 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Ad matching via Cluster-Adaptive Keyword Expansion and Relevance tuning
May 24, 2025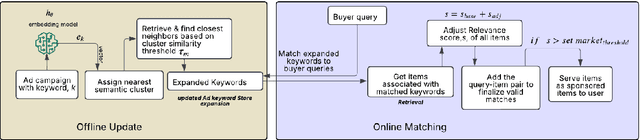

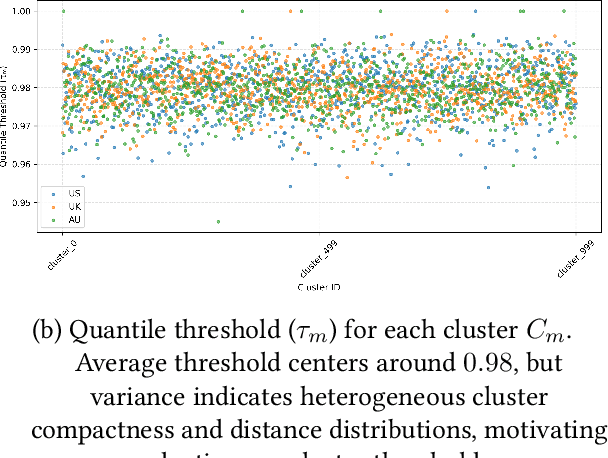
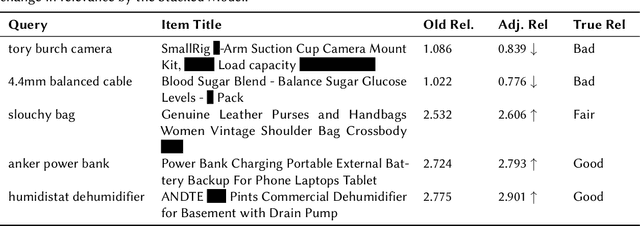
In search advertising, keyword matching connects user queries with relevant ads. While token-based matching increases ad coverage, it can reduce relevance due to overly permissive semantic expansion. This work extends keyword reach through document-side semantic keyword expansion, using a language model to broaden token-level matching without altering queries. We propose a solution using a pre-trained siamese model to generate dense vector representations of ad keywords and identify semantically related variants through nearest neighbor search. To maintain precision, we introduce a cluster-based thresholding mechanism that adjusts similarity cutoffs based on local semantic density. Each expanded keyword maps to a group of seller-listed items, which may only partially align with the original intent. To ensure relevance, we enhance the downstream relevance model by adapting it to the expanded keyword space using an incremental learning strategy with a lightweight decision tree ensemble. This system improves both relevance and click-through rate (CTR), offering a scalable, low-latency solution adaptable to evolving query behavior and advertising inventory.
Ranking Policy Learning via Marketplace Expected Value Estimation From Observational Data
Oct 06, 2024



We develop a decision making framework to cast the problem of learning a ranking policy for search or recommendation engines in a two-sided e-commerce marketplace as an expected reward optimization problem using observational data. As a value allocation mechanism, the ranking policy allocates retrieved items to the designated slots so as to maximize the user utility from the slotted items, at any given stage of the shopping journey. The objective of this allocation can in turn be defined with respect to the underlying probabilistic user browsing model as the expected number of interaction events on presented items matching the user intent, given the ranking context. Through recognizing the effect of ranking as an intervention action to inform users' interactions with slotted items and the corresponding economic value of the interaction events for the marketplace, we formulate the expected reward of the marketplace as the collective value from all presented ranking actions. The key element in this formulation is a notion of context value distribution, which signifies not only the attribution of value to ranking interventions within a session but also the distribution of marketplace reward across user sessions. We build empirical estimates for the expected reward of the marketplace from observational data that account for the heterogeneity of economic value across session contexts as well as the distribution shifts in learning from observational user activity data. The ranking policy can then be trained by optimizing the empirical expected reward estimates via standard Bayesian inference techniques. We report empirical results for a product search ranking task in a major e-commerce platform demonstrating the fundamental trade-offs governed by ranking polices trained on empirical reward estimates with respect to extreme choices of the context value distribution.
Conditional Sequential Slate Optimization
Aug 13, 2021
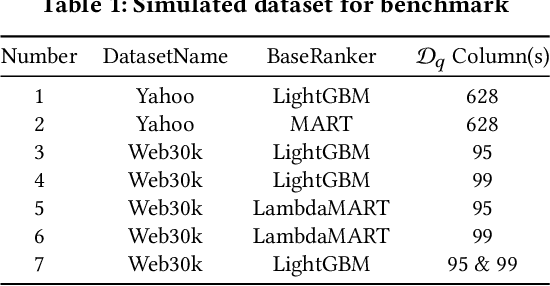
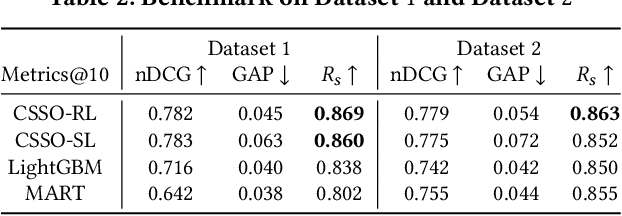
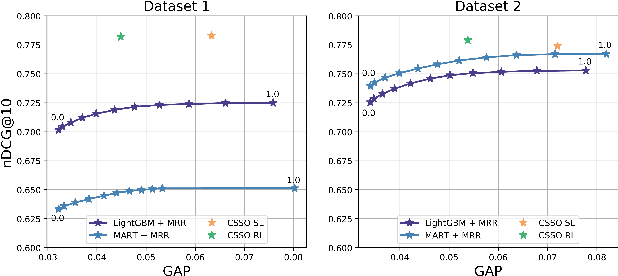
The top search results matching a user query that are displayed on the first page are critical to the effectiveness and perception of a search system. A search ranking system typically orders the results by independent query-document scores to produce a slate of search results. However, such unilateral scoring methods may fail to capture inter-document dependencies that users are sensitive to, thus producing a sub-optimal slate. Further, in practice, many real-world applications such as e-commerce search require enforcing certain distributional criteria at the slate-level, due to business objectives or long term user retention goals. Unilateral scoring of results does not explicitly support optimizing for such objectives with respect to a slate. Hence, solutions to the slate optimization problem must consider the optimal selection and order of the documents, along with adherence to slate-level distributional criteria. To that end, we propose a hybrid framework extended from traditional slate optimization to solve the conditional slate optimization problem. We introduce conditional sequential slate optimization (CSSO), which jointly learns to optimize for traditional ranking metrics as well as prescribed distribution criteria of documents within the slate. The proposed method can be applied to practical real world problems such as enforcing diversity in e-commerce search results, mitigating bias in top results and personalization of results. Experiments on public datasets and real-world data from e-commerce datasets show that CSSO outperforms popular comparable ranking methods in terms of adherence to distributional criteria while producing comparable or better relevance metrics.
Proceedings of the 2017 AdKDD & TargetAd Workshop
Jul 11, 2017Proceedings of the 2017 AdKDD and TargetAd Workshop held in conjunction with the 23rd ACM SIGKDD Conference on Knowledge Discovery and Data Mining Halifax, Nova Scotia, Canada.