 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Algorithm Emulation in Fixed-Weight Transformers
Aug 24, 2025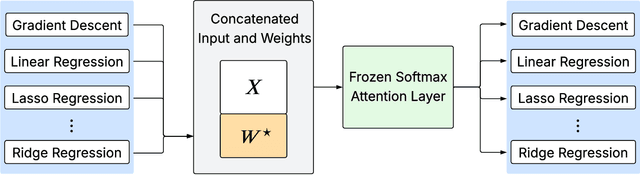
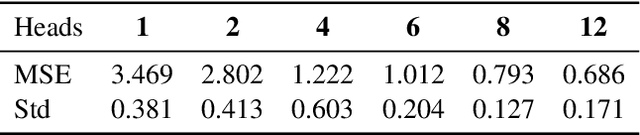
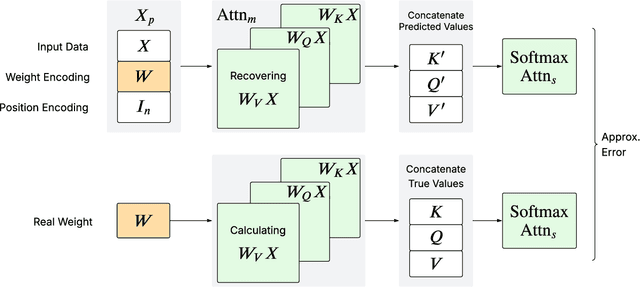

We prove that a minimal Transformer architecture with frozen weights is capable of emulating a broad class of algorithms by in-context prompting. In particular, for any algorithm implementable by a fixed-weight attention head (e.g. one-step gradient descent or linear/ridge regression), there exists a prompt that drives a two-layer softmax attention module to reproduce the algorithm's output with arbitrary precision. This guarantee extends even to a single-head attention layer (using longer prompts if necessary), achieving architectural minimality. Our key idea is to construct prompts that encode an algorithm's parameters into token representations, creating sharp dot-product gaps that force the softmax attention to follow the intended computation. This construction requires no feed-forward layers and no parameter updates. All adaptation happens through the prompt alone. These findings forge a direct link between in-context learning and algorithmic emulation, and offer a simple mechanism for large Transformers to serve as prompt-programmable libraries of algorithms. They illuminate how GPT-style foundation models may swap algorithms via prompts alone, establishing a form of algorithmic universality in modern Transformer models.
Evo-MARL: Co-Evolutionary Multi-Agent Reinforcement Learning for Internalized Safety
Aug 05, 2025


Multi-agent systems (MAS) built on multimodal large language models exhibit strong collaboration and performance. However, their growing openness and interaction complexity pose serious risks, notably jailbreak and adversarial attacks. Existing defenses typically rely on external guard modules, such as dedicated safety agents, to handle unsafe behaviors. Unfortunately, this paradigm faces two challenges: (1) standalone agents offer limited protection, and (2) their independence leads to single-point failure-if compromised, system-wide safety collapses. Naively increasing the number of guard agents further raises cost and complexity. To address these challenges, we propose Evo-MARL, a novel multi-agent reinforcement learning (MARL) framework that enables all task agents to jointly acquire defensive capabilities. Rather than relying on external safety modules, Evo-MARL trains each agent to simultaneously perform its primary function and resist adversarial threats, ensuring robustness without increasing system overhead or single-node failure. Furthermore, Evo-MARL integrates evolutionary search with parameter-sharing reinforcement learning to co-evolve attackers and defenders. This adversarial training paradigm internalizes safety mechanisms and continually enhances MAS performance under co-evolving threats. Experiments show that Evo-MARL reduces attack success rates by up to 22% while boosting accuracy by up to 5% on reasoning tasks-demonstrating that safety and utility can be jointly improved.
Spatial Mental Modeling from Limited Views
Jun 26, 2025



Can Vision Language Models (VLMs) imagine the full scene from just a few views, like humans do? Humans form spatial mental models, internal representations of unseen space, to reason about layout, perspective, and motion. Our new MindCube benchmark with 21,154 questions across 3,268 images exposes this critical gap, where existing VLMs exhibit near-random performance. Using MindCube, we systematically evaluate how well VLMs build robust spatial mental models through representing positions (cognitive mapping), orientations (perspective-taking), and dynamics (mental simulation for "what-if" movements). We then explore three approaches to help VLMs approximate spatial mental models, including unseen intermediate views, natural language reasoning chains, and cognitive maps. The significant improvement comes from a synergistic approach, "map-then-reason", that jointly trains the model to first generate a cognitive map and then reason upon it. By training models to reason over these internal maps, we boosted accuracy from 37.8% to 60.8% (+23.0%). Adding reinforcement learning pushed performance even further to 70.7% (+32.9%). Our key insight is that such scaffolding of spatial mental models, actively constructing and utilizing internal structured spatial representations with flexible reasoning processes, significantly improves understanding of unobservable space.
KEPLA: A Knowledge-Enhanced Deep Learning Framework for Accurate Protein-Ligand Binding Affinity Prediction
Jun 16, 2025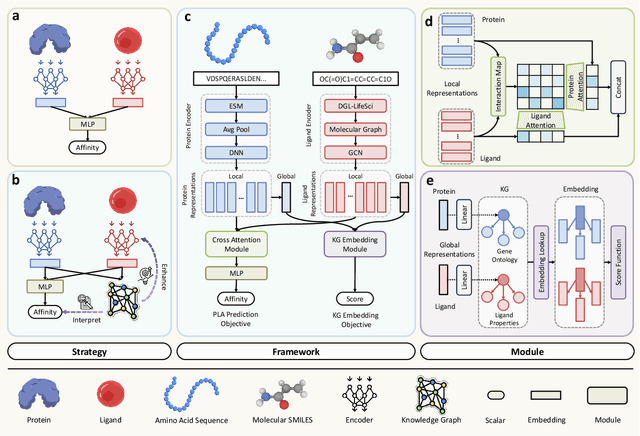
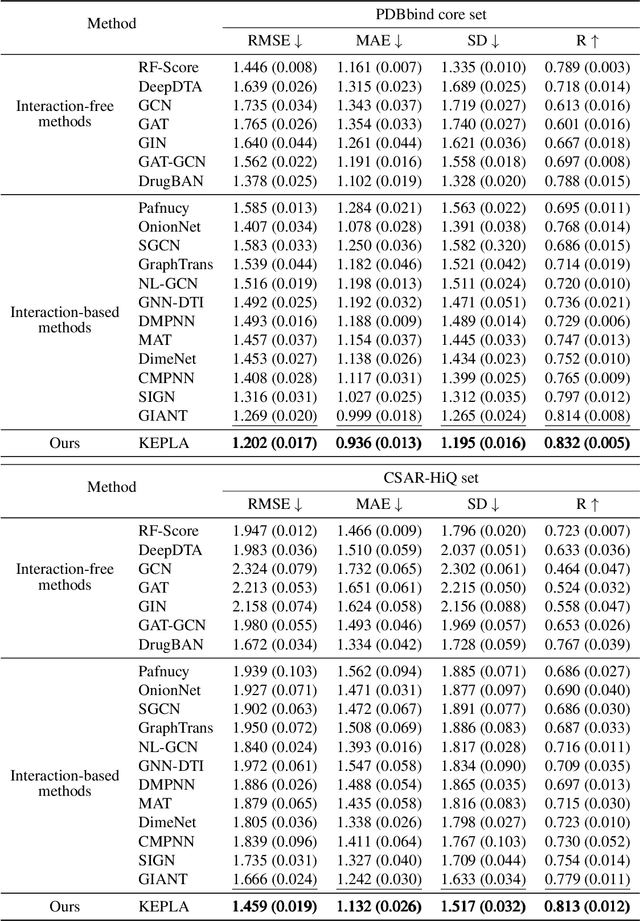
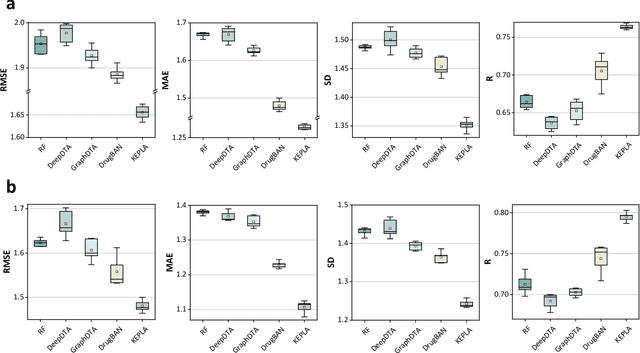
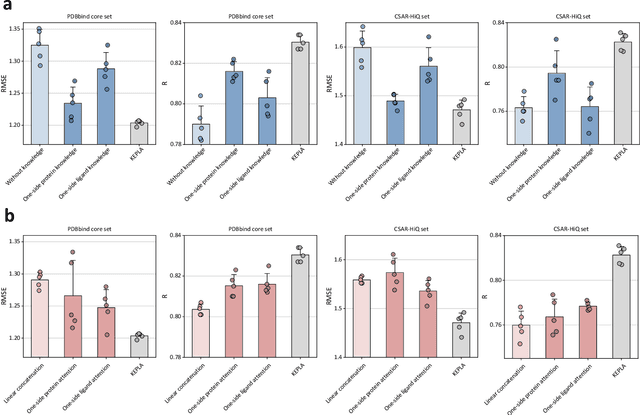
Accurate prediction of protein-ligand binding affinity is critical for drug discovery. While recent deep learning approaches have demonstrated promising results, they often rely solely on structural features, overlooking valuable biochemical knowledge associated with binding affinity. To address this limitation, we propose KEPLA, a novel deep learning framework that explicitly integrates prior knowledge from Gene Ontology and ligand properties of proteins and ligands to enhance prediction performance. KEPLA takes protein sequences and ligand molecular graphs as input and optimizes two complementary objectives: (1) aligning global representations with knowledge graph relations to capture domain-specific biochemical insights, and (2) leveraging cross attention between local representations to construct fine-grained joint embeddings for prediction. Experiments on two benchmark datasets across both in-domain and cross-domain scenarios demonstrate that KEPLA consistently outperforms state-of-the-art baselines. Furthermore, interpretability analyses based on knowledge graph relations and cross attention maps provide valuable insights into the underlying predictive mechanisms.
Cross-Domain Conditional Diffusion Models for Time Series Imputation
Jun 14, 2025Cross-domain time series imputation is an underexplored data-centric research task that presents significant challenges, particularly when the target domain suffers from high missing rates and domain shifts in temporal dynamics. Existing time series imputation approaches primarily focus on the single-domain setting, which cannot effectively adapt to a new domain with domain shifts. Meanwhile, conventional domain adaptation techniques struggle with data incompleteness, as they typically assume the data from both source and target domains are fully observed to enable adaptation. For the problem of cross-domain time series imputation, missing values introduce high uncertainty that hinders distribution alignment, making existing adaptation strategies ineffective. Specifically, our proposed solution tackles this problem from three perspectives: (i) Data: We introduce a frequency-based time series interpolation strategy that integrates shared spectral components from both domains while retaining domain-specific temporal structures, constructing informative priors for imputation. (ii) Model: We design a diffusion-based imputation model that effectively learns domain-shared representations and captures domain-specific temporal dependencies with dedicated denoising networks. (iii) Algorithm: We further propose a cross-domain consistency alignment strategy that selectively regularizes output-level domain discrepancies, enabling effective knowledge transfer while preserving domain-specific characteristics. Extensive experiments on three real-world datasets demonstrate the superiority of our proposed approach. Our code implementation is available here.
crossMoDA Challenge: Evolution of Cross-Modality Domain Adaptation Techniques for Vestibular Schwannoma and Cochlea Segmentation from 2021 to 2023
Jun 13, 2025The cross-Modality Domain Adaptation (crossMoDA) challenge series, initiated in 2021 in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), focuses on unsupervised cross-modality segmentation, learning from contrast-enhanced T1 (ceT1) and transferring to T2 MRI. The task is an extreme example of domain shift chosen to serve as a meaningful and illustrative benchmark. From a clinical application perspective, it aims to automate Vestibular Schwannoma (VS) and cochlea segmentation on T2 scans for more cost-effective VS management. Over time, the challenge objectives have evolved to enhance its clinical relevance. The challenge evolved from using single-institutional data and basic segmentation in 2021 to incorporating multi-institutional data and Koos grading in 2022, and by 2023, it included heterogeneous routine data and sub-segmentation of intra- and extra-meatal tumour components. In this work, we report the findings of the 2022 and 2023 editions and perform a retrospective analysis of the challenge progression over the years. The observations from the successive challenge contributions indicate that the number of outliers decreases with an expanding dataset. This is notable since the diversity of scanning protocols of the datasets concurrently increased. The winning approach of the 2023 edition reduced the number of outliers on the 2021 and 2022 testing data, demonstrating how increased data heterogeneity can enhance segmentation performance even on homogeneous data. However, the cochlea Dice score declined in 2023, likely due to the added complexity from tumour sub-annotations affecting overall segmentation performance. While progress is still needed for clinically acceptable VS segmentation, the plateauing performance suggests that a more challenging cross-modal task may better serve future benchmarking.
Minimalist Softmax Attention Provably Learns Constrained Boolean Functions
May 26, 2025We study the computational limits of learning $k$-bit Boolean functions (specifically, $\mathrm{AND}$, $\mathrm{OR}$, and their noisy variants), using a minimalist single-head softmax-attention mechanism, where $k=\Theta(d)$ relevant bits are selected from $d$ inputs. We show that these simple $\mathrm{AND}$ and $\mathrm{OR}$ functions are unsolvable with a single-head softmax-attention mechanism alone. However, with teacher forcing, the same minimalist attention is capable of solving them. These findings offer two key insights: Architecturally, solving these Boolean tasks requires only minimalist attention, without deep Transformer blocks or FFNs. Methodologically, one gradient descent update with supervision suffices and replaces the multi-step Chain-of-Thought (CoT) reasoning scheme of [Kim and Suzuki, ICLR 2025] for solving Boolean problems. Together, the bounds expose a fundamental gap between what this minimal architecture achieves under ideal supervision and what is provably impossible under standard training.
Surrogate Signals from Format and Length: Reinforcement Learning for Solving Mathematical Problems without Ground Truth Answers
May 26, 2025Large Language Models have achieved remarkable success in natural language processing tasks, with Reinforcement Learning playing a key role in adapting them to specific applications. However, obtaining ground truth answers for training LLMs in mathematical problem-solving is often challenging, costly, and sometimes unfeasible. This research delves into the utilization of format and length as surrogate signals to train LLMs for mathematical problem-solving, bypassing the need for traditional ground truth answers.Our study shows that a reward function centered on format correctness alone can yield performance improvements comparable to the standard GRPO algorithm in early phases. Recognizing the limitations of format-only rewards in the later phases, we incorporate length-based rewards. The resulting GRPO approach, leveraging format-length surrogate signals, not only matches but surpasses the performance of the standard GRPO algorithm relying on ground truth answers in certain scenarios, achieving 40.0\% accuracy on AIME2024 with a 7B base model. Through systematic exploration and experimentation, this research not only offers a practical solution for training LLMs to solve mathematical problems and reducing the dependence on extensive ground truth data collection, but also reveals the essence of why our label-free approach succeeds: base model is like an excellent student who has already mastered mathematical and logical reasoning skills, but performs poorly on the test paper, it simply needs to develop good answering habits to achieve outstanding results in exams , in other words, to unlock the capabilities it already possesses.
A Survey of Large Language Models for Text-Guided Molecular Discovery: from Molecule Generation to Optimization
May 22, 2025Large language models (LLMs) are introducing a paradigm shift in molecular discovery by enabling text-guided interaction with chemical spaces through natural language, symbolic notations, with emerging extensions to incorporate multi-modal inputs. To advance the new field of LLM for molecular discovery, this survey provides an up-to-date and forward-looking review of the emerging use of LLMs for two central tasks: molecule generation and molecule optimization. Based on our proposed taxonomy for both problems, we analyze representative techniques in each category, highlighting how LLM capabilities are leveraged across different learning settings. In addition, we include the commonly used datasets and evaluation protocols. We conclude by discussing key challenges and future directions, positioning this survey as a resource for researchers working at the intersection of LLMs and molecular science. A continuously updated reading list is available at https://github.com/REAL-Lab-NU/Awesome-LLM-Centric-Molecular-Discovery.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.