 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation Robustifies Unlearning
Jun 06, 2025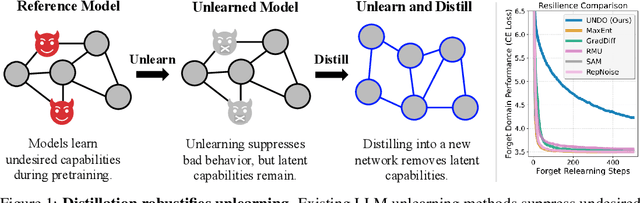

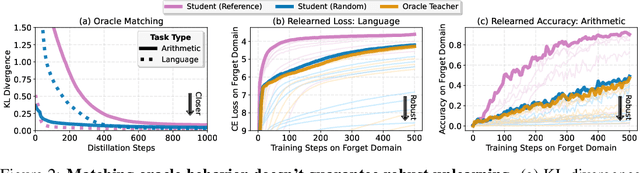
Current LLM unlearning methods are not robust: they can be reverted easily with a few steps of finetuning. This is true even for the idealized unlearning method of training to imitate an oracle model that was never exposed to unwanted information, suggesting that output-based finetuning is insufficient to achieve robust unlearning. In a similar vein, we find that training a randomly initialized student to imitate an unlearned model transfers desired behaviors while leaving undesired capabilities behind. In other words, distillation robustifies unlearning. Building on this insight, we propose Unlearn-Noise-Distill-on-Outputs (UNDO), a scalable method that distills an unlearned model into a partially noised copy of itself. UNDO introduces a tunable tradeoff between compute cost and robustness, establishing a new Pareto frontier on synthetic language and arithmetic tasks. At its strongest setting, UNDO matches the robustness of a model retrained from scratch with perfect data filtering while using only 60-80% of the compute and requiring only 0.01% of the pretraining data to be labeled. We also show that UNDO robustifies unlearning on the more realistic Weapons of Mass Destruction Proxy (WMDP) benchmark. Since distillation is widely used in practice, incorporating an unlearning step beforehand offers a convenient path to robust capability removal.
Direct Inversion: Optimization-Free Text-Driven Real Image Editing with Diffusion Models
Nov 15, 2022



With the rise of large, publicly-available text-to-image diffusion models, text-guided real image editing has garnered much research attention recently. Existing methods tend to either rely on some form of per-instance or per-task fine-tuning and optimization, require multiple novel views, or they inherently entangle preservation of real image identity, semantic coherence, and faithfulness to text guidance. In this paper, we propose an optimization-free and zero fine-tuning framework that applies complex and non-rigid edits to a single real image via a text prompt, avoiding all the pitfalls described above. Using widely-available generic pre-trained text-to-image diffusion models, we demonstrate the ability to modulate pose, scene, background, style, color, and even racial identity in an extremely flexible manner through a single target text detailing the desired edit. Furthermore, our method, which we name $\textit{Direct Inversion}$, proposes multiple intuitively configurable hyperparameters to allow for a wide range of types and extents of real image edits. We prove our method's efficacy in producing high-quality, diverse, semantically coherent, and faithful real image edits through applying it on a variety of inputs for a multitude of tasks. We also formalize our method in well-established theory, detail future experiments for further improvement, and compare against state-of-the-art attempts.
Model-Advantage Optimization for Model-Based Reinforcement Learning
Jun 26, 2021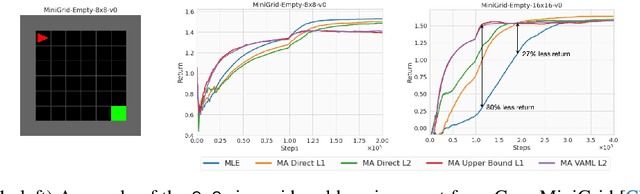
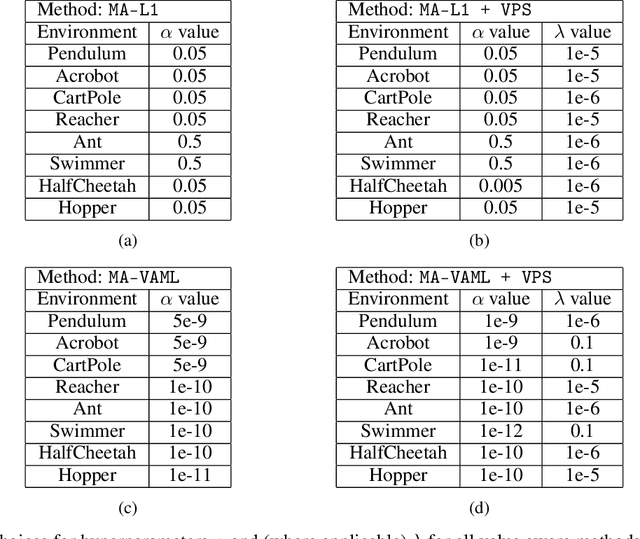
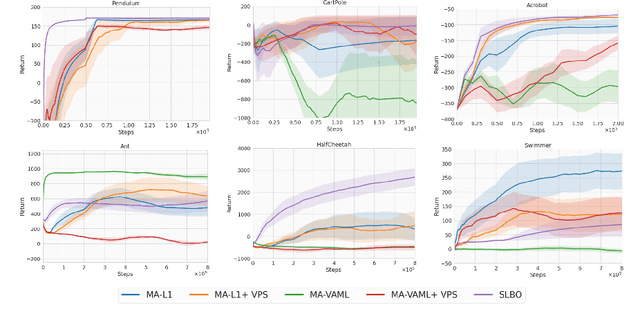
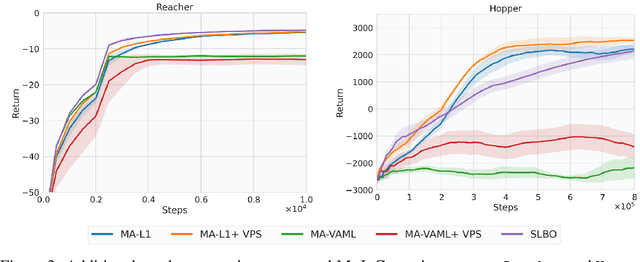
Model-based Reinforcement Learning (MBRL) algorithms have been traditionally designed with the goal of learning accurate dynamics of the environment. This introduces a mismatch between the objectives of model-learning and the overall learning problem of finding an optimal policy. Value-aware model learning, an alternative model-learning paradigm to maximum likelihood, proposes to inform model-learning through the value function of the learnt policy. While this paradigm is theoretically sound, it does not scale beyond toy settings. In this work, we propose a novel value-aware objective that is an upper bound on the absolute performance difference of a policy across two models. Further, we propose a general purpose algorithm that modifies the standard MBRL pipeline -- enabling learning with value aware objectives. Our proposed objective, in conjunction with this algorithm, is the first successful instantiation of value-aware MBRL on challenging continuous control environments, outperforming previous value-aware objectives and with competitive performance w.r.t. MLE-based MBRL approaches.