 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft labeling by Distilling Anatomical knowledge for Improved MS Lesion Segmentation
Jan 26, 2019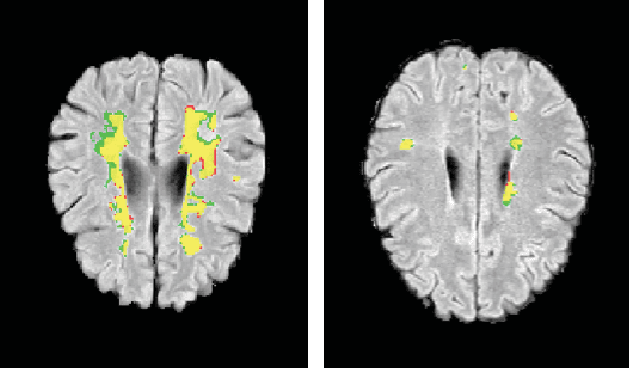
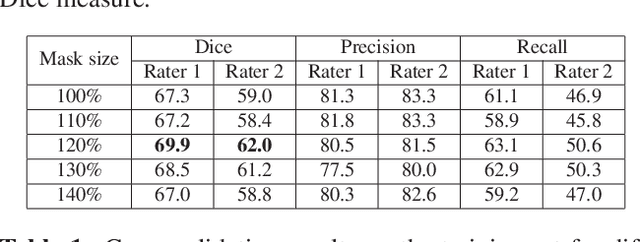
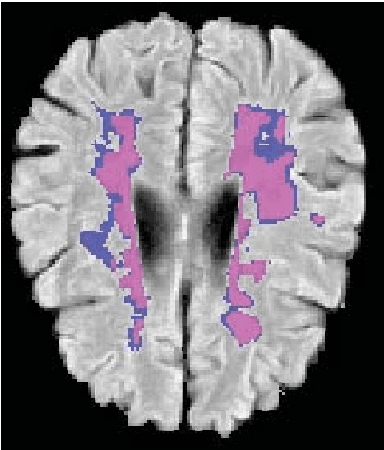
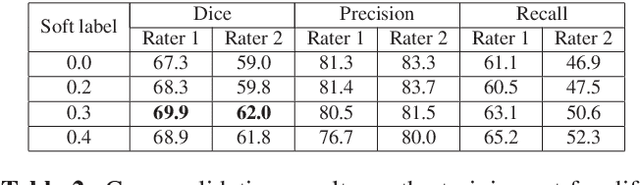
This paper explores the use of a soft ground-truth mask ("soft mask'') to train a Fully Convolutional Neural Network (FCNN) for segmentation of Multiple Sclerosis (MS) lesions. Detection and segmentation of MS lesions is a complex task largely due to the extreme unbalanced data, with very small number of lesion pixels that can be used for training. Utilizing the anatomical knowledge that the lesion surrounding pixels may also include some lesion level information, we suggest to increase the data set of the lesion class with neighboring pixel data - with a reduced confidence weight. A soft mask is constructed by morphological dilation of the binary segmentation mask provided by a given expert, where expert-marked voxels receive label 1 and voxels of the dilated region are assigned a soft label. In the methodology proposed, the FCNN is trained using the soft mask. On the ISBI 2015 challenge dataset, this is shown to provide a better precision-recall tradeoff and to achieve a higher average Dice similarity coefficient. We also show that by using this soft mask scheme we can improve the network segmentation performance when compared to a second independent expert.
The Liver Tumor Segmentation Benchmark (LiTS)
Jan 13, 2019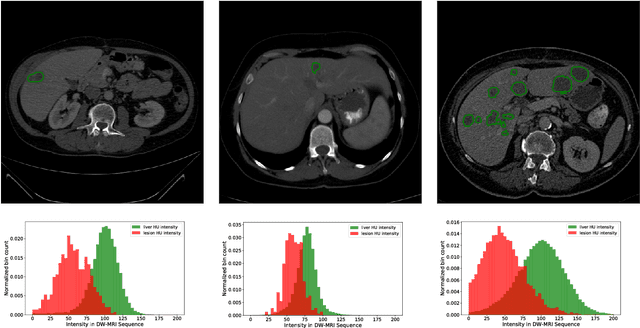


In this work, we report the set-up and results of the Liver Tumor Segmentation Benchmark (LITS) organized in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2016 and International Conference On Medical Image Computing Computer Assisted Intervention (MICCAI) 2017. Twenty four valid state-of-the-art liver and liver tumor segmentation algorithms were applied to a set of 131 computed tomography (CT) volumes with different types of tumor contrast levels (hyper-/hypo-intense), abnormalities in tissues (metastasectomie) size and varying amount of lesions. The submitted algorithms have been tested on 70 undisclosed volumes. The dataset is created in collaboration with seven hospitals and research institutions and manually reviewed by independent three radiologists. We found that not a single algorithm performed best for liver and tumors. The best liver segmentation algorithm achieved a Dice score of 0.96(MICCAI) whereas for tumor segmentation the best algorithm evaluated at 0.67(ISBI) and 0.70(MICCAI). The LITS image data and manual annotations continue to be publicly available through an online evaluation system as an ongoing benchmarking resource.
Improving CNN Training using Disentanglement for Liver Lesion Classification in CT
Nov 01, 2018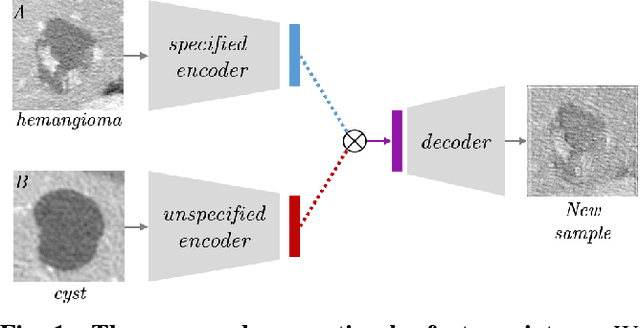
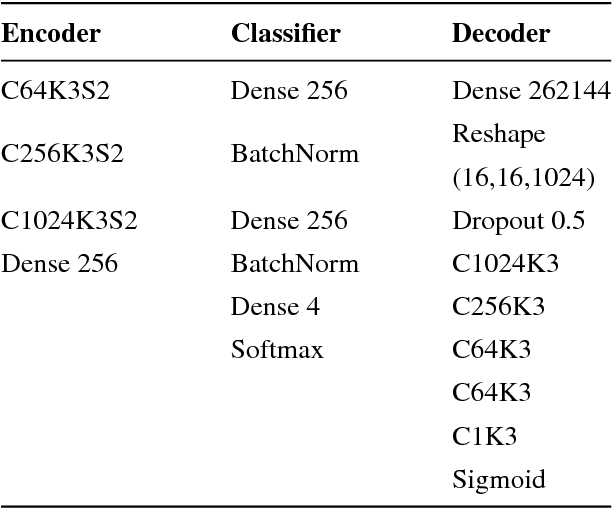
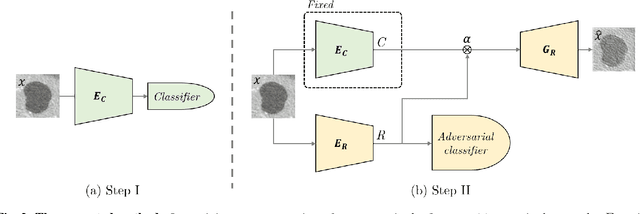
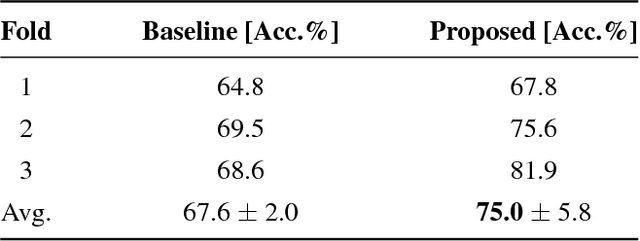
Training data is the key component in designing algorithms for medical image analysis and in many cases it is the main bottleneck in achieving good results. Recent progress in image generation has enabled the training of neural network based solutions using synthetic data. A key factor in the generation of new samples is controlling the important appearance features and potentially being able to generate a new sample of a specific class with different variants. In this work we suggest the synthesis of new data by mixing the class specified and unspecified representation of different factors in the training data. Our experiments on liver lesion classification in CT show an average improvement of 7.4% in accuracy over the baseline training scheme.
Lung Structures Enhancement in Chest Radiographs via CT based FCNN Training
Oct 14, 2018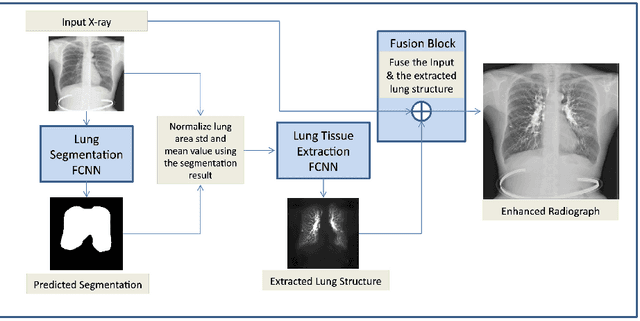
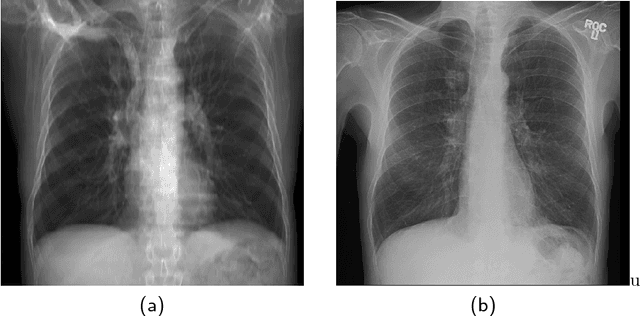
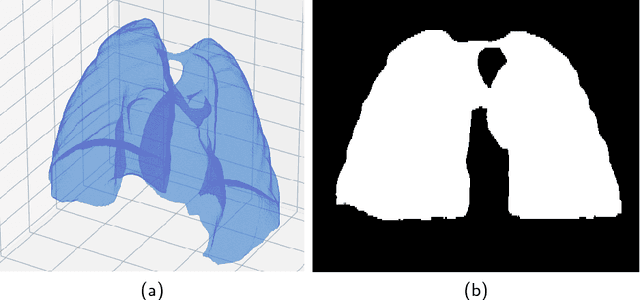
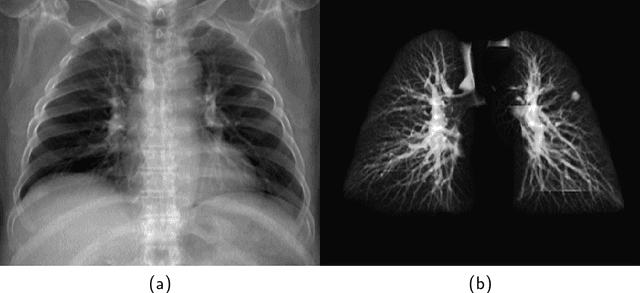
The abundance of overlapping anatomical structures appearing in chest radiographs can reduce the performance of lung pathology detection by automated algorithms (CAD) as well as the human reader. In this paper, we present a deep learning based image processing technique for enhancing the contrast of soft lung structures in chest radiographs using Fully Convolutional Neural Networks (FCNN). Two 2D FCNN architectures were trained to accomplish the task: The first performs 2D lung segmentation which is used for normalization of the lung area. The second FCNN is trained to extract lung structures. To create the training images, we employed Simulated X-Ray or Digitally Reconstructed Radiographs (DRR) derived from 516 scans belonging to the LIDC-IDRI dataset. By first segmenting the lungs in the CT domain, we are able to create a dataset of 2D lung masks to be used for training the segmentation FCNN. For training the extraction FCNN, we create DRR images of only voxels belonging to the 3D lung segmentation which we call "Lung X-ray" and use them as target images. Once the lung structures are extracted, the original image can be enhanced by fusing the original input x-ray and the synthesized "Lung X-ray". We show that our enhancement technique is applicable to real x-ray data, and display our results on the recently released NIH Chest X-Ray-14 dataset. We see promising results when training a DenseNet-121 based architecture to work directly on the lung enhanced X-ray images.
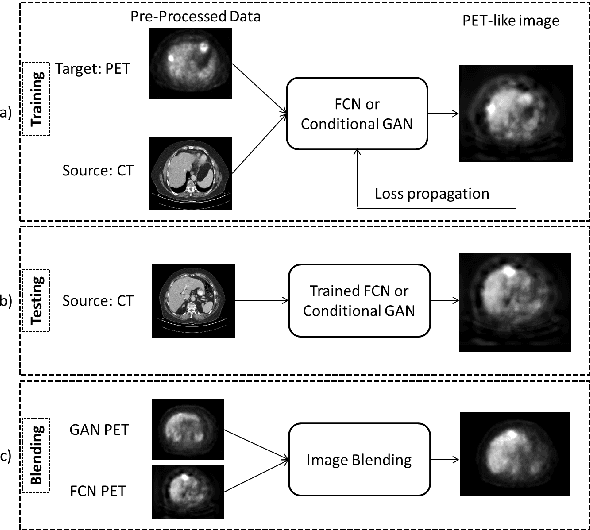
Cross-Modality Synthesis from CT to PET using FCN and GAN Networks for Improved Automated Lesion Detection
Jul 23, 2018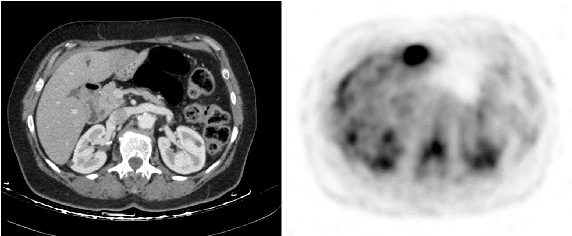
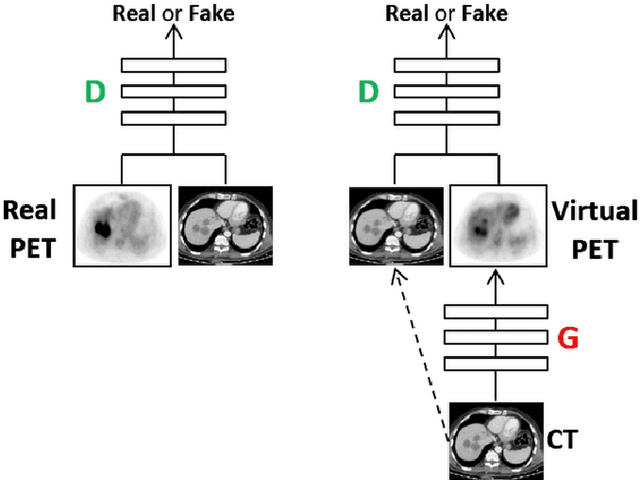

In this work we present a novel system for generation of virtual PET images using CT scans. We combine a fully convolutional network (FCN) with a conditional generative adversarial network (GAN) to generate simulated PET data from given input CT data. The synthesized PET can be used for false-positive reduction in lesion detection solutions. Clinically, such solutions may enable lesion detection and drug treatment evaluation in a CT-only environment, thus reducing the need for the more expensive and radioactive PET/CT scan. Our dataset includes 60 PET/CT scans from Sheba Medical center. We used 23 scans for training and 37 for testing. Different schemes to achieve the synthesized output were qualitatively compared. Quantitative evaluation was conducted using an existing lesion detection software, combining the synthesized PET as a false positive reduction layer for the detection of malignant lesions in the liver. Current results look promising showing a 28% reduction in the average false positive per case from 2.9 to 2.1. The suggested solution is comprehensive and can be expanded to additional body organs, and different modalities.
A Mixture of Views Network with Applications to the Classification of Breast Microcalcifications
Mar 19, 2018
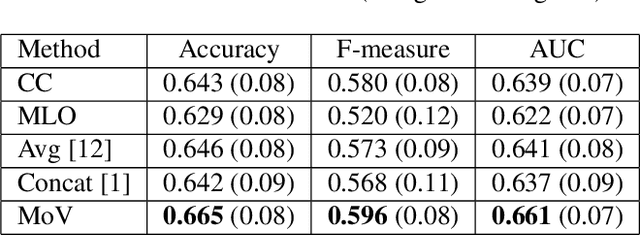
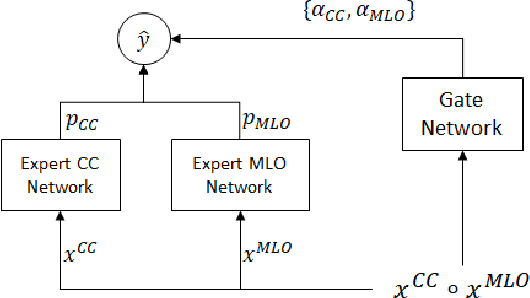
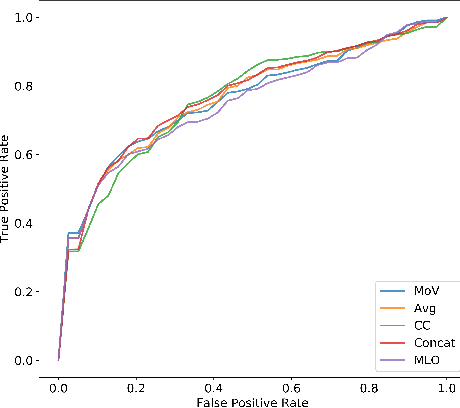
In this paper we examine data fusion methods for multi-view data classification. We present a decision concept which explicitly takes into account the input multi-view structure, where for each case there is a different subset of relevant views. This data fusion concept, which we dub Mixture of Views, is implemented by a special purpose neural network architecture. It is demonstrated on the task of classifying breast microcalcifications as benign or malignant based on CC and MLO mammography views. The single view decisions are combined by a data-driven decision, according to the relevance of each view in a given case, into a global decision. The method is evaluated on a large multi-view dataset extracted from the standardized digital database for screening mammography (DDSM). The experimental results show that our method outperforms previously suggested fusion methods.
GAN-based Synthetic Medical Image Augmentation for increased CNN Performance in Liver Lesion Classification
Mar 03, 2018
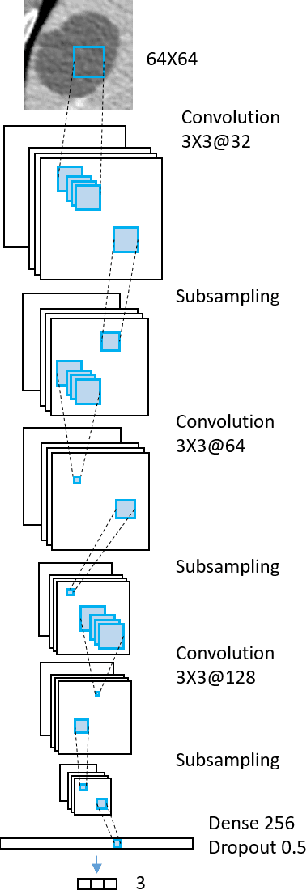
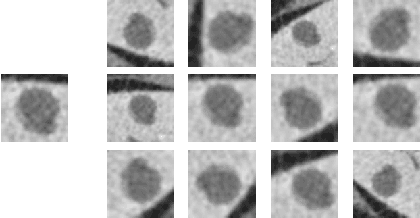
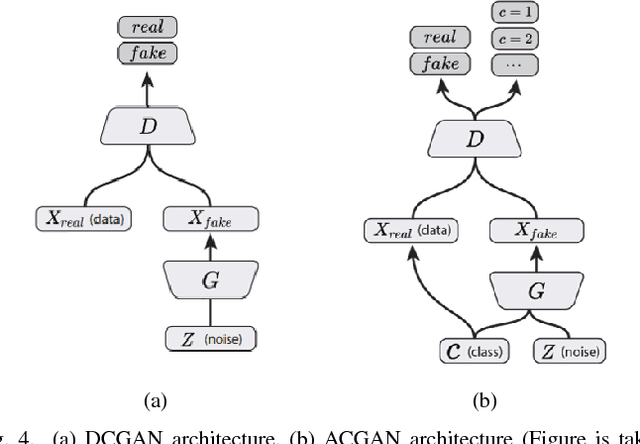
Deep learning methods, and in particular convolutional neural networks (CNNs), have led to an enormous breakthrough in a wide range of computer vision tasks, primarily by using large-scale annotated datasets. However, obtaining such datasets in the medical domain remains a challenge. In this paper, we present methods for generating synthetic medical images using recently presented deep learning Generative Adversarial Networks (GANs). Furthermore, we show that generated medical images can be used for synthetic data augmentation, and improve the performance of CNN for medical image classification. Our novel method is demonstrated on a limited dataset of computed tomography (CT) images of 182 liver lesions (53 cysts, 64 metastases and 65 hemangiomas). We first exploit GAN architectures for synthesizing high quality liver lesion ROIs. Then we present a novel scheme for liver lesion classification using CNN. Finally, we train the CNN using classic data augmentation and our synthetic data augmentation and compare performance. In addition, we explore the quality of our synthesized examples using visualization and expert assessment. The classification performance using only classic data augmentation yielded 78.6% sensitivity and 88.4% specificity. By adding the synthetic data augmentation the results increased to 85.7% sensitivity and 92.4% specificity. We believe that this approach to synthetic data augmentation can generalize to other medical classification applications and thus support radiologists' efforts to improve diagnosis.
Synthetic Data Augmentation using GAN for Improved Liver Lesion Classification
Jan 08, 2018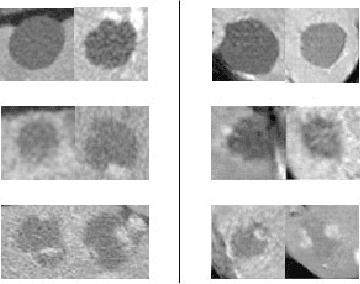
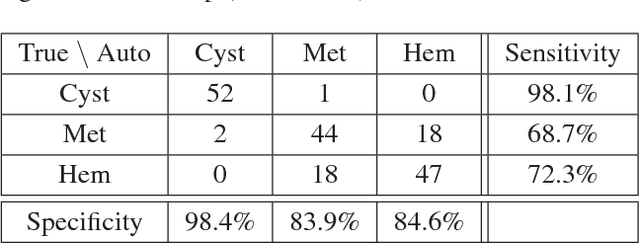
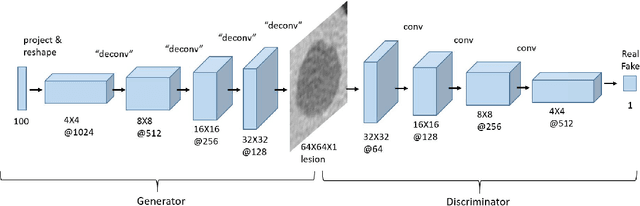
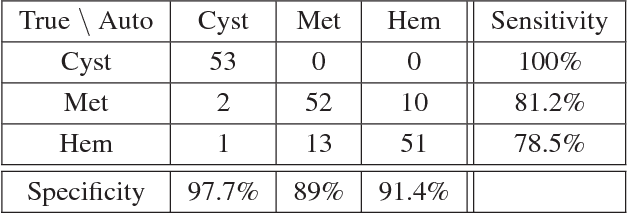
In this paper, we present a data augmentation method that generates synthetic medical images using Generative Adversarial Networks (GANs). We propose a training scheme that first uses classical data augmentation to enlarge the training set and then further enlarges the data size and its diversity by applying GAN techniques for synthetic data augmentation. Our method is demonstrated on a limited dataset of computed tomography (CT) images of 182 liver lesions (53 cysts, 64 metastases and 65 hemangiomas). The classification performance using only classic data augmentation yielded 78.6% sensitivity and 88.4% specificity. By adding the synthetic data augmentation the results significantly increased to 85.7% sensitivity and 92.4% specificity.
Anatomical Data Augmentation For CNN based Pixel-wise Classification
Jan 07, 2018
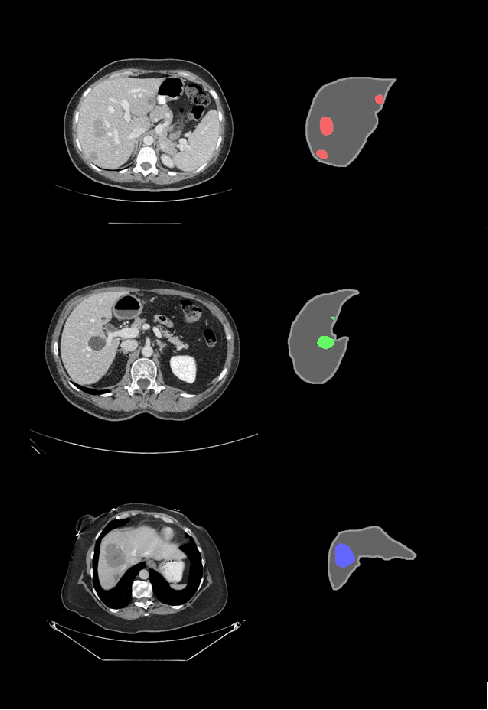
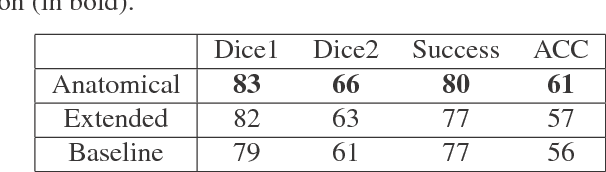
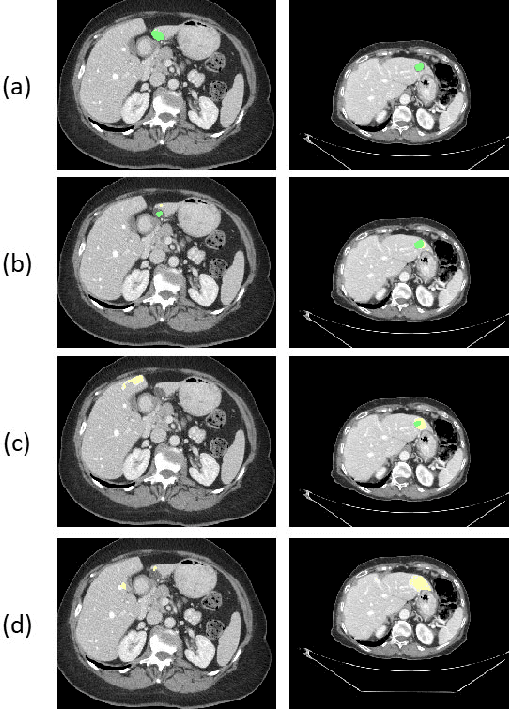
In this work we propose a method for anatomical data augmentation that is based on using slices of computed tomography (CT) examinations that are adjacent to labeled slices as another resource of labeled data for training the network. The extended labeled data is used to train a U-net network for a pixel-wise classification into different hepatic lesions and normal liver tissues. Our dataset contains CT examinations from 140 patients with 333 CT images annotated by an expert radiologist. We tested our approach and compared it to the conventional training process. Results indicate superiority of our method. Using the anatomical data augmentation we achieved an improvement of 3% in the success rate, 5% in the classification accuracy, and 4% in Dice.
Virtual PET Images from CT Data Using Deep Convolutional Networks: Initial Results
Jul 30, 2017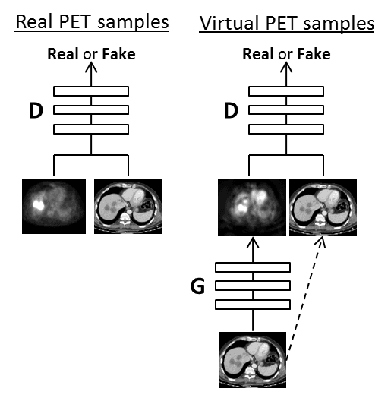
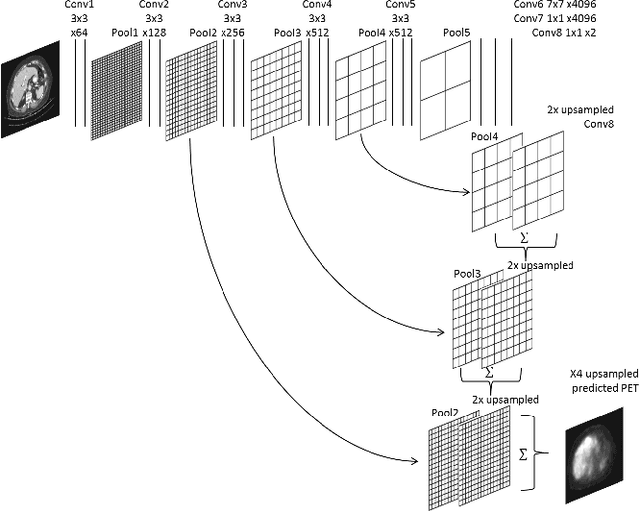
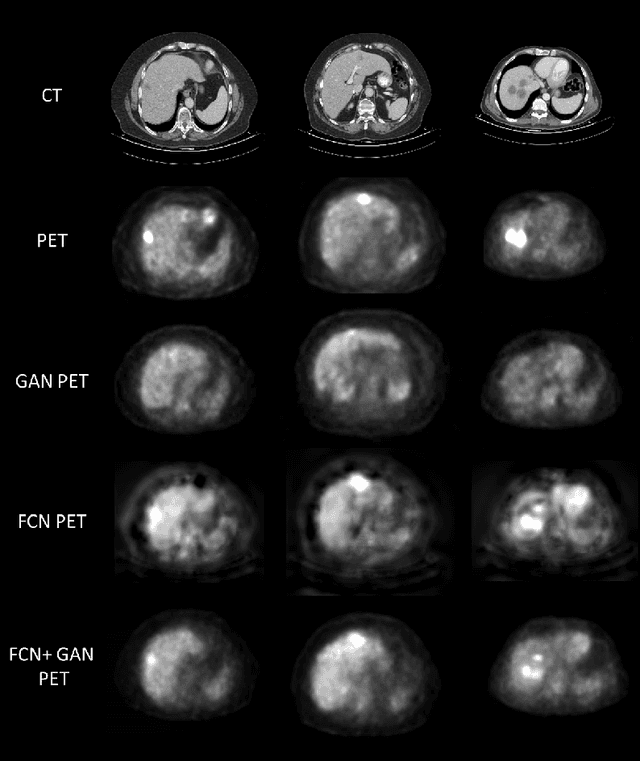
In this work we present a novel system for PET estimation using CT scans. We explore the use of fully convolutional networks (FCN) and conditional generative adversarial networks (GAN) to export PET data from CT data. Our dataset includes 25 pairs of PET and CT scans where 17 were used for training and 8 for testing. The system was tested for detection of malignant tumors in the liver region. Initial results look promising showing high detection performance with a TPR of 92.3% and FPR of 0.25 per case. Future work entails expansion of the current system to the entire body using a much larger dataset. Such a system can be used for tumor detection and drug treatment evaluation in a CT-only environment instead of the expansive and radioactive PET-CT scan.