 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Generation and Editing with StyleGAN: A Survey
Dec 18, 2022



Our goal with this survey is to provide an overview of the state of the art deep learning technologies for face generation and editing. We will cover popular latest architectures and discuss key ideas that make them work, such as inversion, latent representation, loss functions, training procedures, editing methods, and cross domain style transfer. We particularly focus on GAN-based architectures that have culminated in the StyleGAN approaches, which allow generation of high-quality face images and offer rich interfaces for controllable semantics editing and preserving photo quality. We aim to provide an entry point into the field for readers that have basic knowledge about the field of deep learning and are looking for an accessible introduction and overview.
Solving Learn-to-Race Autonomous Racing Challenge by Planning in Latent Space
Jul 05, 2022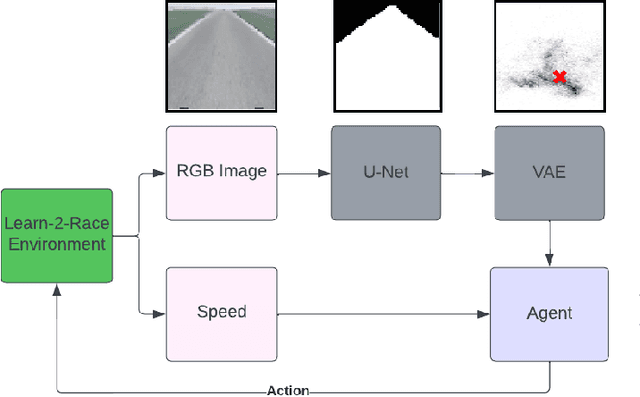
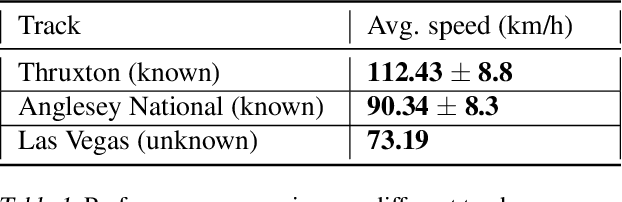

Learn-to-Race Autonomous Racing Virtual Challenge hosted on www<dot>aicrowd<dot>com platform consisted of two tracks: Single and Multi Camera. Our UniTeam team was among the final winners in the Single Camera track. The agent is required to pass the previously unknown F1-style track in the minimum time with the least amount of off-road driving violations. In our approach, we used the U-Net architecture for road segmentation, variational autocoder for encoding a road binary mask, and a nearest-neighbor search strategy that selects the best action for a given state. Our agent achieved an average speed of 105 km/h on stage 1 (known track) and 73 km/h on stage 2 (unknown track) without any off-road driving violations. Here we present our solution and results.
YOLO -- You only look 10647 times
Jan 21, 2022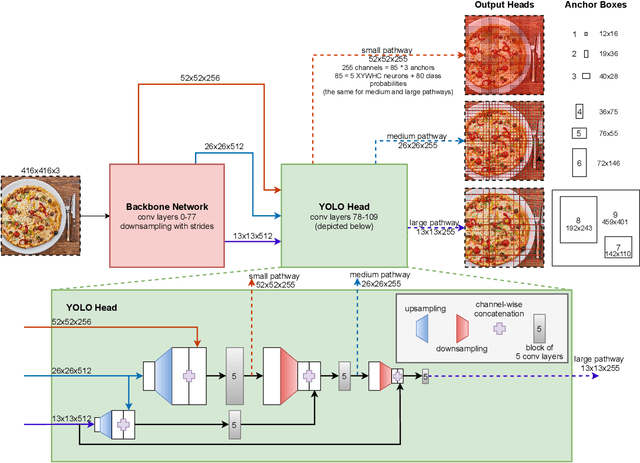



With this work we are explaining the "You Only Look Once" (YOLO) single-stage object detection approach as a parallel classification of 10647 fixed region proposals. We support this view by showing that each of YOLOs output pixel is attentive to a specific sub-region of previous layers, comparable to a local region proposal. This understanding reduces the conceptual gap between YOLO-like single-stage object detection models, RCNN-like two-stage region proposal based models, and ResNet-like image classification models. In addition, we created interactive exploration tools for a better visual understanding of the YOLO information processing streams: https://limchr.github.io/yolo_visualization
Transfer Learning with Jukebox for Music Source Separation
Nov 28, 2021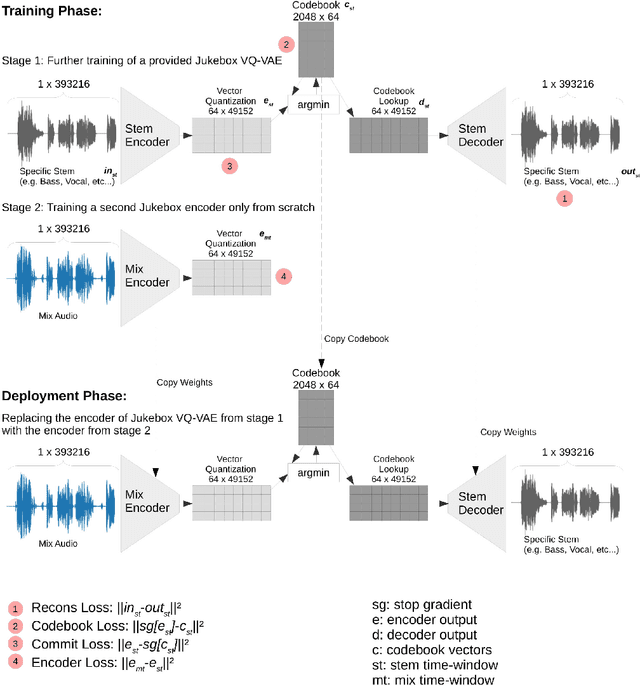
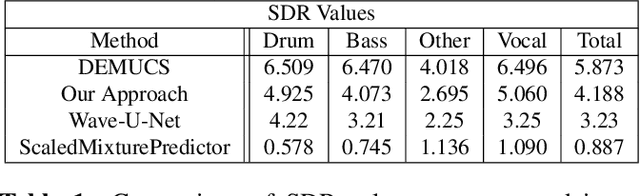
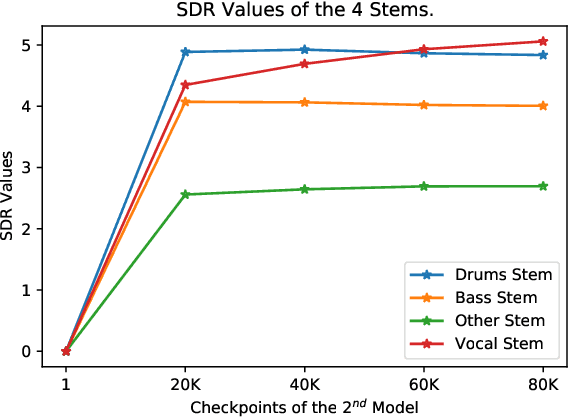
In this work, we demonstrate how to adapt a publicly available pre-trained Jukebox model for the problem of audio source separation from a single mixed audio channel. Our neural network architecture for transfer learning is fast to train and results demonstrate comparable performance to other state-of-the-art approaches. We provide an open-source code implementation of our architecture (https://rebrand.ly/transfer-jukebox-github).
Critic Guided Segmentation of Rewarding Objects in First-Person Views
Jul 20, 2021
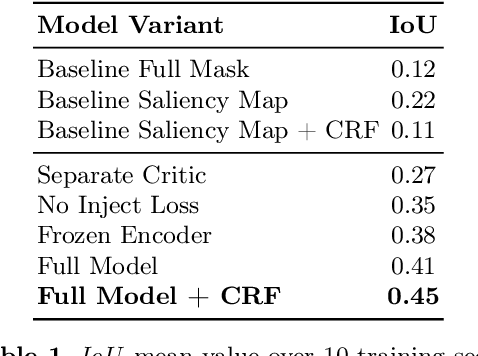

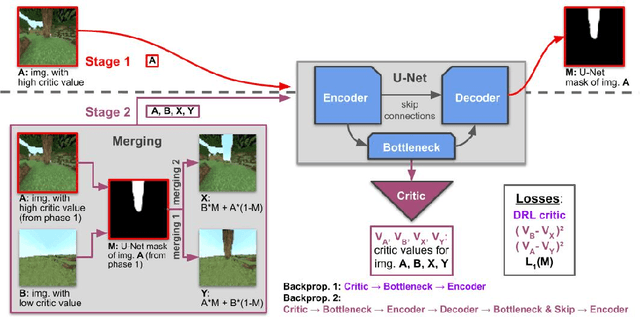
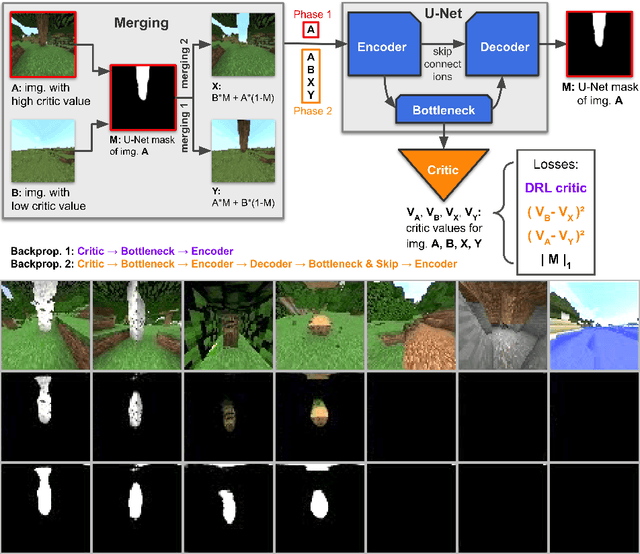
This work discusses a learning approach to mask rewarding objects in images using sparse reward signals from an imitation learning dataset. For that, we train an Hourglass network using only feedback from a critic model. The Hourglass network learns to produce a mask to decrease the critic's score of a high score image and increase the critic's score of a low score image by swapping the masked areas between these two images. We trained the model on an imitation learning dataset from the NeurIPS 2020 MineRL Competition Track, where our model learned to mask rewarding objects in a complex interactive 3D environment with a sparse reward signal. This approach was part of the 1st place winning solution in this competition. Video demonstration and code: https://rebrand.ly/critic-guided-segmentation
Optimizing piano practice with a utility-based scaffold
Jun 21, 2021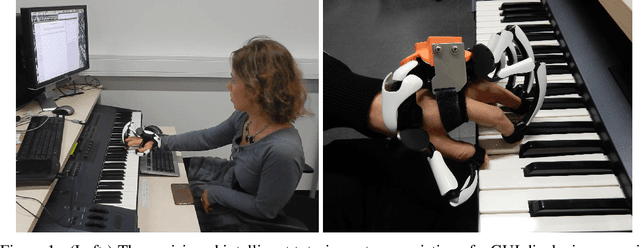
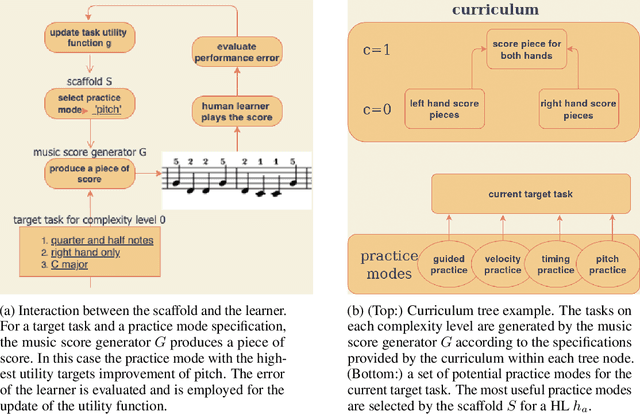
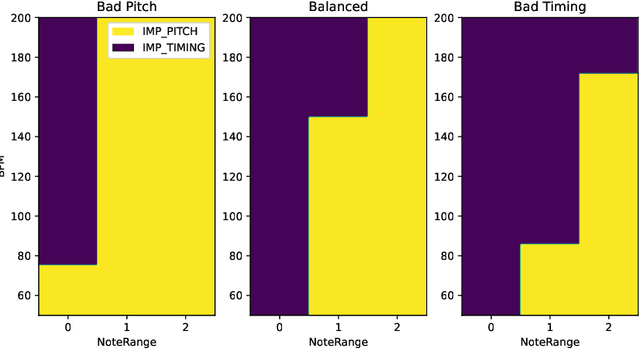
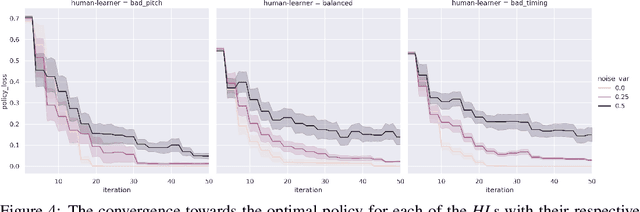
A typical part of learning to play the piano is the progression through a series of practice units that focus on individual dimensions of the skill, such as hand coordination, correct posture, or correct timing. Ideally, a focus on a particular practice method should be made in a way to maximize the learner's progress in learning to play the piano. Because we each learn differently, and because there are many choices for possible piano practice tasks and methods, the set of practice tasks should be dynamically adapted to the human learner. However, having a human teacher guide individual practice is not always feasible since it is time consuming, expensive, and not always available. Instead, we suggest to optimize in the space of practice methods, the so-called practice modes. The proposed optimization process takes into account the skills of the individual learner and their history of learning. In this work we present a modeling framework to guide the human learner through the learning process by choosing practice modes that have the highest expected utility (i.e., improvement in piano playing skill). To this end, we propose a human learner utility model based on a Gaussian process, and exemplify the model training and its application for practice scaffolding on an example of simulated human learners.
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021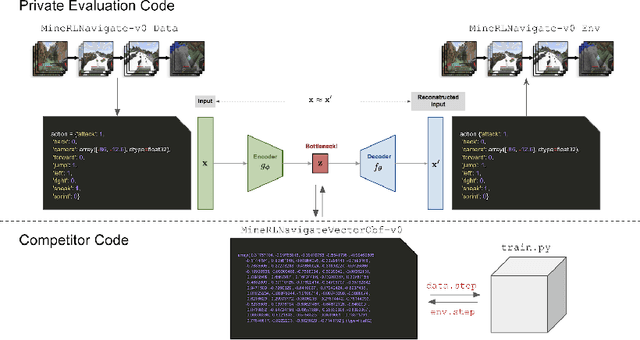

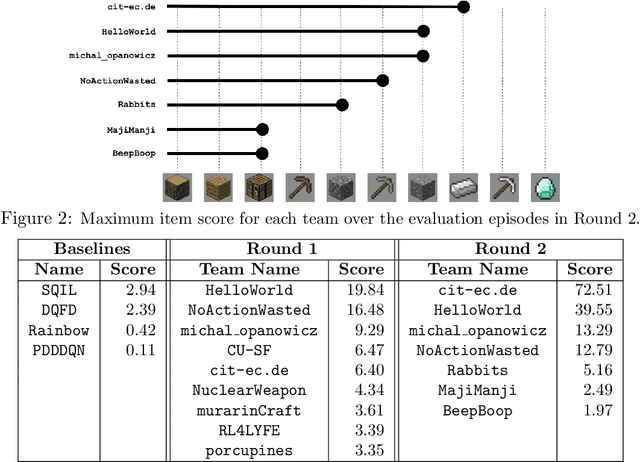
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
Solving Physics Puzzles by Reasoning about Paths
Nov 14, 2020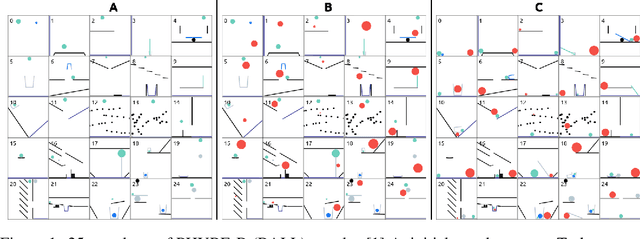

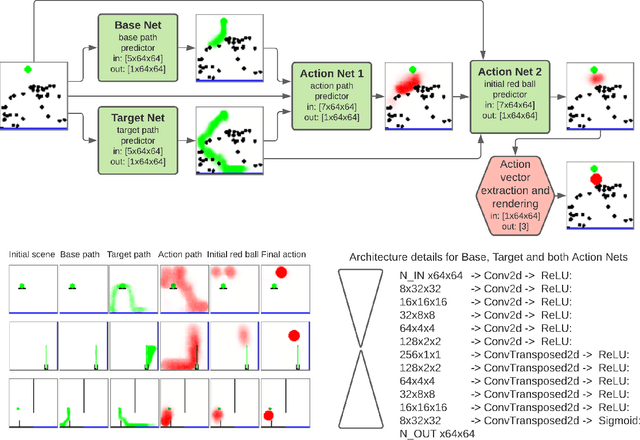
We propose a new deep learning model for goal-driven tasks that require intuitive physical reasoning and intervention in the scene to achieve a desired end goal. Its modular structure is motivated by hypothesizing a sequence of intuitive steps that humans apply when trying to solve such a task. The model first predicts the path the target object would follow without intervention and the path the target object should follow in order to solve the task. Next, it predicts the desired path of the action object and generates the placement of the action object. All components of the model are trained jointly in a supervised way; each component receives its own learning signal but learning signals are also backpropagated through the entire architecture. To evaluate the model we use PHYRE - a benchmark test for goal-driven physical reasoning in 2D mechanics puzzles.
From Crystallized Adaptivity to Fluid Adaptivity in Deep Reinforcement Learning -- Insights from Biological Systems on Adaptive Flexibility
Aug 13, 2019
Recent developments in machine-learning algorithms have led to impressive performance increases in many traditional application scenarios of artificial intelligence research. In the area of deep reinforcement learning, deep learning functional architectures are combined with incremental learning schemes for sequential tasks that include interaction-based, but often delayed feedback. Despite their impressive successes, modern machine-learning approaches, including deep reinforcement learning, still perform weakly when compared to flexibly adaptive biological systems in certain naturally occurring scenarios. Such scenarios include transfers to environments different than the ones in which the training took place or environments that dynamically change, both of which are often mastered by biological systems through a capability that we here term "fluid adaptivity" to contrast it from the much slower adaptivity ("crystallized adaptivity") of the prior learning from which the behavior emerged. In this article, we derive and discuss research strategies, based on analyzes of fluid adaptivity in biological systems and its neuronal modeling, that might aid in equipping future artificially intelligent systems with capabilities of fluid adaptivity more similar to those seen in some biologically intelligent systems. A key component of this research strategy is the dynamization of the problem space itself and the implementation of this dynamization by suitably designed flexibly interacting modules.
Learning efficient haptic shape exploration with a rigid tactile sensor array
Feb 22, 2019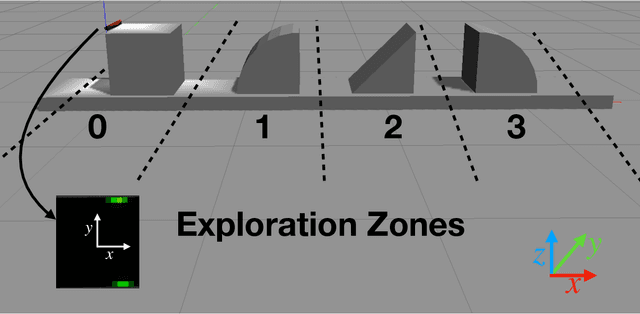
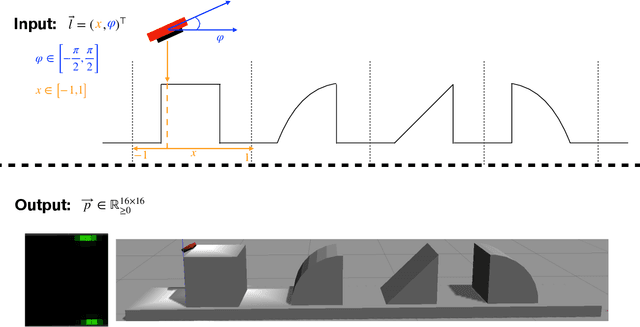
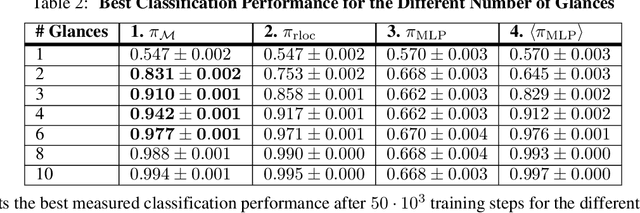
Haptic exploration is a key skill for both robots and humans to discriminate and handle unknown or recognize familiar objects. Its active nature is impressively evident in humans which from early on reliably acquire sophisticated sensory-motor capabilites for active exploratory touch and directed manual exploration that associates surfaces and object properties with their spatial locations. In stark contrast, in robotics the relative lack of good real-world interaction models, along with very restricted sensors and a scarcity of suitable training data to leverage machine learning methods has so far rendered haptic exploration a largely underdeveloped skill for robots, very unlike vision where deep learning approaches and an abundance of available training data have triggered huge advances. In the present work, we connect recent advances in recurrent models of visual attention (RAM) with previous insights about the organisation of human haptic search behavior, exploratory procedures and haptic glances for a novel learning architecture that learns a generative model of haptic exploration in a simplified three-dimensional environment. The proposed algorithm simultaneously optimizes main perception-action loop components: feature extraction, integration of features over time, and the control strategy, while continuously acquiring data online. The resulting method has been successfully tested with four different objects. It achieved results close to 100% while performing object contour exploration that has been optimized for its own sensor morphology.