 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs MC Dropout Bayesian?
Oct 08, 2021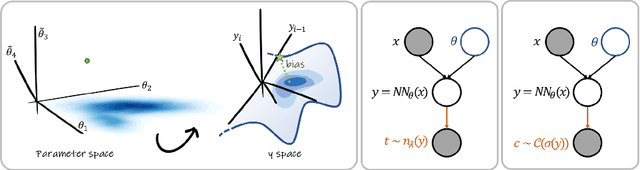

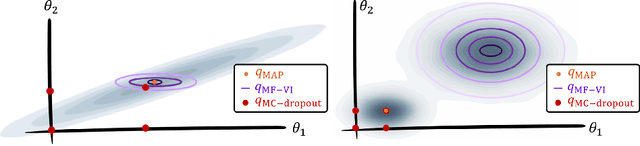

MC Dropout is a mainstream "free lunch" method in medical imaging for approximate Bayesian computations (ABC). Its appeal is to solve out-of-the-box the daunting task of ABC and uncertainty quantification in Neural Networks (NNs); to fall within the variational inference (VI) framework; and to propose a highly multimodal, faithful predictive posterior. We question the properties of MC Dropout for approximate inference, as in fact MC Dropout changes the Bayesian model; its predictive posterior assigns $0$ probability to the true model on closed-form benchmarks; the multimodality of its predictive posterior is not a property of the true predictive posterior but a design artefact. To address the need for VI on arbitrary models, we share a generic VI engine within the pytorch framework. The code includes a carefully designed implementation of structured (diagonal plus low-rank) multivariate normal variational families, and mixtures thereof. It is intended as a go-to no-free-lunch approach, addressing shortcomings of mean-field VI with an adjustable trade-off between expressivity and computational complexity.
Enhancing MR Image Segmentation with Realistic Adversarial Data Augmentation
Aug 07, 2021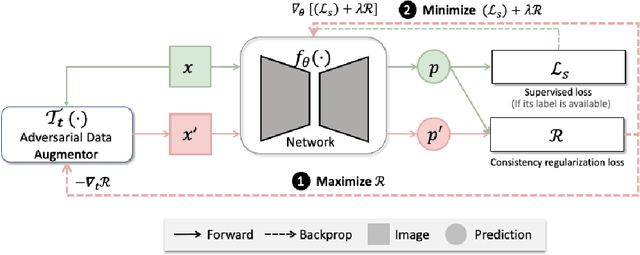

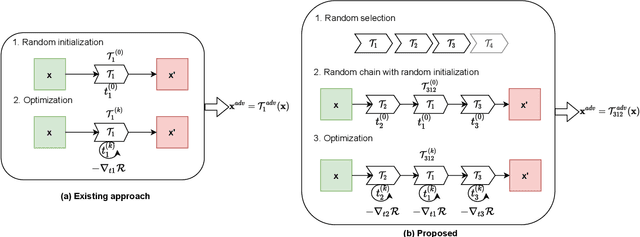
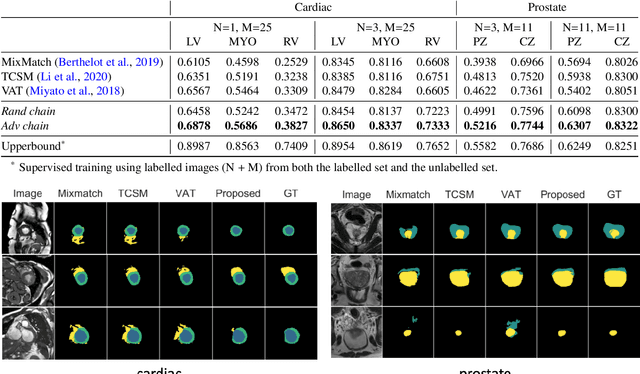
The success of neural networks on medical image segmentation tasks typically relies on large labeled datasets for model training. However, acquiring and manually labeling a large medical image set is resource-intensive, expensive, and sometimes impractical due to data sharing and privacy issues. To address this challenge, we propose an adversarial data augmentation approach to improve the efficiency in utilizing training data and to enlarge the dataset via simulated but realistic transformations. Specifically, we present a generic task-driven learning framework, which jointly optimizes a data augmentation model and a segmentation network during training, generating informative examples to enhance network generalizability for the downstream task. The data augmentation model utilizes a set of photometric and geometric image transformations and chains them to simulate realistic complex imaging variations that could exist in magnetic resonance (MR) imaging. The proposed adversarial data augmentation does not rely on generative networks and can be used as a plug-in module in general segmentation networks. It is computationally efficient and applicable for both supervised and semi-supervised learning. We analyze and evaluate the method on two MR image segmentation tasks: cardiac segmentation and prostate segmentation. Results show that the proposed approach can alleviate the need for labeled data while improving model generalization ability, indicating its practical value in medical imaging applications.
Learning a Model-Driven Variational Network for Deformable Image Registration
May 25, 2021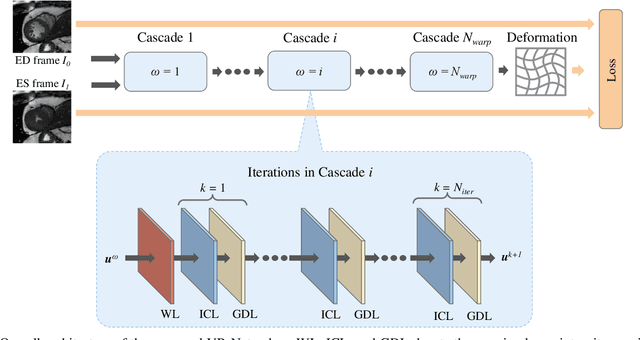
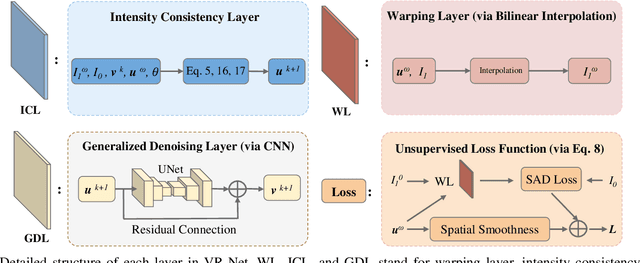
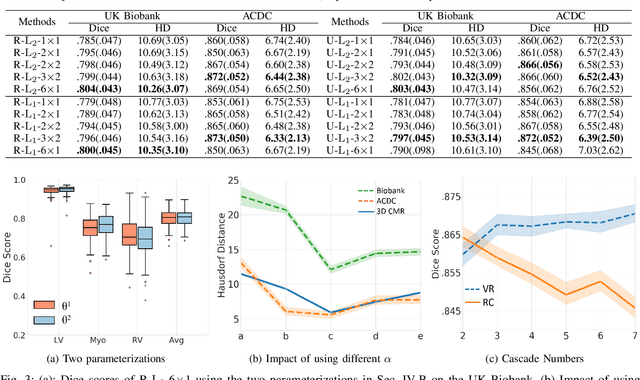
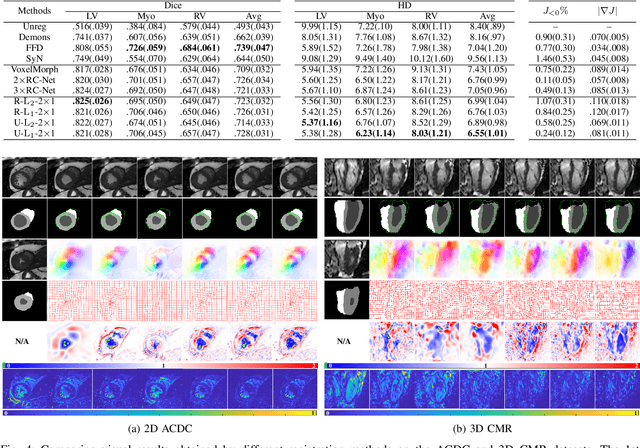
Data-driven deep learning approaches to image registration can be less accurate than conventional iterative approaches, especially when training data is limited. To address this whilst retaining the fast inference speed of deep learning, we propose VR-Net, a novel cascaded variational network for unsupervised deformable image registration. Using the variable splitting optimization scheme, we first convert the image registration problem, established in a generic variational framework, into two sub-problems, one with a point-wise, closed-form solution while the other one is a denoising problem. We then propose two neural layers (i.e. warping layer and intensity consistency layer) to model the analytical solution and a residual U-Net to formulate the denoising problem (i.e. generalized denoising layer). Finally, we cascade the warping layer, intensity consistency layer, and generalized denoising layer to form the VR-Net. Extensive experiments on three (two 2D and one 3D) cardiac magnetic resonance imaging datasets show that VR-Net outperforms state-of-the-art deep learning methods on registration accuracy, while maintains the fast inference speed of deep learning and the data-efficiency of variational model.
Detecting Outliers with Foreign Patch Interpolation
Nov 09, 2020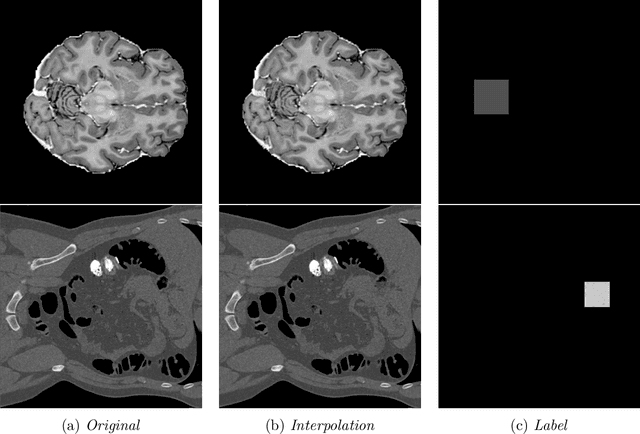
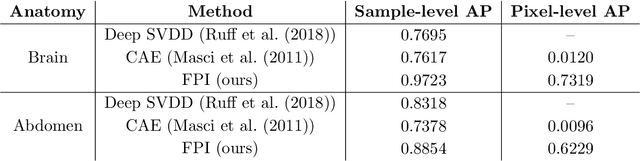
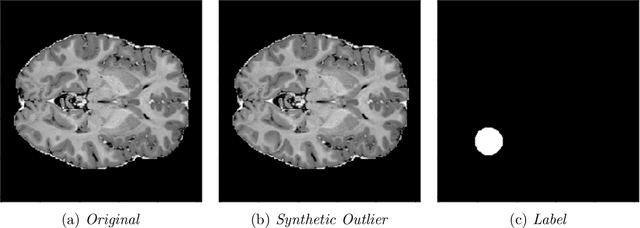
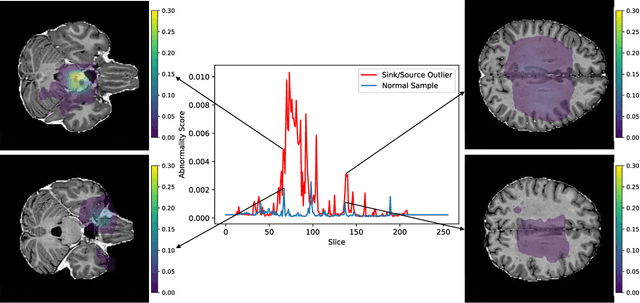
In medical imaging, outliers can contain hypo/hyper-intensities, minor deformations, or completely altered anatomy. To detect these irregularities it is helpful to learn the features present in both normal and abnormal images. However this is difficult because of the wide range of possible abnormalities and also the number of ways that normal anatomy can vary naturally. As such, we leverage the natural variations in normal anatomy to create a range of synthetic abnormalities. Specifically, the same patch region is extracted from two independent samples and replaced with an interpolation between both patches. The interpolation factor, patch size, and patch location are randomly sampled from uniform distributions. A wide residual encoder decoder is trained to give a pixel-wise prediction of the patch and its interpolation factor. This encourages the network to learn what features to expect normally and to identify where foreign patterns have been introduced. The estimate of the interpolation factor lends itself nicely to the derivation of an outlier score. Meanwhile the pixel-wise output allows for pixel- and subject- level predictions using the same model.
Self-Supervision with Superpixels: Training Few-shot Medical Image Segmentation without Annotation
Jul 20, 2020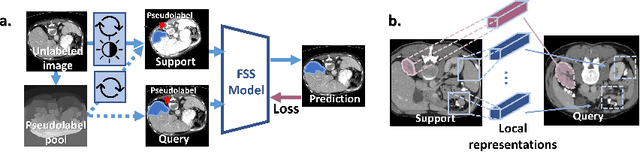
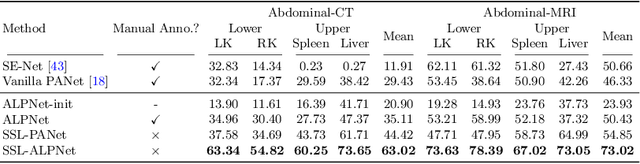
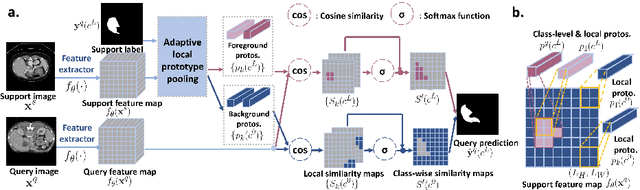
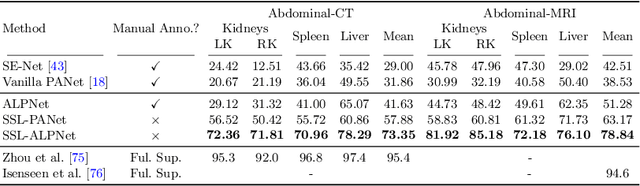
Few-shot semantic segmentation (FSS) has great potential for medical imaging applications. Most of the existing FSS techniques require abundant annotated semantic classes for training. However, these methods may not be applicable for medical images due to the lack of annotations. To address this problem we make several contributions: (1) A novel self-supervised FSS framework for medical images in order to eliminate the requirement for annotations during training. Additionally, superpixel-based pseudo-labels are generated to provide supervision; (2) An adaptive local prototype pooling module plugged into prototypical networks, to solve the common challenging foreground-background imbalance problem in medical image segmentation; (3) We demonstrate the general applicability of the proposed approach for medical images using three different tasks: abdominal organ segmentation for CT and MRI, as well as cardiac segmentation for MRI. Our results show that, for medical image segmentation, the proposed method outperforms conventional FSS methods which require manual annotations for training.
Biomechanics-informed Neural Networks for Myocardial Motion Tracking in MRI
Jul 04, 2020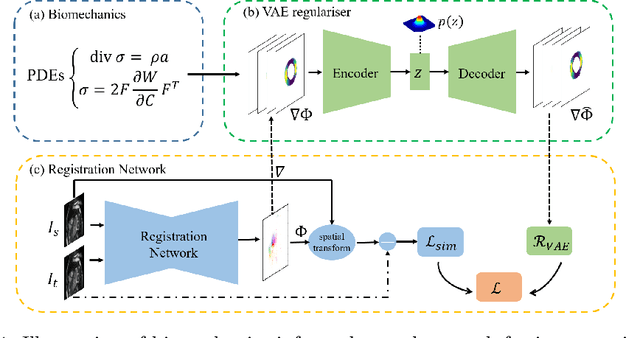
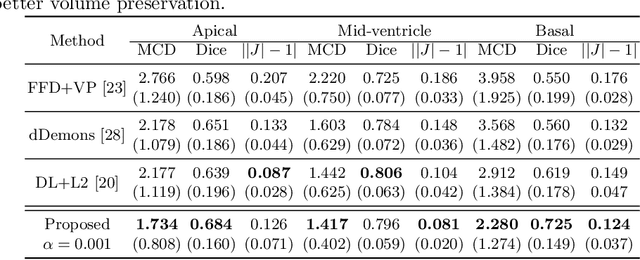
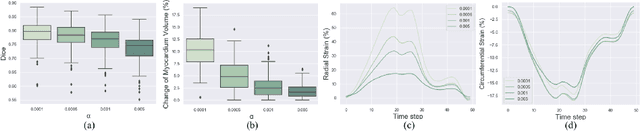
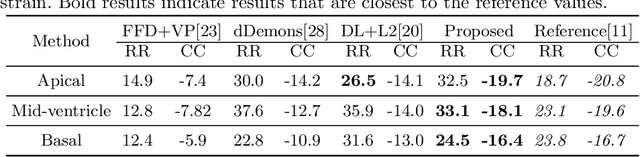
Image registration is an ill-posed inverse problem which often requires regularisation on the solution space. In contrast to most of the current approaches which impose explicit regularisation terms such as smoothness, in this paper we propose a novel method that can implicitly learn biomechanics-informed regularisation. Such an approach can incorporate application-specific prior knowledge into deep learning based registration. Particularly, the proposed biomechanics-informed regularisation leverages a variational autoencoder (VAE) to learn a manifold for biomechanically plausible deformations and to implicitly capture their underlying properties via reconstructing biomechanical simulations. The learnt VAE regulariser then can be coupled with any deep learning based registration network to regularise the solution space to be biomechanically plausible. The proposed method is validated in the context of myocardial motion tracking on 2D stacks of cardiac MRI data from two different datasets. The results show that it can achieve better performance against other competing methods in terms of motion tracking accuracy and has the ability to learn biomechanical properties such as incompressibility and strains. The method has also been shown to have better generalisability to unseen domains compared with commonly used L2 regularisation schemes.
Realistic Adversarial Data Augmentation for MR Image Segmentation
Jun 23, 2020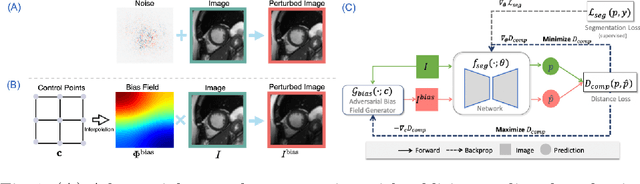
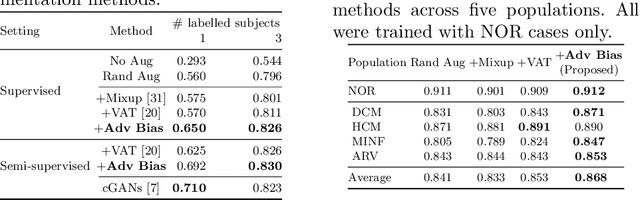
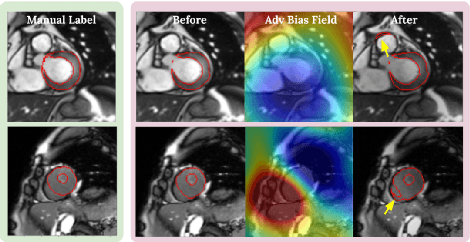
Neural network-based approaches can achieve high accuracy in various medical image segmentation tasks. However, they generally require large labelled datasets for supervised learning. Acquiring and manually labelling a large medical dataset is expensive and sometimes impractical due to data sharing and privacy issues. In this work, we propose an adversarial data augmentation method for training neural networks for medical image segmentation. Instead of generating pixel-wise adversarial attacks, our model generates plausible and realistic signal corruptions, which models the intensity inhomogeneities caused by a common type of artefacts in MR imaging: bias field. The proposed method does not rely on generative networks, and can be used as a plug-in module for general segmentation networks in both supervised and semi-supervised learning. Using cardiac MR imaging we show that such an approach can improve the generalization ability and robustness of models as well as provide significant improvements in low-data scenarios.
Deep learning for cardiac image segmentation: A review
Nov 09, 2019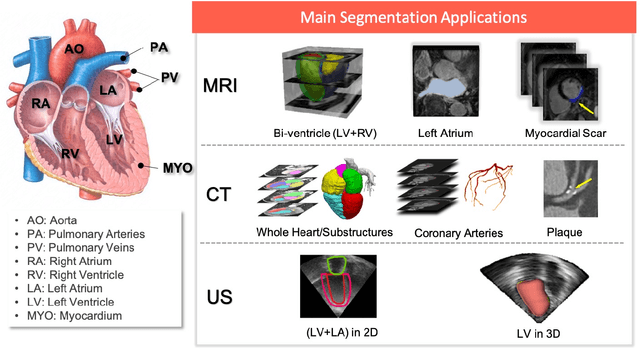
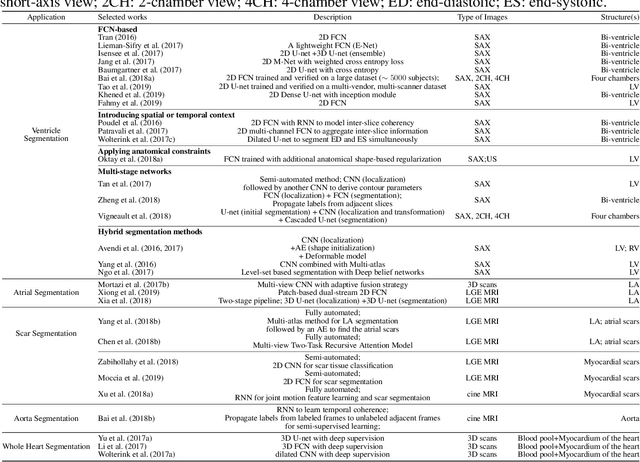
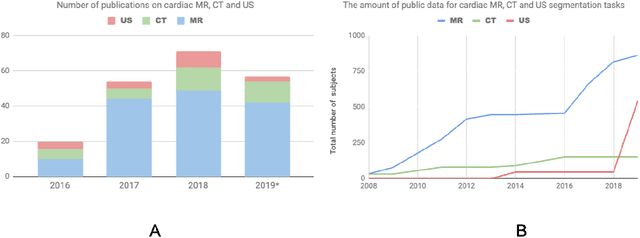

Deep learning has become the most widely used approach for cardiac image segmentation in recent years. In this paper, we provide a review of over 100 cardiac image segmentation papers using deep learning, which covers common imaging modalities including magnetic resonance imaging (MRI), computed tomography (CT), and ultrasound (US) and major anatomical structures of interest (ventricles, atria and vessels). In addition, a summary of publicly available cardiac image datasets and code repositories are included to provide a base for encouraging reproducible research. Finally, we discuss the challenges and limitations with current deep learning-based approaches (scarcity of labels, model generalizability across different domains, interpretability) and suggest potential directions for future research.
Unsupervised Multi-modal Style Transfer for Cardiac MR Segmentation
Aug 21, 2019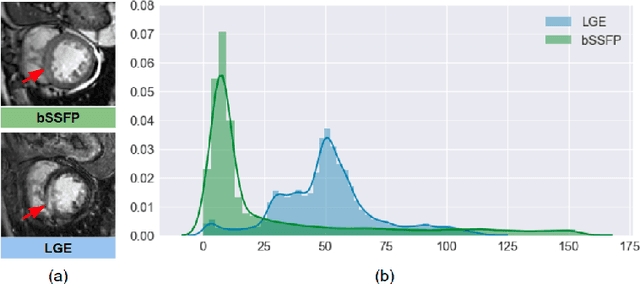
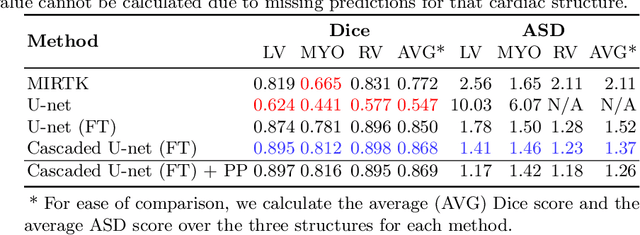
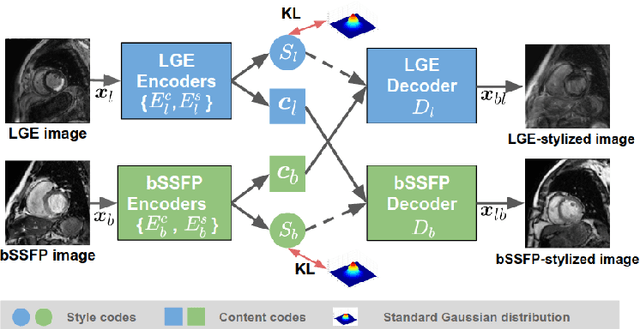
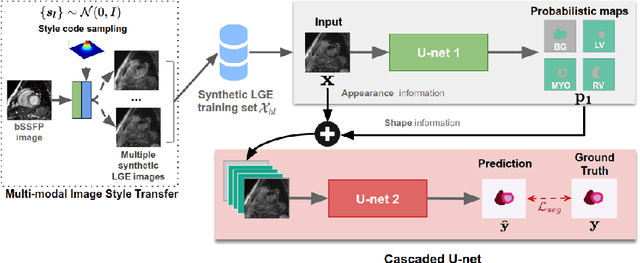
In this work, we present a fully automatic method to segment cardiac structures from late-gadolinium enhanced (LGE) images without using labelled LGE data for training, but instead by transferring the anatomical knowledge and features learned on annotated balanced steady-state free precession (bSSFP) images, which are easier to acquire. Our framework mainly consists of two neural networks: a multi-modal image translation network for style transfer and a cascaded segmentation network for image segmentation. The multi-modal image translation network generates realistic and diverse synthetic LGE images conditioned on a single annotated bSSFP image, forming a synthetic LGE training set. This set is then utilized to fine-tune the segmentation network pre-trained on labelled bSSFP images, achieving the goal of unsupervised LGE image segmentation. In particular, the proposed cascaded segmentation network is able to produce accurate segmentation by taking both shape prior and image appearance into account, achieving an average Dice score of 0.92 for the left ventricle, 0.83 for the myocardium, and 0.88 for the right ventricle on the test set.