 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-augmented Agentic AI for Mental Health Medication Information Seeking
Jun 24, 2026Patients increasingly seek medication information online, yet safety knowledge for psychiatric drugs is split between regulatory adverse-event records, which are authoritative but abstract, and patient narratives, which are experience-near but unvalidated. Integrating them without conflating evidence and anecdote is especially consequential in psychiatry, where poorly contextualised information can amplify fear, nocebo responses, and non-adherence. Here we develop a provenance-aware, knowledge-graph-based multi-agent framework unifying 466,525 Reddit posts, 60,782 WebMD reviews, and twenty years of U.S. FDA Adverse Event Reporting System records for nine antidepressants. A large-language-model entity-recognition pipeline benchmarked against physician annotations reached highest F1 scores of 0.969 for medications and 0.973 for conditions. The two community platforms were far more concordant with each other (overlap up to a Jaccard similarity of 0.905) than with regulatory reports, indicating that patient-generated data form a partly independent safety signal. For sertraline, many adverse events appeared in community sources hundreds of days before the corresponding FDA date. A Neo4j knowledge graph grounded in ATC-N, ICD-10, and MedDRA vocabularies preserves provenance, keeping every claim traceable and regulatory facts distinct from patient experience. These results establish source-aware integration as a route to more auditable psychiatric medication information, with usefulness and patient benefit to be tested prospectively.
AIPatient Arena: EHR-grounded evaluation of large language models in end-to-end clinical consultation workflows
Jun 16, 2026Large language models (LLMs) are increasingly considered for use in clinical consultation tasks, yet most medical evaluations remain static, single-turn, or narrowly outcome-based, limiting their ability to reflect the sequential, uncertain, and interactive nature of real-world care. Here, we propose AIPatient Arena, an EHRs-grounded evaluation framework for assessing the clinical utility of LLMs across eight dimensions of clinical competence. The framework integrates EHR data into patient-specific knowledge graphs, enabling multi-turn physician-patient interactions. We applied AIPatient Arena on a primary cohort of 437 patients and two out-of-distribution validation cohorts of 119 and 67 patients. We observe that LLMs performed well in medical interview questioning skills (QS; mean scores, 4.43-4.99/5), ethical and professional conduct (ET; 4.38-4.93/5), and clarity and transparency of clinical explanations (EX; 3.80-4.72/5). Performance was moderate in information integration (II; 3.19-4.21/5) and medication safety and justification (MS; 3.13-3.78/5), but persistent weaknesses were observed in handling of ambiguous patient responses (HR; 2.57-3.32/5), information coverage (IC; 2.08-3.02/5), and diagnostic accuracy and reasoning (Dx; 2.63-3.55/5). Process-based evaluation revealed recurrent interaction failures, including repetitive questioning, omission of past medical history, and inadequate handling of uncertainty. Richer conversational context improved diagnostic reasoning but yielded limited gains in treatment planning. These findings indicate that final-answer accuracy alone is insufficient for evaluating clinical readiness and highlight the importance of assessing how models gather, interpret, and communicate information throughout a consultation. AIPatient Arena provides an EHR-grounded framework for workflow-oriented pre-deployment evaluation of medical LLMs.
Evaluating an evidence-guided reinforcement learning framework in aligning light-parameter large language models with decision-making cognition in psychiatric clinical reasoning
Feb 06, 2026Large language models (LLMs) hold transformative potential for medical decision support yet their application in psychiatry remains constrained by hallucinations and superficial reasoning. This limitation is particularly acute in light-parameter LLMs which are essential for privacy-preserving and efficient clinical deployment. Existing training paradigms prioritize linguistic fluency over structured clinical logic and result in a fundamental misalignment with professional diagnostic cognition. Here we introduce ClinMPO, a reinforcement learning framework designed to align the internal reasoning of LLMs with professional psychiatric practice. The framework employs a specialized reward model trained independently on a dataset derived from 4,474 psychiatry journal articles and structured according to evidence-based medicine principles. We evaluated ClinMPO on a unseen subset of the benchmark designed to isolate reasoning capabilities from rote memorization. This test set comprises items where leading large-parameter LLMs consistently fail. We compared the ClinMPO-aligned light LLM performance against a cohort of 300 medical students. The ClinMPO-tuned Qwen3-8B model achieved a diagnostic accuracy of 31.4% and surpassed the human benchmark of 30.8% on these complex cases. These results demonstrate that medical evidence-guided optimization enables light-parameter LLMs to master complex reasoning tasks. Our findings suggest that explicit cognitive alignment offers a scalable pathway to reliable and safe psychiatric decision support.
AIPatient: Simulating Patients with EHRs and LLM Powered Agentic Workflow
Sep 27, 2024



Simulated patient systems play a crucial role in modern medical education and research, providing safe, integrative learning environments and enabling clinical decision-making simulations. Large Language Models (LLM) could advance simulated patient systems by replicating medical conditions and patient-doctor interactions with high fidelity and low cost. However, ensuring the effectiveness and trustworthiness of these systems remains a challenge, as they require a large, diverse, and precise patient knowledgebase, along with a robust and stable knowledge diffusion to users. Here, we developed AIPatient, an advanced simulated patient system with AIPatient Knowledge Graph (AIPatient KG) as the input and the Reasoning Retrieval-Augmented Generation (Reasoning RAG) agentic workflow as the generation backbone. AIPatient KG samples data from Electronic Health Records (EHRs) in the Medical Information Mart for Intensive Care (MIMIC)-III database, producing a clinically diverse and relevant cohort of 1,495 patients with high knowledgebase validity (F1 0.89). Reasoning RAG leverages six LLM powered agents spanning tasks including retrieval, KG query generation, abstraction, checker, rewrite, and summarization. This agentic framework reaches an overall accuracy of 94.15% in EHR-based medical Question Answering (QA), outperforming benchmarks that use either no agent or only partial agent integration. Our system also presents high readability (median Flesch Reading Ease 77.23; median Flesch Kincaid Grade 5.6), robustness (ANOVA F-value 0.6126, p<0.1), and stability (ANOVA F-value 0.782, p<0.1). The promising performance of the AIPatient system highlights its potential to support a wide range of applications, including medical education, model evaluation, and system integration.
Large Language Models in Biomedical and Health Informatics: A Bibliometric Review
Mar 26, 2024Large Language Models (LLMs) have rapidly become important tools in Biomedical and Health Informatics (BHI), enabling new ways to analyze data, treat patients, and conduct research. This bibliometric review aims to provide a panoramic view of how LLMs have been used in BHI by examining research articles and collaboration networks from 2022 to 2023. It further explores how LLMs can improve Natural Language Processing (NLP) applications in various BHI areas like medical diagnosis, patient engagement, electronic health record management, and personalized medicine. To do this, our bibliometric review identifies key trends, maps out research networks, and highlights major developments in this fast-moving field. Lastly, it discusses the ethical concerns and practical challenges of using LLMs in BHI, such as data privacy and reliable medical recommendations. Looking ahead, we consider how LLMs could further transform biomedical research as well as healthcare delivery and patient outcomes. This bibliometric review serves as a resource for stakeholders in healthcare, including researchers, clinicians, and policymakers, to understand the current state and future potential of LLMs in BHI.
A Bibliometric Review of Large Language Models Research from 2017 to 2023
Apr 03, 2023



Large language models (LLMs) are a class of language models that have demonstrated outstanding performance across a range of natural language processing (NLP) tasks and have become a highly sought-after research area, because of their ability to generate human-like language and their potential to revolutionize science and technology. In this study, we conduct bibliometric and discourse analyses of scholarly literature on LLMs. Synthesizing over 5,000 publications, this paper serves as a roadmap for researchers, practitioners, and policymakers to navigate the current landscape of LLMs research. We present the research trends from 2017 to early 2023, identifying patterns in research paradigms and collaborations. We start with analyzing the core algorithm developments and NLP tasks that are fundamental in LLMs research. We then investigate the applications of LLMs in various fields and domains including medicine, engineering, social science, and humanities. Our review also reveals the dynamic, fast-paced evolution of LLMs research. Overall, this paper offers valuable insights into the current state, impact, and potential of LLMs research and its applications.
Learning from Sparse Datasets: Predicting Concrete's Strength by Machine Learning
Apr 29, 2020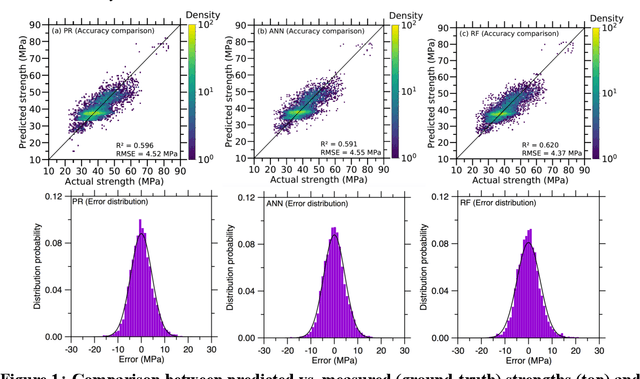
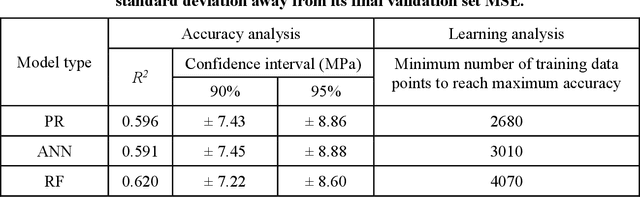
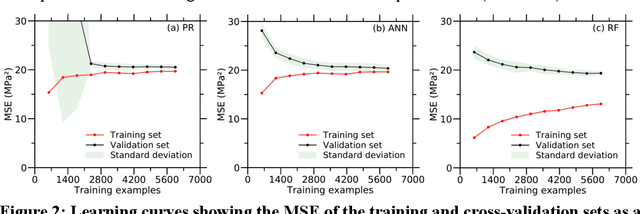
Despite enormous efforts over the last decades to establish the relationship between concrete proportioning and strength, a robust knowledge-based model for accurate concrete strength predictions is still lacking. As an alternative to physical or chemical-based models, data-driven machine learning (ML) methods offer a new solution to this problem. Although this approach is promising for handling the complex, non-linear, non-additive relationship between concrete mixture proportions and strength, a major limitation of ML lies in the fact that large datasets are needed for model training. This is a concern as reliable, consistent strength data is rather limited, especially for realistic industrial concretes. Here, based on the analysis of a large dataset (>10,000 observations) of measured compressive strengths from industrially-produced concretes, we compare the ability of select ML algorithms to "learn" how to reliably predict concrete strength as a function of the size of the dataset. Based on these results, we discuss the competition between how accurate a given model can eventually be (when trained on a large dataset) and how much data is actually required to train this model.