 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText as Neural Operator: Image Manipulation by Text Instruction
Aug 12, 2020
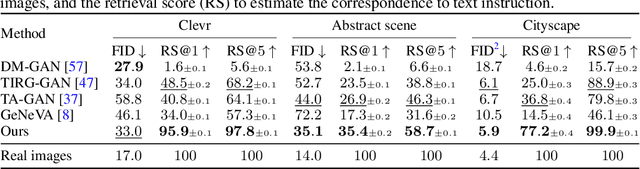
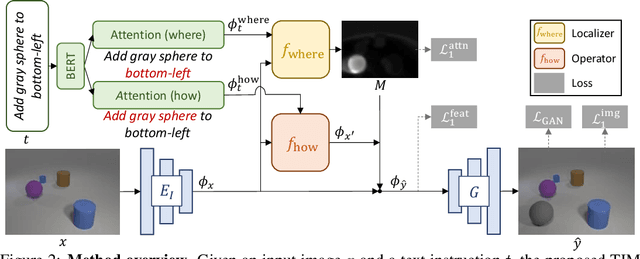
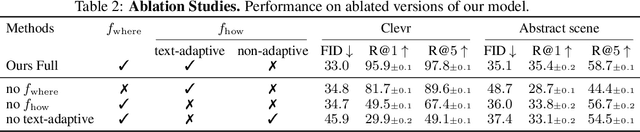
In this paper, we study a new task that allows users to edit an input image using language instructions. In this image generation task, the inputs are a reference image and a text instruction that describes desired modifications to the input image. We propose a GAN-based method to tackle this problem. The key idea is to treat language as neural operators to locally modify the image feature. To this end, our model decomposes the generation process into finding where (spatial region) and how (text operators) to apply modifications. We show that the proposed model performs favorably against recent baselines on three datasets.
RetrieveGAN: Image Synthesis via Differentiable Patch Retrieval
Jul 16, 2020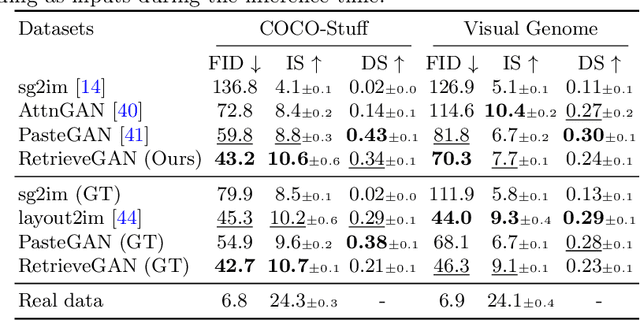
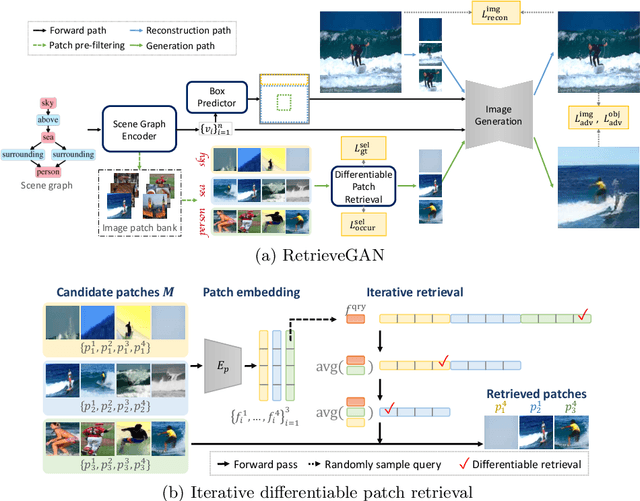

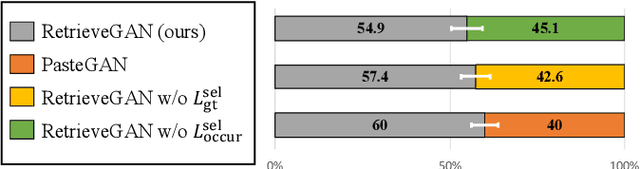
Image generation from scene description is a cornerstone technique for the controlled generation, which is beneficial to applications such as content creation and image editing. In this work, we aim to synthesize images from scene description with retrieved patches as reference. We propose a differentiable retrieval module. With the differentiable retrieval module, we can (1) make the entire pipeline end-to-end trainable, enabling the learning of better feature embedding for retrieval; (2) encourage the selection of mutually compatible patches with additional objective functions. We conduct extensive quantitative and qualitative experiments to demonstrate that the proposed method can generate realistic and diverse images, where the retrieved patches are reasonable and mutually compatible.
Modeling Artistic Workflows for Image Generation and Editing
Jul 14, 2020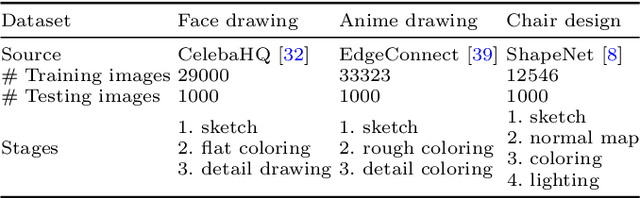
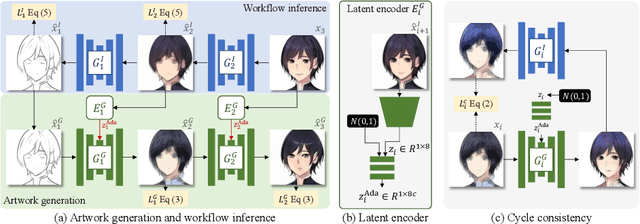

People often create art by following an artistic workflow involving multiple stages that inform the overall design. If an artist wishes to modify an earlier decision, significant work may be required to propagate this new decision forward to the final artwork. Motivated by the above observations, we propose a generative model that follows a given artistic workflow, enabling both multi-stage image generation as well as multi-stage image editing of an existing piece of art. Furthermore, for the editing scenario, we introduce an optimization process along with learning-based regularization to ensure the edited image produced by the model closely aligns with the originally provided image. Qualitative and quantitative results on three different artistic datasets demonstrate the effectiveness of the proposed framework on both image generation and editing tasks.
Regularizing Meta-Learning via Gradient Dropout
Apr 13, 2020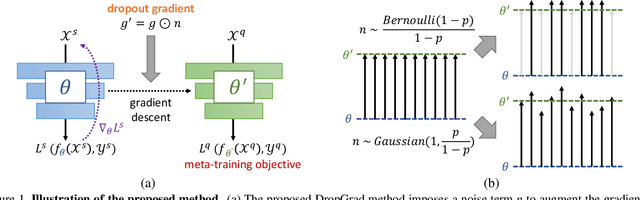
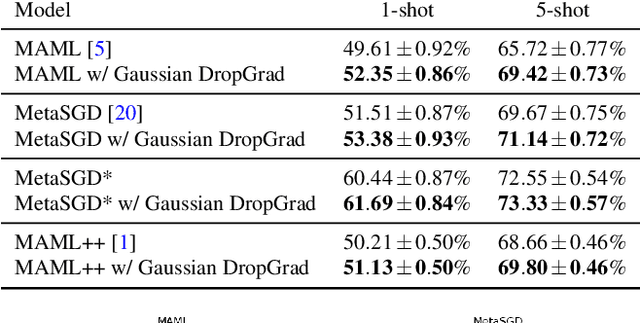
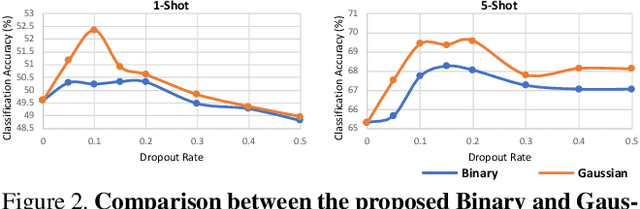
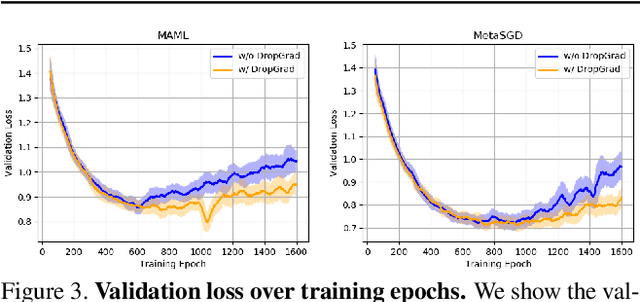
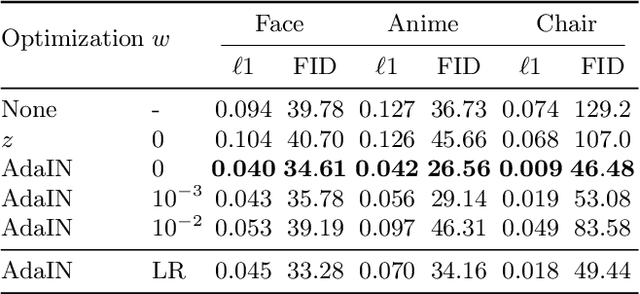
With the growing attention on learning-to-learn new tasks using only a few examples, meta-learning has been widely used in numerous problems such as few-shot classification, reinforcement learning, and domain generalization. However, meta-learning models are prone to overfitting when there are no sufficient training tasks for the meta-learners to generalize. Although existing approaches such as Dropout are widely used to address the overfitting problem, these methods are typically designed for regularizing models of a single task in supervised training. In this paper, we introduce a simple yet effective method to alleviate the risk of overfitting for gradient-based meta-learning. Specifically, during the gradient-based adaptation stage, we randomly drop the gradient in the inner-loop optimization of each parameter in deep neural networks, such that the augmented gradients improve generalization to new tasks. We present a general form of the proposed gradient dropout regularization and show that this term can be sampled from either the Bernoulli or Gaussian distribution. To validate the proposed method, we conduct extensive experiments and analysis on numerous computer vision tasks, demonstrating that the gradient dropout regularization mitigates the overfitting problem and improves the performance upon various gradient-based meta-learning frameworks.
Cross-Domain Few-Shot Classification via Learned Feature-Wise Transformation
Feb 18, 2020



Few-shot classification aims to recognize novel categories with only few labeled images in each class. Existing metric-based few-shot classification algorithms predict categories by comparing the feature embeddings of query images with those from a few labeled images (support examples) using a learned metric function. While promising performance has been demonstrated, these methods often fail to generalize to unseen domains due to large discrepancy of the feature distribution across domains. In this work, we address the problem of few-shot classification under domain shifts for metric-based methods. Our core idea is to use feature-wise transformation layers for augmenting the image features using affine transforms to simulate various feature distributions under different domains in the training stage. To capture variations of the feature distributions under different domains, we further apply a learning-to-learn approach to search for the hyper-parameters of the feature-wise transformation layers. We conduct extensive experiments and ablation studies under the domain generalization setting using five few-shot classification datasets: mini-ImageNet, CUB, Cars, Places, and Plantae. Experimental results demonstrate that the proposed feature-wise transformation layer is applicable to various metric-based models, and provides consistent improvements on the few-shot classification performance under domain shift.
Progressive Domain Adaptation for Object Detection
Oct 24, 2019
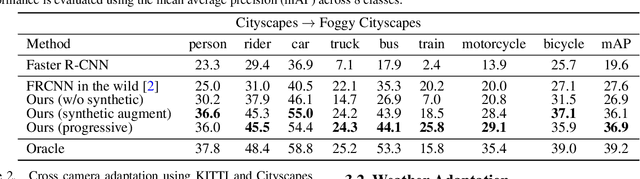
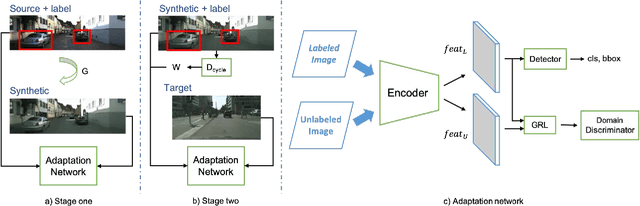
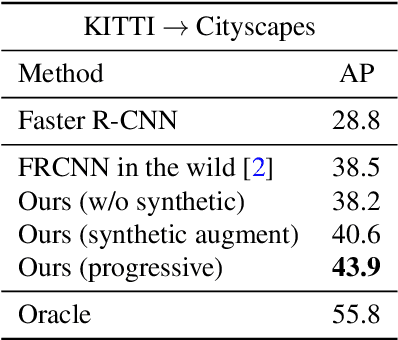
Recent deep learning methods for object detection rely on a large amount of bounding box annotations. Collecting these annotations is laborious and costly, yet supervised models do not generalize well when testing on images from a different distribution. Domain adaptation provides a solution by adapting existing labels to the target testing data. However, a large gap between domains could make adaptation a challenging task, which leads to unstable training processes and sub-optimal results. In this paper, we propose to bridge the domain gap with an intermediate domain and progressively solve easier adaptation subtasks. This intermediate domain is constructed by translating the source images to mimic the ones in the target domain. To tackle the domain-shift problem, we adopt adversarial learning to align distributions at the feature level. In addition, a weighted task loss is applied to deal with unbalanced image quality in the intermediate domain. Experimental results show that our method performs favorably against the state-of-the-art method in terms of the performance on the target domain.
Self-supervised Audio Spatialization with Correspondence Classifier
May 14, 2019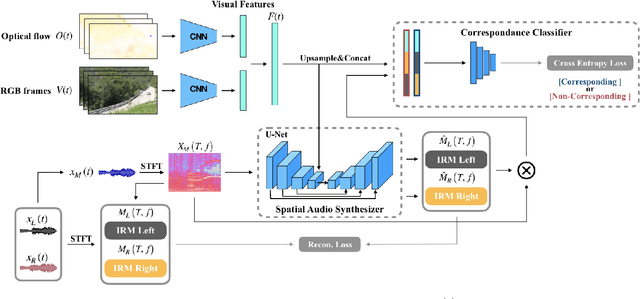


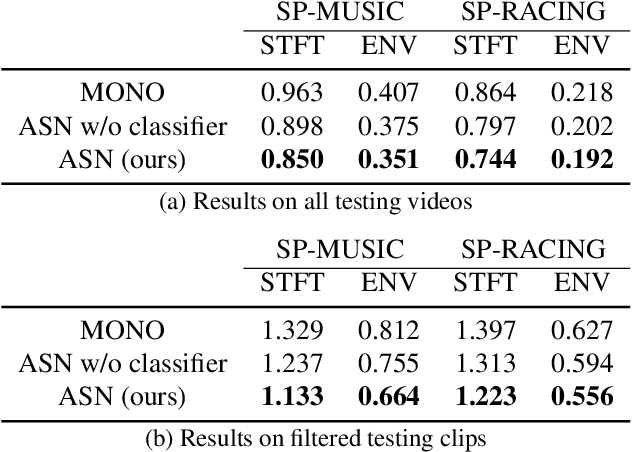
Spatial audio is an essential medium to audiences for 3D visual and auditory experience. However, the recording devices and techniques are expensive or inaccessible to the general public. In this work, we propose a self-supervised audio spatialization network that can generate spatial audio given the corresponding video and monaural audio. To enhance spatialization performance, we use an auxiliary classifier to classify ground-truth videos and those with audio where the left and right channels are swapped. We collect a large-scale video dataset with spatial audio to validate the proposed method. Experimental results demonstrate the effectiveness of the proposed model on the audio spatialization task.
Few-Shot Viewpoint Estimation
May 13, 2019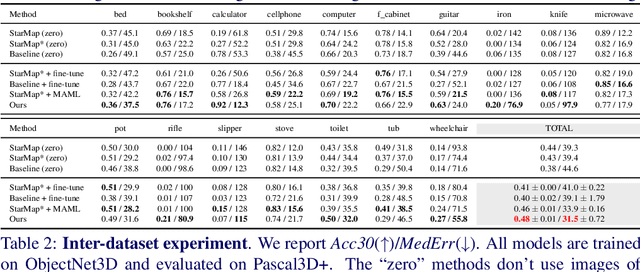
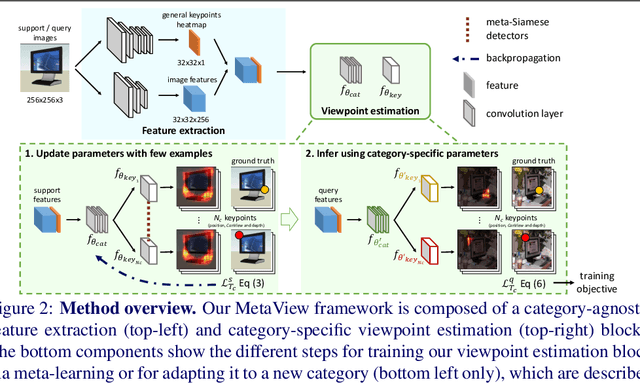
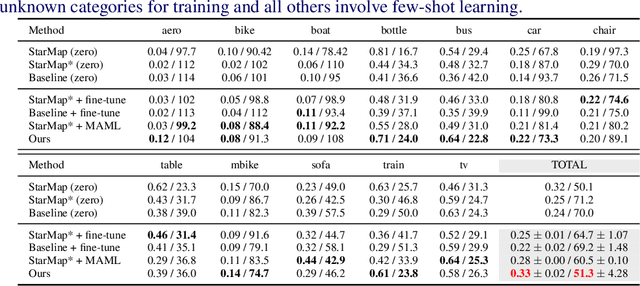
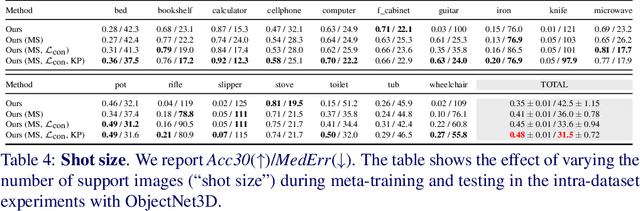
Viewpoint estimation for known categories of objects has been improved significantly thanks to deep networks and large datasets, but generalization to unknown categories is still very challenging. With an aim towards improving performance on unknown categories, we introduce the problem of category-level few-shot viewpoint estimation. We design a novel framework to successfully train viewpoint networks for new categories with few examples (10 or less). We formulate the problem as one of learning to estimate category-specific 3D canonical shapes, their associated depth estimates, and semantic 2D keypoints. We apply meta-learning to learn weights for our network that are amenable to category-specific few-shot fine-tuning. Furthermore, we design a flexible meta-Siamese network that maximizes information sharing during meta-learning. Through extensive experimentation on the ObjectNet3D and Pascal3D+ benchmark datasets, we demonstrate that our framework, which we call MetaView, significantly outperforms fine-tuning the state-of-the-art models with few examples, and that the specific architectural innovations of our method are crucial to achieving good performance.
DRIT++: Diverse Image-to-Image Translation via Disentangled Representations
May 02, 2019
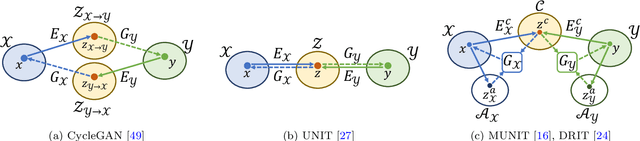
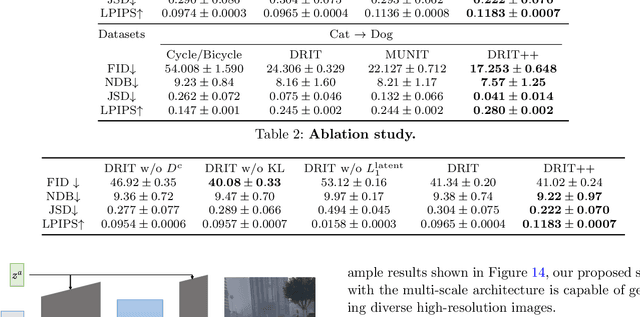
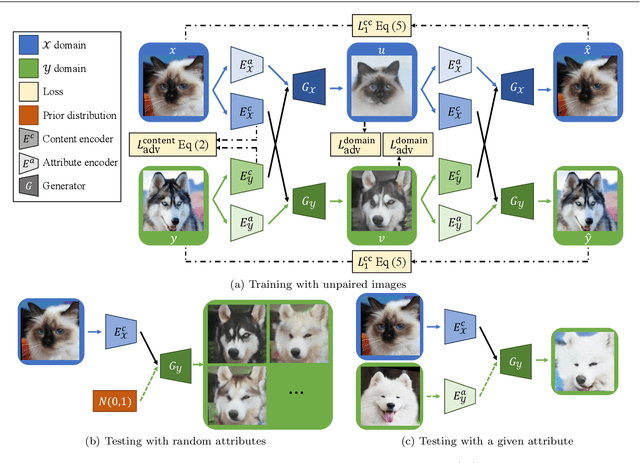
Image-to-image translation aims to learn the mapping between two visual domains. There are two main challenges for this task: 1) lack of aligned training pairs and 2) multiple possible outputs from a single input image. In this work, we present an approach based on disentangled representation for generating diverse outputs without paired training images. To synthesize diverse outputs, we propose to embed images onto two spaces: a domain-invariant content space capturing shared information across domains and a domain-specific attribute space. Our model takes the encoded content features extracted from a given input and attribute vectors sampled from the attribute space to synthesize diverse outputs at test time. To handle unpaired training data, we introduce a cross-cycle consistency loss based on disentangled representations. Qualitative results show that our model can generate diverse and realistic images on a wide range of tasks without paired training data. For quantitative evaluations, we measure realism with user study and Fr\'{e}chet inception distance, and measure diversity with the perceptual distance metric, Jensen-Shannon divergence, and number of statistically-different bins.
Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis
Apr 03, 2019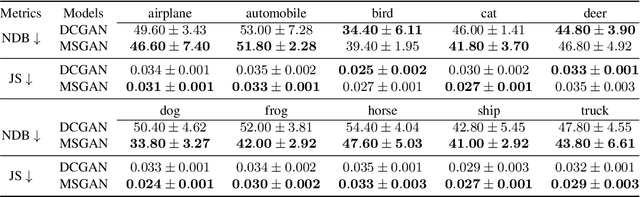
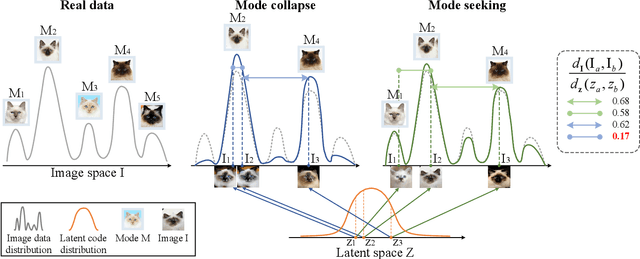

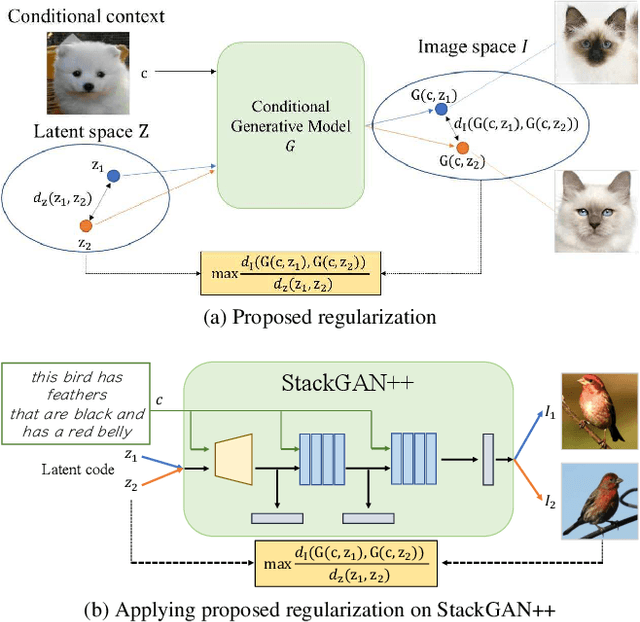
Most conditional generation tasks expect diverse outputs given a single conditional context. However, conditional generative adversarial networks (cGANs) often focus on the prior conditional information and ignore the input noise vectors, which contribute to the output variations. Recent attempts to resolve the mode collapse issue for cGANs are usually task-specific and computationally expensive. In this work, we propose a simple yet effective regularization term to address the mode collapse issue for cGANs. The proposed method explicitly maximizes the ratio of the distance between generated images with respect to the corresponding latent codes, thus encouraging the generators to explore more minor modes during training. This mode seeking regularization term is readily applicable to various conditional generation tasks without imposing training overhead or modifying the original network structures. We validate the proposed algorithm on three conditional image synthesis tasks including categorical generation, image-to-image translation, and text-to-image synthesis with different baseline models. Both qualitative and quantitative results demonstrate the effectiveness of the proposed regularization method for improving diversity without loss of quality.