 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Gradient Inversion Attacks Make Federated Learning Unsafe?
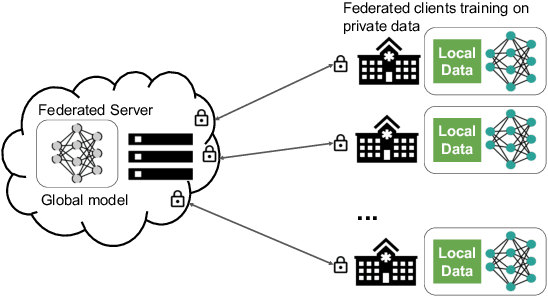
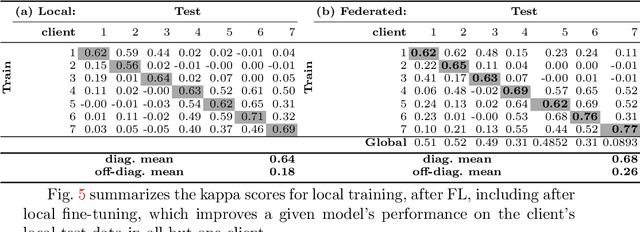
Feb 14, 2022Federated learning (FL) allows the collaborative training of AI models without needing to share raw data. This capability makes it especially interesting for healthcare applications where patient and data privacy is of utmost concern. However, recent works on the inversion of deep neural networks from model gradients raised concerns about the security of FL in preventing the leakage of training data. In this work, we show that these attacks presented in the literature are impractical in real FL use-cases and provide a new baseline attack that works for more realistic scenarios where the clients' training involves updating the Batch Normalization (BN) statistics. Furthermore, we present new ways to measure and visualize potential data leakage in FL. Our work is a step towards establishing reproducible methods of measuring data leakage in FL and could help determine the optimal tradeoffs between privacy-preserving techniques, such as differential privacy, and model accuracy based on quantifiable metrics.
T-AutoML: Automated Machine Learning for Lesion Segmentation using Transformers in 3D Medical Imaging
Nov 15, 2021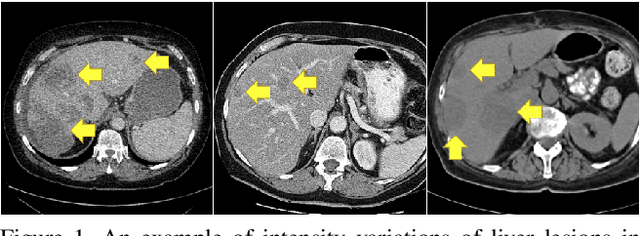
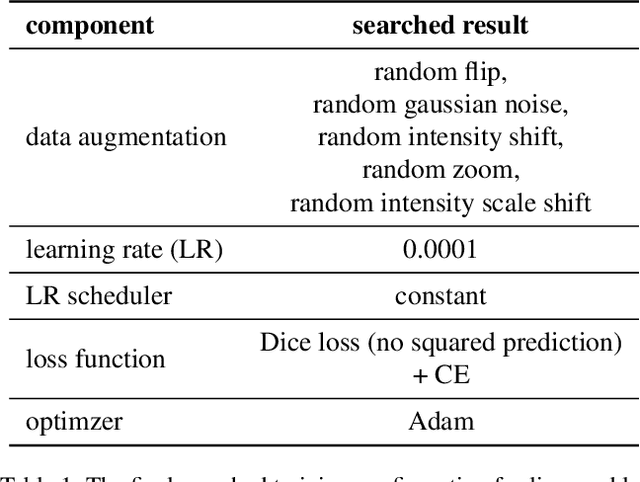
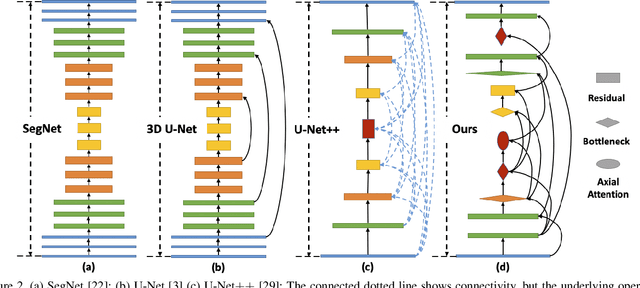
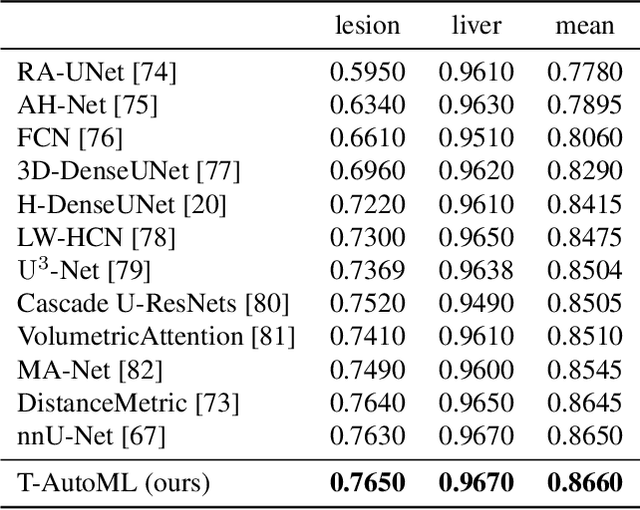
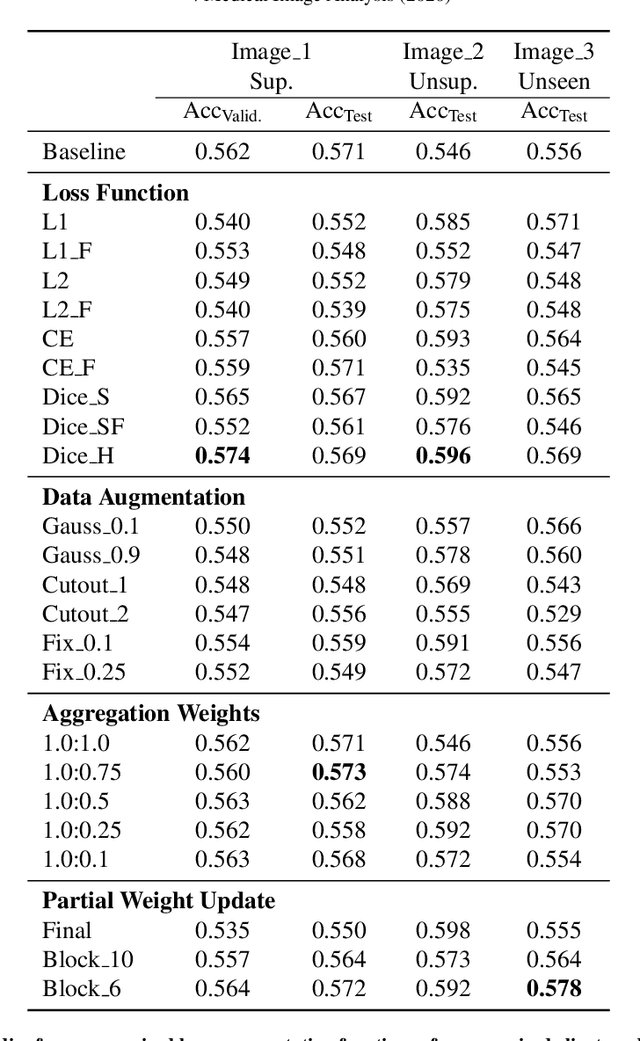
Lesion segmentation in medical imaging has been an important topic in clinical research. Researchers have proposed various detection and segmentation algorithms to address this task. Recently, deep learning-based approaches have significantly improved the performance over conventional methods. However, most state-of-the-art deep learning methods require the manual design of multiple network components and training strategies. In this paper, we propose a new automated machine learning algorithm, T-AutoML, which not only searches for the best neural architecture, but also finds the best combination of hyper-parameters and data augmentation strategies simultaneously. The proposed method utilizes the modern transformer model, which is introduced to adapt to the dynamic length of the search space embedding and can significantly improve the ability of the search. We validate T-AutoML on several large-scale public lesion segmentation data-sets and achieve state-of-the-art performance.
Multi-task Federated Learning for Heterogeneous Pancreas Segmentation
Aug 19, 2021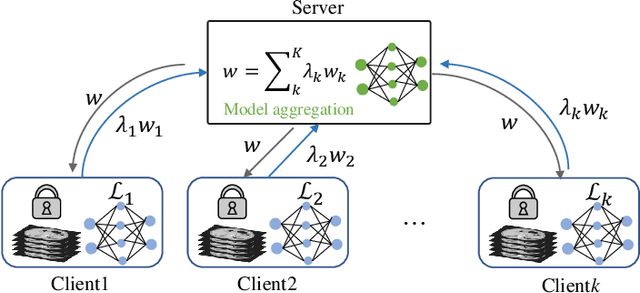
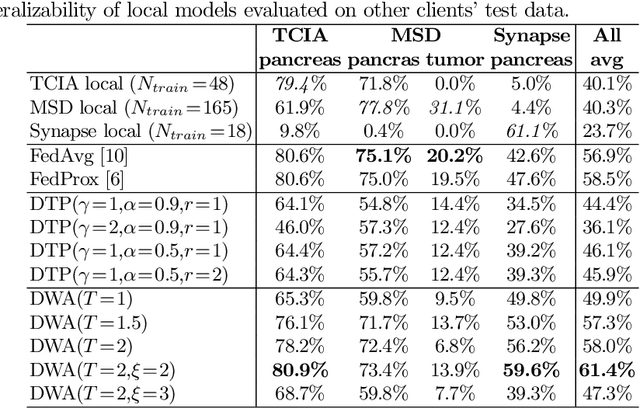
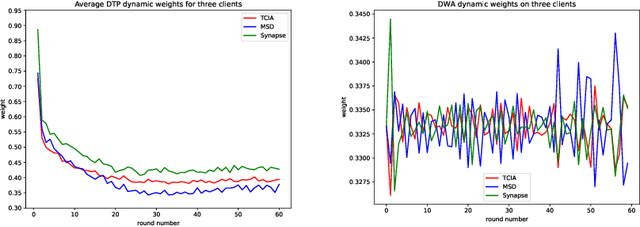

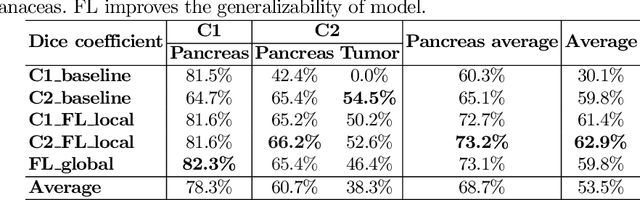
Federated learning (FL) for medical image segmentation becomes more challenging in multi-task settings where clients might have different categories of labels represented in their data. For example, one client might have patient data with "healthy'' pancreases only while datasets from other clients may contain cases with pancreatic tumors. The vanilla federated averaging algorithm makes it possible to obtain more generalizable deep learning-based segmentation models representing the training data from multiple institutions without centralizing datasets. However, it might be sub-optimal for the aforementioned multi-task scenarios. In this paper, we investigate heterogeneous optimization methods that show improvements for the automated segmentation of pancreas and pancreatic tumors in abdominal CT images with FL settings.
Federated Whole Prostate Segmentation in MRI with Personalized Neural Architectures
Jul 16, 2021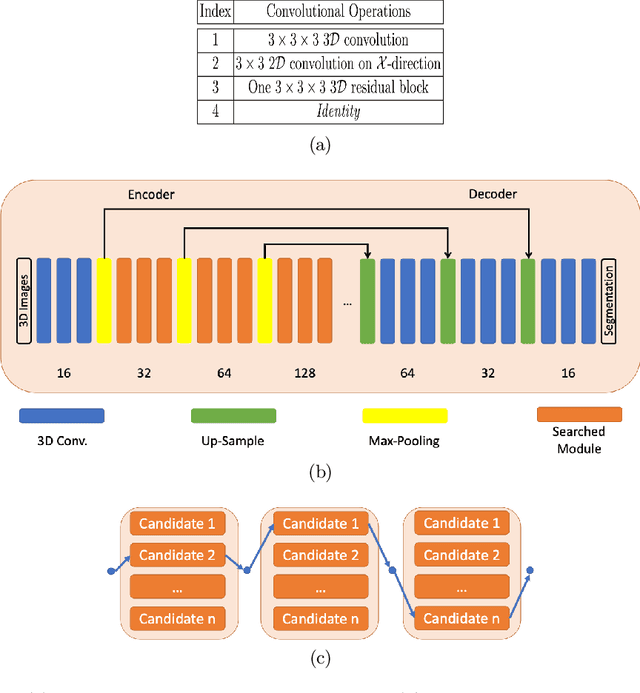
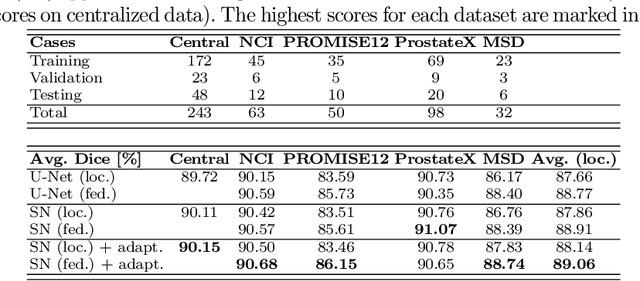
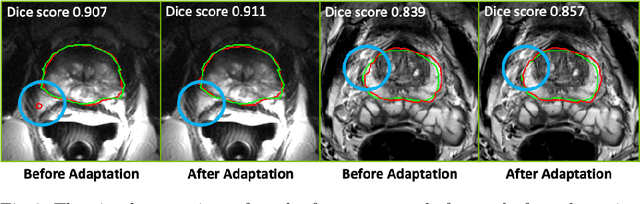
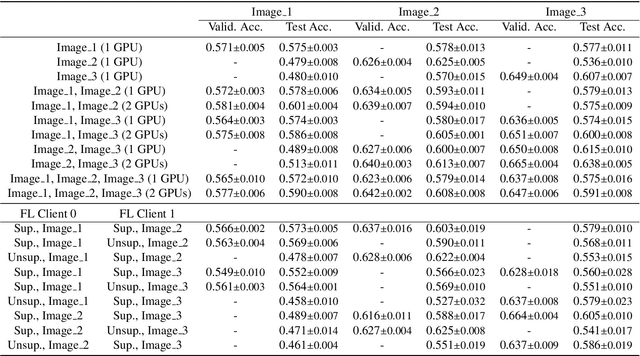
Building robust deep learning-based models requires diverse training data, ideally from several sources. However, these datasets cannot be combined easily because of patient privacy concerns or regulatory hurdles, especially if medical data is involved. Federated learning (FL) is a way to train machine learning models without the need for centralized datasets. Each FL client trains on their local data while only sharing model parameters with a global server that aggregates the parameters from all clients. At the same time, each client's data can exhibit differences and inconsistencies due to the local variation in the patient population, imaging equipment, and acquisition protocols. Hence, the federated learned models should be able to adapt to the local particularities of a client's data. In this work, we combine FL with an AutoML technique based on local neural architecture search by training a "supernet". Furthermore, we propose an adaptation scheme to allow for personalized model architectures at each FL client's site. The proposed method is evaluated on four different datasets from 3D prostate MRI and shown to improve the local models' performance after adaptation through selecting an optimal path through the AutoML supernet.
Diminishing Uncertainty within the Training Pool: Active Learning for Medical Image Segmentation
Jan 07, 2021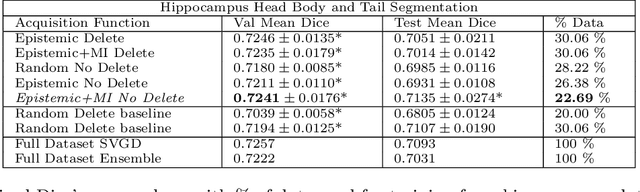
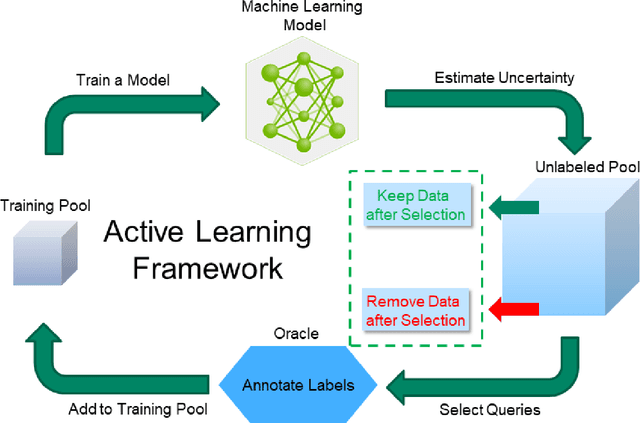
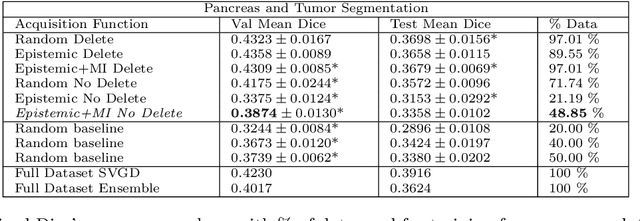
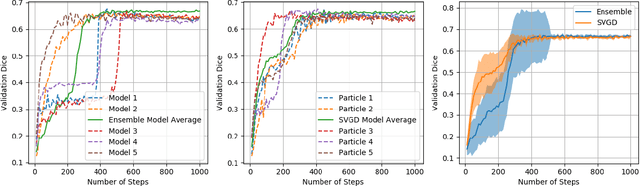
Active learning is a unique abstraction of machine learning techniques where the model/algorithm could guide users for annotation of a set of data points that would be beneficial to the model, unlike passive machine learning. The primary advantage being that active learning frameworks select data points that can accelerate the learning process of a model and can reduce the amount of data needed to achieve full accuracy as compared to a model trained on a randomly acquired data set. Multiple frameworks for active learning combined with deep learning have been proposed, and the majority of them are dedicated to classification tasks. Herein, we explore active learning for the task of segmentation of medical imaging data sets. We investigate our proposed framework using two datasets: 1.) MRI scans of the hippocampus, 2.) CT scans of pancreas and tumors. This work presents a query-by-committee approach for active learning where a joint optimizer is used for the committee. At the same time, we propose three new strategies for active learning: 1.) increasing frequency of uncertain data to bias the training data set; 2.) Using mutual information among the input images as a regularizer for acquisition to ensure diversity in the training dataset; 3.) adaptation of Dice log-likelihood for Stein variational gradient descent (SVGD). The results indicate an improvement in terms of data reduction by achieving full accuracy while only using 22.69 % and 48.85 % of the available data for each dataset, respectively.
* 19 pages, 13 figures, Transactions of Medical Imaging
Federated Semi-Supervised Learning for COVID Region Segmentation in Chest CT using Multi-National Data from China, Italy, Japan
Nov 23, 2020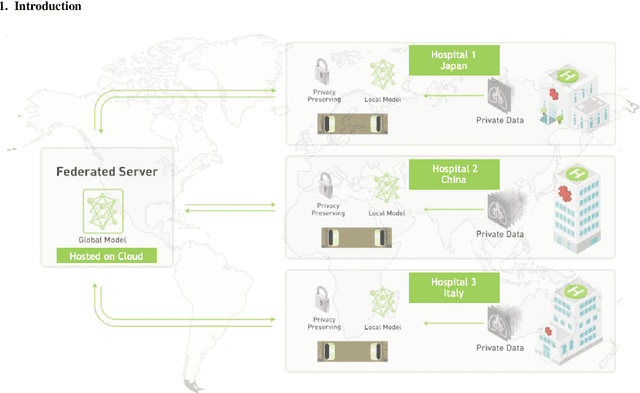
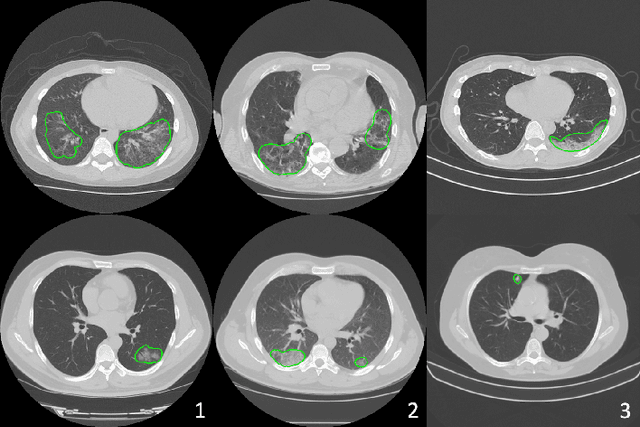
The recent outbreak of COVID-19 has led to urgent needs for reliable diagnosis and management of SARS-CoV-2 infection. As a complimentary tool, chest CT has been shown to be able to reveal visual patterns characteristic for COVID-19, which has definite value at several stages during the disease course. To facilitate CT analysis, recent efforts have focused on computer-aided characterization and diagnosis, which has shown promising results. However, domain shift of data across clinical data centers poses a serious challenge when deploying learning-based models. In this work, we attempt to find a solution for this challenge via federated and semi-supervised learning. A multi-national database consisting of 1704 scans from three countries is adopted to study the performance gap, when training a model with one dataset and applying it to another. Expert radiologists manually delineated 945 scans for COVID-19 findings. In handling the variability in both the data and annotations, a novel federated semi-supervised learning technique is proposed to fully utilize all available data (with or without annotations). Federated learning avoids the need for sensitive data-sharing, which makes it favorable for institutions and nations with strict regulatory policy on data privacy. Moreover, semi-supervision potentially reduces the annotation burden under a distributed setting. The proposed framework is shown to be effective compared to fully supervised scenarios with conventional data sharing instead of model weight sharing.
Automated Pancreas Segmentation Using Multi-institutional Collaborative Deep Learning
Sep 28, 2020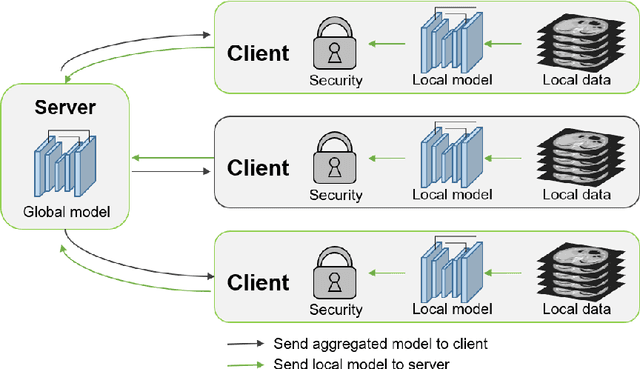

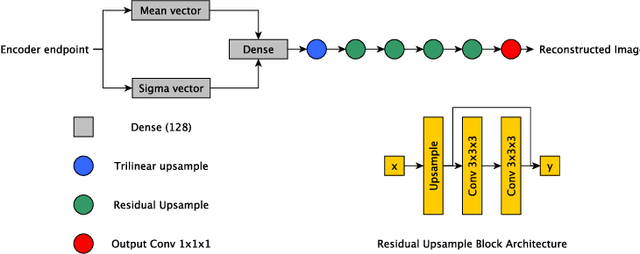
The performance of deep learning-based methods strongly relies on the number of datasets used for training. Many efforts have been made to increase the data in the medical image analysis field. However, unlike photography images, it is hard to generate centralized databases to collect medical images because of numerous technical, legal, and privacy issues. In this work, we study the use of federated learning between two institutions in a real-world setting to collaboratively train a model without sharing the raw data across national boundaries. We quantitatively compare the segmentation models obtained with federated learning and local training alone. Our experimental results show that federated learning models have higher generalizability than standalone training.
Federated Learning for Breast Density Classification: A Real-World Implementation
Sep 17, 2020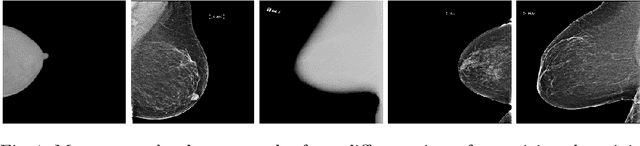

Building robust deep learning-based models requires large quantities of diverse training data. In this study, we investigate the use of federated learning (FL) to build medical imaging classification models in a real-world collaborative setting. Seven clinical institutions from across the world joined this FL effort to train a model for breast density classification based on Breast Imaging, Reporting & Data System (BI-RADS). We show that despite substantial differences among the datasets from all sites (mammography system, class distribution, and data set size) and without centralizing data, we can successfully train AI models in federation. The results show that models trained using FL perform 6.3% on average better than their counterparts trained on an institute's local data alone. Furthermore, we show a 45.8% relative improvement in the models' generalizability when evaluated on the other participating sites' testing data.
Colonoscope tracking method based on shape estimation network
Apr 20, 2020This paper presents a colonoscope tracking method utilizing a colon shape estimation method. CT colonography is used as a less-invasive colon diagnosis method. If colonic polyps or early-stage cancers are found, they are removed in a colonoscopic examination. In the colonoscopic examination, understanding where the colonoscope running in the colon is difficult. A colonoscope navigation system is necessary to reduce overlooking of polyps. We propose a colonoscope tracking method for navigation systems. Previous colonoscope tracking methods caused large tracking errors because they do not consider deformations of the colon during colonoscope insertions. We utilize the shape estimation network (SEN), which estimates deformed colon shape during colonoscope insertions. The SEN is a neural network containing long short-term memory (LSTM) layer. To perform colon shape estimation suitable to the real clinical situation, we trained the SEN using data obtained during colonoscope operations of physicians. The proposed tracking method performs mapping of the colonoscope tip position to a position in the colon using estimation results of the SEN. We evaluated the proposed method in a phantom study. We confirmed that tracking errors of the proposed method was enough small to perform navigation in the ascending, transverse, and descending colons.
* Accepted paper as an oral presentation at SPIE Medical Imaging 2019, San Diego, CA, USA
Colon Shape Estimation Method for Colonoscope Tracking using Recurrent Neural Networks
Apr 20, 2020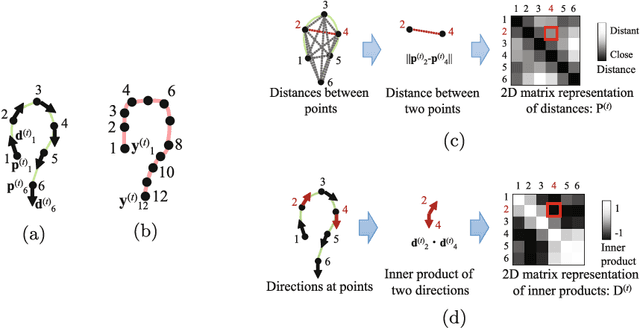
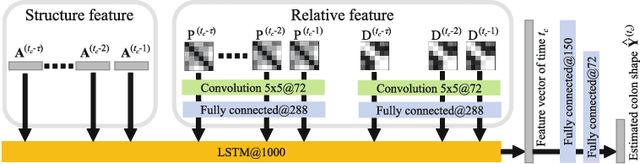
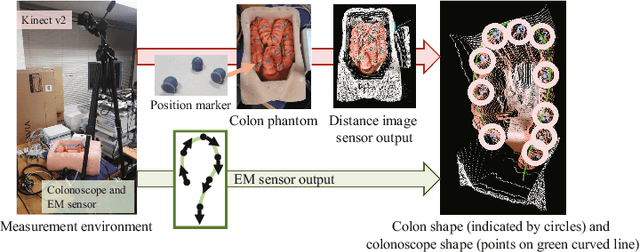
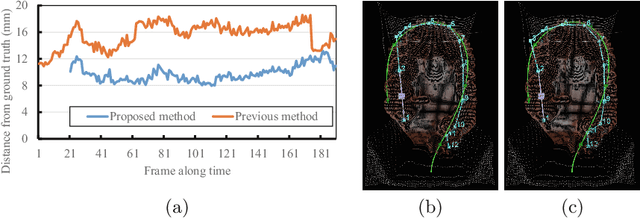
We propose an estimation method using a recurrent neural network (RNN) of the colon's shape where deformation was occurred by a colonoscope insertion. Colonoscope tracking or a navigation system that navigates physician to polyp positions is needed to reduce such complications as colon perforation. Previous tracking methods caused large tracking errors at the transverse and sigmoid colons because these areas largely deform during colonoscope insertion. Colon deformation should be taken into account in tracking processes. We propose a colon deformation estimation method using RNN and obtain the colonoscope shape from electromagnetic sensors during its insertion into the colon. This method obtains positional, directional, and an insertion length from the colonoscope shape. From its shape, we also calculate the relative features that represent the positional and directional relationships between two points on a colonoscope. Long short-term memory is used to estimate the current colon shape from the past transition of the features of the colonoscope shape. We performed colon shape estimation in a phantom study and correctly estimated the colon shapes during colonoscope insertion with 12.39 (mm) estimation error.
* Accepted paper as a poster presentation at MICCAI 2018 (International Conference on Medical Image Computing and Computer-Assisted Intervention), Granada, Spain