 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Multi-modal Learning via Cross-modal Random Network Prediction
Jul 22, 2022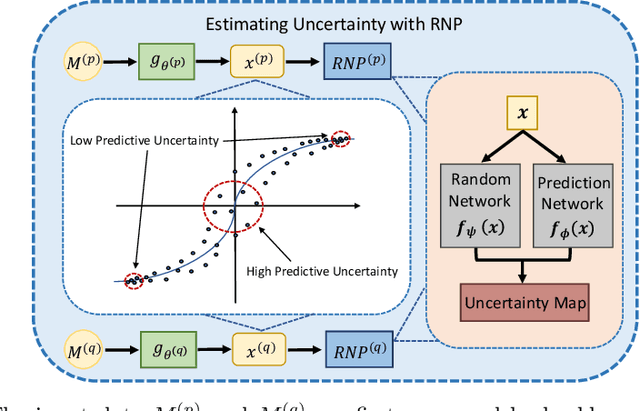
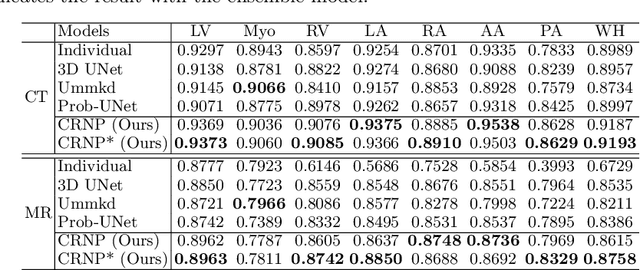
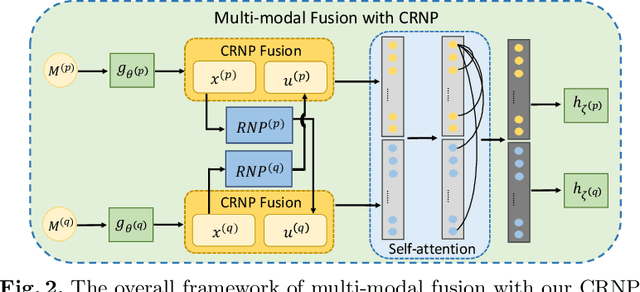
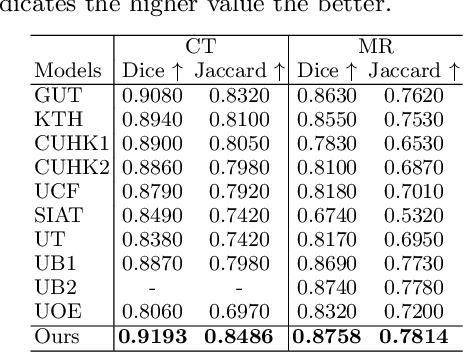
Multi-modal learning focuses on training models by equally combining multiple input data modalities during the prediction process. However, this equal combination can be detrimental to the prediction accuracy because different modalities are usually accompanied by varying levels of uncertainty. Using such uncertainty to combine modalities has been studied by a couple of approaches, but with limited success because these approaches are either designed to deal with specific classification or segmentation problems and cannot be easily translated into other tasks, or suffer from numerical instabilities. In this paper, we propose a new Uncertainty-aware Multi-modal Learner that estimates uncertainty by measuring feature density via Cross-modal Random Network Prediction (CRNP). CRNP is designed to require little adaptation to translate between different prediction tasks, while having a stable training process. From a technical point of view, CRNP is the first approach to explore random network prediction to estimate uncertainty and to combine multi-modal data. Experiments on two 3D multi-modal medical image segmentation tasks and three 2D multi-modal computer vision classification tasks show the effectiveness, adaptability and robustness of CRNP. Also, we provide an extensive discussion on different fusion functions and visualization to validate the proposed model.
Incorporating Linguistic Knowledge for Abstractive Multi-document Summarization
Sep 23, 2021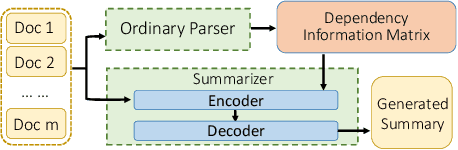
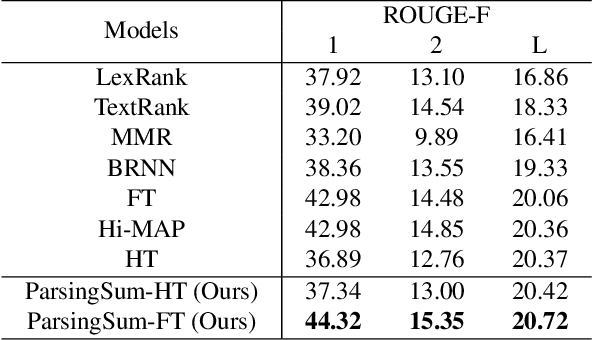
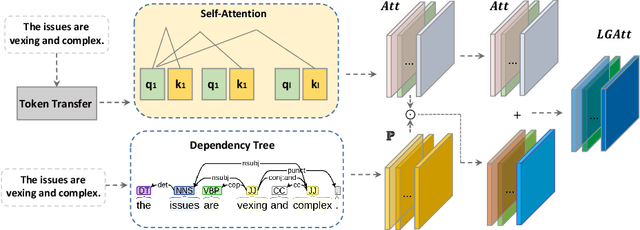
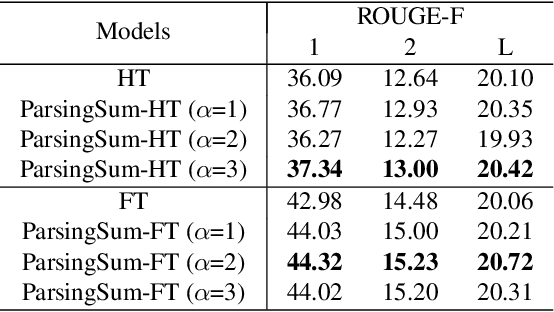
Within natural language processing tasks, linguistic knowledge can always serve an important role in assisting the model to learn excel representations and better guide the natural language generation. In this work, we develop a neural network based abstractive multi-document summarization (MDS) model which leverages dependency parsing to capture cross-positional dependencies and grammatical structures. More concretely, we process the dependency information into the linguistic-guided attention mechanism and further fuse it with the multi-head attention for better feature representation. With the help of linguistic signals, sentence-level relations can be correctly captured, thus improving MDS performance. Our model has two versions based on Flat-Transformer and Hierarchical Transformer respectively. Empirical studies on both versions demonstrate that this simple but effective method outperforms existing works on the benchmark dataset. Extensive analyses examine different settings and configurations of the proposed model which provide a good reference to the community.
Data Hiding with Deep Learning: A Survey Unifying Digital Watermarking and Steganography
Jul 20, 2021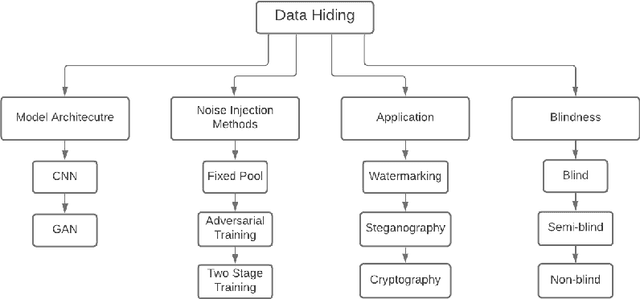
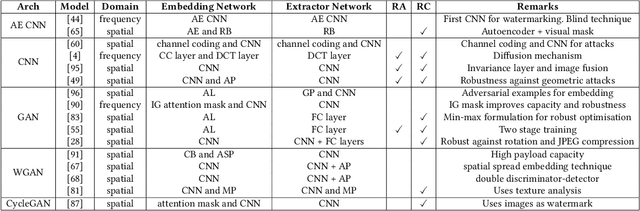
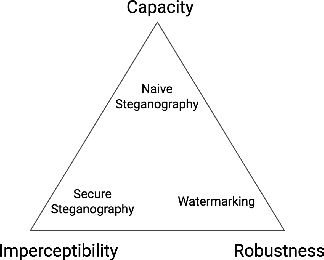
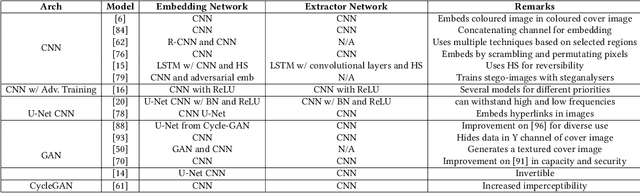
Data hiding is the process of embedding information into a noise-tolerant signal such as a piece of audio, video, or image. Digital watermarking is a form of data hiding where identifying data is robustly embedded so that it can resist tampering and be used to identify the original owners of the media. Steganography, another form of data hiding, embeds data for the purpose of secure and secret communication. This survey summarises recent developments in deep learning techniques for data hiding for the purposes of watermarking and steganography, categorising them based on model architectures and noise injection methods. The objective functions, evaluation metrics, and datasets used for training these data hiding models are comprehensively summarised. Finally, we propose and discuss possible future directions for research into deep data hiding techniques.
Fed-EINI: An Efficient and Interpretable Inference Framework for Decision Tree Ensembles in Federated Learning
May 20, 2021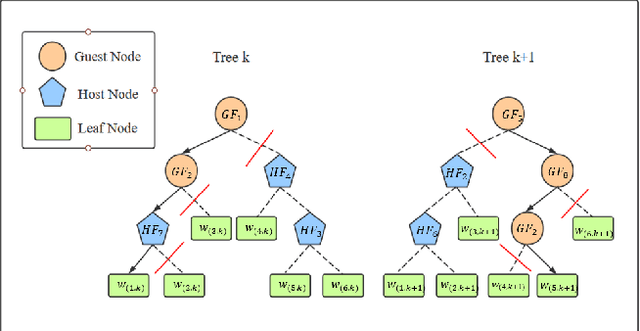
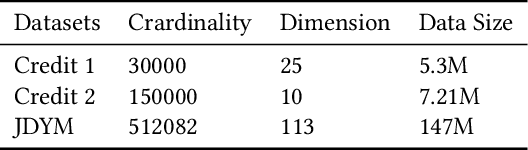
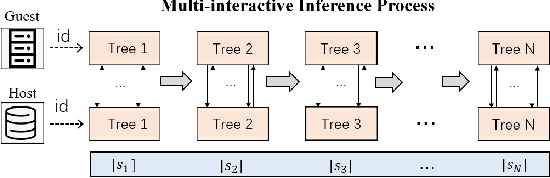
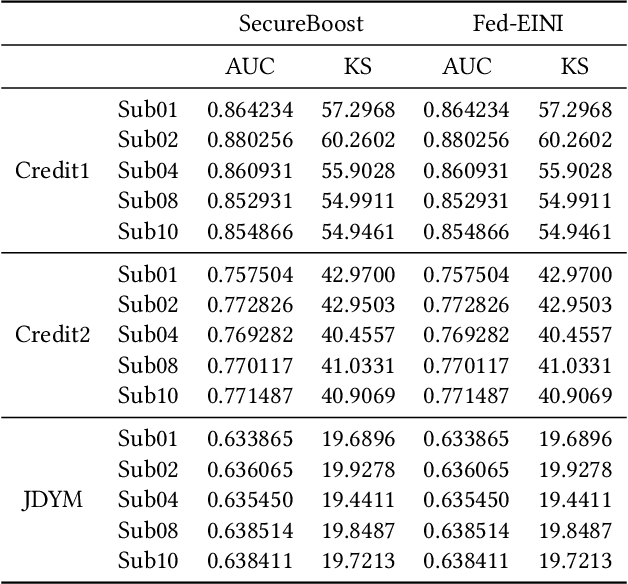
The increasing concerns about data privacy and security drives the emergence of a new field of studying privacy-preserving machine learning from isolated data sources, i.e., \textit{federated learning}. Vertical federated learning, where different parties hold different features for common users, has a great potential of driving a more variety of business cooperation among enterprises in different fields. Decision tree models especially decision tree ensembles are a class of widely applied powerful machine learning models with high interpretability and modeling efficiency. However, the interpretability are compromised in these works such as SecureBoost since the feature names are not exposed to avoid possible data breaches due to the unprotected decision path. In this paper, we shall propose Fed-EINI, an efficient and interpretable inference framework for federated decision tree models with only one round of multi-party communication. We shall compute the candidate sets of leaf nodes based on the local data at each party in parallel, followed by securely computing the weight of the only leaf node in the intersection of the candidate sets. We propose to protect the decision path by the efficient additively homomorphic encryption method, which allows the disclosure of feature names and thus makes the federated decision trees interpretable. The advantages of Fed-EINI will be demonstrated through theoretical analysis and extensive numerical results. Experiments show that the inference efficiency is improved by over $50\%$ in average.
Kernel Agnostic Real-world Image Super-resolution
Apr 19, 2021
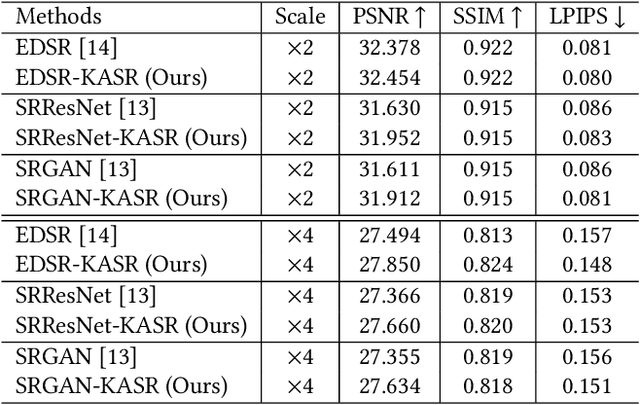
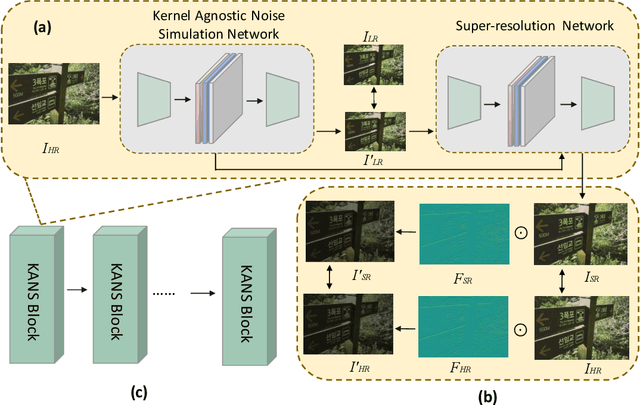
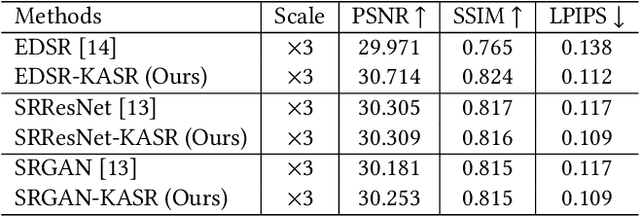
Recently, deep neural network models have achieved impressive results in various research fields. Come with it, an increasing number of attentions have been attracted by deep super-resolution (SR) approaches. Many existing methods attempt to restore high-resolution images from directly down-sampled low-resolution images or with the assumption of Gaussian degradation kernels with additive noises for their simplicities. However, in real-world scenarios, highly complex kernels and non-additive noises may be involved, even though the distorted images are visually similar to the clear ones. Existing SR models are facing difficulties to deal with real-world images under such circumstances. In this paper, we introduce a new kernel agnostic SR framework to deal with real-world image SR problem. The framework can be hanged seamlessly to multiple mainstream models. In the proposed framework, the degradation kernels and noises are adaptively modeled rather than explicitly specified. Moreover, we also propose an iterative supervision process and frequency-attended objective from orthogonal perspectives to further boost the performance. The experiments validate the effectiveness of the proposed framework on multiple real-world datasets.
Oriole: Thwarting Privacy against Trustworthy Deep Learning Models
Feb 23, 2021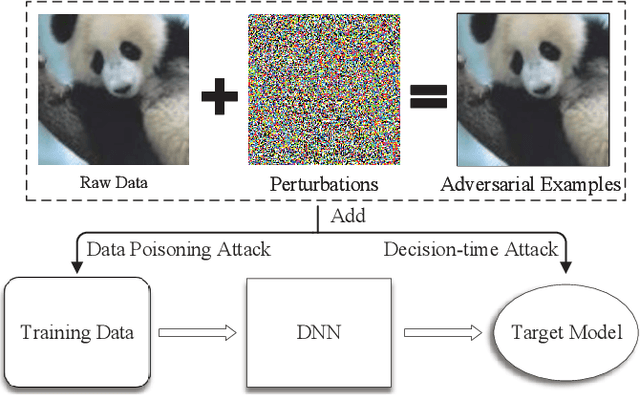
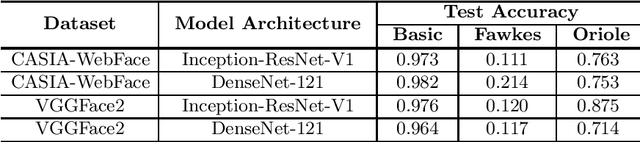
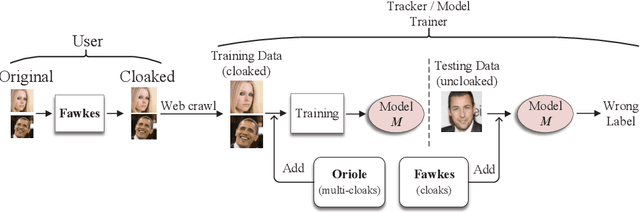
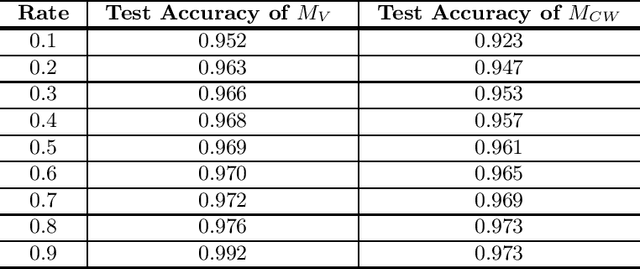
Deep Neural Networks have achieved unprecedented success in the field of face recognition such that any individual can crawl the data of others from the Internet without their explicit permission for the purpose of training high-precision face recognition models, creating a serious violation of privacy. Recently, a well-known system named Fawkes (published in USENIX Security 2020) claimed this privacy threat can be neutralized by uploading cloaked user images instead of their original images. In this paper, we present Oriole, a system that combines the advantages of data poisoning attacks and evasion attacks, to thwart the protection offered by Fawkes, by training the attacker face recognition model with multi-cloaked images generated by Oriole. Consequently, the face recognition accuracy of the attack model is maintained and the weaknesses of Fawkes are revealed. Experimental results show that our proposed Oriole system is able to effectively interfere with the performance of the Fawkes system to achieve promising attacking results. Our ablation study highlights multiple principal factors that affect the performance of the Oriole system, including the DSSIM perturbation budget, the ratio of leaked clean user images, and the numbers of multi-cloaks for each uncloaked image. We also identify and discuss at length the vulnerabilities of Fawkes. We hope that the new methodology presented in this paper will inform the security community of a need to design more robust privacy-preserving deep learning models.
Delayed Rewards Calibration via Reward Empirical Sufficiency
Feb 23, 2021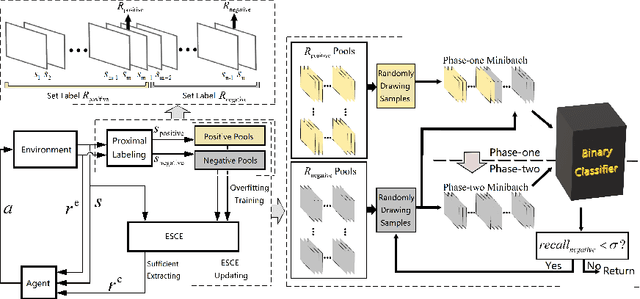
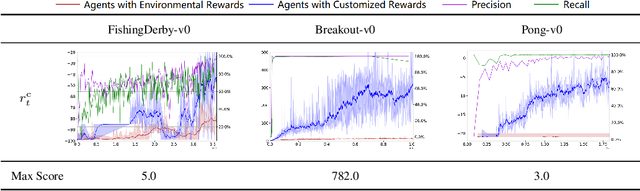
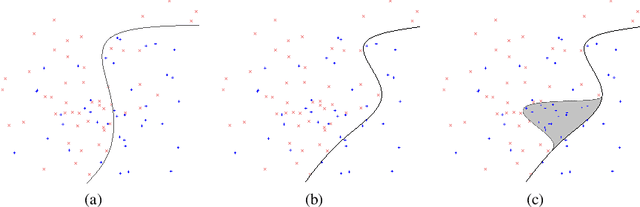
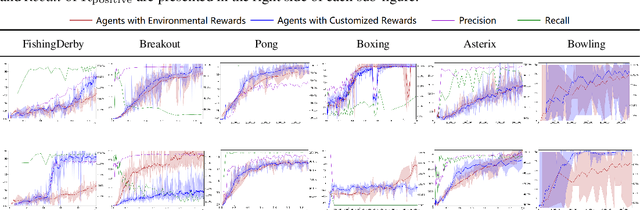
Appropriate credit assignment for delay rewards is a fundamental challenge for reinforcement learning. To tackle this problem, we introduce a delay reward calibration paradigm inspired from a classification perspective. We hypothesize that well-represented state vectors share similarities with each other since they contain the same or equivalent essential information. To this end, we define an empirical sufficient distribution, where the state vectors within the distribution will lead agents to environmental reward signals in the consequent steps. Therefore, a purify-trained classifier is designed to obtain the distribution and generate the calibrated rewards. We examine the correctness of sufficient state extraction by tracking the real-time extraction and building different reward functions in environments. The results demonstrate that the classifier could generate timely and accurate calibrated rewards. Moreover, the rewards are able to make the model training process more efficient. Finally, we identify and discuss that the sufficient states extracted by our model resonate with the observations of humans.
Multi-intersection Traffic Optimisation: A Benchmark Dataset and a Strong Baseline
Jan 24, 2021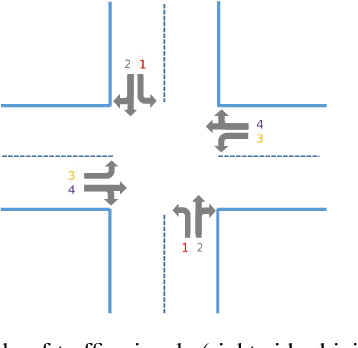
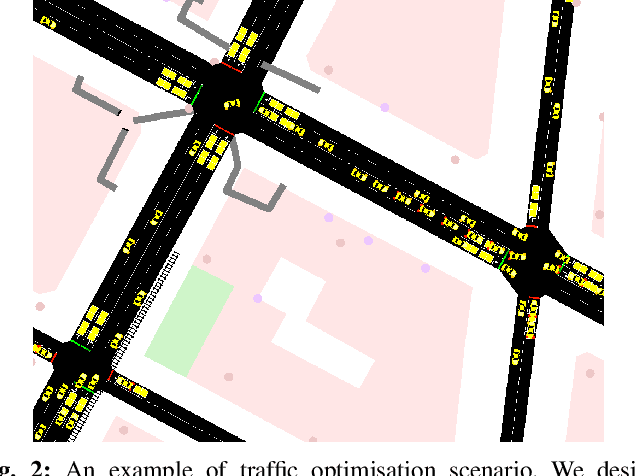
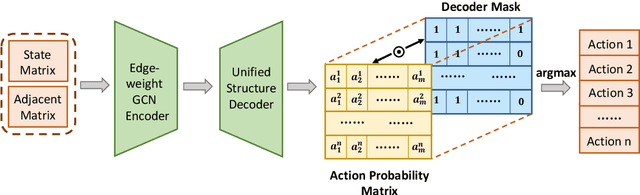
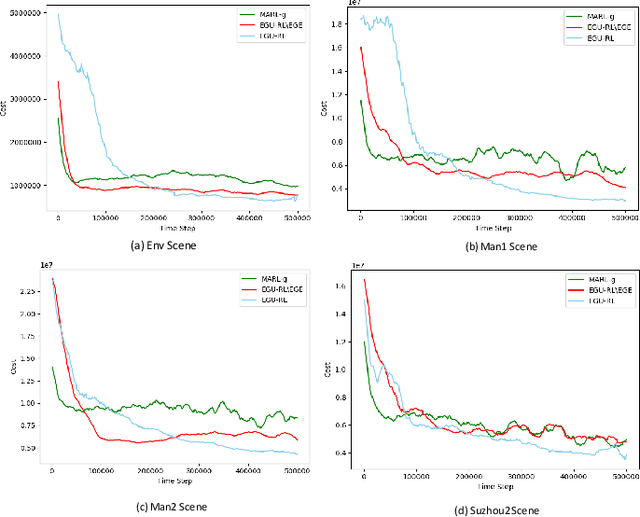
The control of traffic signals is fundamental and critical to alleviate traffic congestion in urban areas. However, it is challenging since traffic dynamics are complicated in real situations. Because of the high complexity of modelling the optimisation problem, experimental settings of current works are often inconsistent. Moreover, it is not trivial to control multiple intersections properly in real complex traffic scenarios due to its vast state and action space. Failing to take intersection topology relations into account also results in inferior traffic condition. To address these issues, in this work we carefully design our settings and propose new data including both synthetic and real traffic data in more complex scenarios. Additionally, we propose a novel and strong baseline model based on deep reinforcement learning with the encoder-decoder structure: an edge-weighted graph convolutional encoder to excavate multi-intersection relations; and a unified structure decoder to jointly model multiple junctions in a comprehensive manner, which significantly reduces the number of the model parameters. By doing so, the proposed model is able to effectively deal with multi-intersection traffic optimisation problems. Models have been trained and tested on both synthetic and real maps and traffic data with the Simulation of Urban Mobility (SUMO) simulator. Experimental results show that the proposed model surpasses existing methods in the literature.
Memory-Gated Recurrent Networks
Dec 30, 2020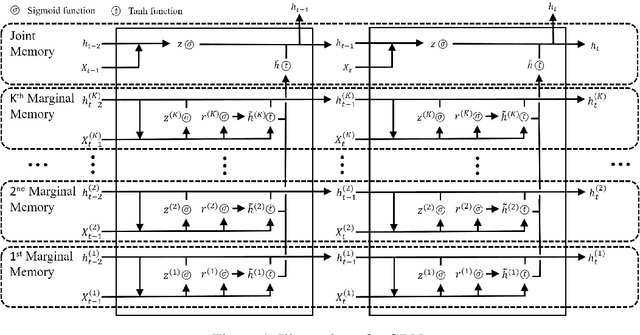
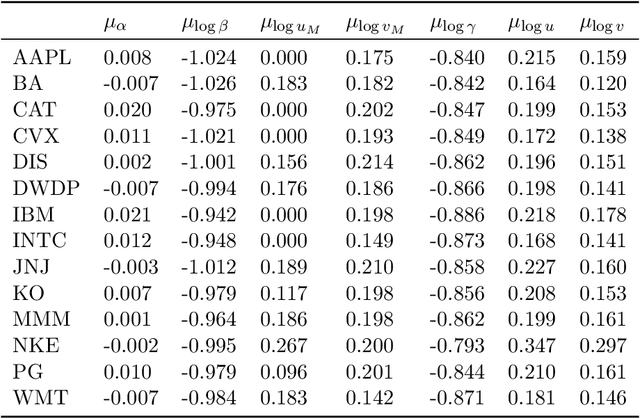
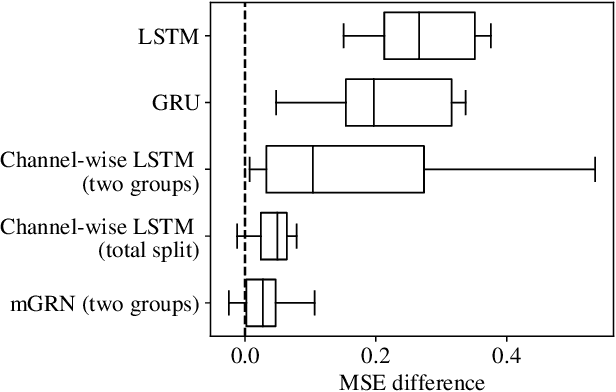
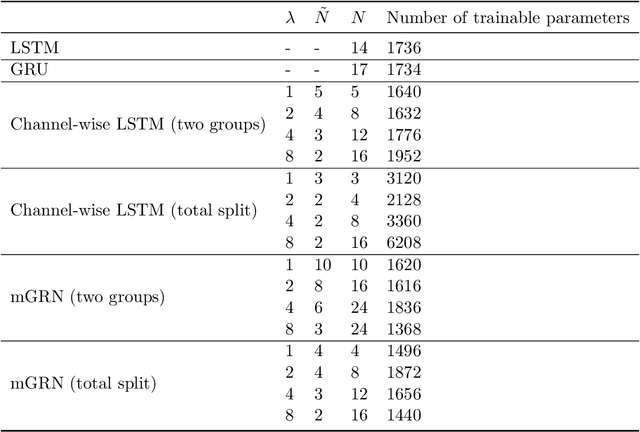
The essence of multivariate sequential learning is all about how to extract dependencies in data. These data sets, such as hourly medical records in intensive care units and multi-frequency phonetic time series, often time exhibit not only strong serial dependencies in the individual components (the "marginal" memory) but also non-negligible memories in the cross-sectional dependencies (the "joint" memory). Because of the multivariate complexity in the evolution of the joint distribution that underlies the data generating process, we take a data-driven approach and construct a novel recurrent network architecture, termed Memory-Gated Recurrent Networks (mGRN), with gates explicitly regulating two distinct types of memories: the marginal memory and the joint memory. Through a combination of comprehensive simulation studies and empirical experiments on a range of public datasets, we show that our proposed mGRN architecture consistently outperforms state-of-the-art architectures targeting multivariate time series.
Fully Quantized Image Super-Resolution Networks
Nov 29, 2020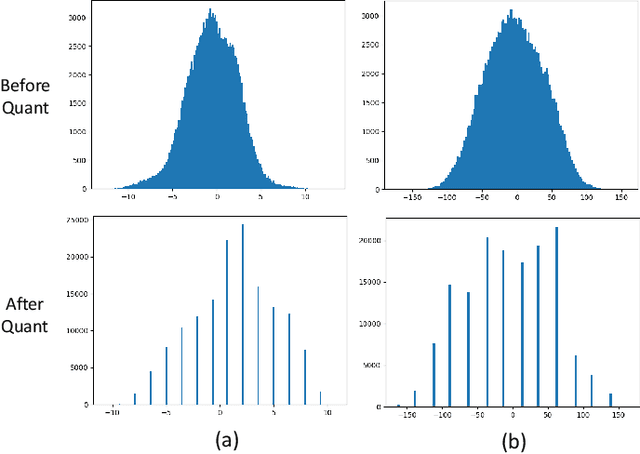
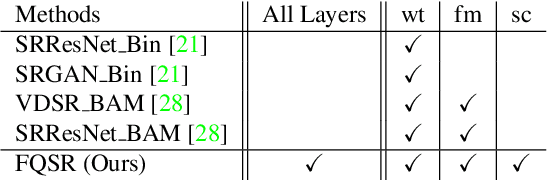
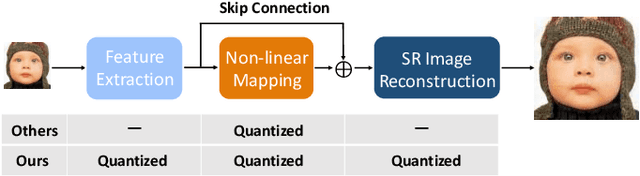
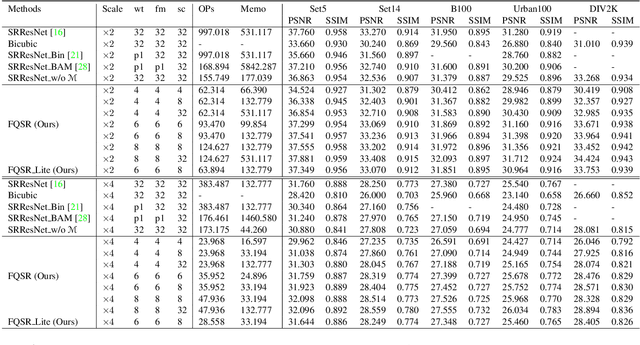
With the rising popularity of intelligent mobile devices, it is of great practical significance to develop accurate, realtime and energy-efficient image Super-Resolution (SR) inference methods. A prevailing method for improving the inference efficiency is model quantization, which allows for replacing the expensive floating-point operations with efficient fixed-point or bitwise arithmetic. To date, it is still challenging for quantized SR frameworks to deliver feasible accuracy-efficiency trade-off. Here, we propose a Fully Quantized image Super-Resolution framework (FQSR) to jointly optimize efficiency and accuracy. In particular, we target on obtaining end-to-end quantized models for all layers, especially including skip connections, which was rarely addressed in the literature. We further identify training obstacles faced by low-bit SR networks and propose two novel methods accordingly. The two difficulites are caused by 1) activation and weight distributions being vastly distinctive in different layers; 2) the inaccurate approximation of the quantization. We apply our quantization scheme on multiple mainstream super-resolution architectures, including SRResNet, SRGAN and EDSR. Experimental results show that our FQSR using low bits quantization can achieve on par performance compared with the full-precision counterparts on five benchmark datasets and surpass state-of-the-art quantized SR methods with significantly reduced computational cost and memory consumption.