 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere is the disease? Semi-supervised pseudo-normality synthesis from an abnormal image
Jun 24, 2021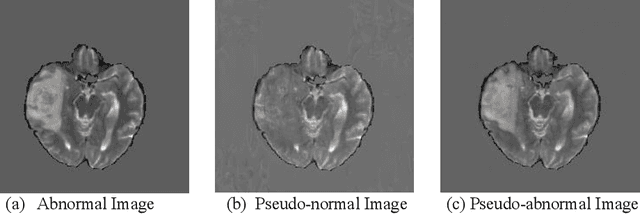

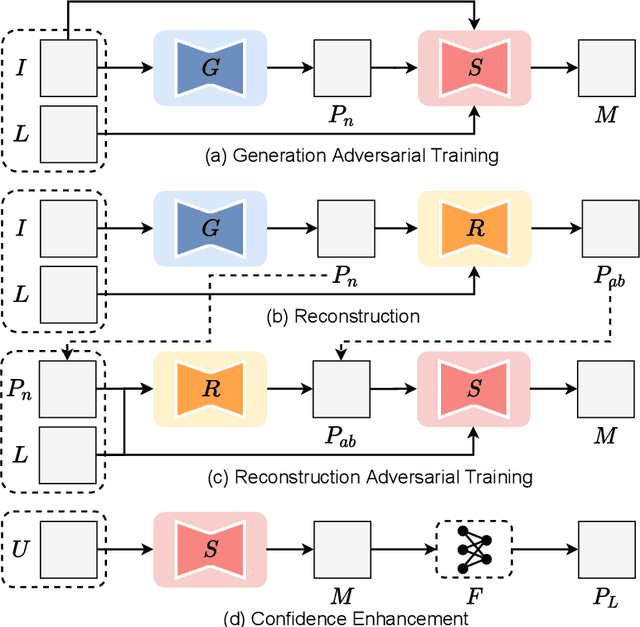
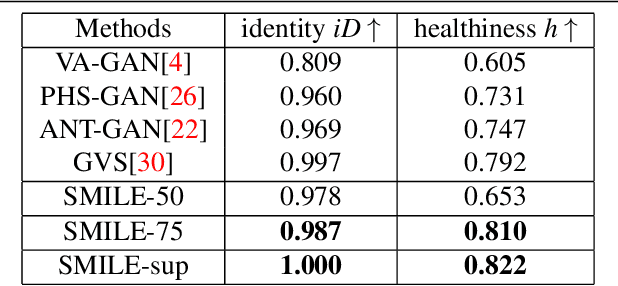
Pseudo-normality synthesis, which computationally generates a pseudo-normal image from an abnormal one (e.g., with lesions), is critical in many perspectives, from lesion detection, data augmentation to clinical surgery suggestion. However, it is challenging to generate high-quality pseudo-normal images in the absence of the lesion information. Thus, expensive lesion segmentation data have been introduced to provide lesion information for the generative models and improve the quality of the synthetic images. In this paper, we aim to alleviate the need of a large amount of lesion segmentation data when generating pseudo-normal images. We propose a Semi-supervised Medical Image generative LEarning network (SMILE) which not only utilizes limited medical images with segmentation masks, but also leverages massive medical images without segmentation masks to generate realistic pseudo-normal images. Extensive experiments show that our model outperforms the best state-of-the-art model by up to 6% for data augmentation task and 3% in generating high-quality images. Moreover, the proposed semi-supervised learning achieves comparable medical image synthesis quality with supervised learning model, using only 50 of segmentation data.
Conditional Training with Bounding Map for Universal Lesion Detection
Mar 23, 2021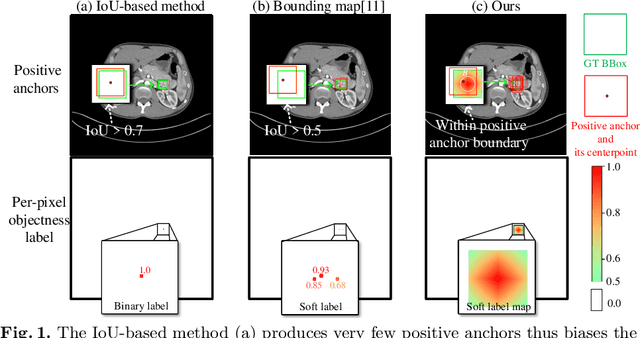
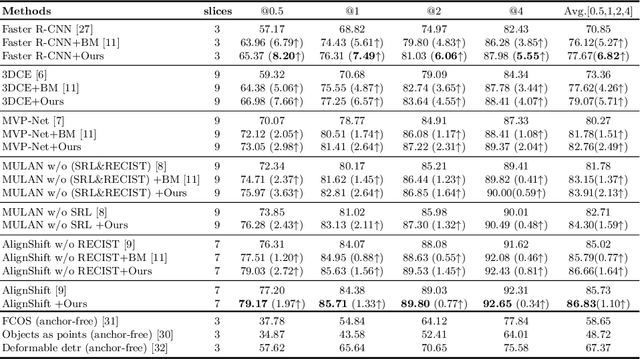
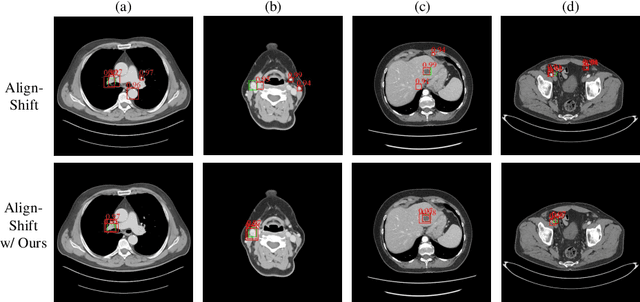
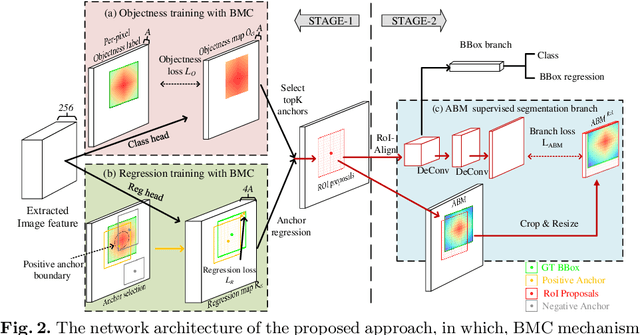
Universal Lesion Detection (ULD) in computed tomography plays an essential role in computer-aided diagnosis. Promising ULD results have been reported by coarse-to-fine two-stage detection approaches, but such two-stage ULD methods still suffer from issues like imbalance of positive v.s. negative anchors during object proposal and insufficient supervision problem during localization regression and classification of the region of interest (RoI) proposals. While leveraging pseudo segmentation masks such as bounding map (BM) can reduce the above issues to some degree, it is still an open problem to effectively handle the diverse lesion shapes and sizes in ULD. In this paper, we propose a BM-based conditional training for two-stage ULD, which can (i) reduce positive vs. negative anchor imbalance via BM-based conditioning (BMC) mechanism for anchor sampling instead of traditional IoU-based rule; and (ii) adaptively compute size-adaptive BM (ABM) from lesion bounding box, which is used for improving lesion localization accuracy via ABMsupervised segmentation. Experiments with four state-of-the-art methods show that the proposed approach can bring an almost free detection accuracy improvement without requiring expensive lesion mask annotations.
Deep Learning to Segment Pelvic Bones: Large-scale CT Datasets and Baseline Models
Dec 16, 2020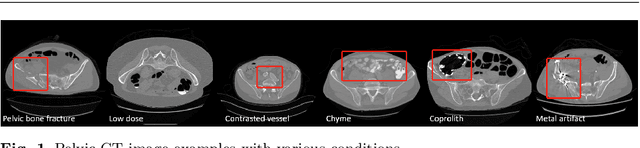
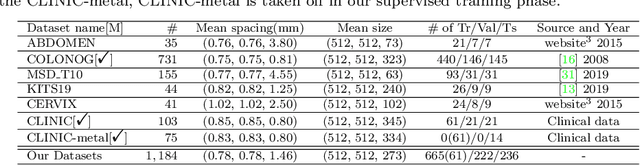
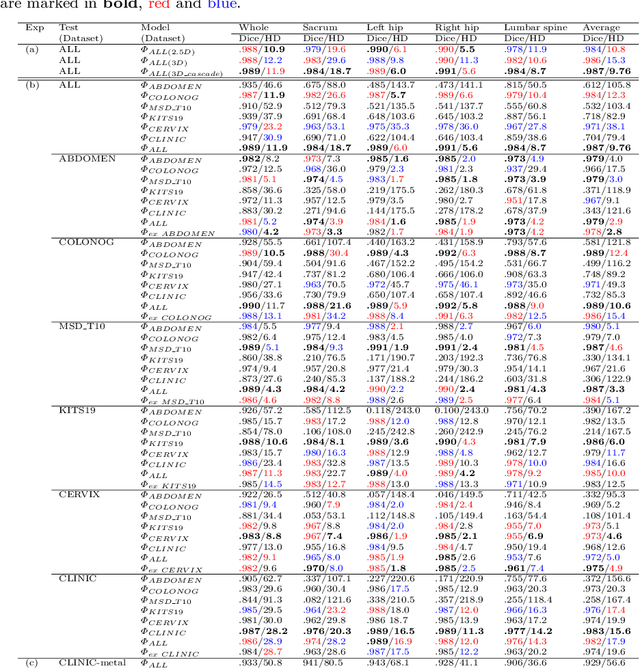
Purpose: Pelvic bone segmentation in CT has always been an essential step in clinical diagnosis and surgery planning of pelvic bone diseases. Existing methods for pelvic bone segmentation are either hand-crafted or semi-automatic and achieve limited accuracy when dealing with image appearance variations due to the multi-site domain shift, the presence of contrasted vessels, coprolith and chyme, bone fractures, low dose, metal artifacts, etc. Due to the lack of a large-scale pelvic CT dataset with annotations, deep learning methods are not fully explored. Methods: In this paper, we aim to bridge the data gap by curating a large pelvic CT dataset pooled from multiple sources and different manufacturers, including 1, 184 CT volumes and over 320, 000 slices with different resolutions and a variety of the above-mentioned appearance variations. Then we propose for the first time, to the best of our knowledge, to learn a deep multi-class network for segmenting lumbar spine, sacrum, left hip, and right hip, from multiple-domain images simultaneously to obtain more effective and robust feature representations. Finally, we introduce a post-processing tool based on the signed distance function (SDF) to eliminate false predictions while retaining correctly predicted bone fragments. Results: Extensive experiments on our dataset demonstrate the effectiveness of our automatic method, achieving an average Dice of 0.987 for a metal-free volume. SDF post-processor yields a decrease of 10.5% in hausdorff distance by maintaining important bone fragments in post-processing phase. Conclusion: We believe this large-scale dataset will promote the development of the whole community and plan to open source the images, annotations, codes, and trained baseline models at this URL1.
Bounding Maps for Universal Lesion Detection
Jul 18, 2020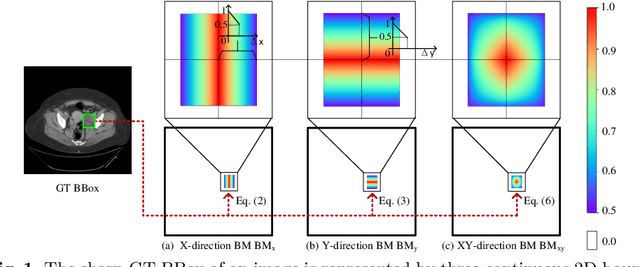
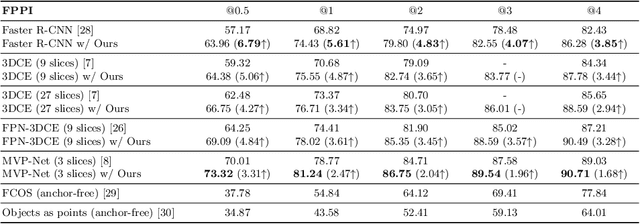
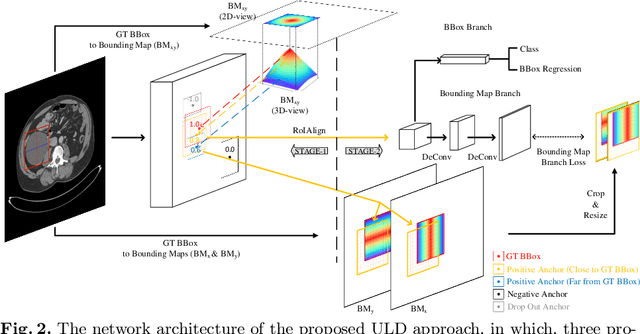

Universal Lesion Detection (ULD) in computed tomography plays an essential role in computer-aided diagnosis systems. Many detection approaches achieve excellent results for ULD using possible bounding boxes (or anchors) as proposals. However, empirical evidence shows that using anchor-based proposals leads to a high false-positive (FP) rate. In this paper, we propose a box-to-map method to represent a bounding box with three soft continuous maps with bounds in x-, y- and xy- directions. The bounding maps (BMs) are used in two-stage anchor-based ULD frameworks to reduce the FP rate. In the 1 st stage of the region proposal network, we replace the sharp binary ground-truth label of anchors with the corresponding xy-direction BM hence the positive anchors are now graded. In the 2 nd stage, we add a branch that takes our continuous BMs in x- and y- directions for extra supervision of detailed locations. Our method, when embedded into three state-of-the-art two-stage anchor-based detection methods, brings a free detection accuracy improvement (e.g., a 1.68% to 3.85% boost of sensitivity at 4 FPs) without extra inference time.
Video-based Remote Physiological Measurement via Cross-verified Feature Disentangling
Jul 16, 2020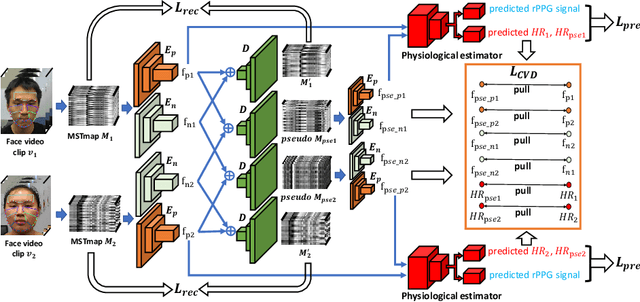
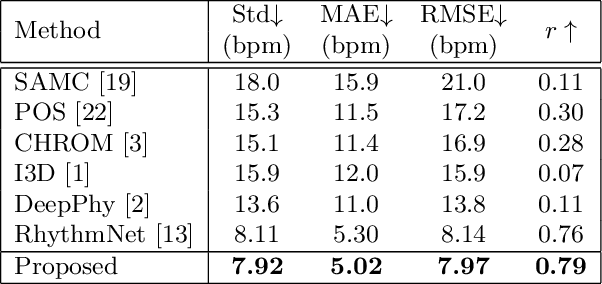
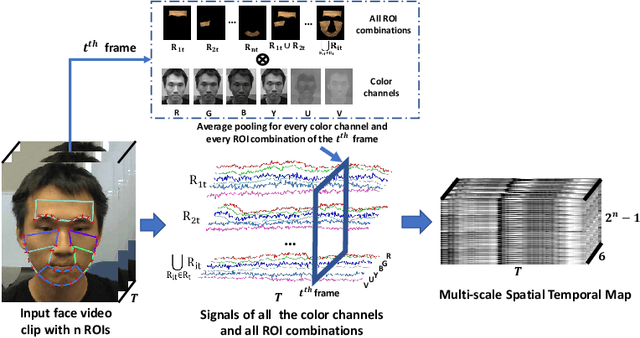
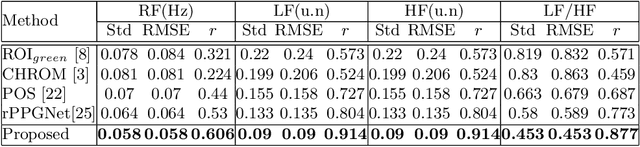
Remote physiological measurements, e.g., remote photoplethysmography (rPPG) based heart rate (HR), heart rate variability (HRV) and respiration frequency (RF) measuring, are playing more and more important roles under the application scenarios where contact measurement is inconvenient or impossible. Since the amplitude of the physiological signals is very small, they can be easily affected by head movements, lighting conditions, and sensor diversities. To address these challenges, we propose a cross-verified feature disentangling strategy to disentangle the physiological features with non-physiological representations, and then use the distilled physiological features for robust multi-task physiological measurements. We first transform the input face videos into a multi-scale spatial-temporal map (MSTmap), which can suppress the irrelevant background and noise features while retaining most of the temporal characteristics of the periodic physiological signals. Then we take pairwise MSTmaps as inputs to an autoencoder architecture with two encoders (one for physiological signals and the other for non-physiological information) and use a cross-verified scheme to obtain physiological features disentangled with the non-physiological features. The disentangled features are finally used for the joint prediction of multiple physiological signals like average HR values and rPPG signals. Comprehensive experiments on different large-scale public datasets of multiple physiological measurement tasks as well as the cross-database testing demonstrate the robustness of our approach.
Miss the Point: Targeted Adversarial Attack on Multiple Landmark Detection
Jul 10, 2020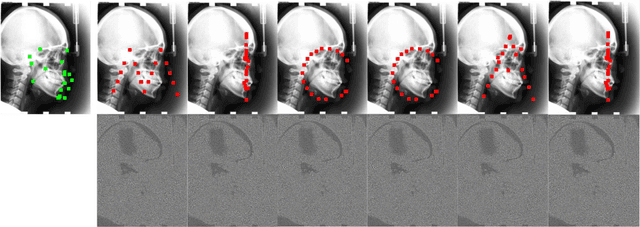
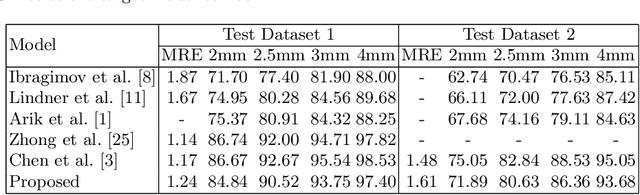
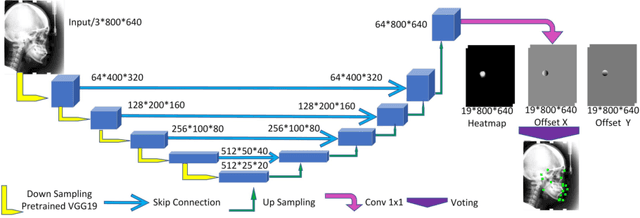
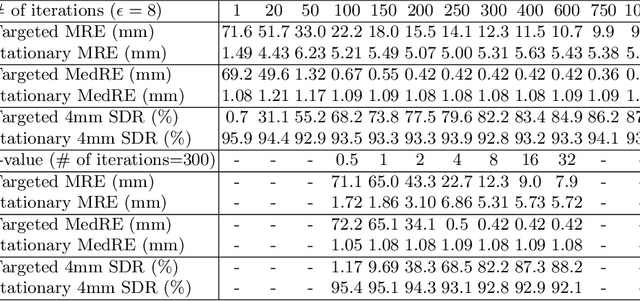
Recent methods in multiple landmark detection based on deep convolutional neural networks (CNNs) reach high accuracy and improve traditional clinical workflow. However, the vulnerability of CNNs to adversarial-example attacks can be easily exploited to break classification and segmentation tasks. This paper is the first to study how fragile a CNN-based model on multiple landmark detection to adversarial perturbations. Specifically, we propose a novel Adaptive Targeted Iterative FGSM (ATI-FGSM) attack against the state-of-the-art models in multiple landmark detection. The attacker can use ATI-FGSM to precisely control the model predictions of arbitrarily selected landmarks, while keeping other stationary landmarks still, by adding imperceptible perturbations to the original image. A comprehensive evaluation on a public dataset for cephalometric landmark detection demonstrates that the adversarial examples generated by ATI-FGSM break the CNN-based network more effectively and efficiently, compared with the original Iterative FGSM attack. Our work reveals serious threats to patients' health. Furthermore, we discuss the limitations of our method and provide potential defense directions, by investigating the coupling effect of nearby landmarks, i.e., a major source of divergence in our experiments. Our source code is available at https://github.com/qsyao/attack_landmark_detection.
Human Recognition Using Face in Computed Tomography
May 28, 2020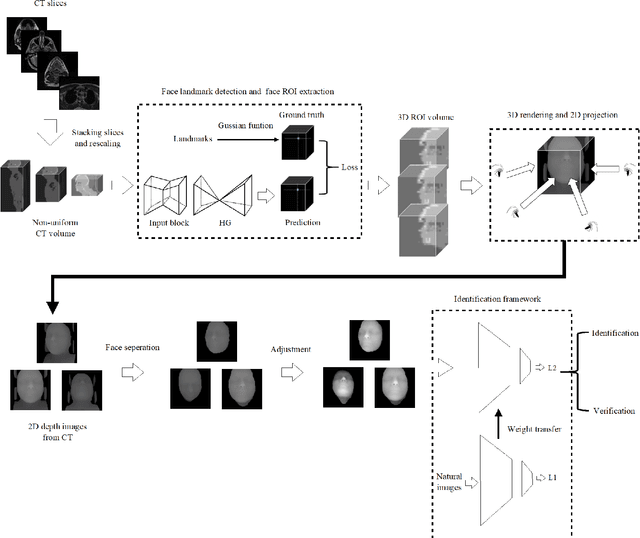
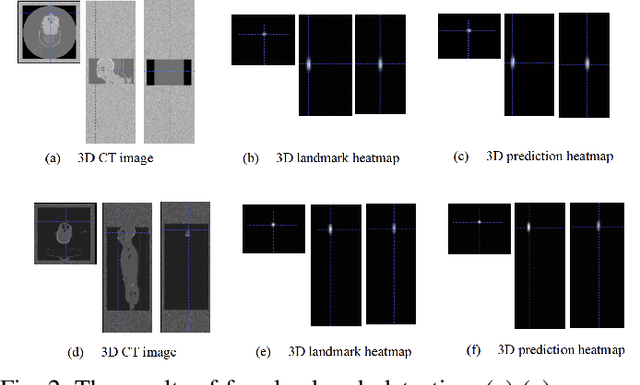
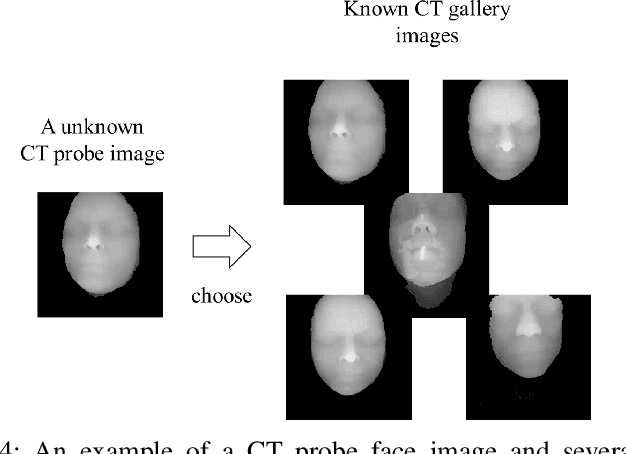
With the mushrooming use of computed tomography (CT) images in clinical decision making, management of CT data becomes increasingly difficult. From the patient identification perspective, using the standard DICOM tag to track patient information is challenged by issues such as misspelling, lost file, site variation, etc. In this paper, we explore the feasibility of leveraging the faces in 3D CT images as biometric features. Specifically, we propose an automatic processing pipeline that first detects facial landmarks in 3D for ROI extraction and then generates aligned 2D depth images, which are used for automatic recognition. To boost the recognition performance, we employ transfer learning to reduce the data sparsity issue and to introduce a group sampling strategy to increase inter-class discrimination when training the recognition network. Our proposed method is capable of capturing underlying identity characteristics in medical images while reducing memory consumption. To test its effectiveness, we curate 600 3D CT images of 280 patients from multiple sources for performance evaluation. Experimental results demonstrate that our method achieves a 1:56 identification accuracy of 92.53% and a 1:1 verification accuracy of 96.12%, outperforming other competing approaches.
Cross-domain Face Presentation Attack Detection via Multi-domain Disentangled Representation Learning
Apr 04, 2020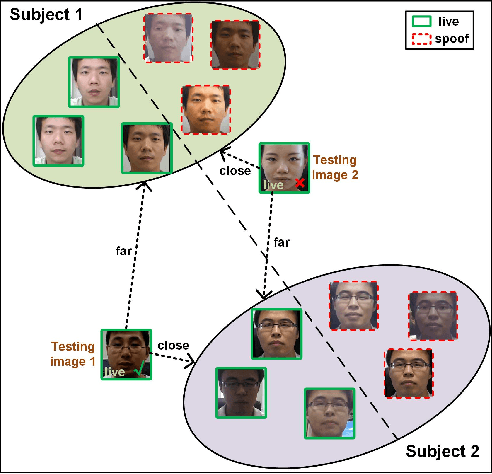
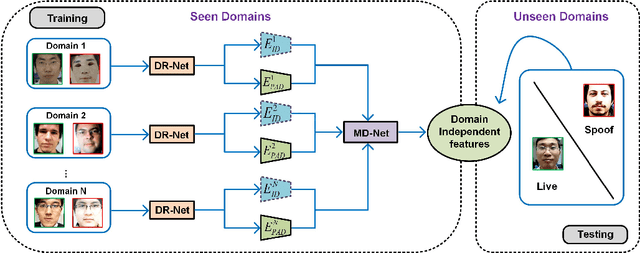
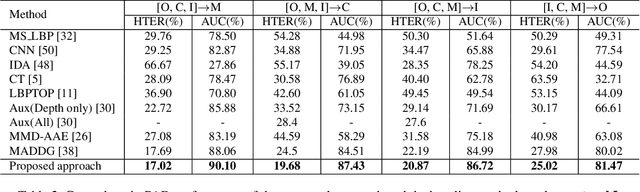
Face presentation attack detection (PAD) has been an urgent problem to be solved in the face recognition systems. Conventional approaches usually assume the testing and training are within the same domain; as a result, they may not generalize well into unseen scenarios because the representations learned for PAD may overfit to the subjects in the training set. In light of this, we propose an efficient disentangled representation learning for cross-domain face PAD. Our approach consists of disentangled representation learning (DR-Net) and multi-domain learning (MD-Net). DR-Net learns a pair of encoders via generative models that can disentangle PAD informative features from subject discriminative features. The disentangled features from different domains are fed to MD-Net which learns domain-independent features for the final cross-domain face PAD task. Extensive experiments on several public datasets validate the effectiveness of the proposed approach for cross-domain PAD.
The 1st Challenge on Remote Physiological Signal Sensing (RePSS)
Mar 26, 2020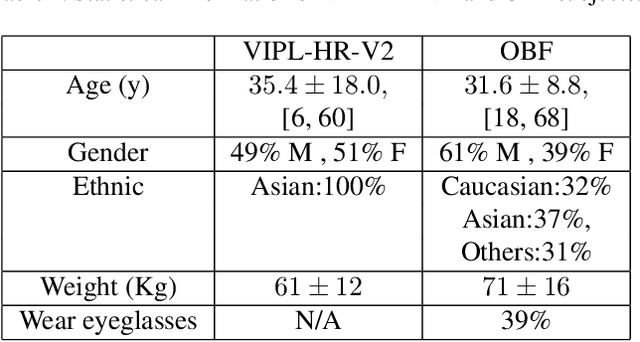

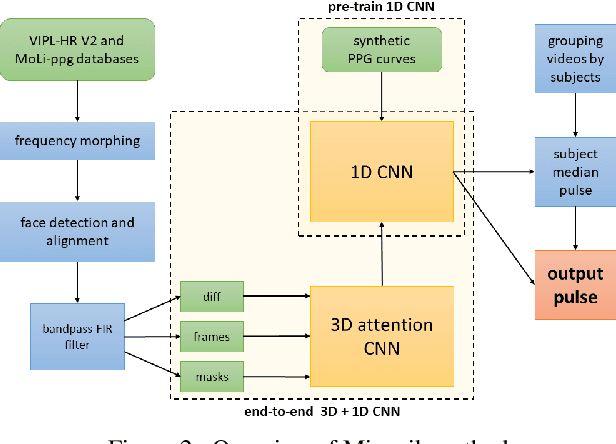
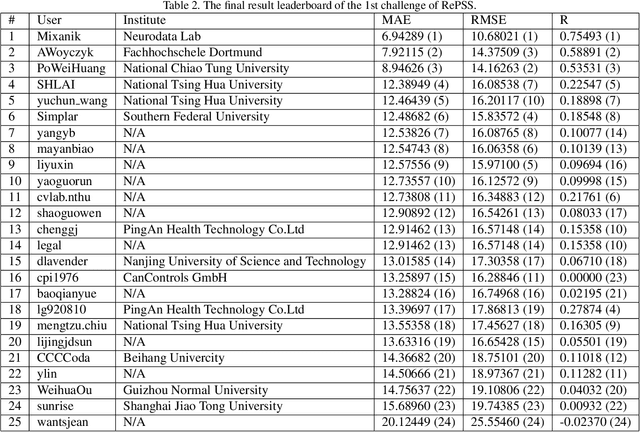
Remote measurement of physiological signals from videos is an emerging topic. The topic draws great interests, but the lack of publicly available benchmark databases and a fair validation platform are hindering its further development. For this concern, we organize the first challenge on Remote Physiological Signal Sensing (RePSS), in which two databases of VIPL and OBF are provided as the benchmark for kin researchers to evaluate their approaches. The 1st challenge of RePSS focuses on measuring the average heart rate from facial videos, which is the basic problem of remote physiological measurement. This paper presents an overview of the challenge, including data, protocol, analysis of results and discussion. The top ranked solutions are highlighted to provide insights for researchers, and future directions are outlined for this topic and this challenge.
FCSR-GAN: Joint Face Completion and Super-resolution via Multi-task Learning
Nov 04, 2019
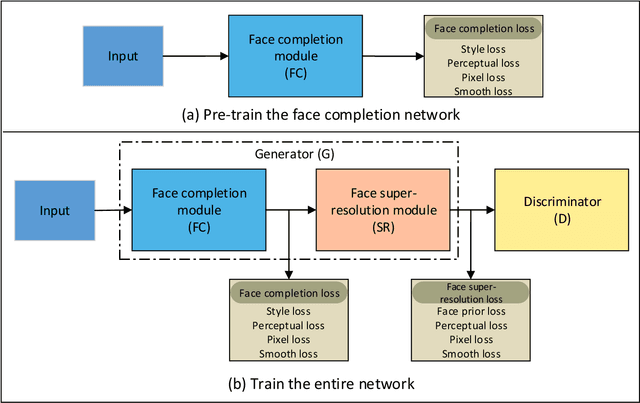
Combined variations containing low-resolution and occlusion often present in face images in the wild, e.g., under the scenario of video surveillance. While most of the existing face image recovery approaches can handle only one type of variation per model, in this work, we propose a deep generative adversarial network (FCSR-GAN) for performing joint face completion and face super-resolution via multi-task learning. The generator of FCSR-GAN aims to recover a high-resolution face image without occlusion given an input low-resolution face image with occlusion. The discriminator of FCSR-GAN uses a set of carefully designed losses (an adversarial loss, a perceptual loss, a pixel loss, a smooth loss, a style loss, and a face prior loss) to assure the high quality of the recovered high-resolution face images without occlusion. The whole network of FCSR-GAN can be trained end-to-end using our two-stage training strategy. Experimental results on the public-domain CelebA and Helen databases show that the proposed approach outperforms the state-of-the-art methods in jointly performing face super-resolution (up to 8 $\times$) and face completion, and shows good generalization ability in cross-database testing. Our FCSR-GAN is also useful for improving face identification performance when there are low-resolution and occlusion in face images.