 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeNet 2.0: More Productive End-to-End Speech Recognition Toolkit
Mar 29, 2022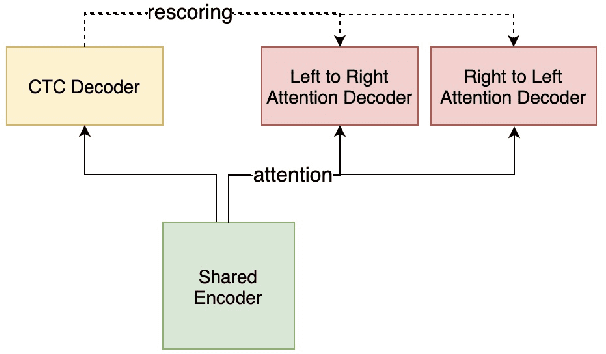


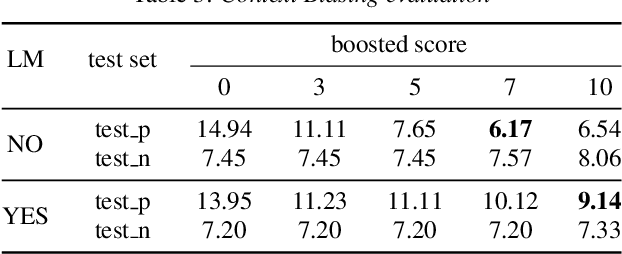
Recently, we made available WeNet, a production-oriented end-to-end speech recognition toolkit, which introduces a unified two-pass (U2) framework and a built-in runtime to address the streaming and non-streaming decoding modes in a single model. To further improve ASR performance and facilitate various production requirements, in this paper, we present WeNet 2.0 with four important updates. (1) We propose U2++, a unified two-pass framework with bidirectional attention decoders, which includes the future contextual information by a right-to-left attention decoder to improve the representative ability of the shared encoder and the performance during the rescoring stage. (2) We introduce an n-gram based language model and a WFST-based decoder into WeNet 2.0, promoting the use of rich text data in production scenarios. (3) We design a unified contextual biasing framework, which leverages user-specific context (e.g., contact lists) to provide rapid adaptation ability for production and improves ASR accuracy in both with-LM and without-LM scenarios. (4) We design a unified IO to support large-scale data for effective model training. In summary, the brand-new WeNet 2.0 achieves up to 10\% relative recognition performance improvement over the original WeNet on various corpora and makes available several important production-oriented features.
WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition
Oct 18, 2021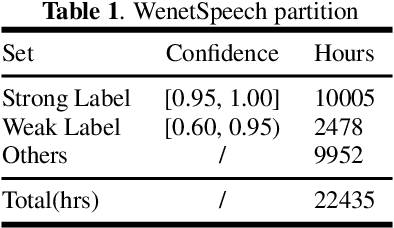

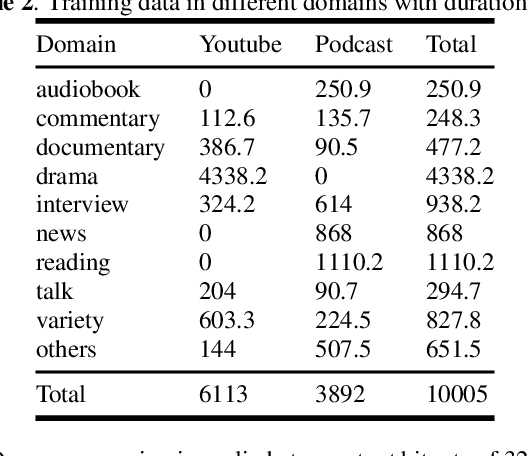
In this paper, we present WenetSpeech, a multi-domain Mandarin corpus consisting of 10000+ hours high-quality labeled speech, 2400+ hours weakly labeled speech, and about 10000 hours unlabeled speech, with 22400+ hours in total. We collect the data from YouTube and Podcast, which covers a variety of speaking styles, scenarios, domains, topics, and noisy conditions. An optical character recognition (OCR) based method is introduced to generate the audio/text segmentation candidates for the YouTube data on its corresponding video captions, while a high-quality ASR transcription system is used to generate audio/text pair candidates for the Podcast data. Then we propose a novel end-to-end label error detection approach to further validate and filter the candidates. We also provide three manually labelled high-quality test sets along with WenetSpeech for evaluation -- Dev for cross-validation purpose in training, Test_Net, collected from Internet for matched test, and Test\_Meeting, recorded from real meetings for more challenging mismatched test. Baseline systems trained with WenetSpeech are provided for three popular speech recognition toolkits, namely Kaldi, ESPnet, and WeNet, and recognition results on the three test sets are also provided as benchmarks. To the best of our knowledge, WenetSpeech is the current largest open-sourced Mandarin speech corpus with transcriptions, which benefits research on production-level speech recognition.
An Asynchronous WFST-Based Decoder For Automatic Speech Recognition
Mar 16, 2021
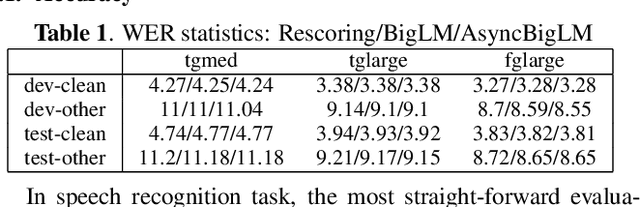
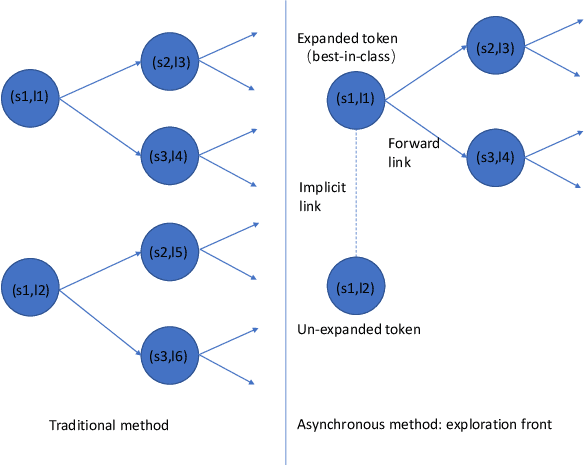
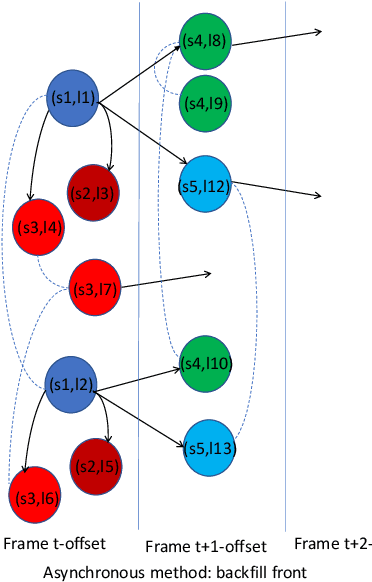
We introduce asynchronous dynamic decoder, which adopts an efficient A* algorithm to incorporate big language models in the one-pass decoding for large vocabulary continuous speech recognition. Unlike standard one-pass decoding with on-the-fly composition decoder which might induce a significant computation overhead, the asynchronous dynamic decoder has a novel design where it has two fronts, with one performing "exploration" and the other "backfill". The computation of the two fronts alternates in the decoding process, resulting in more effective pruning than the standard one-pass decoding with an on-the-fly composition decoder. Experiments show that the proposed decoder works notably faster than the standard one-pass decoding with on-the-fly composition decoder, while the acceleration will be more obvious with the increment of data complexity.
Wake Word Detection with Streaming Transformers
Feb 08, 2021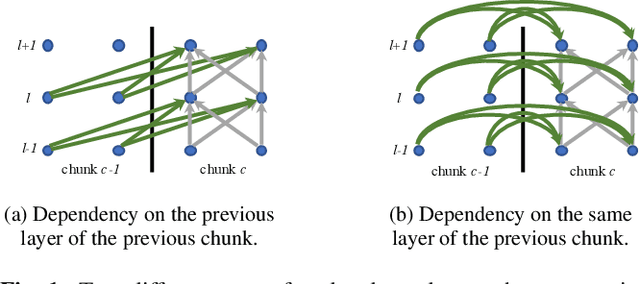
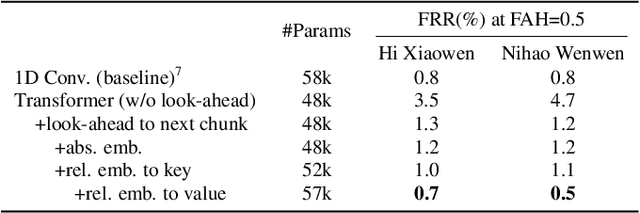
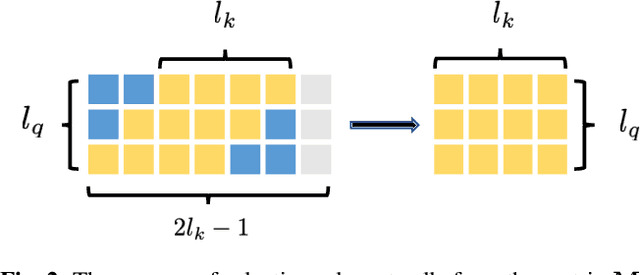
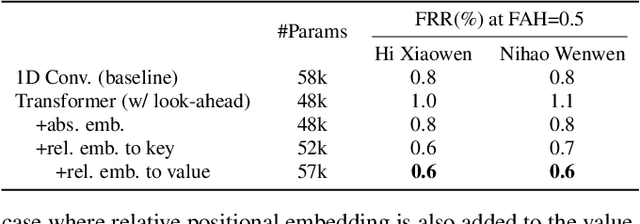
Modern wake word detection systems usually rely on neural networks for acoustic modeling. Transformers has recently shown superior performance over LSTM and convolutional networks in various sequence modeling tasks with their better temporal modeling power. However it is not clear whether this advantage still holds for short-range temporal modeling like wake word detection. Besides, the vanilla Transformer is not directly applicable to the task due to its non-streaming nature and the quadratic time and space complexity. In this paper we explore the performance of several variants of chunk-wise streaming Transformers tailored for wake word detection in a recently proposed LF-MMI system, including looking-ahead to the next chunk, gradient stopping, different positional embedding methods and adding same-layer dependency between chunks. Our experiments on the Mobvoi wake word dataset demonstrate that our proposed Transformer model outperforms the baseline convolution network by 25% on average in false rejection rate at the same false alarm rate with a comparable model size, while still maintaining linear complexity w.r.t. the sequence length.
Wake Word Detection with Alignment-Free Lattice-Free MMI
May 25, 2020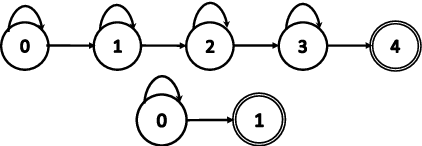
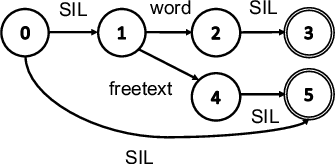

Always-on spoken language interfaces, e.g. personal digital assistants, rely on a wake word to start processing spoken input. We present novel methods to train a hybrid DNN/HMM wake word detection system from partially labeled training data, and to use it in on-line applications: (i) we remove the prerequisite of frame-level alignments in the LF-MMI training algorithm, permitting the use of un-transcribed training examples that are annotated only for the presence/absence of the wake word; (ii) we show that the classical keyword/filler model must be supplemented with an explicit non-speech (silence) model for good performance; (iii) we present an FST-based decoder to perform online detection. We evaluate our methods on two real data sets, showing 50%--90% reduction in false rejection rates at pre-specified false alarm rates over the best previously published figures, and re-validate them on a third (large) data set.
Espresso: A Fast End-to-end Neural Speech Recognition Toolkit
Oct 15, 2019
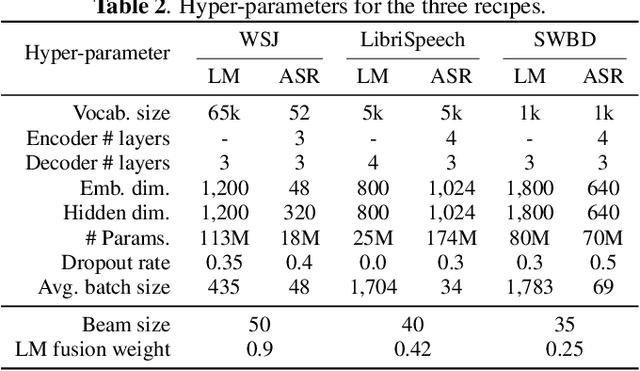
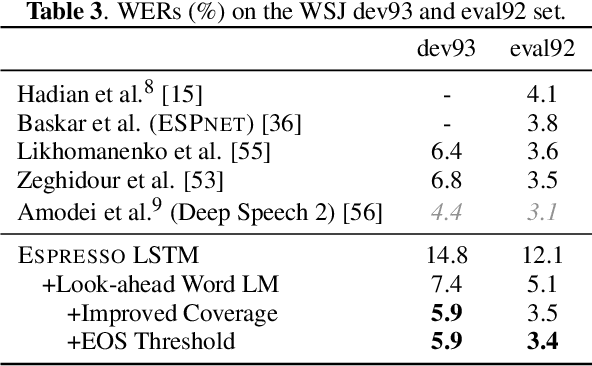
We present Espresso, an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit based on the deep learning library PyTorch and the popular neural machine translation toolkit fairseq. Espresso supports distributed training across GPUs and computing nodes, and features various decoding approaches commonly employed in ASR, including look-ahead word-based language model fusion, for which a fast, parallelized decoder is implemented. Espresso achieves state-of-the-art ASR performance on the WSJ, LibriSpeech, and Switchboard data sets among other end-to-end systems without data augmentation, and is 4--11x faster for decoding than similar systems (e.g. ESPnet).