 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGamePad: A Learning Environment for Theorem Proving
Jun 02, 2018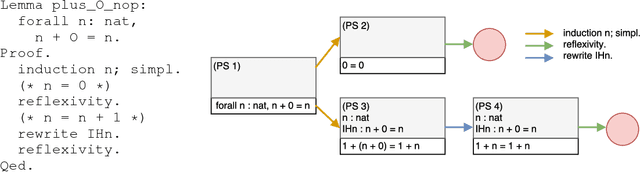
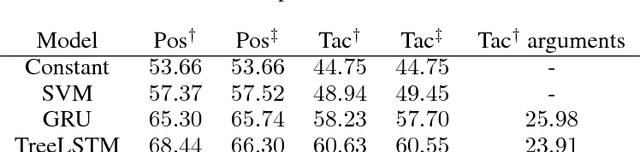
In this paper, we introduce a system called GamePad that can be used to explore the application of machine learning methods to theorem proving in the Coq proof assistant. Interactive theorem provers such as Coq enable users to construct machine-checkable proofs in a step-by-step manner. Hence, they provide an opportunity to explore theorem proving at a human level of abstraction. We use GamePad to synthesize proofs for a simple algebraic rewrite problem and train baseline models for a formalization of the Feit-Thompson theorem. We address position evaluation (i.e., predict the number of proof steps left) and tactic prediction (i.e., predict the next proof step) tasks, which arise naturally in human-level theorem proving.
Emergent Complexity via Multi-Agent Competition
Mar 14, 2018
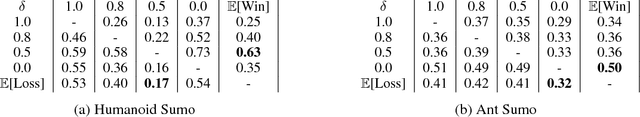
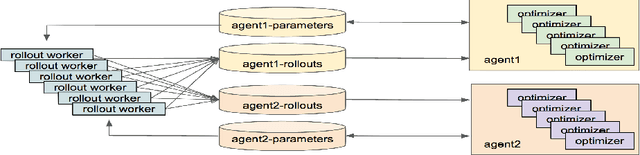
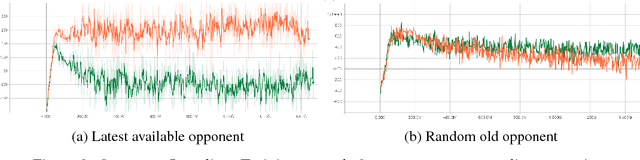
Reinforcement learning algorithms can train agents that solve problems in complex, interesting environments. Normally, the complexity of the trained agent is closely related to the complexity of the environment. This suggests that a highly capable agent requires a complex environment for training. In this paper, we point out that a competitive multi-agent environment trained with self-play can produce behaviors that are far more complex than the environment itself. We also point out that such environments come with a natural curriculum, because for any skill level, an environment full of agents of this level will have the right level of difficulty. This work introduces several competitive multi-agent environments where agents compete in a 3D world with simulated physics. The trained agents learn a wide variety of complex and interesting skills, even though the environment themselves are relatively simple. The skills include behaviors such as running, blocking, ducking, tackling, fooling opponents, kicking, and defending using both arms and legs. A highlight of the learned behaviors can be found here: https://goo.gl/eR7fbX
Some Considerations on Learning to Explore via Meta-Reinforcement Learning
Mar 03, 2018
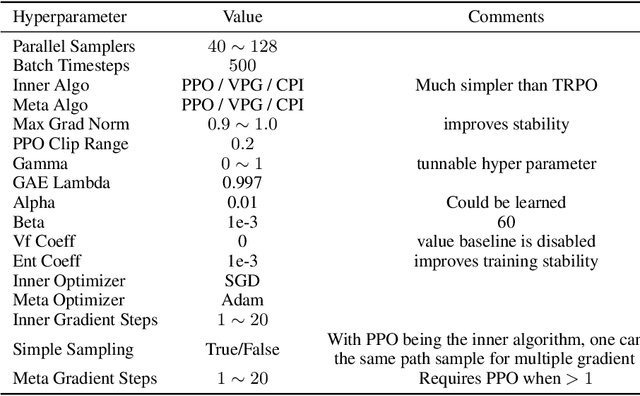
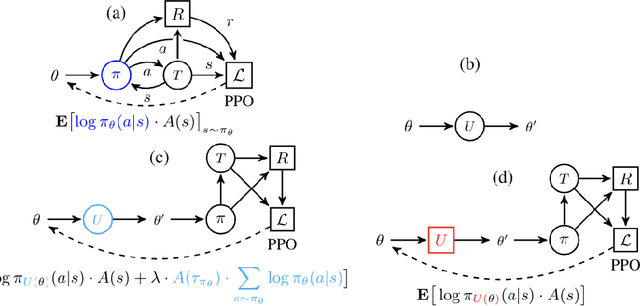

We consider the problem of exploration in meta reinforcement learning. Two new meta reinforcement learning algorithms are suggested: E-MAML and E-$\text{RL}^2$. Results are presented on a novel environment we call `Krazy World' and a set of maze environments. We show E-MAML and E-$\text{RL}^2$ deliver better performance on tasks where exploration is important.
Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments
Feb 23, 2018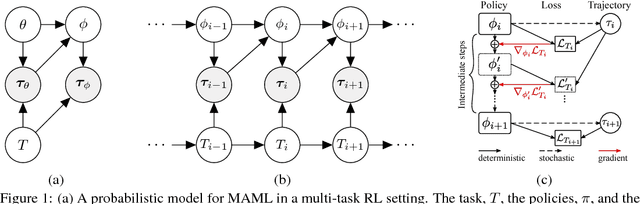


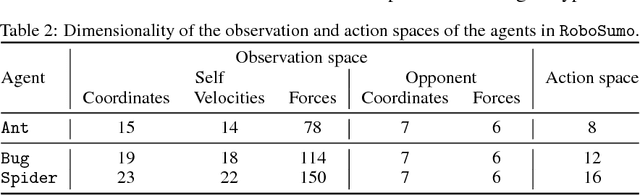
Ability to continuously learn and adapt from limited experience in nonstationary environments is an important milestone on the path towards general intelligence. In this paper, we cast the problem of continuous adaptation into the learning-to-learn framework. We develop a simple gradient-based meta-learning algorithm suitable for adaptation in dynamically changing and adversarial scenarios. Additionally, we design a new multi-agent competitive environment, RoboSumo, and define iterated adaptation games for testing various aspects of continuous adaptation strategies. We demonstrate that meta-learning enables significantly more efficient adaptation than reactive baselines in the few-shot regime. Our experiments with a population of agents that learn and compete suggest that meta-learners are the fittest.
One-Shot Imitation Learning
Dec 04, 2017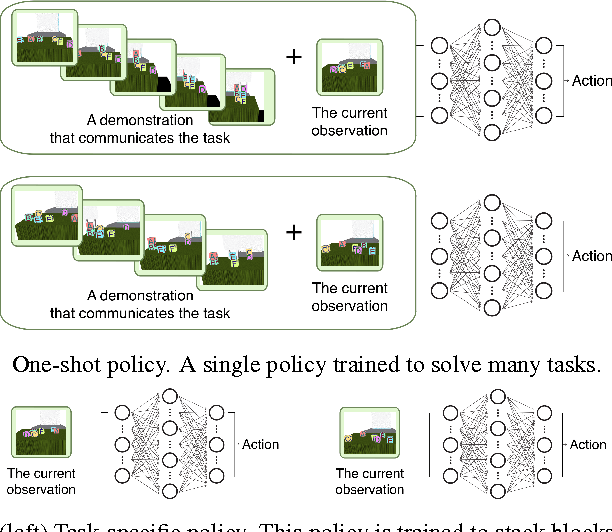
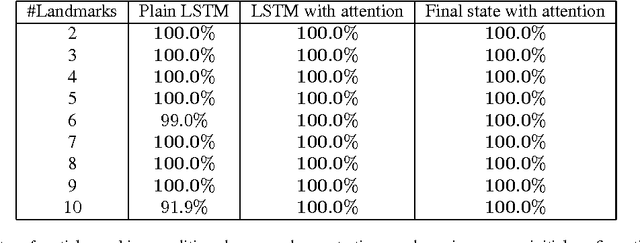
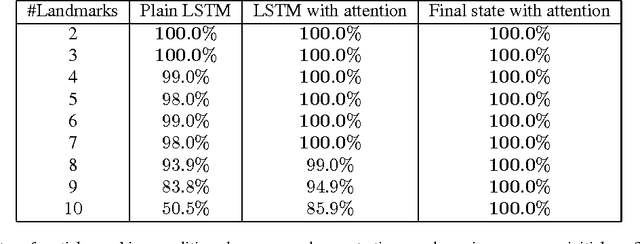
Imitation learning has been commonly applied to solve different tasks in isolation. This usually requires either careful feature engineering, or a significant number of samples. This is far from what we desire: ideally, robots should be able to learn from very few demonstrations of any given task, and instantly generalize to new situations of the same task, without requiring task-specific engineering. In this paper, we propose a meta-learning framework for achieving such capability, which we call one-shot imitation learning. Specifically, we consider the setting where there is a very large set of tasks, and each task has many instantiations. For example, a task could be to stack all blocks on a table into a single tower, another task could be to place all blocks on a table into two-block towers, etc. In each case, different instances of the task would consist of different sets of blocks with different initial states. At training time, our algorithm is presented with pairs of demonstrations for a subset of all tasks. A neural net is trained that takes as input one demonstration and the current state (which initially is the initial state of the other demonstration of the pair), and outputs an action with the goal that the resulting sequence of states and actions matches as closely as possible with the second demonstration. At test time, a demonstration of a single instance of a new task is presented, and the neural net is expected to perform well on new instances of this new task. The use of soft attention allows the model to generalize to conditions and tasks unseen in the training data. We anticipate that by training this model on a much greater variety of tasks and settings, we will obtain a general system that can turn any demonstrations into robust policies that can accomplish an overwhelming variety of tasks. Videos available at https://bit.ly/nips2017-oneshot .
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Sep 07, 2017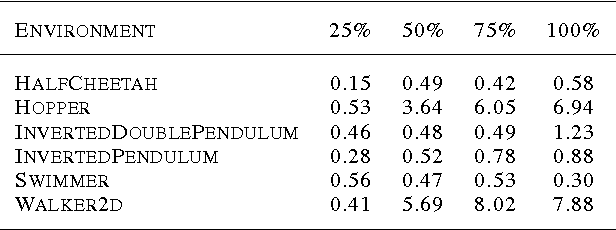
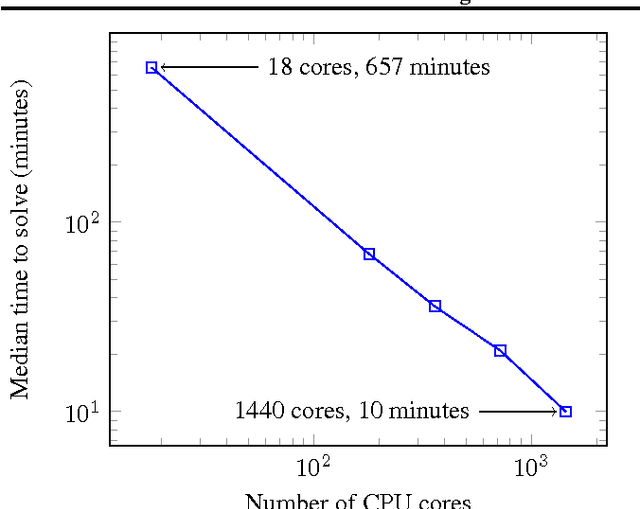
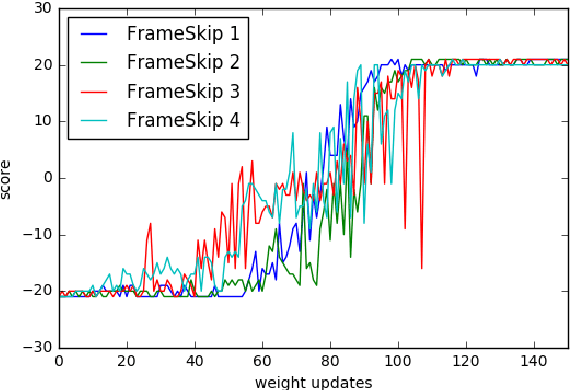
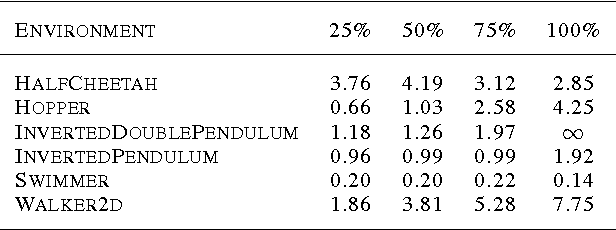
We explore the use of Evolution Strategies (ES), a class of black box optimization algorithms, as an alternative to popular MDP-based RL techniques such as Q-learning and Policy Gradients. Experiments on MuJoCo and Atari show that ES is a viable solution strategy that scales extremely well with the number of CPUs available: By using a novel communication strategy based on common random numbers, our ES implementation only needs to communicate scalars, making it possible to scale to over a thousand parallel workers. This allows us to solve 3D humanoid walking in 10 minutes and obtain competitive results on most Atari games after one hour of training. In addition, we highlight several advantages of ES as a black box optimization technique: it is invariant to action frequency and delayed rewards, tolerant of extremely long horizons, and does not need temporal discounting or value function approximation.
An online sequence-to-sequence model for noisy speech recognition
Jun 16, 2017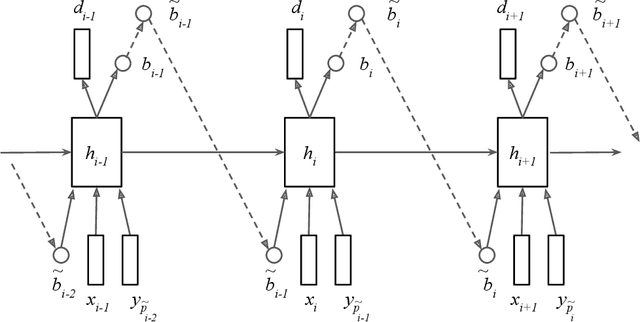
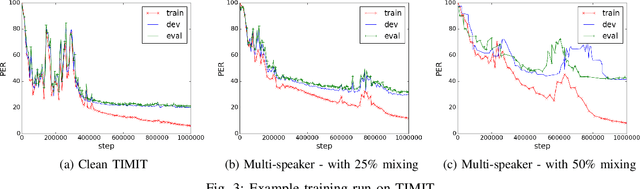
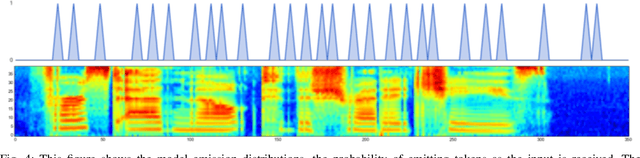
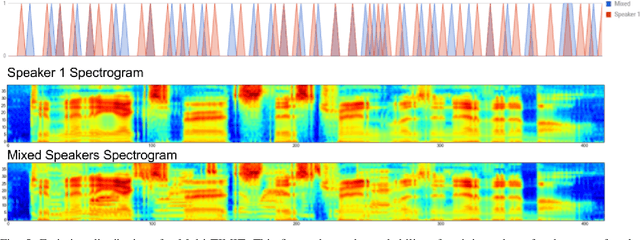
Generative models have long been the dominant approach for speech recognition. The success of these models however relies on the use of sophisticated recipes and complicated machinery that is not easily accessible to non-practitioners. Recent innovations in Deep Learning have given rise to an alternative - discriminative models called Sequence-to-Sequence models, that can almost match the accuracy of state of the art generative models. While these models are easy to train as they can be trained end-to-end in a single step, they have a practical limitation that they can only be used for offline recognition. This is because the models require that the entirety of the input sequence be available at the beginning of inference, an assumption that is not valid for instantaneous speech recognition. To address this problem, online sequence-to-sequence models were recently introduced. These models are able to start producing outputs as data arrives, and the model feels confident enough to output partial transcripts. These models, like sequence-to-sequence are causal - the output produced by the model until any time, $t$, affects the features that are computed subsequently. This makes the model inherently more powerful than generative models that are unable to change features that are computed from the data. This paper highlights two main contributions - an improvement to online sequence-to-sequence model training, and its application to noisy settings with mixed speech from two speakers.
Learning to Generate Reviews and Discovering Sentiment
Apr 06, 2017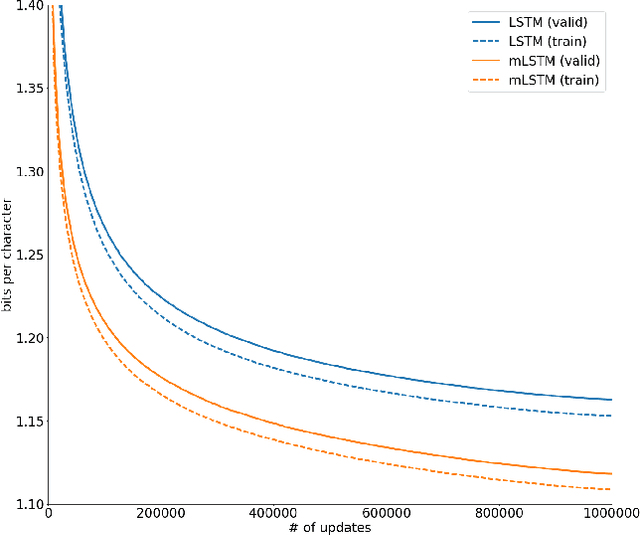
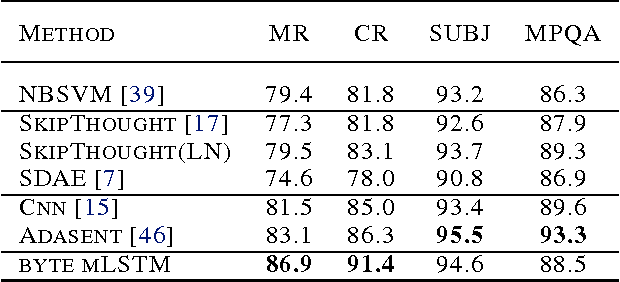
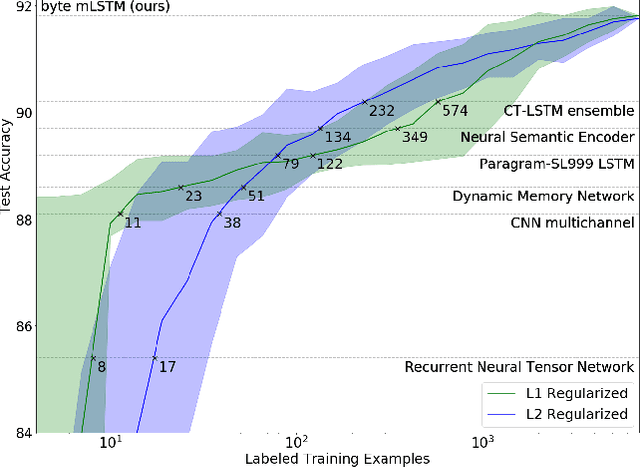

We explore the properties of byte-level recurrent language models. When given sufficient amounts of capacity, training data, and compute time, the representations learned by these models include disentangled features corresponding to high-level concepts. Specifically, we find a single unit which performs sentiment analysis. These representations, learned in an unsupervised manner, achieve state of the art on the binary subset of the Stanford Sentiment Treebank. They are also very data efficient. When using only a handful of labeled examples, our approach matches the performance of strong baselines trained on full datasets. We also demonstrate the sentiment unit has a direct influence on the generative process of the model. Simply fixing its value to be positive or negative generates samples with the corresponding positive or negative sentiment.
Third-Person Imitation Learning
Mar 06, 2017
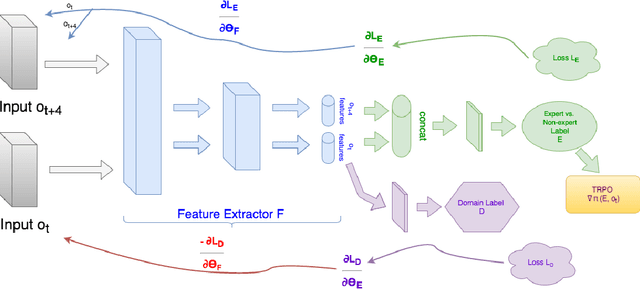


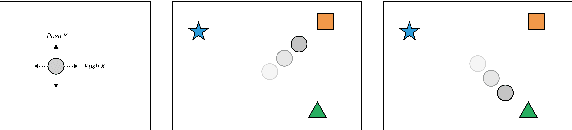
Reinforcement learning (RL) makes it possible to train agents capable of achiev- ing sophisticated goals in complex and uncertain environments. A key difficulty in reinforcement learning is specifying a reward function for the agent to optimize. Traditionally, imitation learning in RL has been used to overcome this problem. Unfortunately, hitherto imitation learning methods tend to require that demonstra- tions are supplied in the first-person: the agent is provided with a sequence of states and a specification of the actions that it should have taken. While powerful, this kind of imitation learning is limited by the relatively hard problem of collect- ing first-person demonstrations. Humans address this problem by learning from third-person demonstrations: they observe other humans perform tasks, infer the task, and accomplish the same task themselves. In this paper, we present a method for unsupervised third-person imitation learn- ing. Here third-person refers to training an agent to correctly achieve a simple goal in a simple environment when it is provided a demonstration of a teacher achieving the same goal but from a different viewpoint; and unsupervised refers to the fact that the agent receives only these third-person demonstrations, and is not provided a correspondence between teacher states and student states. Our methods primary insight is that recent advances from domain confusion can be utilized to yield domain agnostic features which are crucial during the training process. To validate our approach, we report successful experiments on learning from third-person demonstrations in a pointmass domain, a reacher domain, and inverted pendulum.
Variational Lossy Autoencoder
Mar 04, 2017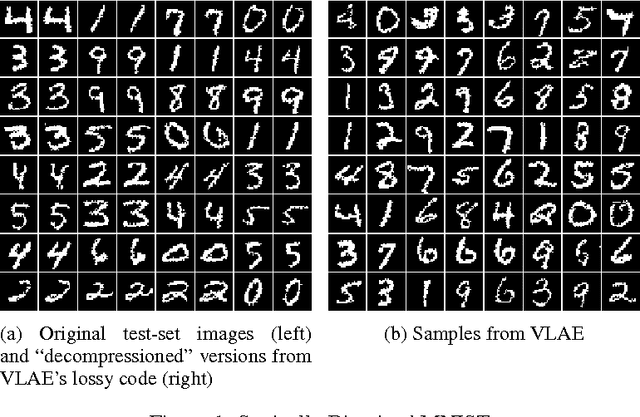
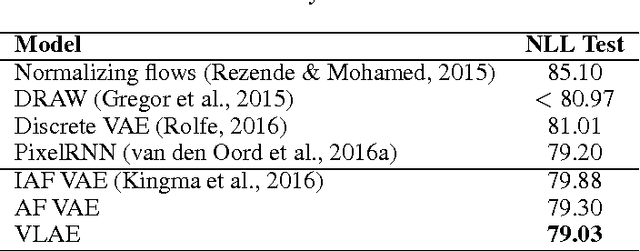


Representation learning seeks to expose certain aspects of observed data in a learned representation that's amenable to downstream tasks like classification. For instance, a good representation for 2D images might be one that describes only global structure and discards information about detailed texture. In this paper, we present a simple but principled method to learn such global representations by combining Variational Autoencoder (VAE) with neural autoregressive models such as RNN, MADE and PixelRNN/CNN. Our proposed VAE model allows us to have control over what the global latent code can learn and , by designing the architecture accordingly, we can force the global latent code to discard irrelevant information such as texture in 2D images, and hence the VAE only "autoencodes" data in a lossy fashion. In addition, by leveraging autoregressive models as both prior distribution $p(z)$ and decoding distribution $p(x|z)$, we can greatly improve generative modeling performance of VAEs, achieving new state-of-the-art results on MNIST, OMNIGLOT and Caltech-101 Silhouettes density estimation tasks.