 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore-Bench: Data Sets, Metrics and Evaluations for Frontier-based and Deep-reinforcement-learning-based Autonomous Exploration
Feb 24, 2022
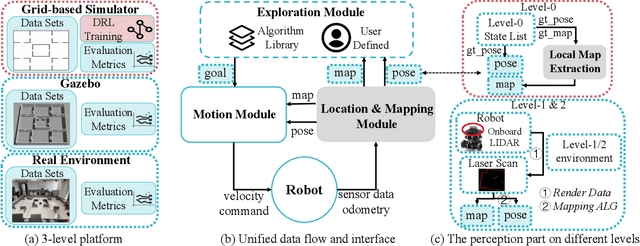
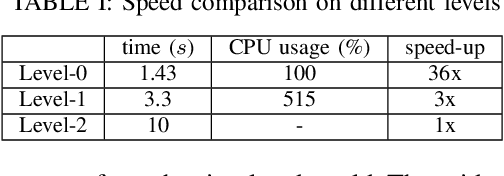
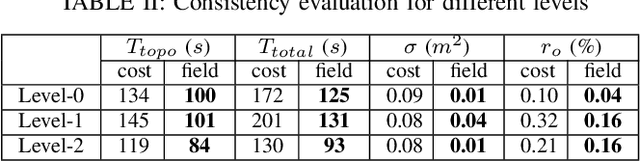
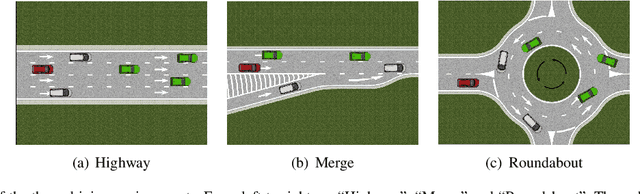
Autonomous exploration and mapping of unknown terrains employing single or multiple robots is an essential task in mobile robotics and has therefore been widely investigated. Nevertheless, given the lack of unified data sets, metrics, and platforms to evaluate the exploration approaches, we develop an autonomous robot exploration benchmark entitled Explore-Bench. The benchmark involves various exploration scenarios and presents two types of quantitative metrics to evaluate exploration efficiency and multi-robot cooperation. Explore-Bench is extremely useful as, recently, deep reinforcement learning (DRL) has been widely used for robot exploration tasks and achieved promising results. However, training DRL-based approaches requires large data sets, and additionally, current benchmarks rely on realistic simulators with a slow simulation speed, which is not appropriate for training exploration strategies. Hence, to support efficient DRL training and comprehensive evaluation, the suggested Explore-Bench designs a 3-level platform with a unified data flow and $12 \times$ speed-up that includes a grid-based simulator for fast evaluation and efficient training, a realistic Gazebo simulator, and a remotely accessible robot testbed for high-accuracy tests in physical environments. The practicality of the proposed benchmark is highlighted with the application of one DRL-based and three frontier-based exploration approaches. Furthermore, we analyze the performance differences and provide some insights about the selection and design of exploration methods. Our benchmark is available at https://github.com/efc-robot/Explore-Bench.
Multi-Agent Vulnerability Discovery for Autonomous Driving with Hazard Arbitration Reward
Dec 12, 2021
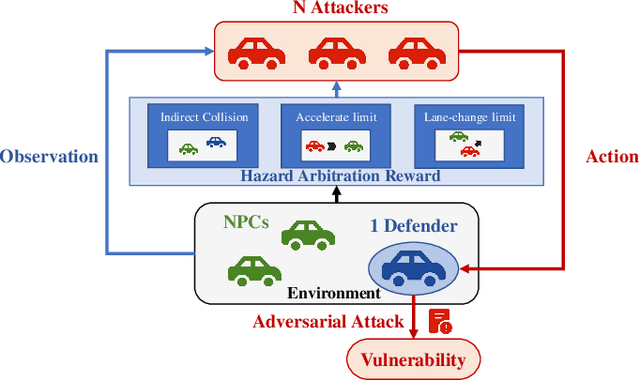

Discovering hazardous scenarios is crucial in testing and further improving driving policies. However, conducting efficient driving policy testing faces two key challenges. On the one hand, the probability of naturally encountering hazardous scenarios is low when testing a well-trained autonomous driving strategy. Thus, discovering these scenarios by purely real-world road testing is extremely costly. On the other hand, a proper determination of accident responsibility is necessary for this task. Collecting scenarios with wrong-attributed responsibilities will lead to an overly conservative autonomous driving strategy. To be more specific, we aim to discover hazardous scenarios that are autonomous-vehicle responsible (AV-responsible), i.e., the vulnerabilities of the under-test driving policy. To this end, this work proposes a Safety Test framework by finding Av-Responsible Scenarios (STARS) based on multi-agent reinforcement learning. STARS guides other traffic participants to produce Av-Responsible Scenarios and make the under-test driving policy misbehave via introducing Hazard Arbitration Reward (HAR). HAR enables our framework to discover diverse, complex, and AV-responsible hazardous scenarios. Experimental results against four different driving policies in three environments demonstrate that STARS can effectively discover AV-responsible hazardous scenarios. These scenarios indeed correspond to the vulnerabilities of the under-test driving policies, thus are meaningful for their further improvements.
Variational Automatic Curriculum Learning for Sparse-Reward Cooperative Multi-Agent Problems
Nov 08, 2021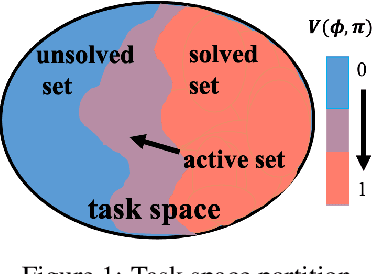

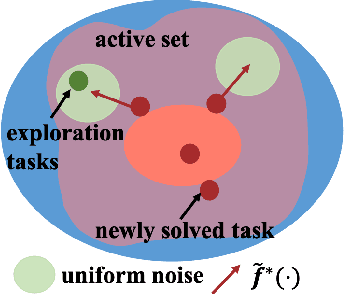

We introduce a curriculum learning algorithm, Variational Automatic Curriculum Learning (VACL), for solving challenging goal-conditioned cooperative multi-agent reinforcement learning problems. We motivate our paradigm through a variational perspective, where the learning objective can be decomposed into two terms: task learning on the current task distribution, and curriculum update to a new task distribution. Local optimization over the second term suggests that the curriculum should gradually expand the training tasks from easy to hard. Our VACL algorithm implements this variational paradigm with two practical components, task expansion and entity progression, which produces training curricula over both the task configurations as well as the number of entities in the task. Experiment results show that VACL solves a collection of sparse-reward problems with a large number of agents. Particularly, using a single desktop machine, VACL achieves 98% coverage rate with 100 agents in the simple-spread benchmark and reproduces the ramp-use behavior originally shown in OpenAI's hide-and-seek project. Our project website is at https://sites.google.com/view/vacl-neurips-2021.
Learning Efficient Multi-Agent Cooperative Visual Exploration
Oct 12, 2021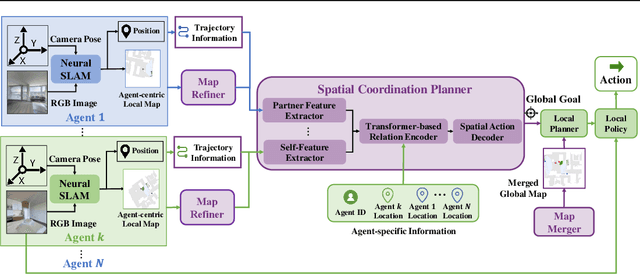
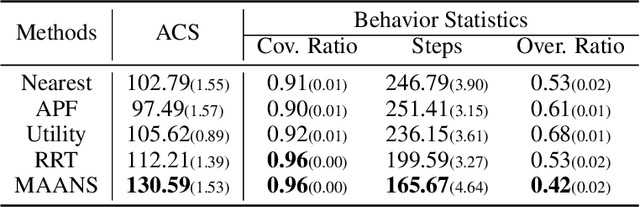
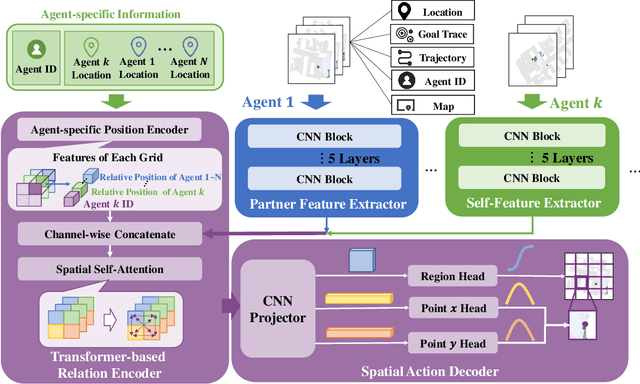
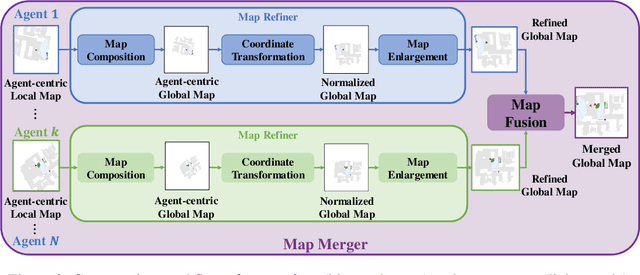
We consider the task of visual indoor exploration with multiple agents, where the agents need to cooperatively explore the entire indoor region using as few steps as possible. Classical planning-based methods often suffer from particularly expensive computation at each inference step and a limited expressiveness of cooperation strategy. By contrast, reinforcement learning (RL) has become a trending paradigm for tackling this challenge due to its modeling capability of arbitrarily complex strategies and minimal inference overhead. We extend the state-of-the-art single-agent RL solution, Active Neural SLAM (ANS), to the multi-agent setting by introducing a novel RL-based global-goal planner, Spatial Coordination Planner (SCP), which leverages spatial information from each individual agent in an end-to-end manner and effectively guides the agents to navigate towards different spatial goals with high exploration efficiency. SCP consists of a transformer-based relation encoder to capture intra-agent interactions and a spatial action decoder to produce accurate goals. In addition, we also implement a few multi-agent enhancements to process local information from each agent for an aligned spatial representation and more precise planning. Our final solution, Multi-Agent Active Neural SLAM (MAANS), combines all these techniques and substantially outperforms 4 different planning-based methods and various RL baselines in the photo-realistic physical testbed, Habitat.
Ensemble-in-One: Learning Ensemble within Random Gated Networks for Enhanced Adversarial Robustness
Mar 27, 2021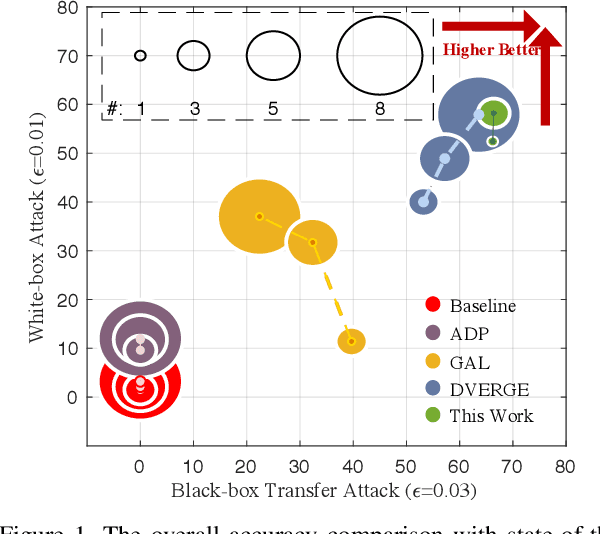
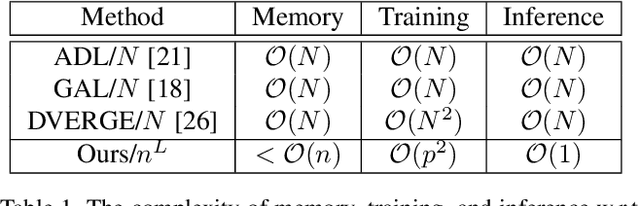
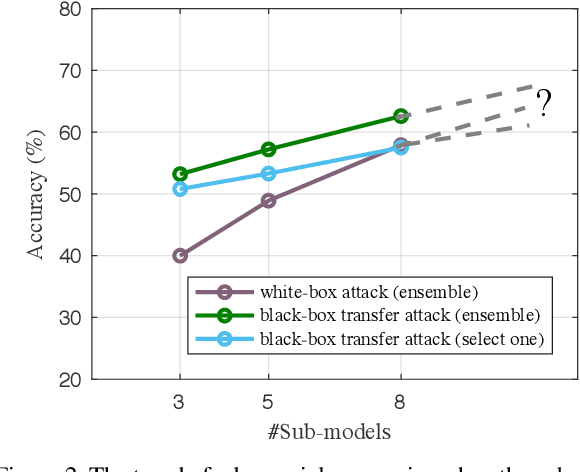
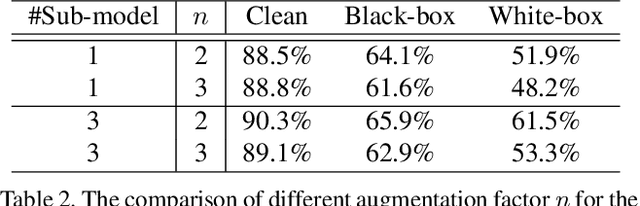
Adversarial attacks have rendered high security risks on modern deep learning systems. Adversarial training can significantly enhance the robustness of neural network models by suppressing the non-robust features. However, the models often suffer from significant accuracy loss on clean data. Ensemble training methods have emerged as promising solutions for defending against adversarial attacks by diversifying the vulnerabilities among the sub-models, simultaneously maintaining comparable accuracy as standard training. However, existing ensemble methods are with poor scalability, owing to the rapid complexity increase when including more sub-models in the ensemble. Moreover, in real-world applications, it is difficult to deploy an ensemble with multiple sub-models, owing to the tight hardware resource budget and latency requirement. In this work, we propose ensemble-in-one (EIO), a simple but efficient way to train an ensemble within one random gated network (RGN). EIO augments the original model by replacing the parameterized layers with multi-path random gated blocks (RGBs) to construct a RGN. By diversifying the vulnerability of the numerous paths within the RGN, better robustness can be achieved. It provides high scalability because the paths within an EIO network exponentially increase with the network depth. Our experiments demonstrate that EIO consistently outperforms previous ensemble training methods with even less computational overhead.
Machine Learning for Electronic Design Automation: A Survey
Jan 10, 2021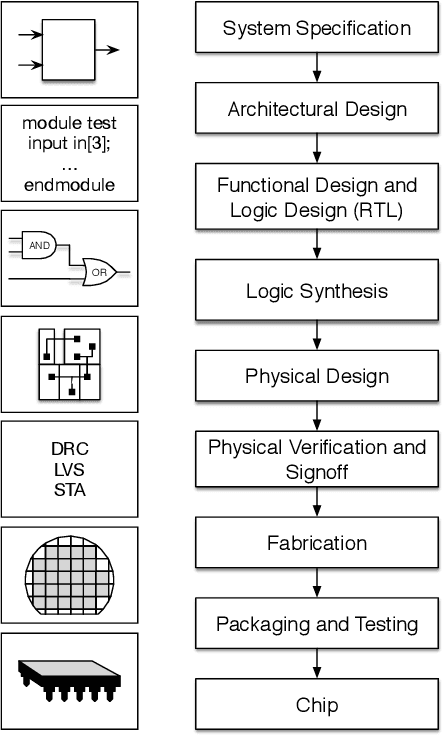

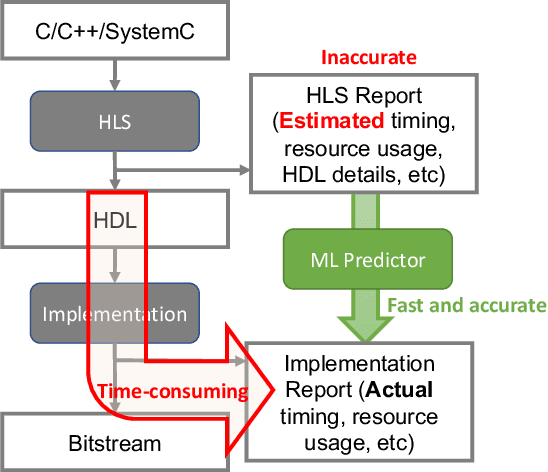
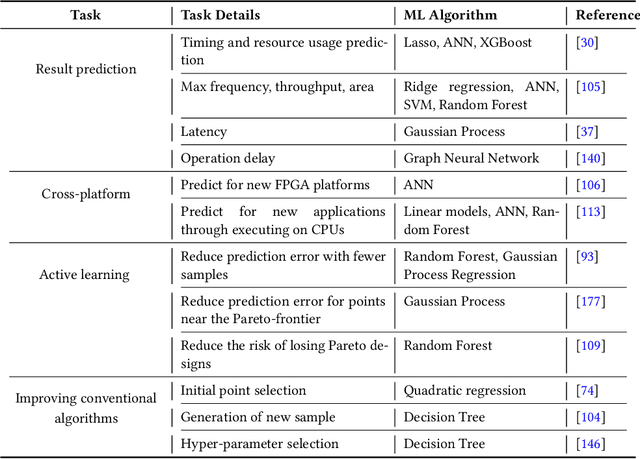
With the down-scaling of CMOS technology, the design complexity of very large-scale integrated (VLSI) is increasing. Although the application of machine learning (ML) techniques in electronic design automation (EDA) can trace its history back to the 90s, the recent breakthrough of ML and the increasing complexity of EDA tasks have aroused more interests in incorporating ML to solve EDA tasks. In this paper, we present a comprehensive review of existing ML for EDA studies, organized following the EDA hierarchy.
Multi-shot NAS for Discovering Adversarially Robust Convolutional Neural Architectures at Targeted Capacities
Jan 01, 2021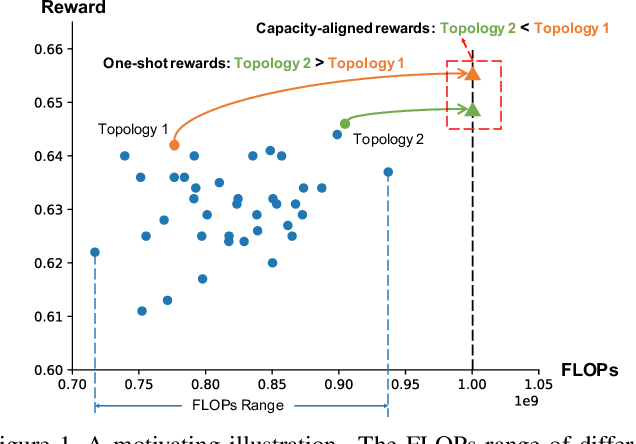
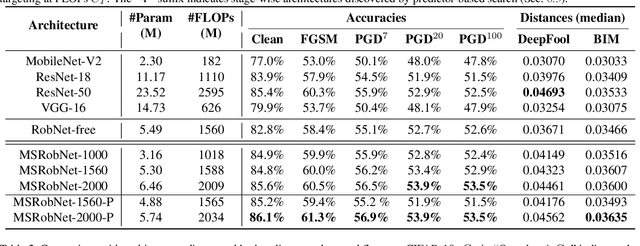

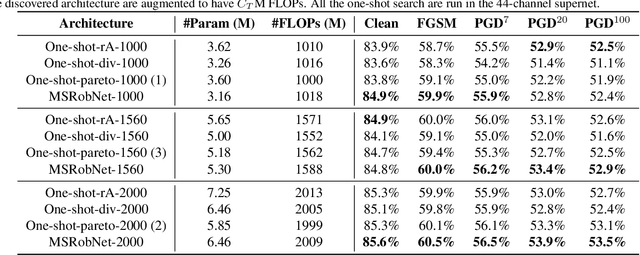
Convolutional neural networks (CNNs) are vulnerable to adversarial examples, and studies show that increasing the model capacity of an architecture topology (e.g., width expansion) can bring consistent robustness improvements. This reveals a clear robustness-efficiency trade-off that should be considered in architecture design. Recent studies have employed one-shot neural architecture search (NAS) to discover adversarially robust architectures. However, since the capacities of different topologies cannot be easily aligned during the search process, current one-shot NAS methods might favor topologies with larger capacity in the supernet. And the discovered topology might be sub-optimal when aligned to the targeted capacity. This paper proposes a novel multi-shot NAS method to explicitly search for adversarially robust architectures at a certain targeted capacity. Specifically, we estimate the reward at the targeted capacity using interior extra-polation of the rewards from multiple supernets. Experimental results demonstrate the effectiveness of the proposed method. For instance, at the targeted FLOPs of 1560M, the discovered MSRobNet-1560 (clean 84.8%, PGD100 52.9%) outperforms the recent NAS-discovered architecture RobNet-free (clean 82.8%, PGD100 52.6%) with similar FLOPs. Codes are available at https://github.com/walkerning/aw_nas.
BARS: Joint Search of Cell Topology and Layout for Accurate and Efficient Binary ARchitectures
Dec 21, 2020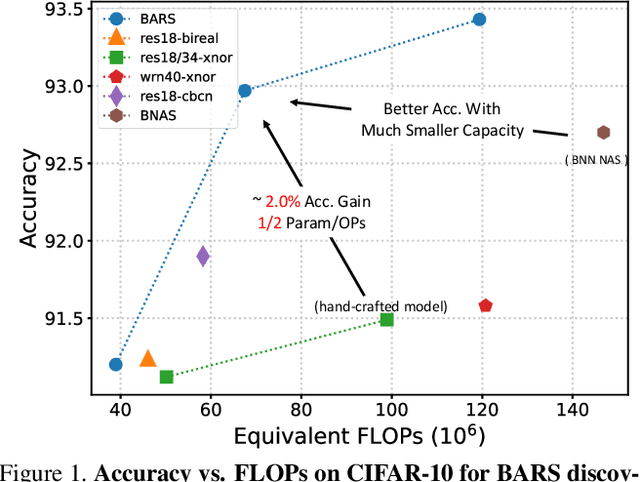

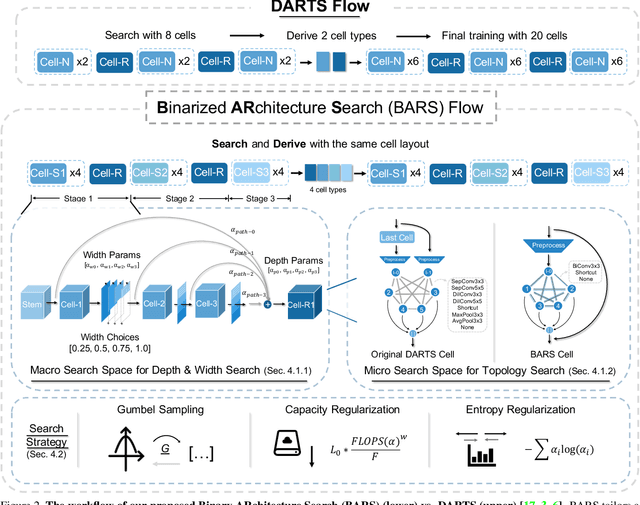
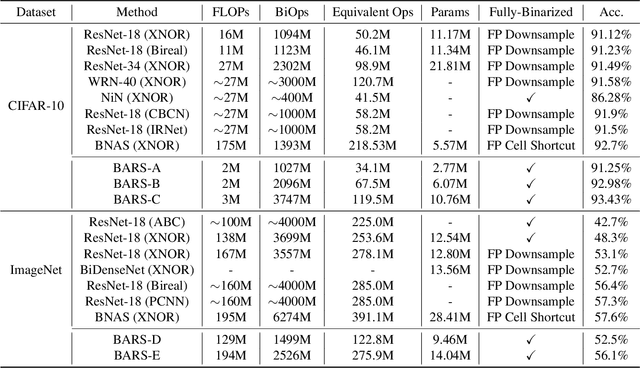
Binary Neural Networks (BNNs) have received significant attention due to their promising efficiency. Currently, most BNN studies directly adopt widely-used CNN architectures, which can be suboptimal for BNNs. This paper proposes a novel Binary ARchitecture Search (BARS) flow to discover superior binary architecture in a large design space. Specifically, we design a two-level (Macro & Micro) search space tailored for BNNs and apply a differentiable neural architecture search (NAS) to explore this search space efficiently. The macro-level search space includes depth and width decisions, which is required for better balancing the model performance and capacity. And we also make modifications to the micro-level search space to strengthen the information flow for BNN. A notable challenge of BNN architecture search lies in that binary operations exacerbate the "collapse" problem of differentiable NAS, and we incorporate various search and derive strategies to stabilize the search process. On CIFAR-10, BARS achieves 1.5% higher accuracy with 2/3 binary Ops and $1/10$ floating-point Ops. On ImageNet, with similar resource consumption, BARS-discovered architecture achieves 3% accuracy gain than hand-crafted architectures, while removing the full-precision downsample layer.
aw_nas: A Modularized and Extensible NAS framework
Nov 25, 2020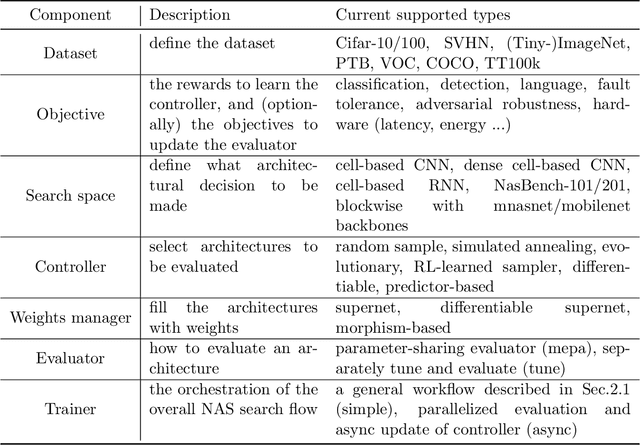
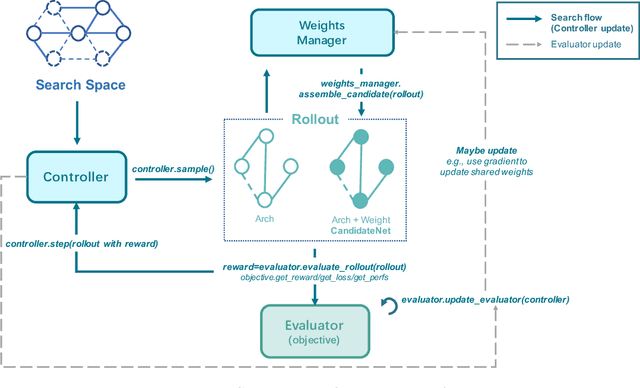

Neural Architecture Search (NAS) has received extensive attention due to its capability to discover neural network architectures in an automated manner. aw_nas is an open-source Python framework implementing various NAS algorithms in a modularized manner. Currently, aw_nas can be used to reproduce the results of mainstream NAS algorithms of various types. Also, due to the modularized design, one can simply experiment with different NAS algorithms for various applications with awnas (e.g., classification, detection, text modeling, fault tolerance, adversarial robustness, hardware efficiency, and etc.). Codes and documentation are available at https://github.com/walkerning/aw_nas.
Attentional Separation-and-Aggregation Network for Self-supervised Depth-Pose Learning in Dynamic Scenes
Nov 18, 2020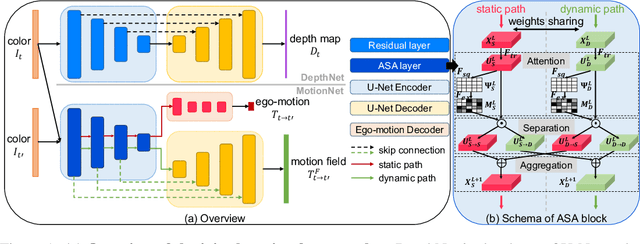
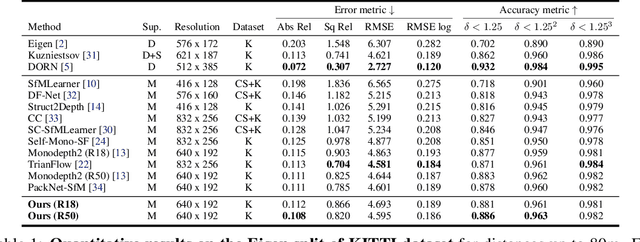


Learning depth and ego-motion from unlabeled videos via self-supervision from epipolar projection can improve the robustness and accuracy of the 3D perception and localization of vision-based robots. However, the rigid projection computed by ego-motion cannot represent all scene points, such as points on moving objects, leading to false guidance in these regions. To address this problem, we propose an Attentional Separation-and-Aggregation Network (ASANet), which can learn to distinguish and extract the scene's static and dynamic characteristics via the attention mechanism. We further propose a novel MotionNet with an ASANet as the encoder, followed by two separate decoders, to estimate the camera's ego-motion and the scene's dynamic motion field. Then, we introduce an auto-selecting approach to detect the moving objects for dynamic-aware learning automatically. Empirical experiments demonstrate that our method can achieve the state-of-the-art performance on the KITTI benchmark.