 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Multimodal Multivariate Learning
Jun 14, 2022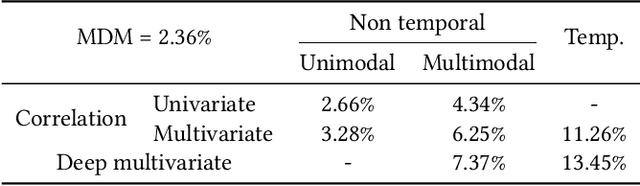
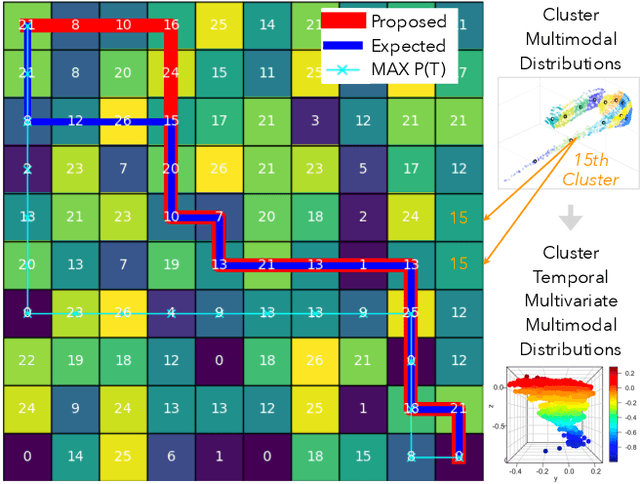

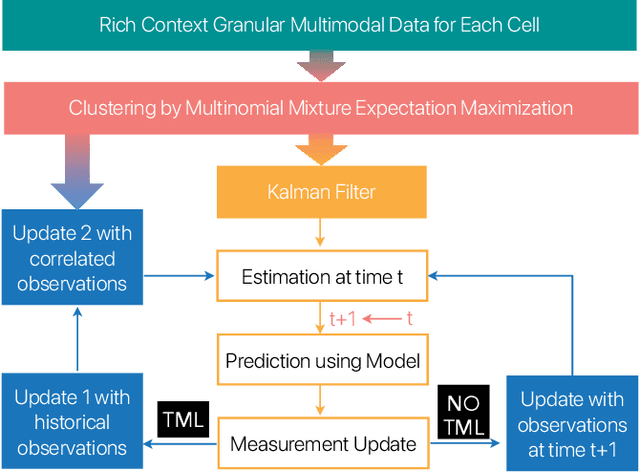
We introduce temporal multimodal multivariate learning, a new family of decision making models that can indirectly learn and transfer online information from simultaneous observations of a probability distribution with more than one peak or more than one outcome variable from one time stage to another. We approximate the posterior by sequentially removing additional uncertainties across different variables and time, based on data-physics driven correlation, to address a broader class of challenging time-dependent decision-making problems under uncertainty. Extensive experiments on real-world datasets ( i.e., urban traffic data and hurricane ensemble forecasting data) demonstrate the superior performance of the proposed targeted decision-making over the state-of-the-art baseline prediction methods across various settings.
Knowledge-enhanced Session-based Recommendation with Temporal Transformer
Dec 16, 2021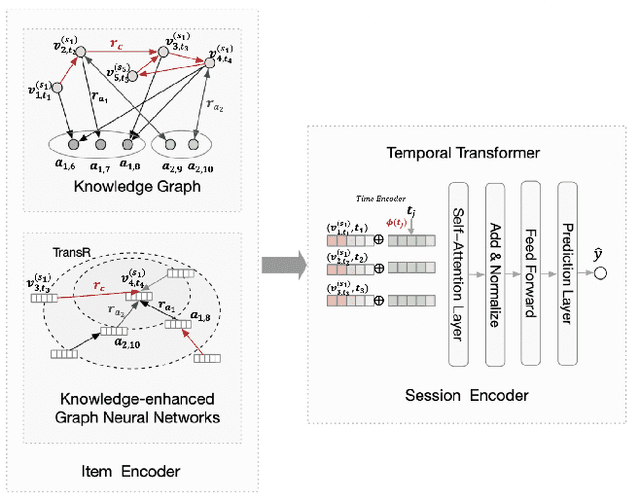
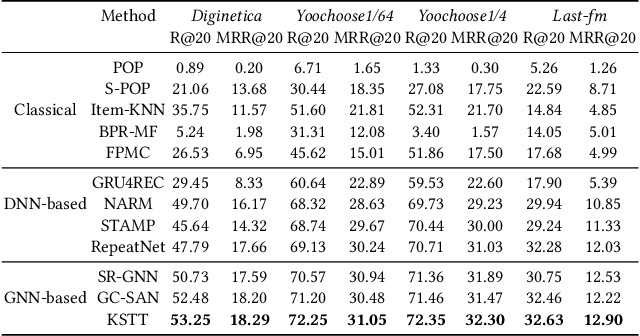
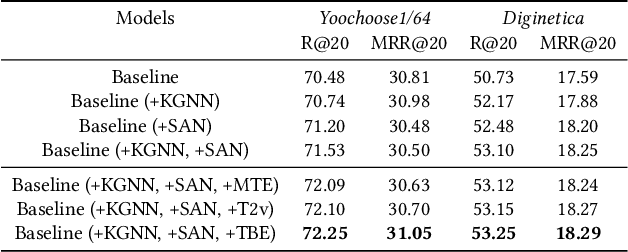
Recent research has achieved impressive progress in the session-based recommendation. However, information such as item knowledge and click time interval, which could be potentially utilized to improve the performance, remains largely unexploited. In this paper, we propose a framework called Knowledge-enhanced Session-based Recommendation with Temporal Transformer (KSTT) to incorporate such information when learning the item and session embeddings. Specifically, a knowledge graph, which models contexts among items within a session and their corresponding attributes, is proposed to obtain item embeddings through graph representation learning. We introduce time interval embedding to represent the time pattern between the item that needs to be predicted and historical click, and use it to replace the position embedding in the original transformer (called temporal transformer). The item embeddings in a session are passed through the temporal transformer network to get the session embedding, based on which the final recommendation is made. Extensive experiments demonstrate that our model outperforms state-of-the-art baselines on four benchmark datasets.
Narrative Question Answering with Cutting-Edge Open-Domain QA Techniques: A Comprehensive Study
Jun 07, 2021
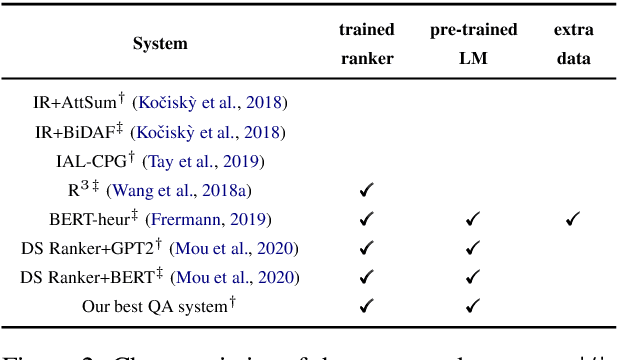
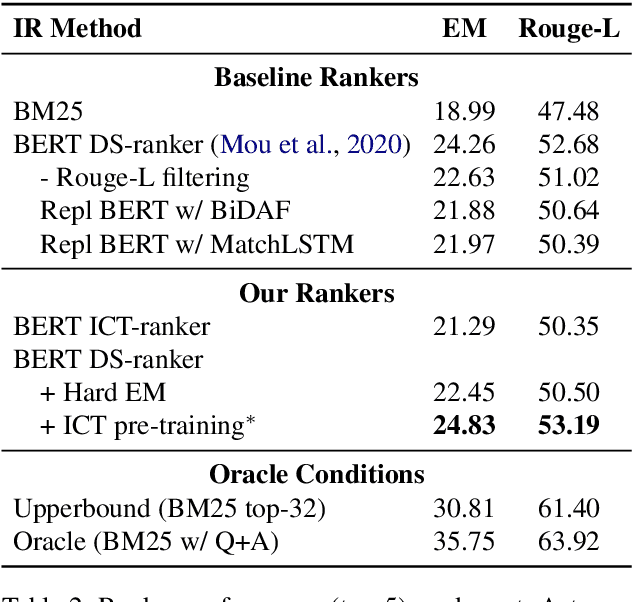

Recent advancements in open-domain question answering (ODQA), i.e., finding answers from large open-domain corpus like Wikipedia, have led to human-level performance on many datasets. However, progress in QA over book stories (Book QA) lags behind despite its similar task formulation to ODQA. This work provides a comprehensive and quantitative analysis about the difficulty of Book QA: (1) We benchmark the research on the NarrativeQA dataset with extensive experiments with cutting-edge ODQA techniques. This quantifies the challenges Book QA poses, as well as advances the published state-of-the-art with a $\sim$7\% absolute improvement on Rouge-L. (2) We further analyze the detailed challenges in Book QA through human studies.\footnote{\url{https://github.com/gorov/BookQA}.} Our findings indicate that the event-centric questions dominate this task, which exemplifies the inability of existing QA models to handle event-oriented scenarios.
Complementary Evidence Identification in Open-Domain Question Answering
Apr 05, 2021
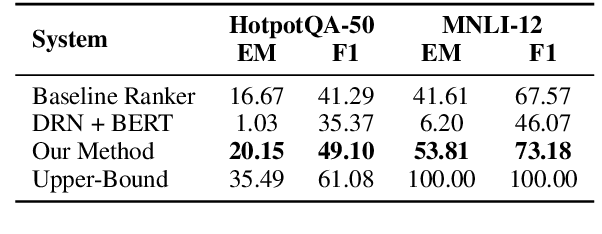

This paper proposes a new problem of complementary evidence identification for open-domain question answering (QA). The problem aims to efficiently find a small set of passages that covers full evidence from multiple aspects as to answer a complex question. To this end, we proposes a method that learns vector representations of passages and models the sufficiency and diversity within the selected set, in addition to the relevance between the question and passages. Our experiments demonstrate that our method considers the dependence within the supporting evidence and significantly improves the accuracy of complementary evidence selection in QA domain.
Neural Data-to-Text Generation with LM-based Text Augmentation
Feb 06, 2021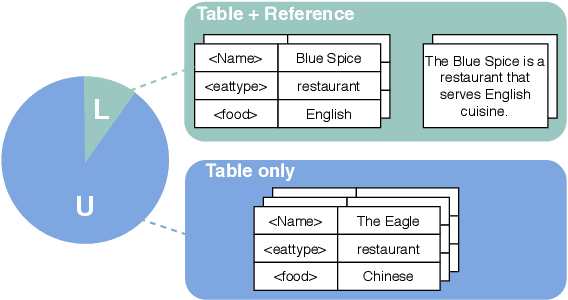
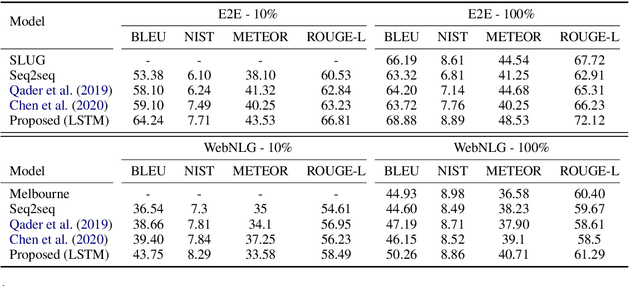
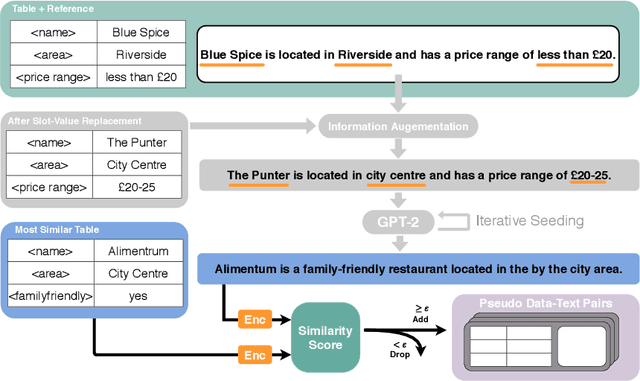
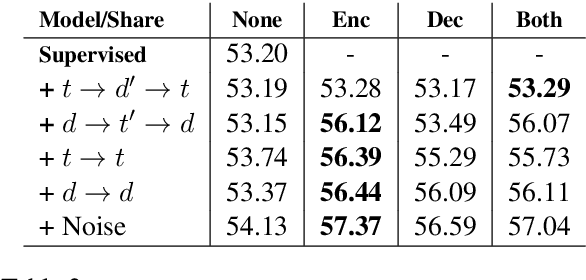
For many new application domains for data-to-text generation, the main obstacle in training neural models consists of a lack of training data. While usually large numbers of instances are available on the data side, often only very few text samples are available. To address this problem, we here propose a novel few-shot approach for this setting. Our approach automatically augments the data available for training by (i) generating new text samples based on replacing specific values by alternative ones from the same category, (ii) generating new text samples based on GPT-2, and (iii) proposing an automatic method for pairing the new text samples with data samples. As the text augmentation can introduce noise to the training data, we use cycle consistency as an objective, in order to make sure that a given data sample can be correctly reconstructed after having been formulated as text (and that text samples can be reconstructed from data). On both the E2E and WebNLG benchmarks, we show that this weakly supervised training paradigm is able to outperform fully supervised seq2seq models with less than 10% annotations. By utilizing all annotated data, our model can boost the performance of a standard seq2seq model by over 5 BLEU points, establishing a new state-of-the-art on both datasets.
Patient-Specific Seizure Prediction Using Single Seizure Electroencephalography Recording
Nov 14, 2020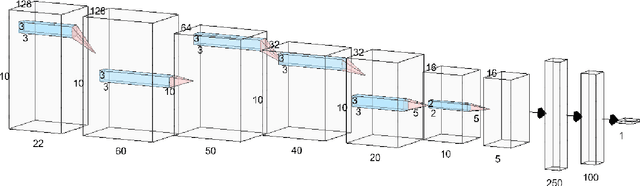
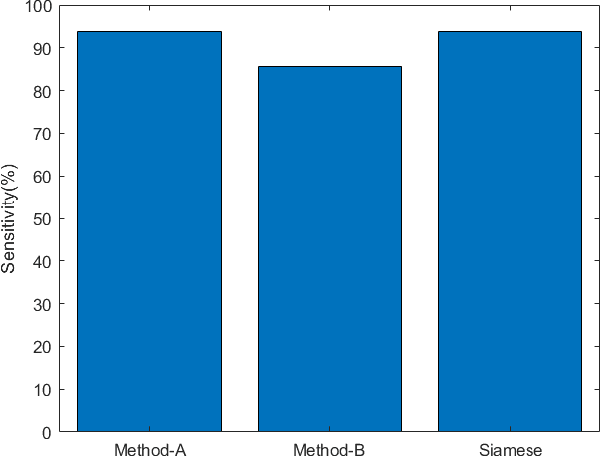
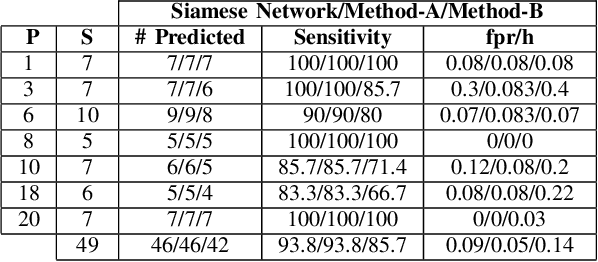
Electroencephalogram (EEG) is a prominent way to measure the brain activity for studying epilepsy, thereby helping in predicting seizures. Seizure prediction is an active research area with many deep learning based approaches dominating the recent literature for solving this problem. But these models require a considerable number of patient-specific seizures to be recorded for extracting the preictal and interictal EEG data for training a classifier. The increase in sensitivity and specificity for seizure prediction using the machine learning models is noteworthy. However, the need for a significant number of patient-specific seizures and periodic retraining of the model because of non-stationary EEG creates difficulties for designing practical device for a patient. To mitigate this process, we propose a Siamese neural network based seizure prediction method that takes a wavelet transformed EEG tensor as an input with convolutional neural network (CNN) as the base network for detecting change-points in EEG. Compared to the solutions in the literature, which utilize days of EEG recordings, our method only needs one seizure for training which translates to less than ten minutes of preictal and interictal data while still getting comparable results to models which utilize multiple seizures for seizure prediction.
Deep Structured Prediction for Facial Landmark Detection
Oct 18, 2020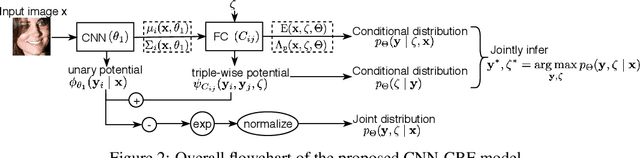
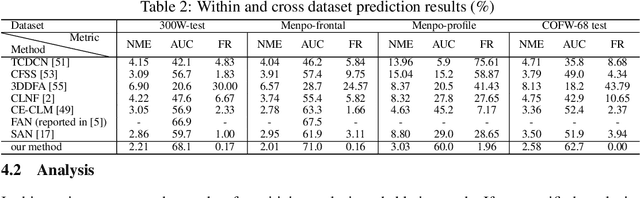

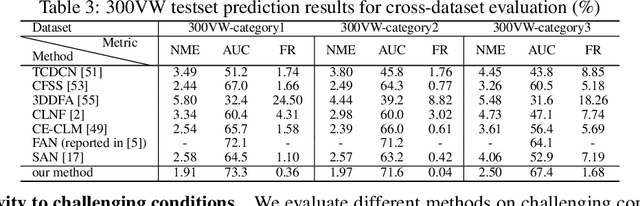
Existing deep learning based facial landmark detection methods have achieved excellent performance. These methods, however, do not explicitly embed the structural dependencies among landmark points. They hence cannot preserve the geometric relationships between landmark points or generalize well to challenging conditions or unseen data. This paper proposes a method for deep structured facial landmark detection based on combining a deep Convolutional Network with a Conditional Random Field. We demonstrate its superior performance to existing state-of-the-art techniques in facial landmark detection, especially a better generalization ability on challenging datasets that include large pose and occlusion.
Multimodal Dialogue State Tracking By QA Approach with Data Augmentation
Jul 20, 2020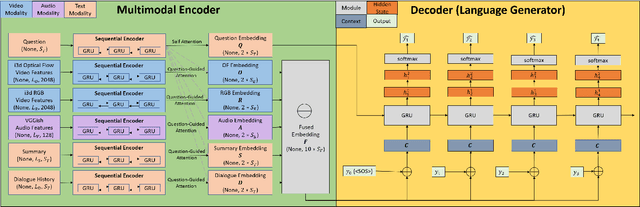
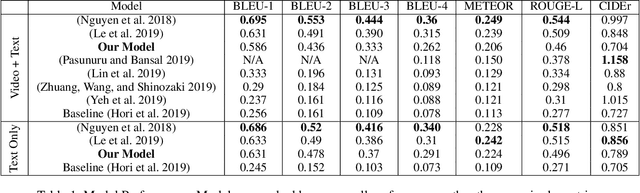


Recently, a more challenging state tracking task, Audio-Video Scene-Aware Dialogue (AVSD), is catching an increasing amount of attention among researchers. Different from purely text-based dialogue state tracking, the dialogue in AVSD contains a sequence of question-answer pairs about a video and the final answer to the given question requires additional understanding of the video. This paper interprets the AVSD task from an open-domain Question Answering (QA) point of view and proposes a multimodal open-domain QA system to deal with the problem. The proposed QA system uses common encoder-decoder framework with multimodal fusion and attention. Teacher forcing is applied to train a natural language generator. We also propose a new data augmentation approach specifically under QA assumption. Our experiments show that our model and techniques bring significant improvements over the baseline model on the DSTC7-AVSD dataset and demonstrate the potentials of our data augmentation techniques.
Frustratingly Hard Evidence Retrieval for QA Over Books
Jul 20, 2020
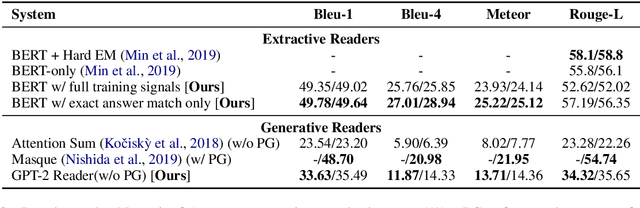
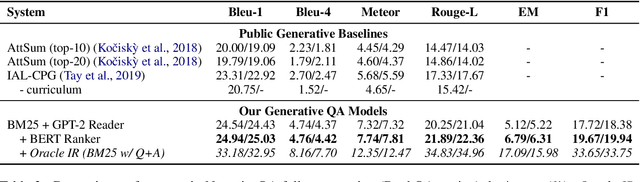
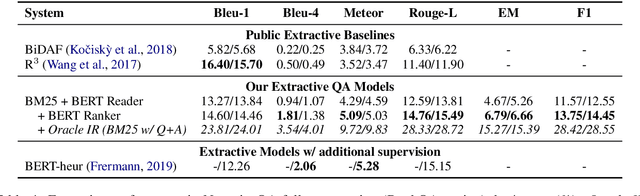
A lot of progress has been made to improve question answering (QA) in recent years, but the special problem of QA over narrative book stories has not been explored in-depth. We formulate BookQA as an open-domain QA task given its similar dependency on evidence retrieval. We further investigate how state-of-the-art open-domain QA approaches can help BookQA. Besides achieving state-of-the-art on the NarrativeQA benchmark, our study also reveals the difficulty of evidence retrieval in books with a wealth of experiments and analysis - which necessitates future effort on novel solutions for evidence retrieval in BookQA.
Diversifying Dialogue Generation with Non-Conversational Text
May 13, 2020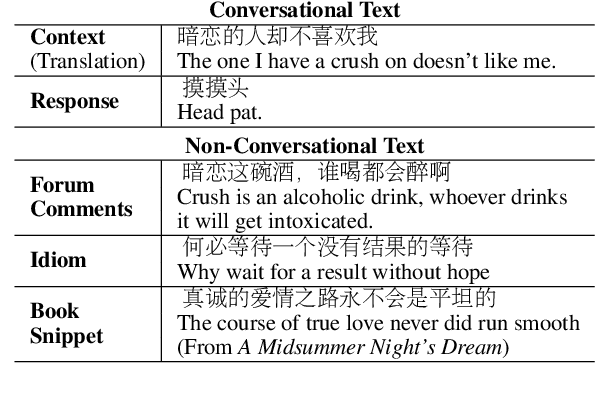
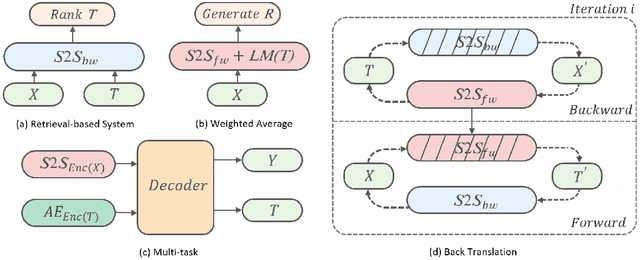
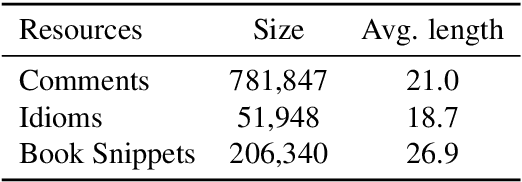
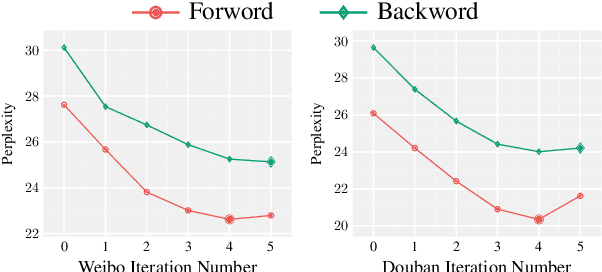
Neural network-based sequence-to-sequence (seq2seq) models strongly suffer from the low-diversity problem when it comes to open-domain dialogue generation. As bland and generic utterances usually dominate the frequency distribution in our daily chitchat, avoiding them to generate more interesting responses requires complex data filtering, sampling techniques or modifying the training objective. In this paper, we propose a new perspective to diversify dialogue generation by leveraging non-conversational text. Compared with bilateral conversations, non-conversational text are easier to obtain, more diverse and cover a much broader range of topics. We collect a large-scale non-conversational corpus from multi sources including forum comments, idioms and book snippets. We further present a training paradigm to effectively incorporate these text via iterative back translation. The resulting model is tested on two conversational datasets and is shown to produce significantly more diverse responses without sacrificing the relevance with context.