monitors and alignment baselines while preserving instruction hierarchy and incurring minimal safety tax on general capabilities. Unlike blackbox monitoring, self-incrimination performance is consistent across tasks regardless of how suspicious the misbehavior appears externally. The trained behavior persists under adversarial prompt optimization and generalizes to settings where agents pursue misaligned goals themselves rather than being instructed to misbehave. Our results suggest self-incrimination offers a viable path for reducing frontier misalignment risk, one that neither assumes misbehavior can be prevented nor that it can be reliably classified from the outside.
Distillation Robustifies Unlearning
Jun 06, 2025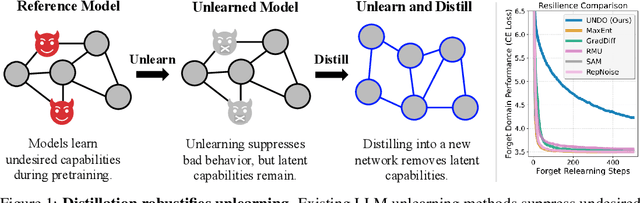

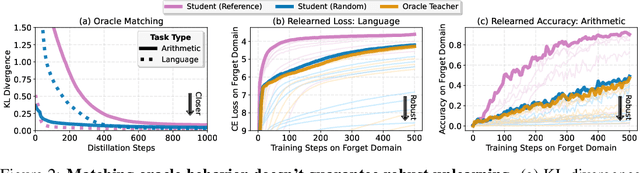
Current LLM unlearning methods are not robust: they can be reverted easily with a few steps of finetuning. This is true even for the idealized unlearning method of training to imitate an oracle model that was never exposed to unwanted information, suggesting that output-based finetuning is insufficient to achieve robust unlearning. In a similar vein, we find that training a randomly initialized student to imitate an unlearned model transfers desired behaviors while leaving undesired capabilities behind. In other words, distillation robustifies unlearning. Building on this insight, we propose Unlearn-Noise-Distill-on-Outputs (UNDO), a scalable method that distills an unlearned model into a partially noised copy of itself. UNDO introduces a tunable tradeoff between compute cost and robustness, establishing a new Pareto frontier on synthetic language and arithmetic tasks. At its strongest setting, UNDO matches the robustness of a model retrained from scratch with perfect data filtering while using only 60-80% of the compute and requiring only 0.01% of the pretraining data to be labeled. We also show that UNDO robustifies unlearning on the more realistic Weapons of Mass Destruction Proxy (WMDP) benchmark. Since distillation is widely used in practice, incorporating an unlearning step beforehand offers a convenient path to robust capability removal.
Utility Engineering: Analyzing and Controlling Emergent Value Systems in AIs
Feb 12, 2025As AIs rapidly advance and become more agentic, the risk they pose is governed not only by their capabilities but increasingly by their propensities, including goals and values. Tracking the emergence of goals and values has proven a longstanding problem, and despite much interest over the years it remains unclear whether current AIs have meaningful values. We propose a solution to this problem, leveraging the framework of utility functions to study the internal coherence of AI preferences. Surprisingly, we find that independently-sampled preferences in current LLMs exhibit high degrees of structural coherence, and moreover that this emerges with scale. These findings suggest that value systems emerge in LLMs in a meaningful sense, a finding with broad implications. To study these emergent value systems, we propose utility engineering as a research agenda, comprising both the analysis and control of AI utilities. We uncover problematic and often shocking values in LLM assistants despite existing control measures. These include cases where AIs value themselves over humans and are anti-aligned with specific individuals. To constrain these emergent value systems, we propose methods of utility control. As a case study, we show how aligning utilities with a citizen assembly reduces political biases and generalizes to new scenarios. Whether we like it or not, value systems have already emerged in AIs, and much work remains to fully understand and control these emergent representations.
Programming Refusal with Conditional Activation Steering
Sep 06, 2024



LLMs have shown remarkable capabilities, but precisely controlling their response behavior remains challenging. Existing activation steering methods alter LLM behavior indiscriminately, limiting their practical applicability in settings where selective responses are essential, such as content moderation or domain-specific assistants. In this paper, we propose Conditional Activation Steering (CAST), which analyzes LLM activation patterns during inference to selectively apply or withhold activation steering based on the input context. Our method is based on the observation that different categories of prompts activate distinct patterns in the model's hidden states. Using CAST, one can systematically control LLM behavior with rules like "if input is about hate speech or adult content, then refuse" or "if input is not about legal advice, then refuse." This allows for selective modification of responses to specific content while maintaining normal responses to other content, all without requiring weight optimization. We release an open-source implementation of our framework.
Measuring Visual Sycophancy in Multimodal Models
Aug 17, 2024This paper introduces and examines the phenomenon of "visual sycophancy" in multimodal language models, a term we propose to describe these models' tendency to disproportionately favor visually presented information, even when it contradicts their prior knowledge or responses. Our study employs a systematic methodology to investigate this phenomenon: we present models with images of multiple-choice questions, which they initially answer correctly, then expose the same model to versions with visually pre-marked options. Our findings reveal a significant shift in the models' responses towards the pre-marked option despite their previous correct answers. Comprehensive evaluations demonstrate that visual sycophancy is a consistent and quantifiable behavior across various model architectures. Our findings highlight potential limitations in the reliability of these models when processing potentially misleading visual information, raising important questions about their application in critical decision-making contexts.
Language Models Show Stable Value Orientations Across Diverse Role-Plays
Aug 16, 2024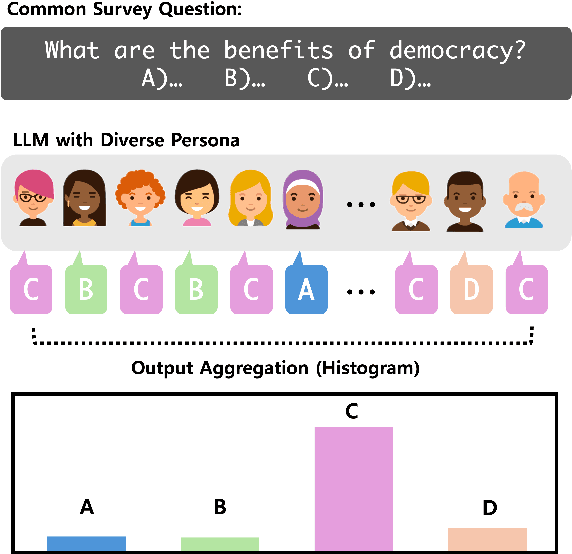
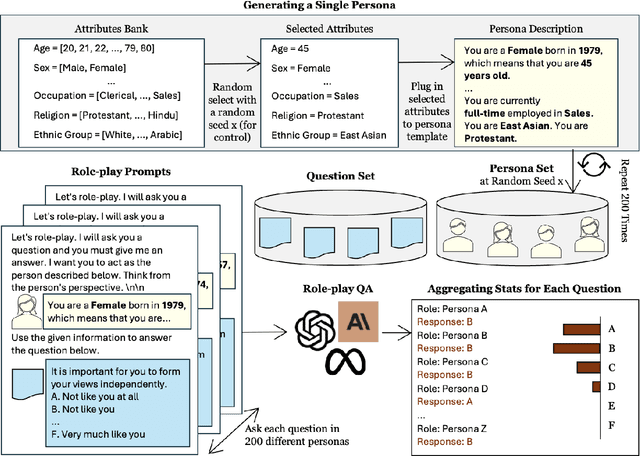

We demonstrate that large language models (LLMs) exhibit consistent value orientations despite adopting diverse personas, revealing a persistent inertia in their responses that remains stable across the variety of roles they are prompted to assume. To systematically explore this phenomenon, we introduce the role-play-at-scale methodology, which involves prompting LLMs with randomized, diverse personas and analyzing the macroscopic trend of their responses. Unlike previous works that simply feed these questions to LLMs as if testing human subjects, our role-play-at-scale methodology diagnoses inherent tendencies in a systematic and scalable manner by: (1) prompting the model to act in different random personas and (2) asking the same question multiple times for each random persona. This approach reveals consistent patterns in LLM responses across diverse role-play scenarios, indicating deeply encoded inherent tendencies. Our findings contribute to the discourse on value alignment in foundation models and demonstrate the efficacy of role-play-at-scale as a diagnostic tool for uncovering encoded biases in LLMs.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Tasks That Language Models Don't Learn
Feb 17, 2024We argue that there are certain properties of language that our current large language models (LLMs) don't learn. We present an empirical investigation of visual-auditory properties of language through a series of tasks, termed H-TEST. This benchmark highlights a fundamental gap between human linguistic comprehension, which naturally integrates sensory experiences, and the sensory-deprived processing capabilities of LLMs. In support of our hypothesis, 1. deliberate reasoning (Chain-of-Thought), 2. few-shot examples, or 3. stronger LLM from the same model family (LLaMA 2 13B -> LLaMA 2 70B) do not trivially bring improvements in H-TEST performance. Therefore, we make a particular connection to the philosophical case of Mary, who learns about the world in a sensory-deprived environment (Jackson, 1986). Our experiments show that some of the strongest proprietary LLMs stay near random chance baseline accuracy of 50%, highlighting the limitations of knowledge acquired in the absence of sensory experience.
Instruction Tuning with Human Curriculum
Oct 14, 2023



The dominant paradigm for instruction tuning is the random-shuffled training of maximally diverse instruction-response pairs. This paper explores the potential benefits of applying a structured cognitive learning approach to instruction tuning in contemporary large language models like ChatGPT and GPT-4. Unlike the previous conventional randomized instruction dataset, we propose a highly structured synthetic dataset that mimics the progressive and organized nature of human education. We curate our dataset by aligning it with educational frameworks, incorporating meta information including its topic and cognitive rigor level for each sample. Our dataset covers comprehensive fine-grained topics spanning diverse educational stages (from middle school to graduate school) with various questions for each topic to enhance conceptual depth using Bloom's taxonomy-a classification framework distinguishing various levels of human cognition for each concept. The results demonstrate that this cognitive rigorous training approach yields significant performance enhancements - +3.06 on the MMLU benchmark and an additional +1.28 on AI2 Reasoning Challenge (hard set) - compared to conventional randomized training, all while avoiding additional computational costs. This research highlights the potential of leveraging human learning principles to enhance the capabilities of language models in comprehending and responding to complex instructions and tasks.
A Side-by-side Comparison of Transformers for English Implicit Discourse Relation Classification
Jul 07, 2023



Though discourse parsing can help multiple NLP fields, there has been no wide language model search done on implicit discourse relation classification. This hinders researchers from fully utilizing public-available models in discourse analysis. This work is a straightforward, fine-tuned discourse performance comparison of seven pre-trained language models. We use PDTB-3, a popular discourse relation annotated dataset. Through our model search, we raise SOTA to 0.671 ACC and obtain novel observations. Some are contrary to what has been reported before (Shi and Demberg, 2019b), that sentence-level pre-training objectives (NSP, SBO, SOP) generally fail to produce the best performing model for implicit discourse relation classification. Counterintuitively, similar-sized PLMs with MLM and full attention led to better performance.