 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaTele: Compact Refractive Metasurface Computational Telephoto Camera
Apr 08, 2026Smartphone cameras face fundamental form-factor constraints that limit their optical magnification, primarily due to the difficulty of reducing a lens assembly's telephoto ratio, the ratio between total track length (TTL) and effective focal length (EFL). Currently, conventional refractive optics struggle to achieve a telephoto ratio below 0.5 without requiring multiple bulky elements to correct optical aberrations. In this paper, we introduce MetaTele, a novel optics-algorithm co-design that breaks this bottleneck. MetaTele explicitly decouples the acquisition of scene structure and color information. First, it utilizes a compact refractive-metasurface optical assembly to capture a fine-detail structure image under a narrow wavelength band, inherently avoiding severe chromatic aberrations. Second, it captures a broadband color cue using the same optics; although this cue is heavily corrupted by chromatic aberrations, it retains sufficient spectral information to guide post-processing. We then employ a custom one-step diffusion model to computationally fuse these two raw measurements, successfully colorizing the structure image while correcting for system aberrations. We demonstrate a MetaTele prototype, achieving an unprecedented telephoto ratio of 0.44 with a TTL of just 13 mm for RGB imaging, paving the way for DSLR-level telephoto capabilities within smartphone form factors.
GenMFSR: Generative Multi-Frame Image Restoration and Super-Resolution
Mar 19, 2026Camera pipelines receive raw Bayer-format frames that need to be denoised, demosaiced, and often super-resolved. Multiple frames are captured to utilize natural hand tremors and enhance resolution. Multi-frame super-resolution is therefore a fundamental problem in camera pipelines. Existing adversarial methods are constrained by the quality of ground truth. We propose GenMFSR, the first Generative Multi-Frame Raw-to-RGB Super Resolution pipeline, that incorporates image priors from foundation models to obtain sub-pixel information for camera ISP applications. GenMFSR can align multiple raw frames, unlike existing single-frame super-resolution methods, and we propose a loss term that restricts generation to high-frequency regions in the raw domain, thus preventing low-frequency artifacts.
FlowSteer: Conditioning Flow Field for Consistent Image Restoration
Dec 09, 2025Flow-based text-to-image (T2I) models excel at prompt-driven image generation, but falter on Image Restoration (IR), often "drifting away" from being faithful to the measurement. Prior work mitigate this drift with data-specific flows or task-specific adapters that are computationally heavy and not scalable across tasks. This raises the question "Can't we efficiently manipulate the existing generative capabilities of a flow model?" To this end, we introduce FlowSteer (FS), an operator-aware conditioning scheme that injects measurement priors along the sampling path,coupling a frozed flow's implicit guidance with explicit measurement constraints. Across super-resolution, deblurring, denoising, and colorization, FS improves measurement consistency and identity preservation in a strictly zero-shot setting-no retrained models, no adapters. We show how the nature of flow models and their sensitivities to noise inform the design of such a scheduler. FlowSteer, although simple, achieves a higher fidelity of reconstructed images, while leveraging the rich generative priors of flow models.
Diffusion Algorithm for Metalens Optical Aberration Correction
Nov 16, 2025
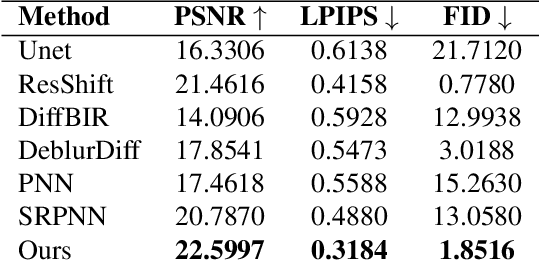


Metalenses offer a path toward creating ultra-thin optical systems, but they inherently suffer from severe, spatially varying optical aberrations, especially chromatic aberration, which makes image reconstruction a significant challenge. This paper presents a novel algorithmic solution to this problem, designed to reconstruct a sharp, full-color image from two inputs: a sharp, bandpass-filtered grayscale ``structure image'' and a heavily distorted ``color cue'' image, both captured by the metalens system. Our method utilizes a dual-branch diffusion model, built upon a pre-trained Stable Diffusion XL framework, to fuse information from the two inputs. We demonstrate through quantitative and qualitative comparisons that our approach significantly outperforms existing deblurring and pansharpening methods, effectively restoring high-frequency details while accurately colorizing the image.
Holistic Interpretation of Public Scenes Using Computer Vision and Temporal Graphs to Identify Social Distancing Violations
Dec 13, 2021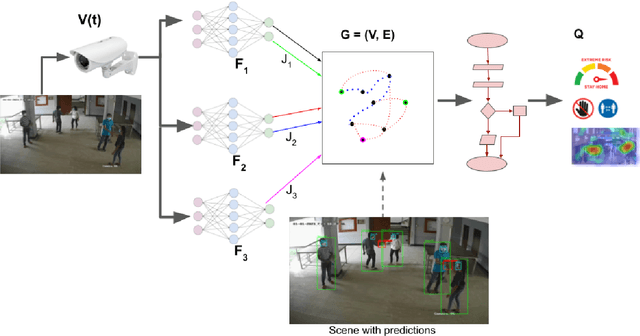

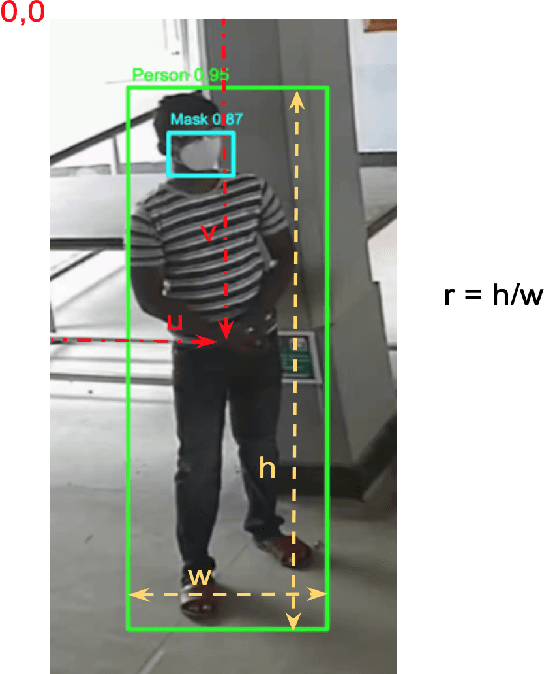

The COVID-19 pandemic has caused an unprecedented global public health crisis. Given its inherent nature, social distancing measures are proposed as the primary strategies to curb the spread of this pandemic. Therefore, identifying situations where these protocols are violated, has implications for curtailing the spread of the disease and promoting a sustainable lifestyle. This paper proposes a novel computer vision-based system to analyze CCTV footage to provide a threat level assessment of COVID-19 spread. The system strives to holistically capture and interpret the information content of CCTV footage spanning multiple frames to recognize instances of various violations of social distancing protocols, across time and space, as well as identification of group behaviors. This functionality is achieved primarily by utilizing a temporal graph-based structure to represent the information of the CCTV footage and a strategy to holistically interpret the graph and quantify the threat level of the given scene. The individual components are tested and validated on a range of scenarios and the complete system is tested against human expert opinion. The results reflect the dependence of the threat level on people, their physical proximity, interactions, protective clothing, and group dynamics. The system performance has an accuracy of 76%, thus enabling a deployable threat monitoring system in cities, to permit normalcy and sustainability in the society.
A generalized forecasting solution to enable future insights of COVID-19 at sub-national level resolutions
Aug 21, 2021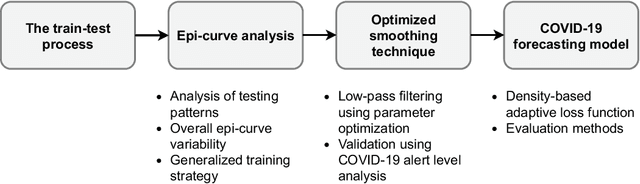
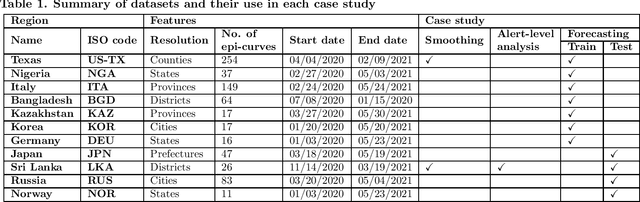
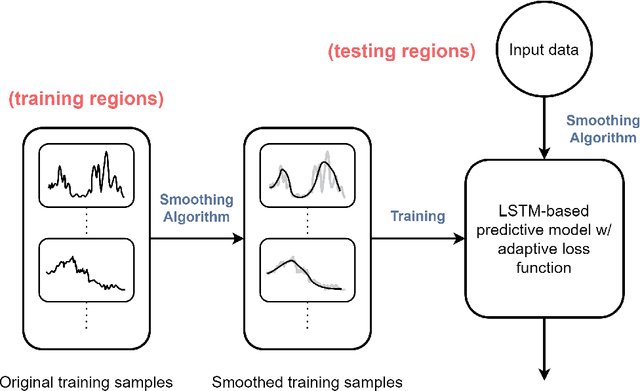
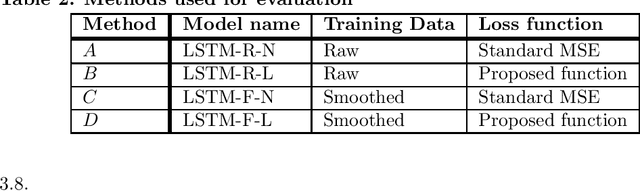
COVID-19 continues to cause a significant impact on public health. To minimize this impact, policy makers undertake containment measures that however, when carried out disproportionately to the actual threat, as a result if errorneous threat assessment, cause undesirable long-term socio-economic complications. In addition, macro-level or national level decision making fails to consider the localized sensitivities in small regions. Hence, the need arises for region-wise threat assessments that provide insights on the behaviour of COVID-19 through time, enabled through accurate forecasts. In this study, a forecasting solution is proposed, to predict daily new cases of COVID-19 in regions small enough where containment measures could be locally implemented, by targeting three main shortcomings that exist in literature; the unreliability of existing data caused by inconsistent testing patterns in smaller regions, weak deploy-ability of forecasting models towards predicting cases in previously unseen regions, and model training biases caused by the imbalanced nature of data in COVID-19 epi-curves. Hence, the contributions of this study are three-fold; an optimized smoothing technique to smoothen less deterministic epi-curves based on epidemiological dynamics of that region, a Long-Short-Term-Memory (LSTM) based forecasting model trained using data from select regions to create a representative and diverse training set that maximizes deploy-ability in regions with lack of historical data, and an adaptive loss function whilst training to mitigate the data imbalances seen in epi-curves. The proposed smoothing technique, the generalized training strategy and the adaptive loss function largely increased the overall accuracy of the forecast, which enables efficient containment measures at a more localized micro-level.
An Optical physics inspired CNN approach for intrinsic image decomposition
May 21, 2021

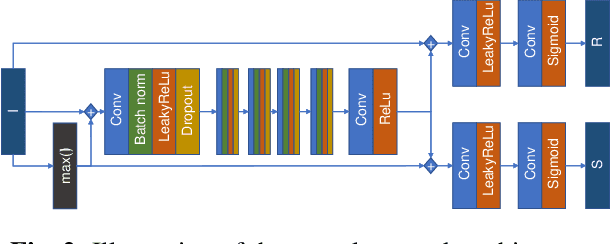

Intrinsic Image Decomposition is an open problem of generating the constituents of an image. Generating reflectance and shading from a single image is a challenging task specifically when there is no ground truth. There is a lack of unsupervised learning approaches for decomposing an image into reflectance and shading using a single image. We propose a neural network architecture capable of this decomposition using physics-based parameters derived from the image. Through experimental results, we show that (a) the proposed methodology outperforms the existing deep learning-based IID techniques and (b) the derived parameters improve the efficacy significantly. We conclude with a closer analysis of the results (numerical and example images) showing several avenues for improvement.
A Retinex based GAN Pipeline to Utilize Paired and Unpaired Datasets for Enhancing Low Light Images
Jun 27, 2020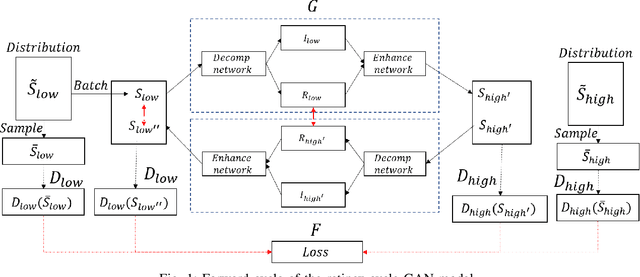
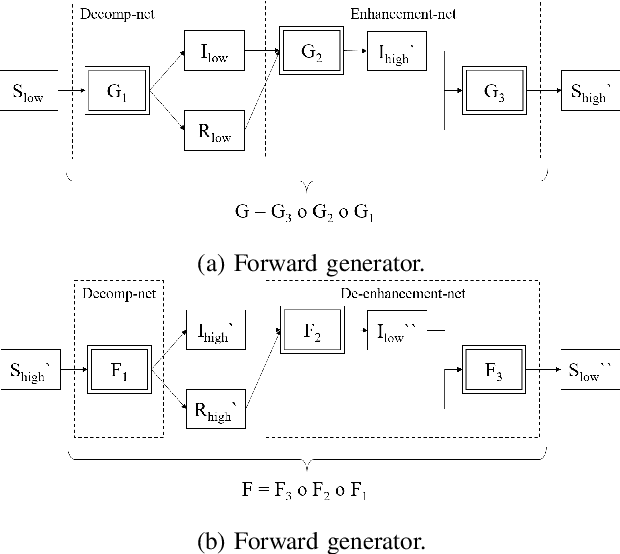
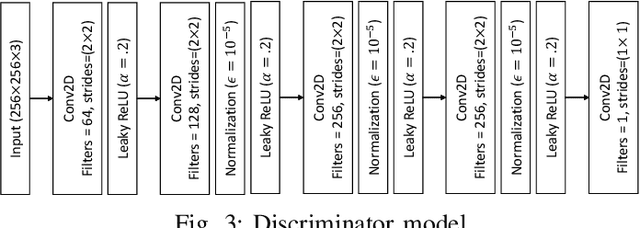

Low light image enhancement is an important challenge for the development of robust computer vision algorithms. The machine learning approaches to this have been either unsupervised, supervised based on paired dataset or supervised based on unpaired dataset. This paper presents a novel deep learning pipeline that can learn from both paired and unpaired datasets. Convolution Neural Networks (CNNs) that are optimized to minimize standard loss, and Generative Adversarial Networks (GANs) that are optimized to minimize the adversarial loss are used to achieve different steps of the low light image enhancement process. Cycle consistency loss and a patched discriminator are utilized to further improve the performance. The paper also analyses the functionality and the performance of different components, hidden layers, and the entire pipeline.
Non-contact Infant Sleep Apnea Detection
Oct 10, 2019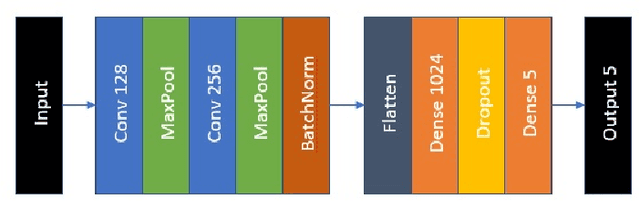
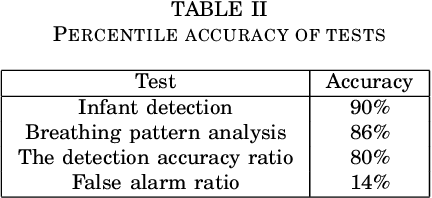
Sleep apnea is a breathing disorder where a person repeatedly stops breathing in sleep. Early detection is crucial for infants because it might bring long term adversities. The existing accurate detection mechanism (pulse oximetry) is a skin contact measurement. The existing non-contact mechanisms (acoustics, video processing) are not accurate enough. This paper presents a novel algorithm for the detection of sleep apnea with video processing. The solution is non-contact, accurate and lightweight enough to run on a single board computer. The paper discusses the accuracy of the algorithm on real data, advantages of the new algorithm, its limitations and suggests future improvements.