 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBANMo: Building Animatable 3D Neural Models from Many Casual Videos
Dec 24, 2021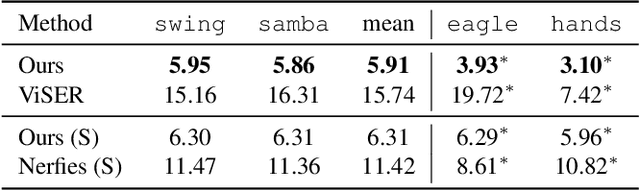
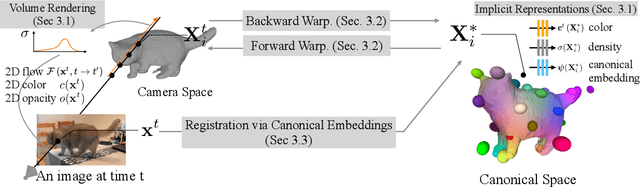

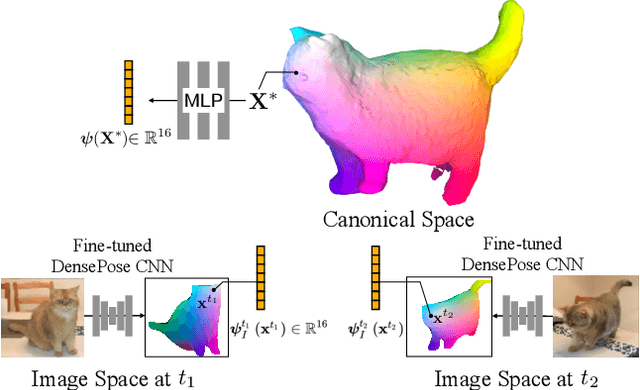
Prior work for articulated 3D shape reconstruction often relies on specialized sensors (e.g., synchronized multi-camera systems), or pre-built 3D deformable models (e.g., SMAL or SMPL). Such methods are not able to scale to diverse sets of objects in the wild. We present BANMo, a method that requires neither a specialized sensor nor a pre-defined template shape. BANMo builds high-fidelity, articulated 3D models (including shape and animatable skinning weights) from many monocular casual videos in a differentiable rendering framework. While the use of many videos provides more coverage of camera views and object articulations, they introduce significant challenges in establishing correspondence across scenes with different backgrounds, illumination conditions, etc. Our key insight is to merge three schools of thought; (1) classic deformable shape models that make use of articulated bones and blend skinning, (2) volumetric neural radiance fields (NeRFs) that are amenable to gradient-based optimization, and (3) canonical embeddings that generate correspondences between pixels and an articulated model. We introduce neural blend skinning models that allow for differentiable and invertible articulated deformations. When combined with canonical embeddings, such models allow us to establish dense correspondences across videos that can be self-supervised with cycle consistency. On real and synthetic datasets, BANMo shows higher-fidelity 3D reconstructions than prior works for humans and animals, with the ability to render realistic images from novel viewpoints and poses. Project webpage: banmo-www.github.io .
Modeling human intention inference in continuous 3D domains by inverse planning and body kinematics
Dec 02, 2021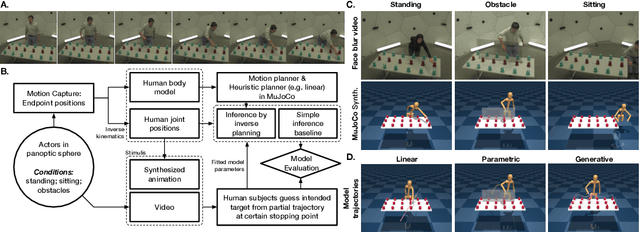
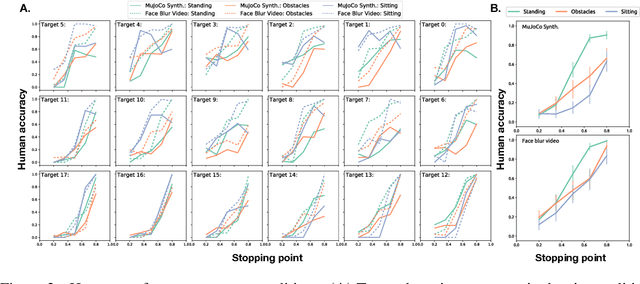
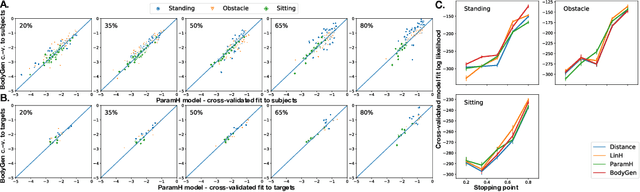
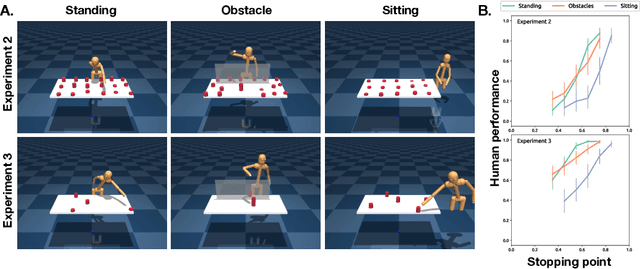
How to build AI that understands human intentions, and uses this knowledge to collaborate with people? We describe a computational framework for evaluating models of goal inference in the domain of 3D motor actions, which receives as input the 3D coordinates of an agent's body, and of possible targets, to produce a continuously updated inference of the intended target. We evaluate our framework in three behavioural experiments using a novel Target Reaching Task, in which human observers infer intentions of actors reaching for targets among distracts. We describe Generative Body Kinematics model, which predicts human intention inference in this domain using Bayesian inverse planning and inverse body kinematics. We compare our model to three heuristics, which formalize the principle of least effort using simple assumptions about the actor's constraints, without the use of inverse planning. Despite being more computationally costly, the Generative Body Kinematics model outperforms the heuristics in certain scenarios, such as environments with obstacles, and at the beginning of reaching actions while the actor is relatively far from the intended target. The heuristics make increasingly accurate predictions during later stages of reaching actions, such as, when the intended target is close, and can be inferred by extrapolating the wrist trajectory. Our results identify contexts in which inverse body kinematics is useful for intention inference. We show that human observers indeed rely on inverse body kinematics in such scenarios, suggesting that modeling body kinematic can improve performance of inference algorithms.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
D3D-HOI: Dynamic 3D Human-Object Interactions from Videos
Aug 19, 2021

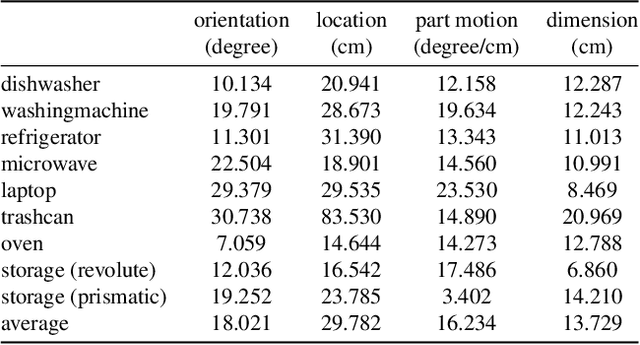

We introduce D3D-HOI: a dataset of monocular videos with ground truth annotations of 3D object pose, shape and part motion during human-object interactions. Our dataset consists of several common articulated objects captured from diverse real-world scenes and camera viewpoints. Each manipulated object (e.g., microwave oven) is represented with a matching 3D parametric model. This data allows us to evaluate the reconstruction quality of articulated objects and establish a benchmark for this challenging task. In particular, we leverage the estimated 3D human pose for more accurate inference of the object spatial layout and dynamics. We evaluate this approach on our dataset, demonstrating that human-object relations can significantly reduce the ambiguity of articulated object reconstructions from challenging real-world videos. Code and dataset are available at https://github.com/facebookresearch/d3d-hoi.
FrankMocap: A Monocular 3D Whole-Body Pose Estimation System via Regression and Integration
Aug 13, 2021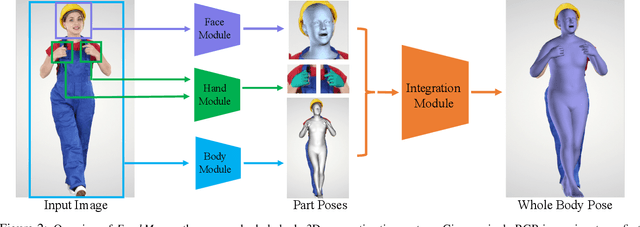
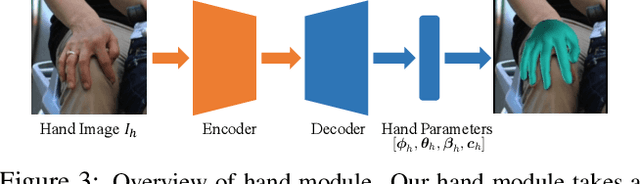

Most existing monocular 3D pose estimation approaches only focus on a single body part, neglecting the fact that the essential nuance of human motion is conveyed through a concert of subtle movements of face, hands, and body. In this paper, we present FrankMocap, a fast and accurate whole-body 3D pose estimation system that can produce 3D face, hands, and body simultaneously from in-the-wild monocular images. The core idea of FrankMocap is its modular design: We first run 3D pose regression methods for face, hands, and body independently, followed by composing the regression outputs via an integration module. The separate regression modules allow us to take full advantage of their state-of-the-art performances without compromising the original accuracy and reliability in practice. We develop three different integration modules that trade off between latency and accuracy. All of them are capable of providing simple yet effective solutions to unify the separate outputs into seamless whole-body pose estimation results. We quantitatively and qualitatively demonstrate that our modularized system outperforms both the optimization-based and end-to-end methods of estimating whole-body pose.
3D Multi-bodies: Fitting Sets of Plausible 3D Human Models to Ambiguous Image Data
Nov 02, 2020

We consider the problem of obtaining dense 3D reconstructions of humans from single and partially occluded views. In such cases, the visual evidence is usually insufficient to identify a 3D reconstruction uniquely, so we aim at recovering several plausible reconstructions compatible with the input data. We suggest that ambiguities can be modelled more effectively by parametrizing the possible body shapes and poses via a suitable 3D model, such as SMPL for humans. We propose to learn a multi-hypothesis neural network regressor using a best-of-M loss, where each of the M hypotheses is constrained to lie on a manifold of plausible human poses by means of a generative model. We show that our method outperforms alternative approaches in ambiguous pose recovery on standard benchmarks for 3D humans, and in heavily occluded versions of these benchmarks.
Perceiving 3D Human-Object Spatial Arrangements from a Single Image in the Wild
Aug 19, 2020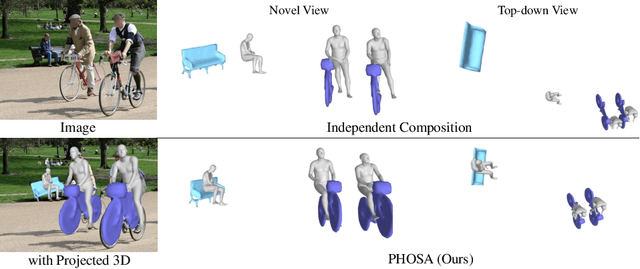
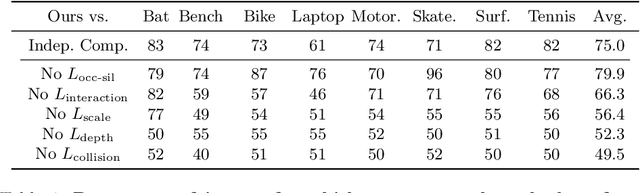
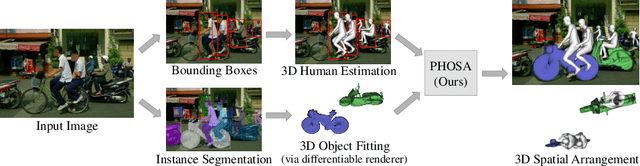
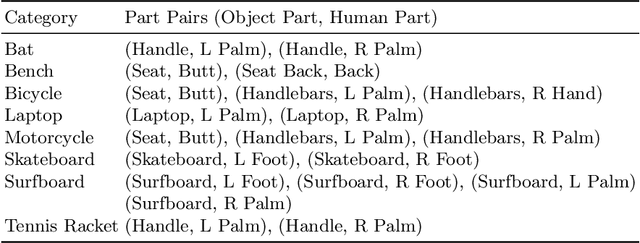
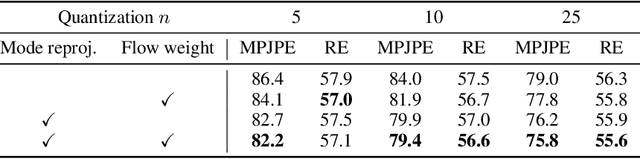
We present a method that infers spatial arrangements and shapes of humans and objects in a globally consistent 3D scene, all from a single image in-the-wild captured in an uncontrolled environment. Notably, our method runs on datasets without any scene- or object-level 3D supervision. Our key insight is that considering humans and objects jointly gives rise to "3D common sense" constraints that can be used to resolve ambiguity. In particular, we introduce a scale loss that learns the distribution of object size from data; an occlusion-aware silhouette re-projection loss to optimize object pose; and a human-object interaction loss to capture the spatial layout of objects with which humans interact. We empirically validate that our constraints dramatically reduce the space of likely 3D spatial configurations. We demonstrate our approach on challenging, in-the-wild images of humans interacting with large objects (such as bicycles, motorcycles, and surfboards) and handheld objects (such as laptops, tennis rackets, and skateboards). We quantify the ability of our approach to recover human-object arrangements and outline remaining challenges in this relatively domain. The project webpage can be found at https://jasonyzhang.com/phosa.
FrankMocap: Fast Monocular 3D Hand and Body Motion Capture by Regression and Integration
Aug 19, 2020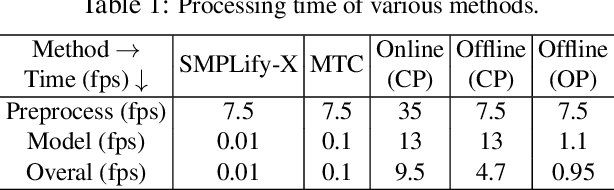
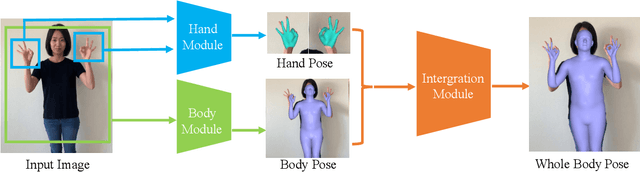
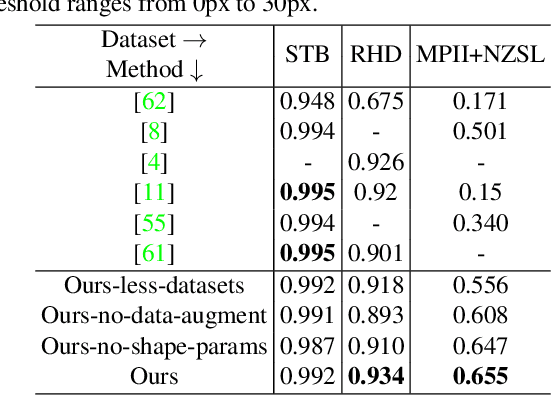
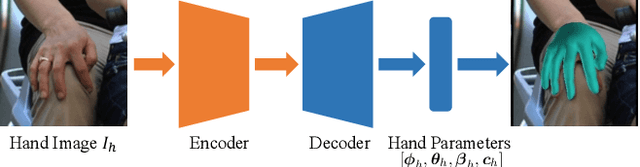
Although the essential nuance of human motion is often conveyed as a combination of body movements and hand gestures, the existing monocular motion capture approaches mostly focus on either body motion capture only ignoring hand parts or hand motion capture only without considering body motion. In this paper, we present FrankMocap, a motion capture system that can estimate both 3D hand and body motion from in-the-wild monocular inputs with faster speed (9.5 fps) and better accuracy than previous work. Our method works in near real-time (9.5 fps) and produces 3D body and hand motion capture outputs as a unified parametric model structure. Our method aims to capture 3D body and hand motion simultaneously from challenging in-the-wild monocular videos. To construct FrankMocap, we build the state-of-the-art monocular 3D "hand" motion capture method by taking the hand part of the whole body parametric model (SMPL-X). Our 3D hand motion capture output can be efficiently integrated to monocular body motion capture output, producing whole body motion results in a unified parrametric model structure. We demonstrate the state-of-the-art performance of our hand motion capture system in public benchmarks, and show the high quality of our whole body motion capture result in various challenging real-world scenes, including a live demo scenario.
Body2Hands: Learning to Infer 3D Hands from Conversational Gesture Body Dynamics
Jul 23, 2020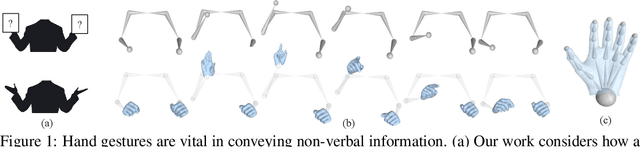
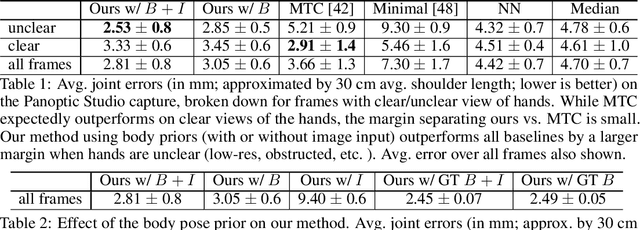
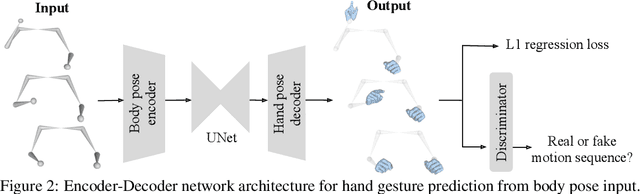
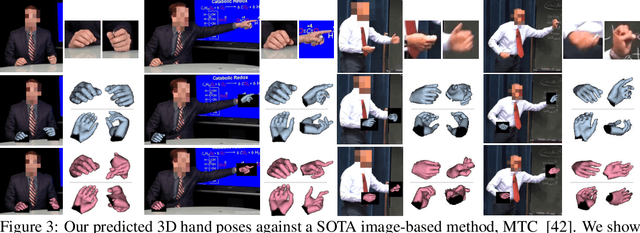
We propose a novel learned deep prior of body motion for 3D hand shape synthesis and estimation in the domain of conversational gestures. Our model builds upon the insight that body motion and hand gestures are strongly correlated in non-verbal communication settings. We formulate the learning of this prior as a prediction task of 3D hand shape over time given body motion input alone. Trained with 3D pose estimations obtained from a large-scale dataset of internet videos, our hand prediction model produces convincing 3D hand gestures given only the 3D motion of the speaker's arms as input. We demonstrate the efficacy of our method on hand gesture synthesis from body motion input, and as a strong body prior for single-view image-based 3D hand pose estimation. We demonstrate that our method outperforms previous state-of-the-art approaches and can generalize beyond the monologue-based training data to multi-person conversations. Video results are available at http://people.eecs.berkeley.edu/~evonne_ng/projects/body2hands/.
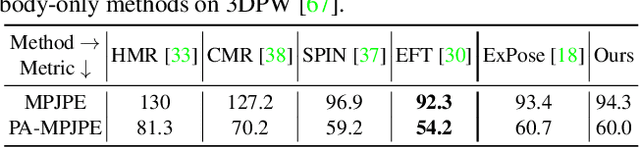
Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation
Apr 07, 2020

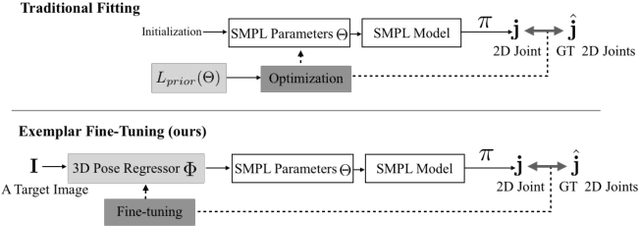
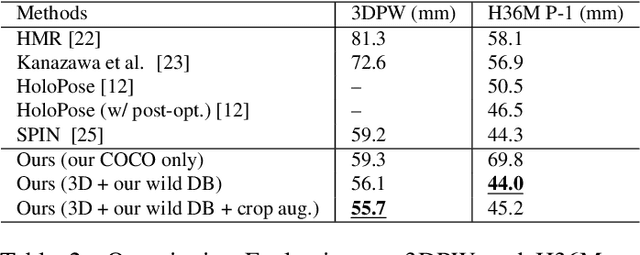
We propose a method for building large collections of human poses with full 3D annotations captured `in the wild', for which specialized capture equipment cannot be used. We start with a dataset with 2D keypoint annotations such as COCO and MPII and generates corresponding 3D poses. This is done via Exemplar Fine-Tuning (EFT), a new method to fit a 3D parametric model to 2D keypoints. EFT is accurate and can exploit a data-driven pose prior to resolve the depth reconstruction ambiguity that comes from using only 2D observations as input. We use EFT to augment these large in-the-wild datasets with plausible and accurate 3D pose annotations. We then use this data to strongly supervise a 3D pose regression network, achieving state-of-the-art results in standard benchmarks, including the ones collected outdoor. This network also achieves unprecedented 3D pose estimation quality on extremely challenging Internet videos.