 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Roadmap for Applying Graph Neural Networks to Numerical Data: Insights from Cementitious Materials
Dec 16, 2025Machine learning (ML) has been increasingly applied in concrete research to optimize performance and mixture design. However, one major challenge in applying ML to cementitious materials is the limited size and diversity of available databases. A promising solution is the development of multi-modal databases that integrate both numerical and graphical data. Conventional ML frameworks in cement research are typically restricted to a single data modality. Graph neural network (GNN) represents a new generation of neural architectures capable of learning from data structured as graphs, capturing relationships through irregular or topology-dependent connections rather than fixed spatial coordinates. While GNN is inherently designed for graphical data, they can be adapted to extract correlations from numerical datasets and potentially embed physical laws directly into their architecture, enabling explainable and physics-informed predictions. This work is among the first few studies to implement GNNs to design concrete, with a particular emphasis on establishing a clear and reproducible pathway for converting tabular data into graph representations using the k-nearest neighbor (K-NN) approach. Model hyperparameters and feature selection are systematically optimized to enhance prediction performance. The GNN shows performance comparable to the benchmark random forest, which has been demonstrated by many studies to yield reliable predictions for cementitious materials. Overall, this study provides a foundational roadmap for transitioning from traditional ML to advanced AI architectures. The proposed framework establishes a strong foundation for future multi-modal and physics-informed GNN models capable of capturing complex material behaviors and accelerating the design and optimization of cementitious materials.
Learning from Sparse Datasets: Predicting Concrete's Strength by Machine Learning
Apr 29, 2020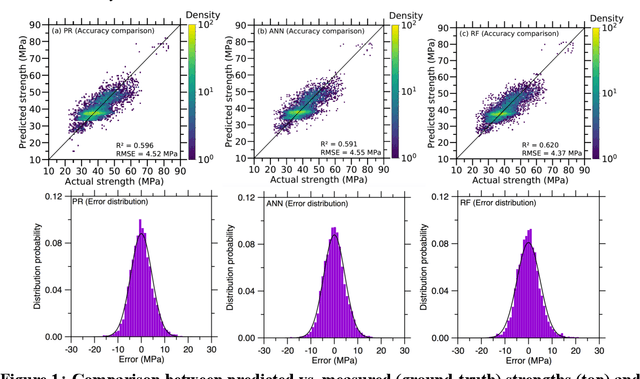
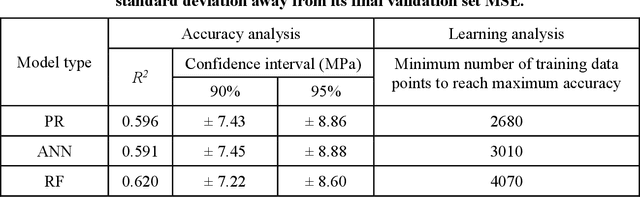
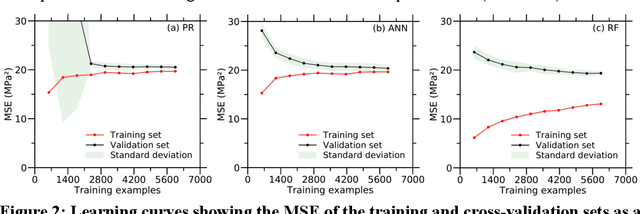
Despite enormous efforts over the last decades to establish the relationship between concrete proportioning and strength, a robust knowledge-based model for accurate concrete strength predictions is still lacking. As an alternative to physical or chemical-based models, data-driven machine learning (ML) methods offer a new solution to this problem. Although this approach is promising for handling the complex, non-linear, non-additive relationship between concrete mixture proportions and strength, a major limitation of ML lies in the fact that large datasets are needed for model training. This is a concern as reliable, consistent strength data is rather limited, especially for realistic industrial concretes. Here, based on the analysis of a large dataset (>10,000 observations) of measured compressive strengths from industrially-produced concretes, we compare the ability of select ML algorithms to "learn" how to reliably predict concrete strength as a function of the size of the dataset. Based on these results, we discuss the competition between how accurate a given model can eventually be (when trained on a large dataset) and how much data is actually required to train this model.