 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixupE: Understanding and Improving Mixup from Directional Derivative Perspective
Dec 29, 2022



Mixup is a popular data augmentation technique for training deep neural networks where additional samples are generated by linearly interpolating pairs of inputs and their labels. This technique is known to improve the generalization performance in many learning paradigms and applications. In this work, we first analyze Mixup and show that it implicitly regularizes infinitely many directional derivatives of all orders. We then propose a new method to improve Mixup based on the novel insight. To demonstrate the effectiveness of the proposed method, we conduct experiments across various domains such as images, tabular data, speech, and graphs. Our results show that the proposed method improves Mixup across various datasets using a variety of architectures, for instance, exhibiting an improvement over Mixup by 0.8% in ImageNet top-1 accuracy.
Combined Scaling for Zero-shot Transfer Learning
Nov 19, 2021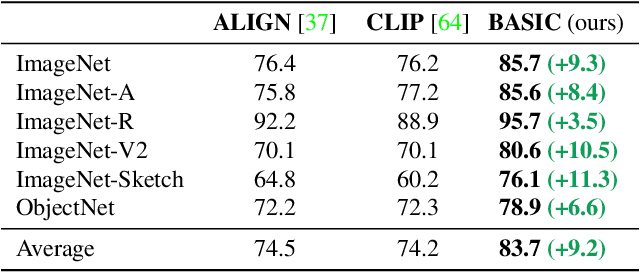
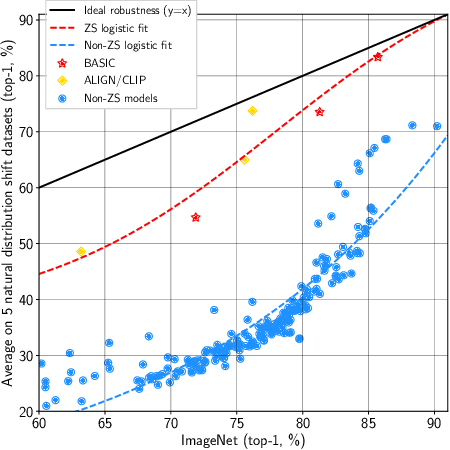
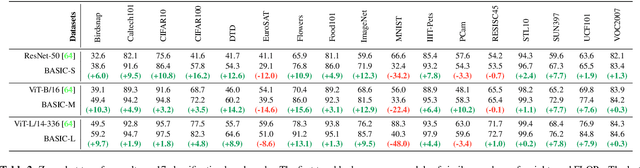

We present a combined scaling method called BASIC that achieves 85.7% top-1 zero-shot accuracy on the ImageNet ILSVRC-2012 validation set, surpassing the best-published zero-shot models - CLIP and ALIGN - by 9.3%. Our BASIC model also shows significant improvements in robustness benchmarks. For instance, on 5 test sets with natural distribution shifts such as ImageNet-{A,R,V2,Sketch} and ObjectNet, our model achieves 83.7% top-1 average accuracy, only a small drop from the its original ImageNet accuracy. To achieve these results, we scale up the contrastive learning framework of CLIP and ALIGN in three dimensions: data size, model size, and batch size. Our dataset has 6.6B noisy image-text pairs, which is 4x larger than ALIGN, and 16x larger than CLIP. Our largest model has 3B weights, which is 3.75x larger in parameters and 8x larger in FLOPs than ALIGN and CLIP. Our batch size is 65536 which is 2x more than CLIP and 4x more than ALIGN. The main challenge with scaling is the limited memory of our accelerators such as GPUs and TPUs. We hence propose a simple method of online gradient caching to overcome this limit.
An Applied Deep Learning Approach for Estimating Soybean Relative Maturity from UAV Imagery to Aid Plant Breeding Decisions
Aug 02, 2021
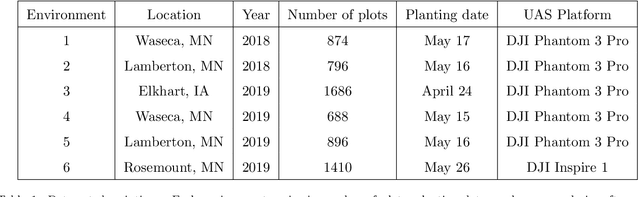
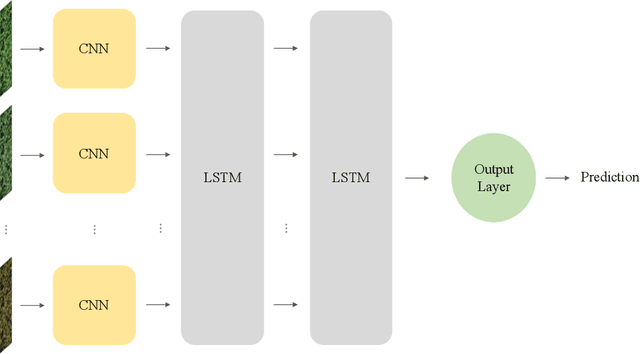
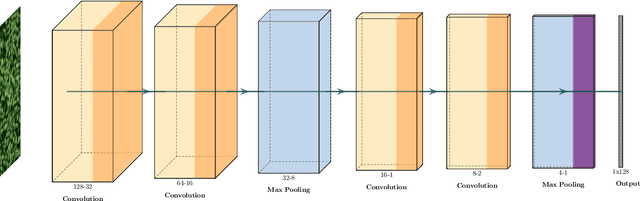
For a global breeding organization, identifying the next generation of superior crops is vital for its success. Recognizing new genetic varieties requires years of in-field testing to gather data about the crop's yield, pest resistance, heat resistance, etc. At the conclusion of the growing season, organizations need to determine which varieties will be advanced to the next growing season (or sold to farmers) and which ones will be discarded from the candidate pool. Specifically for soybeans, identifying their relative maturity is a vital piece of information used for advancement decisions. However, this trait needs to be physically observed, and there are resource limitations (time, money, etc.) that bottleneck the data collection process. To combat this, breeding organizations are moving toward advanced image capturing devices. In this paper, we develop a robust and automatic approach for estimating the relative maturity of soybeans using a time series of UAV images. An end-to-end hybrid model combining Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) is proposed to extract features and capture the sequential behavior of time series data. The proposed deep learning model was tested on six different environments across the United States. Results suggest the effectiveness of our proposed CNN-LSTM model compared to the local regression method. Furthermore, we demonstrate how this newfound information can be used to aid in plant breeding advancement decisions.
WheatNet: A Lightweight Convolutional Neural Network for High-throughput Image-based Wheat Head Detection and Counting
Mar 20, 2021
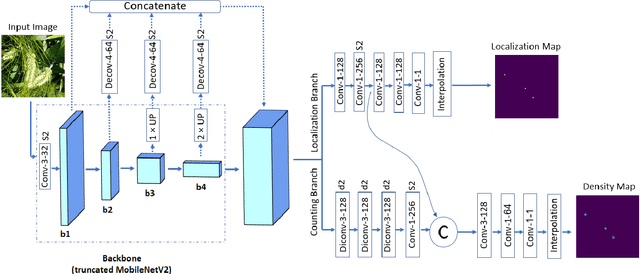
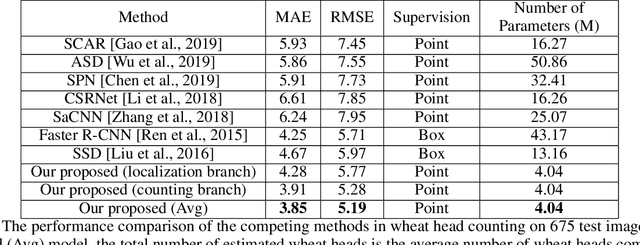

For a globally recognized planting breeding organization, manually-recorded field observation data is crucial for plant breeding decision making. However, certain phenotypic traits such as plant color, height, kernel counts, etc. can only be collected during a specific time-window of a crop's growth cycle. Due to labor-intensive requirements, only a small subset of possible field observations are recorded each season. To help mitigate this data collection bottleneck in wheat breeding, we propose a novel deep learning framework to accurately and efficiently count wheat heads to aid in the gathering of real-time data for decision making. We call our model WheatNet and show that our approach is robust and accurate for a wide range of environmental conditions of the wheat field. WheatNet uses a truncated MobileNetV2 as a lightweight backbone feature extractor which merges feature maps with different scales to counter image scale variations. Then, extracted multi-scale features go to two parallel sub-networks for simultaneous density-based counting and localization tasks. Our proposed method achieves an MAE and RMSE of 3.85 and 5.19 in our wheat head counting task, respectively, while having significantly fewer parameters when compared to other state-of-the-art methods. Our experiments and comparisons with other state-of-the-art methods demonstrate the superiority and effectiveness of our proposed method.
Meta Back-translation
Feb 15, 2021
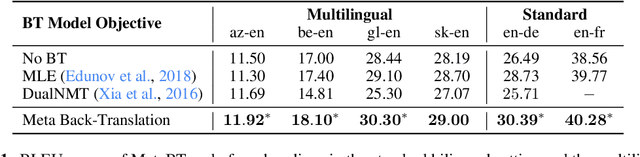
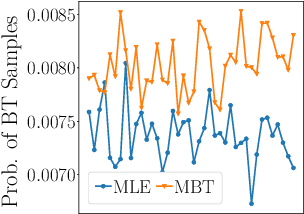

Back-translation is an effective strategy to improve the performance of Neural Machine Translation~(NMT) by generating pseudo-parallel data. However, several recent works have found that better translation quality of the pseudo-parallel data does not necessarily lead to better final translation models, while lower-quality but more diverse data often yields stronger results. In this paper, we propose a novel method to generate pseudo-parallel data from a pre-trained back-translation model. Our method is a meta-learning algorithm which adapts a pre-trained back-translation model so that the pseudo-parallel data it generates would train a forward-translation model to do well on a validation set. In our evaluations in both the standard datasets WMT En-De'14 and WMT En-Fr'14, as well as a multilingual translation setting, our method leads to significant improvements over strong baselines. Our code will be made available.
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Feb 11, 2021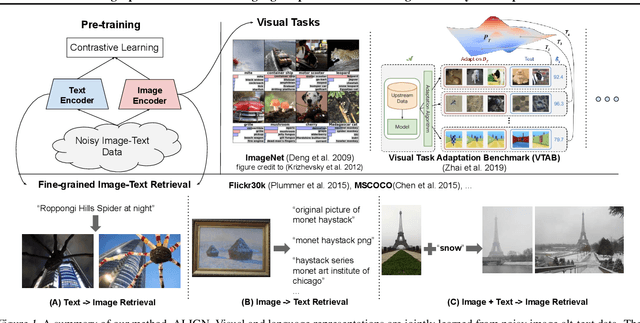
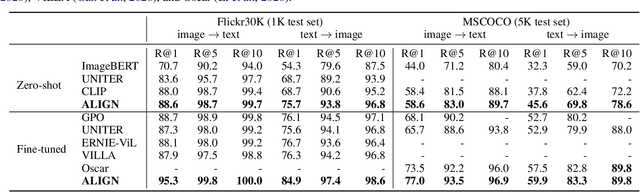


Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations also set new state-of-the-art results on Flickr30K and MSCOCO benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable cross-modality search with complex text and text + image queries.
AutoDropout: Learning Dropout Patterns to Regularize Deep Networks
Jan 05, 2021

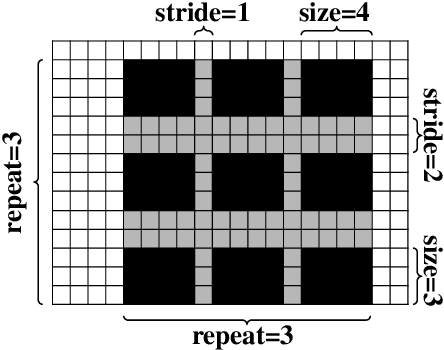
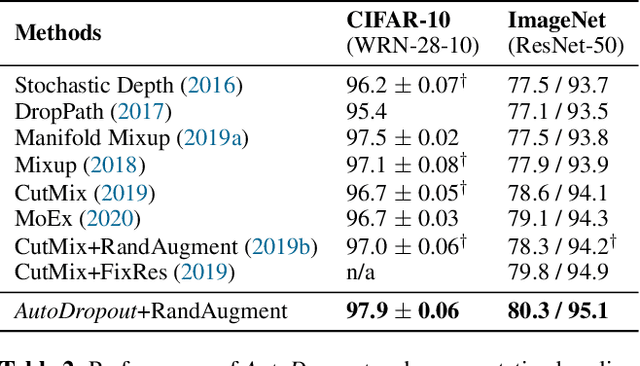
Neural networks are often over-parameterized and hence benefit from aggressive regularization. Conventional regularization methods, such as Dropout or weight decay, do not leverage the structures of the network's inputs and hidden states. As a result, these conventional methods are less effective than methods that leverage the structures, such as SpatialDropout and DropBlock, which randomly drop the values at certain contiguous areas in the hidden states and setting them to zero. Although the locations of dropout areas random, the patterns of SpatialDropout and DropBlock are manually designed and fixed. Here we propose to learn the dropout patterns. In our method, a controller learns to generate a dropout pattern at every channel and layer of a target network, such as a ConvNet or a Transformer. The target network is then trained with the dropout pattern, and its resulting validation performance is used as a signal for the controller to learn from. We show that this method works well for both image recognition on CIFAR-10 and ImageNet, as well as language modeling on Penn Treebank and WikiText-2. The learned dropout patterns also transfers to different tasks and datasets, such as from language model on Penn Treebank to Engligh-French translation on WMT 2014. Our code will be available.
YieldNet: A Convolutional Neural Network for Simultaneous Corn and Soybean Yield Prediction Based on Remote Sensing Data
Dec 05, 2020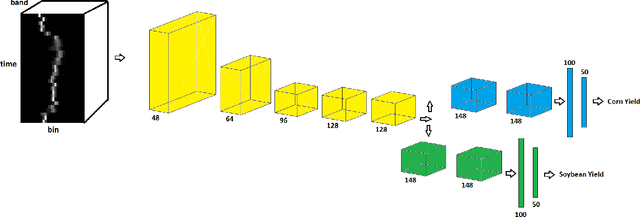
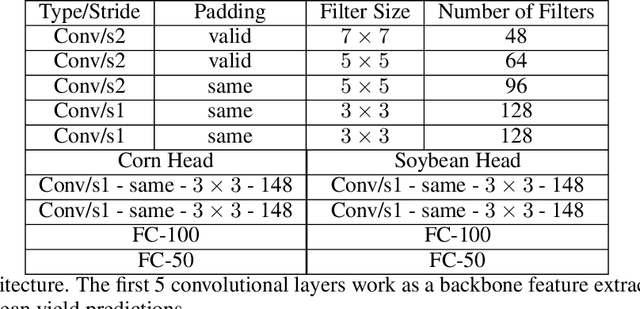
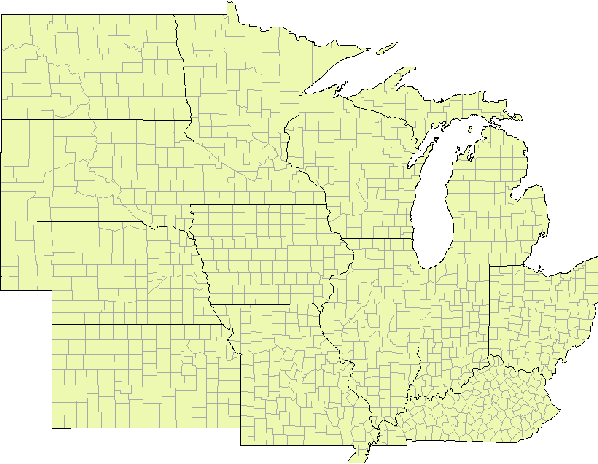
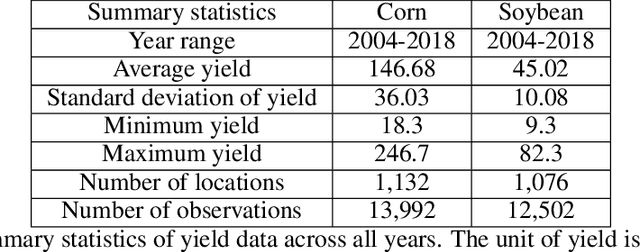
Large scale crop yield estimation is, in part, made possible due to the availability of remote sensing data allowing for the continuous monitoring of crops throughout its growth state. Having this information allows stakeholders the ability to make real-time decisions to maximize yield potential. Although various models exist that predict yield from remote sensing data, there currently does not exist an approach that can estimate yield for multiple crops simultaneously, and thus leads to more accurate predictions. A model that predicts yield of multiple crops and concurrently considers the interaction between multiple crop's yield. We propose a new model called YieldNet which utilizes a novel deep learning framework that uses transfer learning between corn and soybean yield predictions by sharing the weights of the backbone feature extractor. Additionally, to consider the multi-target response variable, we propose a new loss function. Numerical results demonstrate that our proposed method accurately predicts yield from one to four months before the harvest, and is competitive to other state-of-the-art approaches.
Towards Domain-Agnostic Contrastive Learning
Nov 09, 2020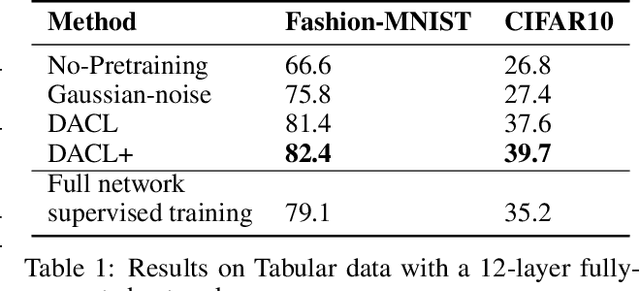
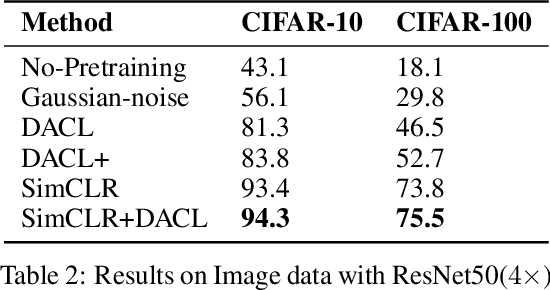
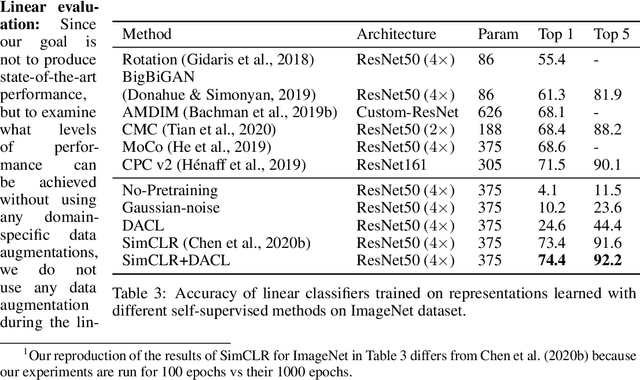

Despite recent success, most contrastive self-supervised learning methods are domain-specific, relying heavily on data augmentation techniques that require knowledge about a particular domain, such as image cropping and rotation. To overcome such limitation, we propose a novel domain-agnostic approach to contrastive learning, named DACL, that is applicable to domains where invariances, and thus, data augmentation techniques, are not readily available. Key to our approach is the use of Mixup noise to create similar and dissimilar examples by mixing data samples differently either at the input or hidden-state levels. To demonstrate the effectiveness of DACL, we conduct experiments across various domains such as tabular data, images, and graphs. Our results show that DACL not only outperforms other domain-agnostic noising methods, such as Gaussian-noise, but also combines well with domain-specific methods, such as SimCLR, to improve self-supervised visual representation learning. Finally, we theoretically analyze our method and show advantages over the Gaussian-noise based contrastive learning approach.
Training EfficientNets at Supercomputer Scale: 83% ImageNet Top-1 Accuracy in One Hour
Nov 05, 2020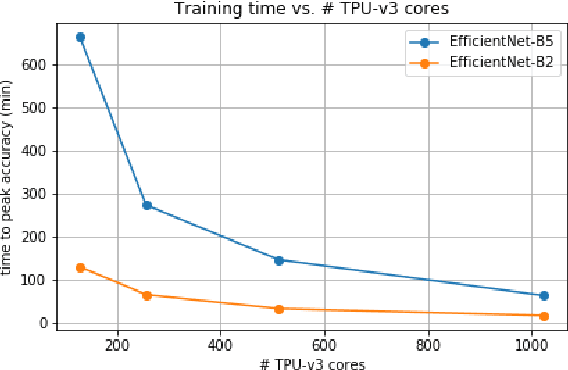
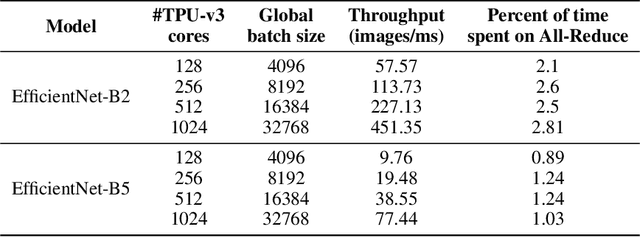
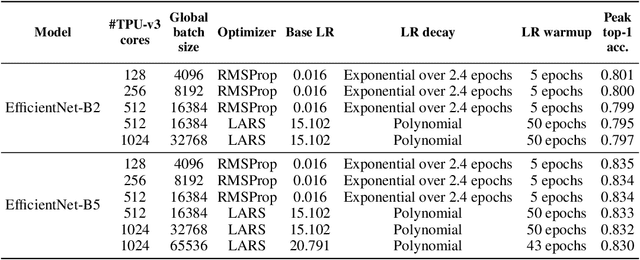
EfficientNets are a family of state-of-the-art image classification models based on efficiently scaled convolutional neural networks. Currently, EfficientNets can take on the order of days to train; for example, training an EfficientNet-B0 model takes 23 hours on a Cloud TPU v2-8 node. In this paper, we explore techniques to scale up the training of EfficientNets on TPU-v3 Pods with 2048 cores, motivated by speedups that can be achieved when training at such scales. We discuss optimizations required to scale training to a batch size of 65536 on 1024 TPU-v3 cores, such as selecting large batch optimizers and learning rate schedules as well as utilizing distributed evaluation and batch normalization techniques. Additionally, we present timing and performance benchmarks for EfficientNet models trained on the ImageNet dataset in order to analyze the behavior of EfficientNets at scale. With our optimizations, we are able to train EfficientNet on ImageNet to an accuracy of 83% in 1 hour and 4 minutes.