 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUET -- Dual User Embedding Transformers for Offsite Conversion Prediction
Jun 08, 2026Offsite conversion rate (OCVR) prediction is an important ranking problem in computational recommendation systems. This task presents a modeling challenge: click signals are abundant and exhibit short temporal horizons, whereas conversion signals are inherently sparse, long-delayed, and frequently unattributed. Despite these statistical disparities, both signal types must inform models that operate within strict serving-latency constraints. Prior pre-training approaches address this heterogeneity with a single, undifferentiated encoder applied uniformly across both data streams. We propose DUET (Dual User Embedding Transformers), a framework that explicitly partitions user behavioral data into two domain-coherent streams -- clicks and conversions -- and pre-trains dedicated transformer encoders with architectures tailored to each stream's statistical characteristics: multi-layer self-attention for the dense click stream and interleaved cross- and self-attention for the sparse conversion stream. The resulting complementary embeddings are jointly consumed by a downstream ranker without exceeding serving-latency budgets. Evaluation demonstrates up to 0.38% normalized entropy (NE) reduction relative to the strongest baseline, and A/B test shows consistent improvements in OCVR prediction accuracy.
Learning from Sparse Datasets: Predicting Concrete's Strength by Machine Learning
Apr 29, 2020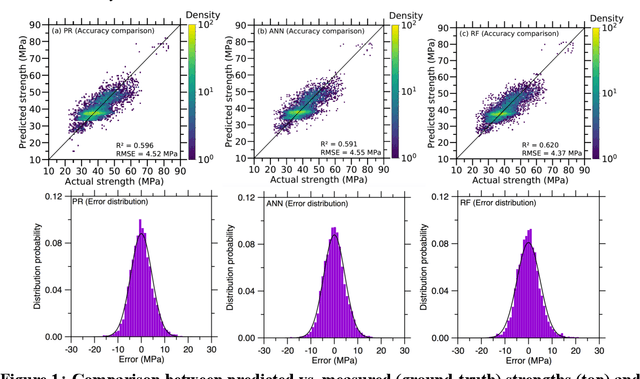
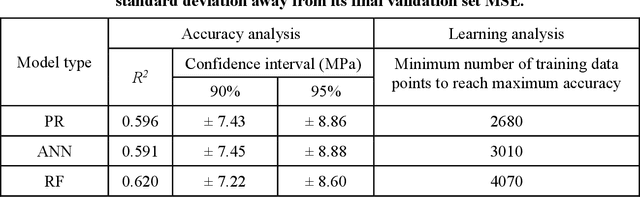
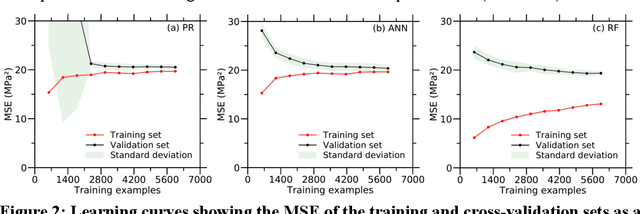
Despite enormous efforts over the last decades to establish the relationship between concrete proportioning and strength, a robust knowledge-based model for accurate concrete strength predictions is still lacking. As an alternative to physical or chemical-based models, data-driven machine learning (ML) methods offer a new solution to this problem. Although this approach is promising for handling the complex, non-linear, non-additive relationship between concrete mixture proportions and strength, a major limitation of ML lies in the fact that large datasets are needed for model training. This is a concern as reliable, consistent strength data is rather limited, especially for realistic industrial concretes. Here, based on the analysis of a large dataset (>10,000 observations) of measured compressive strengths from industrially-produced concretes, we compare the ability of select ML algorithms to "learn" how to reliably predict concrete strength as a function of the size of the dataset. Based on these results, we discuss the competition between how accurate a given model can eventually be (when trained on a large dataset) and how much data is actually required to train this model.