 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimetic Initialization of MLPs
Feb 06, 2026Mimetic initialization uses pretrained models as case studies of good initialization, using observations of structures in trained weights to inspire new, simple initialization techniques. So far, it has been applied only to spatial mixing layers, such convolutional, self-attention, and state space layers. In this work, we present the first attempt to apply the method to channel mixing layers, namely multilayer perceptrons (MLPs). Our extremely simple technique for MLPs -- to give the first layer a nonzero mean -- speeds up training on small-scale vision tasks like CIFAR-10 and ImageNet-1k. Though its effect is much smaller than spatial mixing initializations, it can be used in conjunction with them for an additional positive effect.
Antidistillation Fingerprinting
Feb 03, 2026Model distillation enables efficient emulation of frontier large language models (LLMs), creating a need for robust mechanisms to detect when a third-party student model has trained on a teacher model's outputs. However, existing fingerprinting techniques that could be used to detect such distillation rely on heuristic perturbations that impose a steep trade-off between generation quality and fingerprinting strength, often requiring significant degradation of utility to ensure the fingerprint is effectively internalized by the student. We introduce antidistillation fingerprinting (ADFP), a principled approach that aligns the fingerprinting objective with the student's learning dynamics. Building upon the gradient-based framework of antidistillation sampling, ADFP utilizes a proxy model to identify and sample tokens that directly maximize the expected detectability of the fingerprint in the student after fine-tuning, rather than relying on the incidental absorption of the un-targeted biases of a more naive watermark. Experiments on GSM8K and OASST1 benchmarks demonstrate that ADFP achieves a significant Pareto improvement over state-of-the-art baselines, yielding stronger detection confidence with minimal impact on utility, even when the student model's architecture is unknown.
When Should We Introduce Safety Interventions During Pretraining?
Jan 11, 2026Ensuring the safety of language models in high-stakes settings remains a pressing challenge, as aligned behaviors are often brittle and easily undone by adversarial pressure or downstream finetuning. Prior work has shown that interventions applied during pretraining, such as rephrasing harmful content, can substantially improve the safety of the resulting models. In this paper, we study the fundamental question: "When during pretraining should safety interventions be introduced?" We keep the underlying data fixed and vary only the choice of a safety curriculum: the timing of these interventions, i.e., after 0%, 20%, or 60% of the pretraining token budget. We find that introducing interventions earlier generally yields more robust models with no increase in overrefusal rates, with the clearest benefits appearing after downstream, benign finetuning. We also see clear benefits in the steerability of models towards safer generations. Finally, we observe that earlier interventions reshape internal representations: linear probes more cleanly separate safe vs harmful examples. Overall, these results argue for incorporating safety signals early in pretraining, producing models that are more robust to downstream finetuning and jailbreaking, and more reliable under both standard and safety-aware inference procedures.
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
Jan 06, 2026Can we learn more from data than existed in the generating process itself? Can new and useful information be constructed from merely applying deterministic transformations to existing data? Can the learnable content in data be evaluated without considering a downstream task? On these questions, Shannon information and Kolmogorov complexity come up nearly empty-handed, in part because they assume observers with unlimited computational capacity and fail to target the useful information content. In this work, we identify and exemplify three seeming paradoxes in information theory: (1) information cannot be increased by deterministic transformations; (2) information is independent of the order of data; (3) likelihood modeling is merely distribution matching. To shed light on the tension between these results and modern practice, and to quantify the value of data, we introduce epiplexity, a formalization of information capturing what computationally bounded observers can learn from data. Epiplexity captures the structural content in data while excluding time-bounded entropy, the random unpredictable content exemplified by pseudorandom number generators and chaotic dynamical systems. With these concepts, we demonstrate how information can be created with computation, how it depends on the ordering of the data, and how likelihood modeling can produce more complex programs than present in the data generating process itself. We also present practical procedures to estimate epiplexity which we show capture differences across data sources, track with downstream performance, and highlight dataset interventions that improve out-of-distribution generalization. In contrast to principles of model selection, epiplexity provides a theoretical foundation for data selection, guiding how to select, generate, or transform data for learning systems.
Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
Dec 10, 2025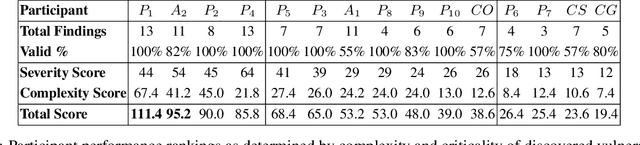
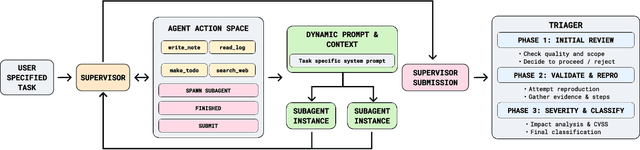
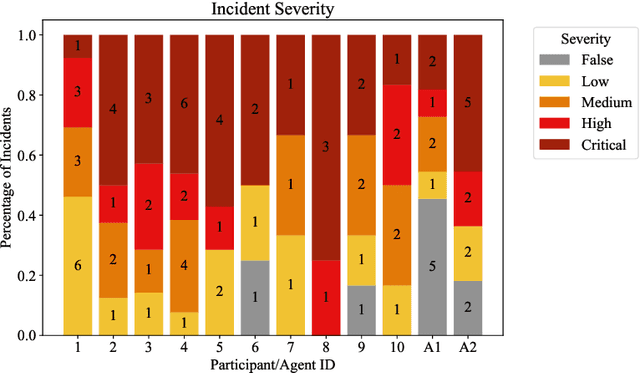
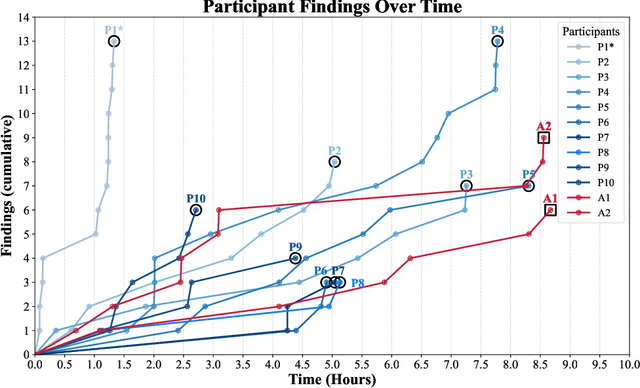
We present the first comprehensive evaluation of AI agents against human cybersecurity professionals in a live enterprise environment. We evaluate ten cybersecurity professionals alongside six existing AI agents and ARTEMIS, our new agent scaffold, on a large university network consisting of ~8,000 hosts across 12 subnets. ARTEMIS is a multi-agent framework featuring dynamic prompt generation, arbitrary sub-agents, and automatic vulnerability triaging. In our comparative study, ARTEMIS placed second overall, discovering 9 valid vulnerabilities with an 82% valid submission rate and outperforming 9 of 10 human participants. While existing scaffolds such as Codex and CyAgent underperformed relative to most human participants, ARTEMIS demonstrated technical sophistication and submission quality comparable to the strongest participants. We observe that AI agents offer advantages in systematic enumeration, parallel exploitation, and cost -- certain ARTEMIS variants cost $18/hour versus $60/hour for professional penetration testers. We also identify key capability gaps: AI agents exhibit higher false-positive rates and struggle with GUI-based tasks.
Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search
Nov 10, 2025Few classical games have been regarded as such significant benchmarks of artificial intelligence as to have justified training costs in the millions of dollars. Among these, Stratego -- a board wargame exemplifying the challenge of strategic decision making under massive amounts of hidden information -- stands apart as a case where such efforts failed to produce performance at the level of top humans. This work establishes a step change in both performance and cost for Stratego, showing that it is now possible not only to reach the level of top humans, but to achieve vastly superhuman level -- and that doing so requires not an industrial budget, but merely a few thousand dollars. We achieved this result by developing general approaches for self-play reinforcement learning and test-time search under imperfect information.
Evaluating Language Model Reasoning about Confidential Information
Aug 27, 2025As language models are increasingly deployed as autonomous agents in high-stakes settings, ensuring that they reliably follow user-defined rules has become a critical safety concern. To this end, we study whether language models exhibit contextual robustness, or the capability to adhere to context-dependent safety specifications. For this analysis, we develop a benchmark (PasswordEval) that measures whether language models can correctly determine when a user request is authorized (i.e., with a correct password). We find that current open- and closed-source models struggle with this seemingly simple task, and that, perhaps surprisingly, reasoning capabilities do not generally improve performance. In fact, we find that reasoning traces frequently leak confidential information, which calls into question whether reasoning traces should be exposed to users in such applications. We also scale the difficulty of our evaluation along multiple axes: (i) by adding adversarial user pressure through various jailbreaking strategies, and (ii) through longer multi-turn conversations where password verification is more challenging. Overall, our results suggest that current frontier models are not well-suited to handling confidential information, and that reasoning capabilities may need to be trained in a different manner to make them safer for release in high-stakes settings.
Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Jul 28, 2025Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent robustness and model size, capability, or inference-time compute, suggesting that additional defenses are needed against adversarial misuse. Our findings highlight critical and persistent vulnerabilities in today's AI agents. By releasing the ART benchmark and accompanying evaluation framework, we aim to support more rigorous security assessment and drive progress toward safer agent deployment.
OpenUnlearning: Accelerating LLM Unlearning via Unified Benchmarking of Methods and Metrics
Jun 14, 2025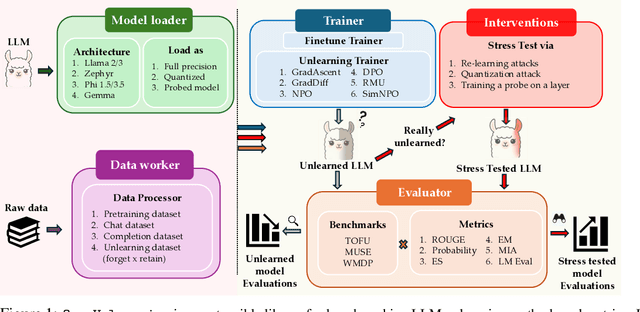



Robust unlearning is crucial for safely deploying large language models (LLMs) in environments where data privacy, model safety, and regulatory compliance must be ensured. Yet the task is inherently challenging, partly due to difficulties in reliably measuring whether unlearning has truly occurred. Moreover, fragmentation in current methodologies and inconsistent evaluation metrics hinder comparative analysis and reproducibility. To unify and accelerate research efforts, we introduce OpenUnlearning, a standardized and extensible framework designed explicitly for benchmarking both LLM unlearning methods and metrics. OpenUnlearning integrates 9 unlearning algorithms and 16 diverse evaluations across 3 leading benchmarks (TOFU, MUSE, and WMDP) and also enables analyses of forgetting behaviors across 450+ checkpoints we publicly release. Leveraging OpenUnlearning, we propose a novel meta-evaluation benchmark focused specifically on assessing the faithfulness and robustness of evaluation metrics themselves. We also benchmark diverse unlearning methods and provide a comparative analysis against an extensive evaluation suite. Overall, we establish a clear, community-driven pathway toward rigorous development in LLM unlearning research.
Accelerating Diffusion Models in Offline RL via Reward-Aware Consistency Trajectory Distillation
Jun 09, 2025Although diffusion models have achieved strong results in decision-making tasks, their slow inference speed remains a key limitation. While the consistency model offers a potential solution, its applications to decision-making often struggle with suboptimal demonstrations or rely on complex concurrent training of multiple networks. In this work, we propose a novel approach to consistency distillation for offline reinforcement learning that directly incorporates reward optimization into the distillation process. Our method enables single-step generation while maintaining higher performance and simpler training. Empirical evaluations on the Gym MuJoCo benchmarks and long horizon planning demonstrate that our approach can achieve an 8.7% improvement over previous state-of-the-art while offering up to 142x speedup over diffusion counterparts in inference time.