 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Adversarial Defence with Boundary-guided Generation
Jul 16, 2019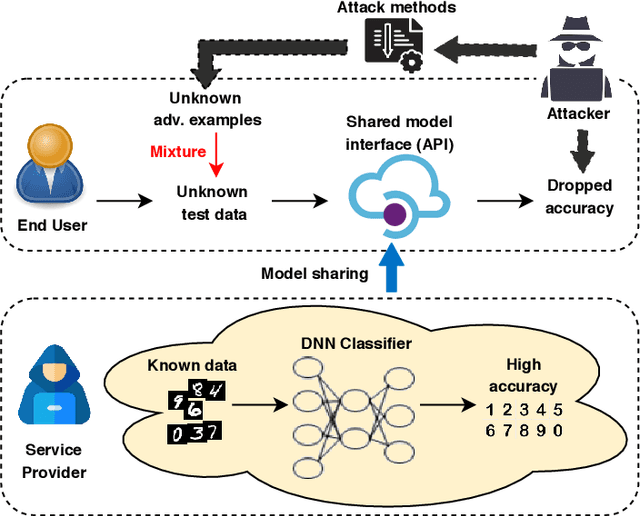
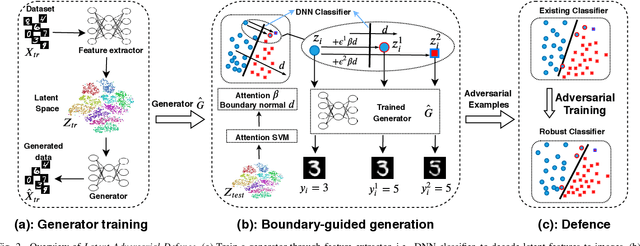

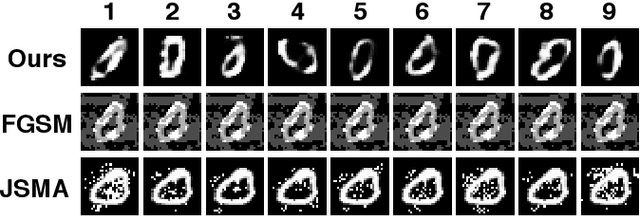
Deep Neural Networks (DNNs) have recently achieved great success in many tasks, which encourages DNNs to be widely used as a machine learning service in model sharing scenarios. However, attackers can easily generate adversarial examples with a small perturbation to fool the DNN models to predict wrong labels. To improve the robustness of shared DNN models against adversarial attacks, we propose a novel method called Latent Adversarial Defence (LAD). The proposed LAD method improves the robustness of a DNN model through adversarial training on generated adversarial examples. Different from popular attack methods which are carried in the input space and only generate adversarial examples of repeating patterns, LAD generates myriad of adversarial examples through adding perturbations to latent features along the normal of the decision boundary which is constructed by an SVM with an attention mechanism. Once adversarial examples are generated, we adversarially train the model through augmenting the training data with generated adversarial examples. Extensive experiments on the MNIST, SVHN, and CelebA dataset demonstrate the effectiveness of our model in defending against different types of adversarial attacks.
Fast and Robust Rank Aggregation against Model Misspecification
May 29, 2019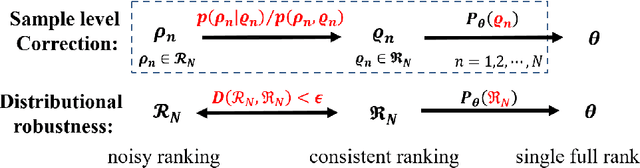
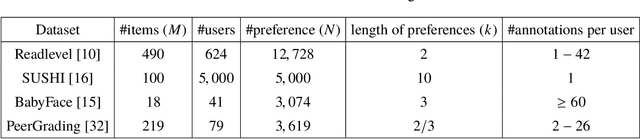

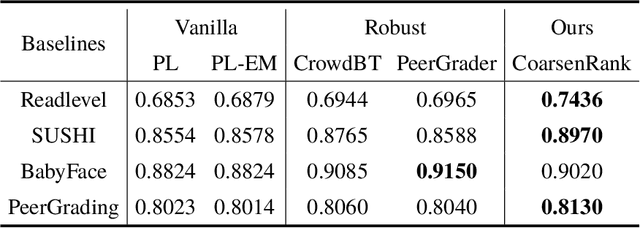
In rank aggregation, preferences from different users are summarized into a total order under the homogeneous data assumption. Thus, model misspecification arises and rank aggregation methods take some noise models into account. However, they all rely on certain noise model assumptions and cannot handle agnostic noises in the real world. In this paper, we propose CoarsenRank, which rectifies the underlying data distribution directly and aligns it to the homogeneous data assumption without involving any noise model. To this end, we define a neighborhood of the data distribution over which Bayesian inference of CoarsenRank is performed, and therefore the resultant posterior enjoys robustness against model misspecification. Further, we derive a tractable closed-form solution for CoarsenRank making it computationally efficient. Experiments on real-world datasets show that CoarsenRank is fast and robust, achieving consistent improvement over baseline methods.
Curriculum Loss: Robust Learning and Generalization against Label Corruption
May 28, 2019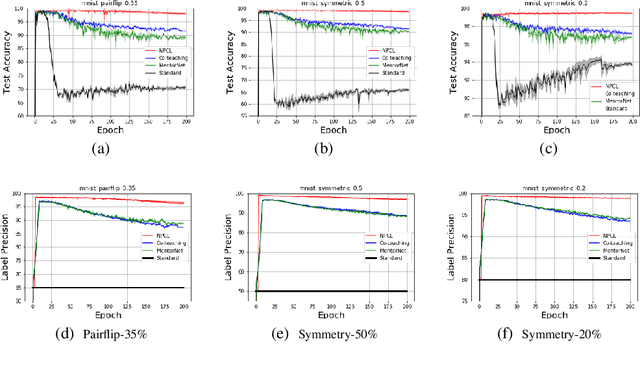

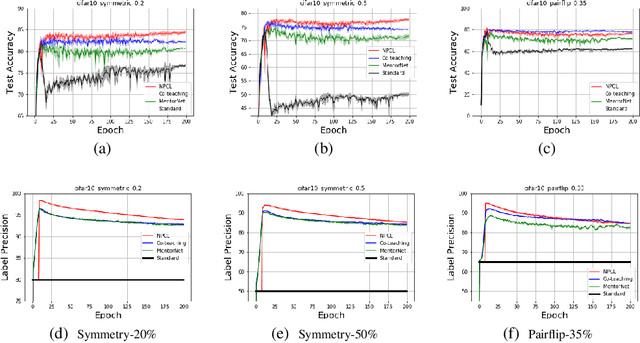
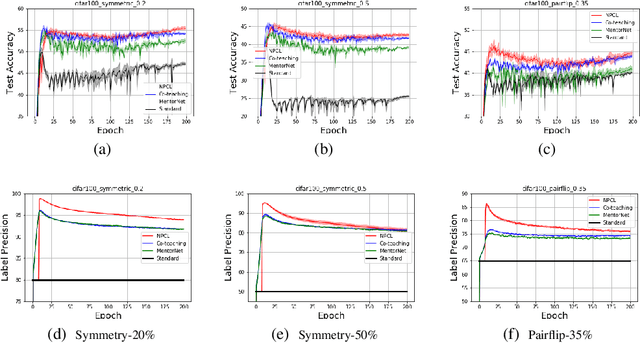
Generalization is vital important for many deep network models. It becomes more challenging when high robustness is required for learning with noisy labels. The 0-1 loss has monotonic relationship between empirical adversary (reweighted) risk, and it is robust to outliers. However, it is also difficult to optimize. To efficiently optimize 0-1 loss while keeping its robust properties, we propose a very simple and efficient loss, i.e. curriculum loss (CL). Our CL is a tighter upper bound of the 0-1 loss compared with conventional summation based surrogate losses. Moreover, CL can adaptively select samples for training as a curriculum learning. To handle large rate of noisy label corruption, we extend our curriculum loss to a more general form that can automatically prune the estimated noisy samples during training. Experimental results on noisy MNIST, CIFAR10 and CIFAR100 dataset validate the robustness of the proposed loss.
Learning Image-Specific Attributes by Hyperbolic Neighborhood Graph Propagation
May 25, 2019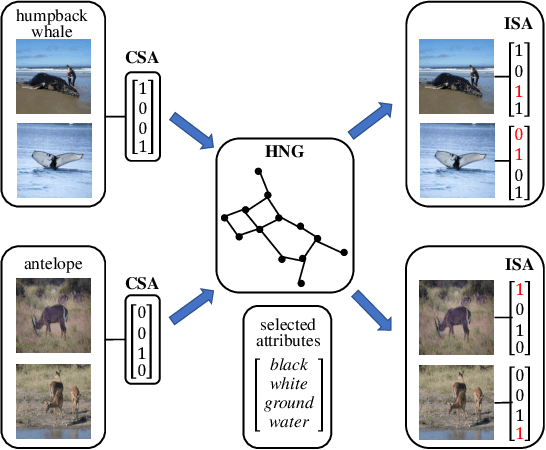
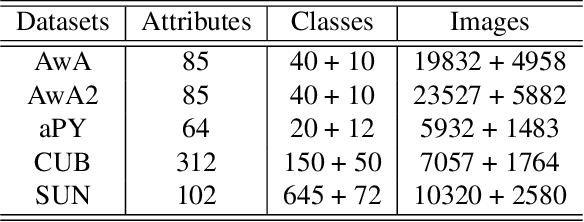
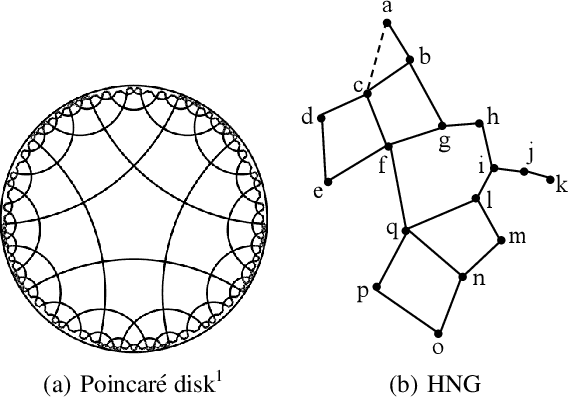
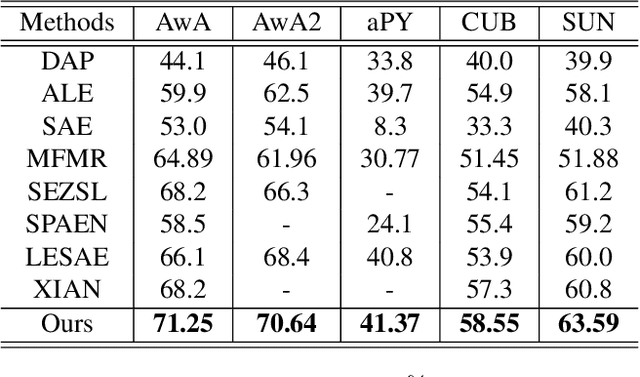
As a kind of semantic representation of visual object descriptions, attributes are widely used in various computer vision tasks. In most of existing attribute-based research, class-specific attributes (CSA), which are class-level annotations, are usually adopted due to its low annotation cost for each class instead of each individual image. However, class-specific attributes are usually noisy because of annotation errors and diversity of individual images. Therefore, it is desirable to obtain image-specific attributes (ISA), which are image-level annotations, from the original class-specific attributes. In this paper, we propose to learn image-specific attributes by graph-based attribute propagation. Considering the intrinsic property of hyperbolic geometry that its distance expands exponentially, hyperbolic neighborhood graph (HNG) is constructed to characterize the relationship between samples. Based on HNG, we define neighborhood consistency for each sample to identify inconsistent samples. Subsequently, inconsistent samples are refined based on their neighbors in HNG. Extensive experiments on five benchmark datasets demonstrate the significant superiority of the learned image-specific attributes over the original class-specific attributes in the zero-shot object classification task.
Efficient Batch Black-box Optimization with Deterministic Regret Bounds
May 24, 2019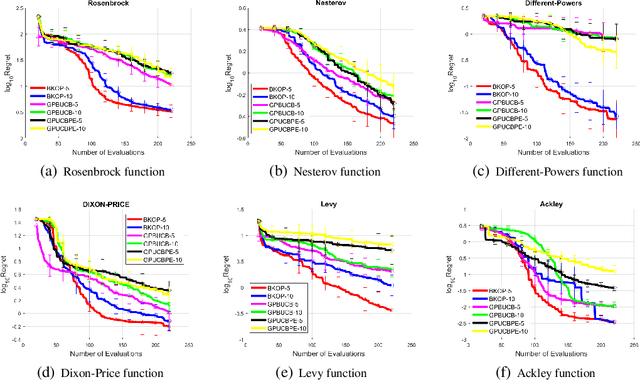
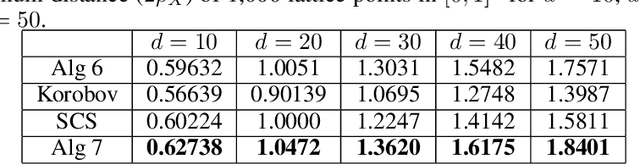
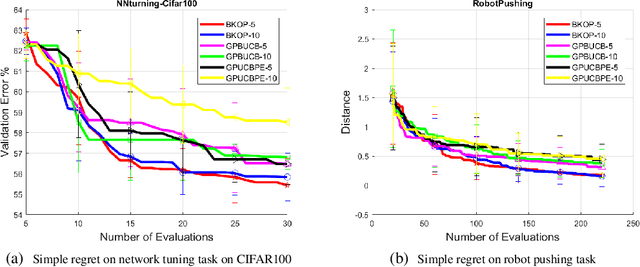
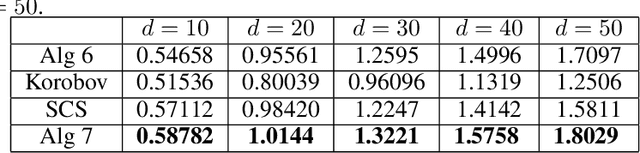
In this work, we investigate black-box optimization from the perspective of frequentist kernel methods. We propose a novel batch optimization algorithm to jointly maximize the acquisition function and select points from a whole batch in a holistic way. Theoretically, we derive regret bounds for both the noise-free and perturbation settings. Moreover, we analyze the property of the adversarial regret that is required by robust initialization for Bayesian Optimization (BO), and prove that the adversarial regret bounds decrease with the decrease of covering radius, which provides a criterion for generating (initialization point set) to minimize the bound. We then propose fast searching algorithms to generate a point set with a small covering radius for the robust initialization. Experimental results on both synthetic benchmark problems and real-world problems show the effectiveness of the proposed algorithms.
Marginalized Average Attentional Network for Weakly-Supervised Learning
May 21, 2019
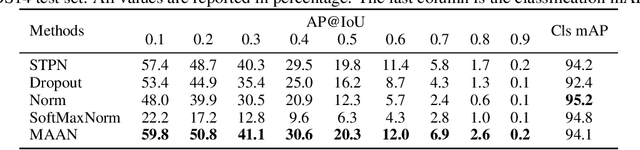
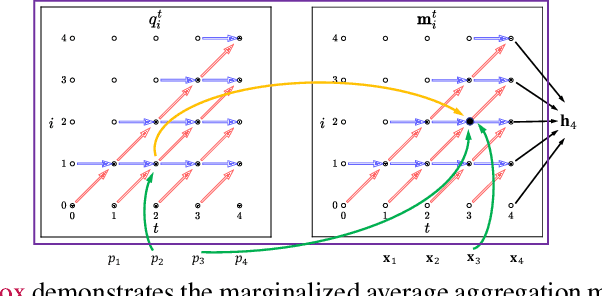
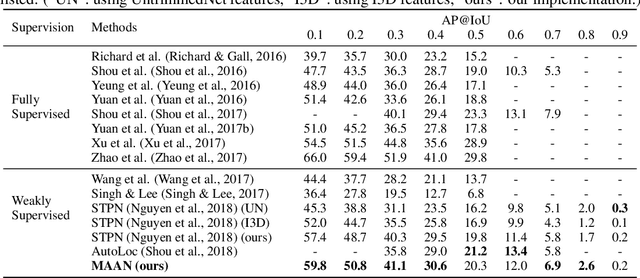
In weakly-supervised temporal action localization, previous works have failed to locate dense and integral regions for each entire action due to the overestimation of the most salient regions. To alleviate this issue, we propose a marginalized average attentional network (MAAN) to suppress the dominant response of the most salient regions in a principled manner. The MAAN employs a novel marginalized average aggregation (MAA) module and learns a set of latent discriminative probabilities in an end-to-end fashion. MAA samples multiple subsets from the video snippet features according to a set of latent discriminative probabilities and takes the expectation over all the averaged subset features. Theoretically, we prove that the MAA module with learned latent discriminative probabilities successfully reduces the difference in responses between the most salient regions and the others. Therefore, MAAN is able to generate better class activation sequences and identify dense and integral action regions in the videos. Moreover, we propose a fast algorithm to reduce the complexity of constructing MAA from O($2^T$) to O($T^2$). Extensive experiments on two large-scale video datasets show that our MAAN achieves superior performance on weakly-supervised temporal action localization
Safeguarded Dynamic Label Regression for Generalized Noisy Supervision
Mar 06, 2019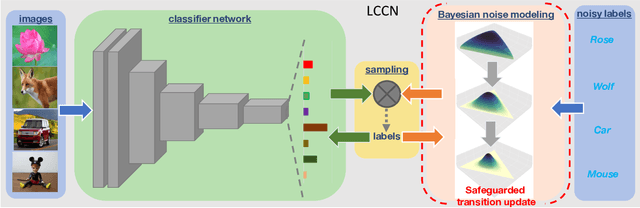

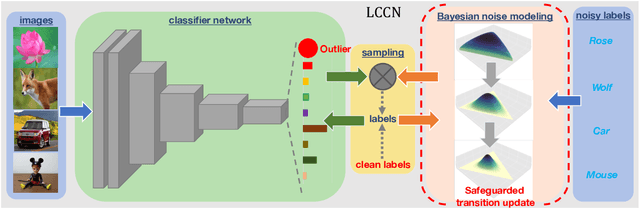

Learning with noisy labels, which aims to reduce expensive labors on accurate annotations, has become imperative in the Big Data era. Previous noise transition based method has achieved promising results and presented a theoretical guarantee on performance in the case of class-conditional noise. However, this type of approaches critically depend on an accurate pre-estimation of the noise transition, which is usually impractical. Subsequent improvement adapts the pre-estimation along with the training progress via a Softmax layer. However, the parameters in the Softmax layer are highly tweaked for the fragile performance due to the ill-posed stochastic approximation. To address these issues, we propose a Latent Class-Conditional Noise model (LCCN) that naturally embeds the noise transition under a Bayesian framework. By projecting the noise transition into a Dirichlet-distributed space, the learning is constrained on a simplex based on the whole dataset, instead of some ad-hoc parametric space. We then deduce a dynamic label regression method for LCCN to iteratively infer the latent labels, to stochastically train the classifier and to model the noise. Our approach safeguards the bounded update of the noise transition, which avoids previous arbitrarily tuning via a batch of samples. We further generalize LCCN for open-set noisy labels and the semi-supervised setting. We perform extensive experiments with the controllable noise data sets, CIFAR-10 and CIFAR-100, and the agnostic noise data sets, Clothing1M and WebVision17. The experimental results have demonstrated that the proposed model outperforms several state-of-the-art methods.
How does Disagreement Help Generalization against Label Corruption?
Jan 26, 2019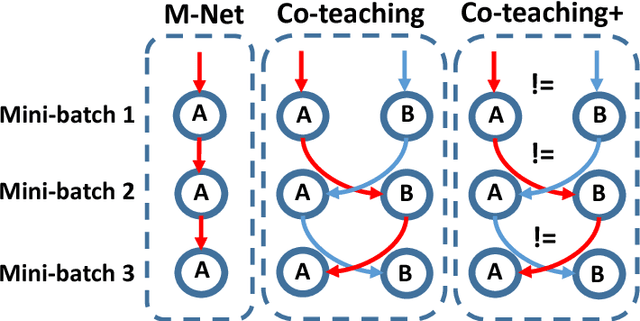
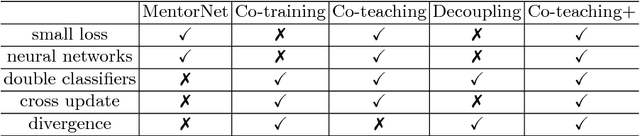
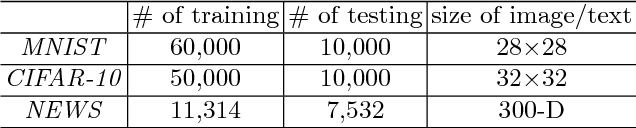
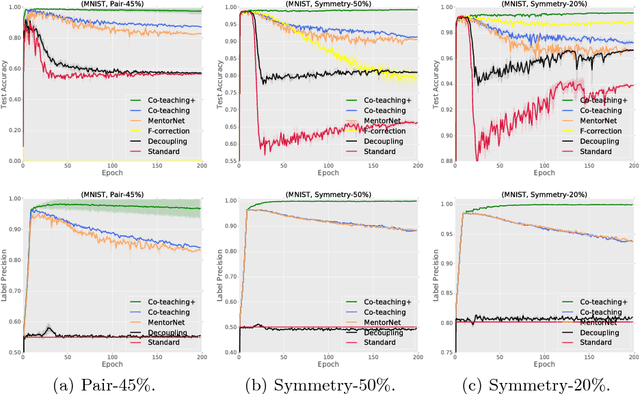
Learning with noisy labels is one of the hottest problems in weakly-supervised learning. Based on memorization effects of deep neural networks, training on small-loss instances becomes very promising for handling noisy labels. This fosters the state-of-the-art approach "Co-teaching" that cross-trains two deep neural networks using the small-loss trick. However, with the increase of epochs, two networks converge to a consensus and Co-teaching reduces to the self-training MentorNet. To tackle this issue, we propose a robust learning paradigm called Co-teaching+, which bridges the "Update by Disagreement" strategy with the original Co-teaching. First, two networks feed forward and predict all data, but keep prediction disagreement data only. Then, among such disagreement data, each network selects its small-loss data, but back propagates the small-loss data from its peer network and updates its own parameters. Empirical results on benchmark datasets demonstrate that Co-teaching+ is much superior to many state-of-the-art methods in the robustness of trained models.
A Survey on Multi-output Learning
Jan 02, 2019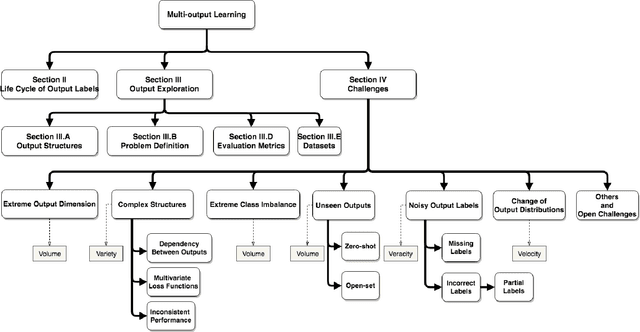
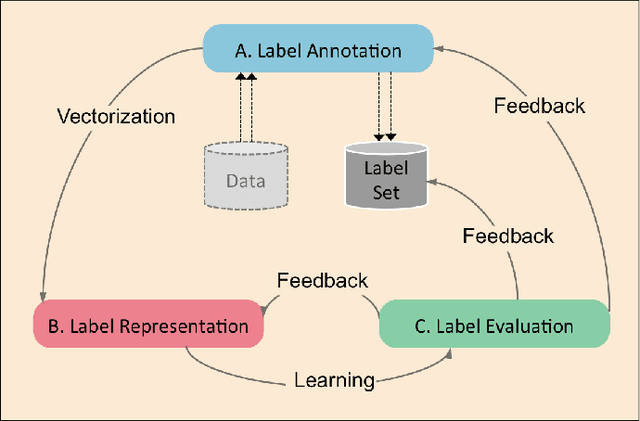
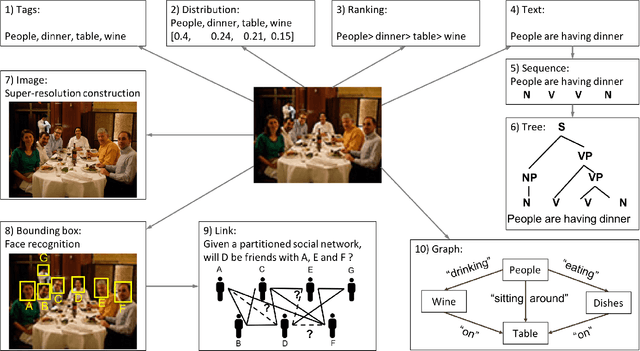
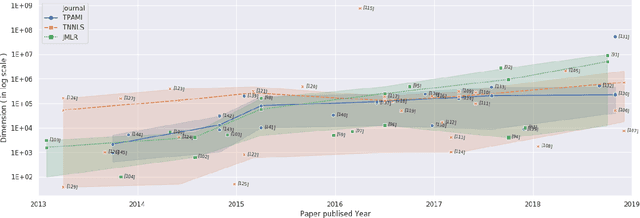
Multi-output learning aims to simultaneously predict multiple outputs given an input. It is an important learning problem due to the pressing need for sophisticated decision making in real-world applications. Inspired by big data, the 4Vs characteristics of multi-output imposes a set of challenges to multi-output learning, in terms of the volume, velocity, variety and veracity of the outputs. Increasing number of works in the literature have been devoted to the study of multi-output learning and the development of novel approaches for addressing the challenges encountered. However, it lacks a comprehensive overview on different types of challenges of multi-output learning brought by the characteristics of the multiple outputs and the techniques proposed to overcome the challenges. This paper thus attempts to fill in this gap to provide a comprehensive review on this area. We first introduce different stages of the life cycle of the output labels. Then we present the paradigm on multi-output learning, including its myriads of output structures, definitions of its different sub-problems, model evaluation metrics and popular data repositories used in the study. Subsequently, we review a number of state-of-the-art multi-output learning methods, which are categorized based on the challenges.
VR-SGD: A Simple Stochastic Variance Reduction Method for Machine Learning
Oct 28, 2018
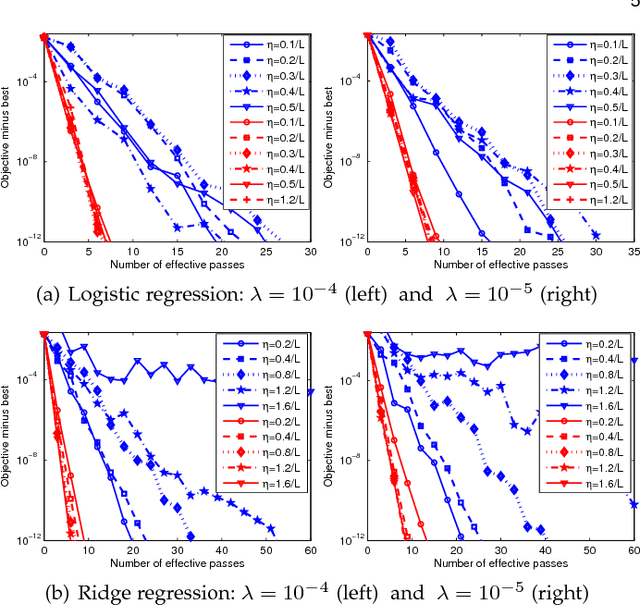
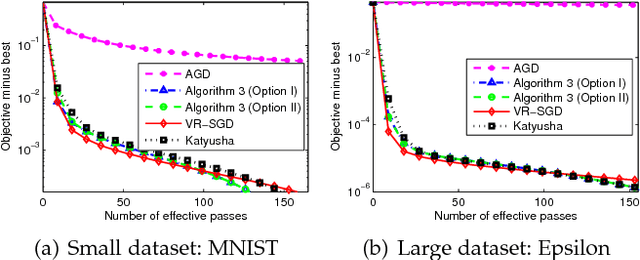
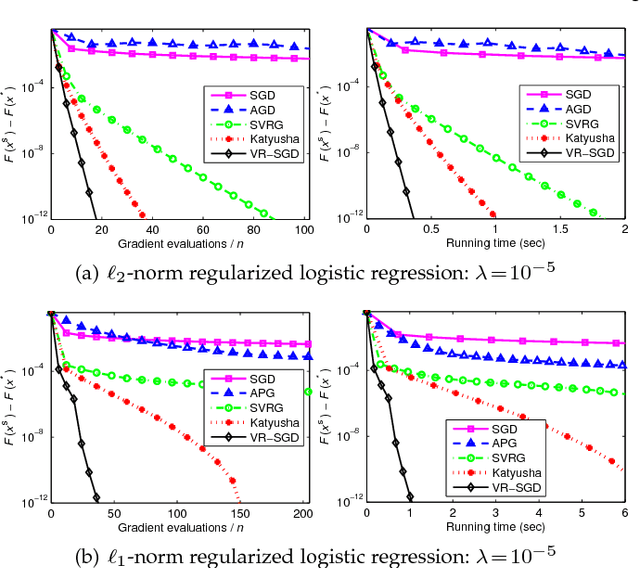
In this paper, we propose a simple variant of the original SVRG, called variance reduced stochastic gradient descent (VR-SGD). Unlike the choices of snapshot and starting points in SVRG and its proximal variant, Prox-SVRG, the two vectors of VR-SGD are set to the average and last iterate of the previous epoch, respectively. The settings allow us to use much larger learning rates, and also make our convergence analysis more challenging. We also design two different update rules for smooth and non-smooth objective functions, respectively, which means that VR-SGD can tackle non-smooth and/or non-strongly convex problems directly without any reduction techniques. Moreover, we analyze the convergence properties of VR-SGD for strongly convex problems, which show that VR-SGD attains linear convergence. Different from its counterparts that have no convergence guarantees for non-strongly convex problems, we also provide the convergence guarantees of VR-SGD for this case, and empirically verify that VR-SGD with varying learning rates achieves similar performance to its momentum accelerated variant that has the optimal convergence rate $\mathcal{O}(1/T^2)$. Finally, we apply VR-SGD to solve various machine learning problems, such as convex and non-convex empirical risk minimization, and leading eigenvalue computation. Experimental results show that VR-SGD converges significantly faster than SVRG and Prox-SVRG, and usually outperforms state-of-the-art accelerated methods, e.g., Katyusha.