 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecontextualization Mitigates Specification Gaming without Modifying the Specification
Dec 22, 2025Developers often struggle to specify correct training labels and rewards. Perhaps they don't need to. We propose recontextualization, which reduces how often language models "game" training signals, performing misbehaviors those signals mistakenly reinforce. We show recontextualization prevents models from learning to 1) prioritize evaluation metrics over chat response quality; 2) special-case code to pass incorrect tests; 3) lie to users; and 4) become sycophantic. Our method works by generating completions from prompts discouraging misbehavior and then recontextualizing them as though they were in response to prompts permitting misbehavior. Recontextualization trains language models to resist misbehavior even when instructions permit it. This mitigates the reinforcement of misbehavior from misspecified training signals, reducing specification gaming without improving the supervision signal.
Distillation Robustifies Unlearning
Jun 06, 2025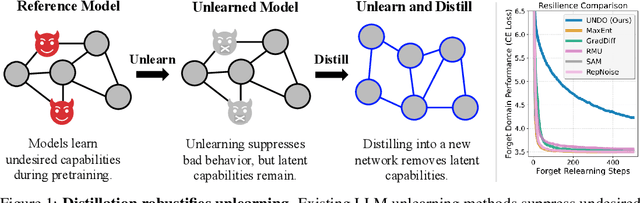

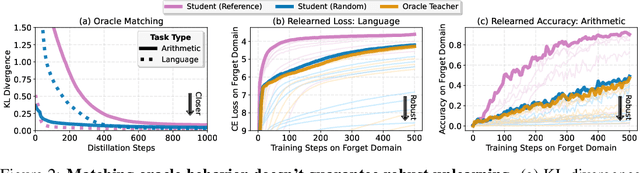
Current LLM unlearning methods are not robust: they can be reverted easily with a few steps of finetuning. This is true even for the idealized unlearning method of training to imitate an oracle model that was never exposed to unwanted information, suggesting that output-based finetuning is insufficient to achieve robust unlearning. In a similar vein, we find that training a randomly initialized student to imitate an unlearned model transfers desired behaviors while leaving undesired capabilities behind. In other words, distillation robustifies unlearning. Building on this insight, we propose Unlearn-Noise-Distill-on-Outputs (UNDO), a scalable method that distills an unlearned model into a partially noised copy of itself. UNDO introduces a tunable tradeoff between compute cost and robustness, establishing a new Pareto frontier on synthetic language and arithmetic tasks. At its strongest setting, UNDO matches the robustness of a model retrained from scratch with perfect data filtering while using only 60-80% of the compute and requiring only 0.01% of the pretraining data to be labeled. We also show that UNDO robustifies unlearning on the more realistic Weapons of Mass Destruction Proxy (WMDP) benchmark. Since distillation is widely used in practice, incorporating an unlearning step beforehand offers a convenient path to robust capability removal.