 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHART: Efficient Visual Generation with Hybrid Autoregressive Transformer
Oct 14, 2024



We introduce Hybrid Autoregressive Transformer (HART), an autoregressive (AR) visual generation model capable of directly generating 1024x1024 images, rivaling diffusion models in image generation quality. Existing AR models face limitations due to the poor image reconstruction quality of their discrete tokenizers and the prohibitive training costs associated with generating 1024px images. To address these challenges, we present the hybrid tokenizer, which decomposes the continuous latents from the autoencoder into two components: discrete tokens representing the big picture and continuous tokens representing the residual components that cannot be represented by the discrete tokens. The discrete component is modeled by a scalable-resolution discrete AR model, while the continuous component is learned with a lightweight residual diffusion module with only 37M parameters. Compared with the discrete-only VAR tokenizer, our hybrid approach improves reconstruction FID from 2.11 to 0.30 on MJHQ-30K, leading to a 31% generation FID improvement from 7.85 to 5.38. HART also outperforms state-of-the-art diffusion models in both FID and CLIP score, with 4.5-7.7x higher throughput and 6.9-13.4x lower MACs. Our code is open sourced at https://github.com/mit-han-lab/hart.
Condition-Aware Neural Network for Controlled Image Generation
Apr 01, 2024



We present Condition-Aware Neural Network (CAN), a new method for adding control to image generative models. In parallel to prior conditional control methods, CAN controls the image generation process by dynamically manipulating the weight of the neural network. This is achieved by introducing a condition-aware weight generation module that generates conditional weight for convolution/linear layers based on the input condition. We test CAN on class-conditional image generation on ImageNet and text-to-image generation on COCO. CAN consistently delivers significant improvements for diffusion transformer models, including DiT and UViT. In particular, CAN combined with EfficientViT (CaT) achieves 2.78 FID on ImageNet 512x512, surpassing DiT-XL/2 while requiring 52x fewer MACs per sampling step.
DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Mar 07, 2024



Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naively implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1$\times$ speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
EfficientViT-SAM: Accelerated Segment Anything Model Without Performance Loss
Feb 07, 2024We present EfficientViT-SAM, a new family of accelerated segment anything models. We retain SAM's lightweight prompt encoder and mask decoder while replacing the heavy image encoder with EfficientViT. For the training, we begin with the knowledge distillation from the SAM-ViT-H image encoder to EfficientViT. Subsequently, we conduct end-to-end training on the SA-1B dataset. Benefiting from EfficientViT's efficiency and capacity, EfficientViT-SAM delivers 48.9x measured TensorRT speedup on A100 GPU over SAM-ViT-H without sacrificing performance. Our code and pre-trained models are released at https://github.com/mit-han-lab/efficientvit.
A possibilistic framework for multi-target multi-sensor fusion
Sep 25, 2022
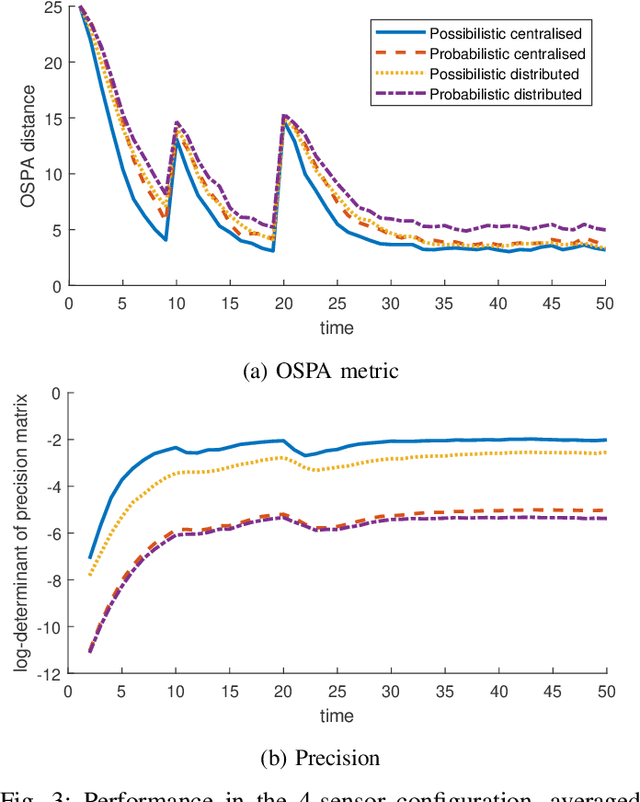
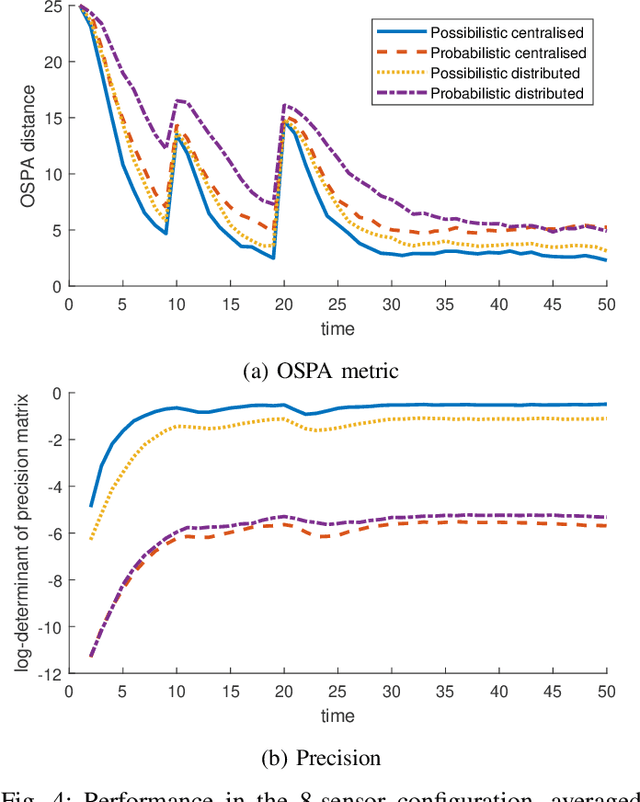
Fusing and sharing information from multiple sensors over a network is a challenging task, especially in the context of multi-target tracking. Part of this challenge arises from the absence of a foundational rule for fusing probability distributions, with various approaches stemming from different principles. Yet, when expressing multi-target tracking algorithms within the framework of possibility theory, one specific fusion rule appears to be particularly natural and useful. In this article, this fusion rule is applied to both centralised and decentralised fusion, based on the possibilistic analogue of the probability hypothesis density filter. We then show that the proposed approach outperforms its probabilistic counterpart on simulated data.
EfficientViT: Enhanced Linear Attention for High-Resolution Low-Computation Visual Recognition
May 29, 2022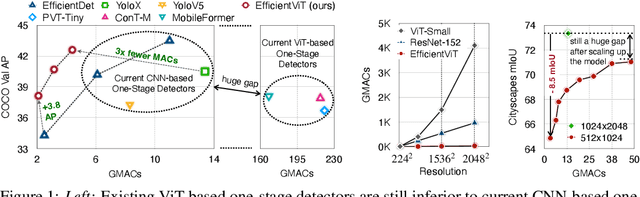
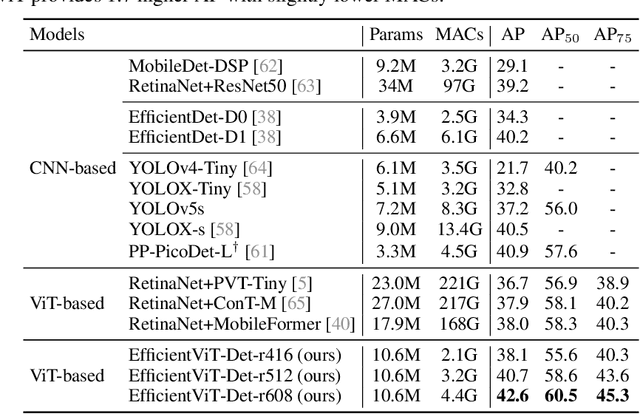
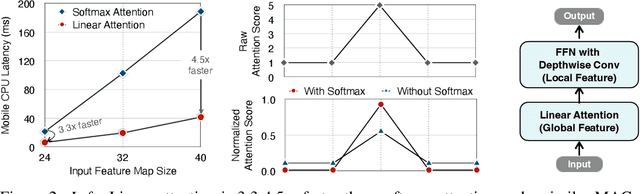
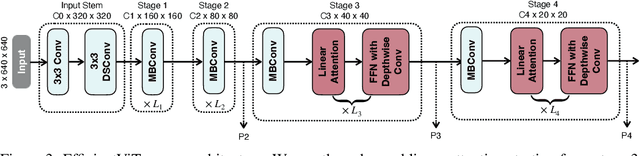
Vision Transformer (ViT) has achieved remarkable performance in many vision tasks. However, ViT is inferior to convolutional neural networks (CNNs) when targeting high-resolution mobile vision applications. The key computational bottleneck of ViT is the softmax attention module which has quadratic computational complexity with the input resolution. It is essential to reduce the cost of ViT to deploy it on edge devices. Existing methods (e.g., Swin, PVT) restrict the softmax attention within local windows or reduce the resolution of key/value tensors to reduce the cost, which sacrifices ViT's core advantages on global feature extractions. In this work, we present EfficientViT, an efficient ViT architecture for high-resolution low-computation visual recognition. Instead of restricting the softmax attention, we propose to replace softmax attention with linear attention while enhancing its local feature extraction ability with depthwise convolution. EfficientViT maintains global and local feature extraction capability while enjoying linear computational complexity. Extensive experiments on COCO object detection and Cityscapes semantic segmentation demonstrate the effectiveness of our method. On the COCO dataset, EfficientViT achieves 42.6 AP with 4.4G MACs, surpassing EfficientDet-D1 by 2.4 AP while having 27.9% fewer MACs. On Cityscapes, EfficientViT reaches 78.7 mIoU with 19.1G MACs, outperforming SegFormer by 2.5 mIoU while requiring less than 1/3 the computational cost. On Qualcomm Snapdragon 855 CPU, EfficientViT is 3x faster than EfficientNet while achieving higher ImageNet accuracy.
Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation
May 03, 2022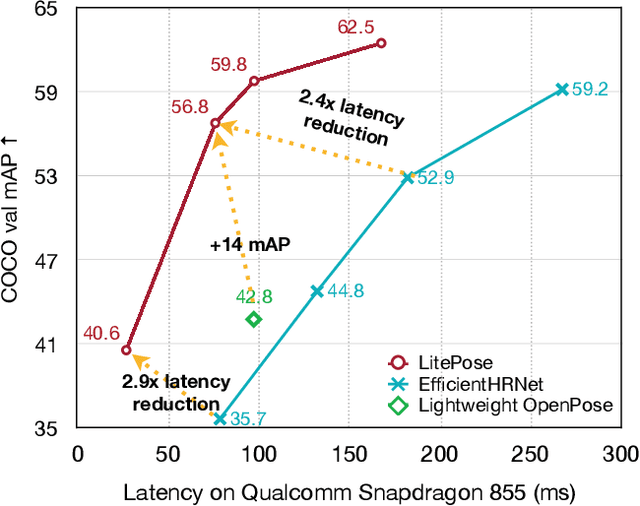
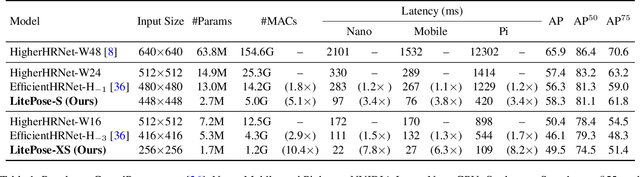
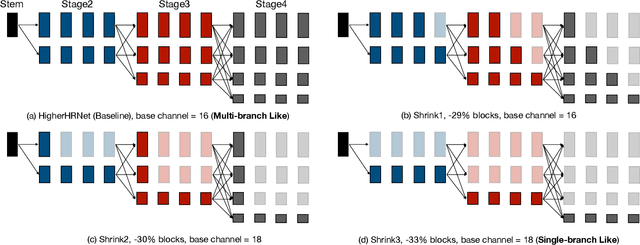
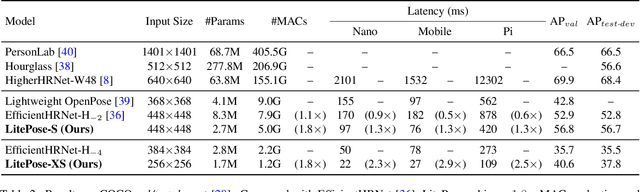
Pose estimation plays a critical role in human-centered vision applications. However, it is difficult to deploy state-of-the-art HRNet-based pose estimation models on resource-constrained edge devices due to the high computational cost (more than 150 GMACs per frame). In this paper, we study efficient architecture design for real-time multi-person pose estimation on edge. We reveal that HRNet's high-resolution branches are redundant for models at the low-computation region via our gradual shrinking experiments. Removing them improves both efficiency and performance. Inspired by this finding, we design LitePose, an efficient single-branch architecture for pose estimation, and introduce two simple approaches to enhance the capacity of LitePose, including Fusion Deconv Head and Large Kernel Convs. Fusion Deconv Head removes the redundancy in high-resolution branches, allowing scale-aware feature fusion with low overhead. Large Kernel Convs significantly improve the model's capacity and receptive field while maintaining a low computational cost. With only 25% computation increment, 7x7 kernels achieve +14.0 mAP better than 3x3 kernels on the CrowdPose dataset. On mobile platforms, LitePose reduces the latency by up to 5.0x without sacrificing performance, compared with prior state-of-the-art efficient pose estimation models, pushing the frontier of real-time multi-person pose estimation on edge. Our code and pre-trained models are released at https://github.com/mit-han-lab/litepose.
* 11 pages
Enable Deep Learning on Mobile Devices: Methods, Systems, and Applications
Apr 25, 2022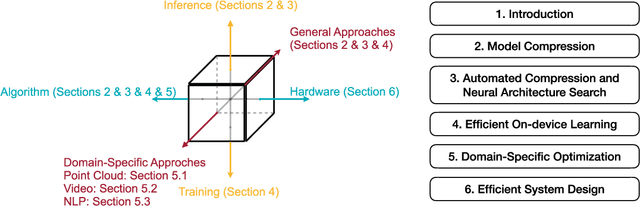
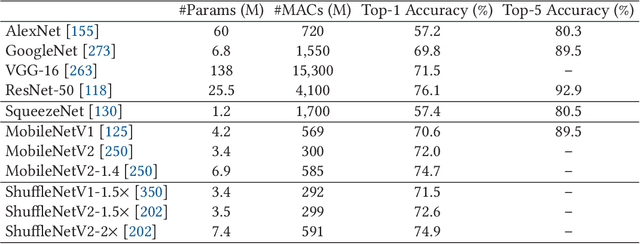
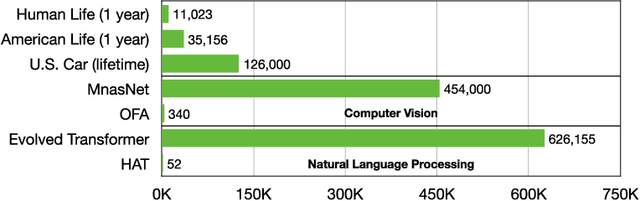
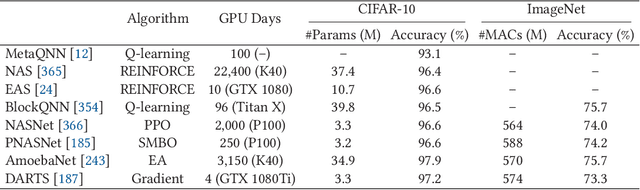
Deep neural networks (DNNs) have achieved unprecedented success in the field of artificial intelligence (AI), including computer vision, natural language processing and speech recognition. However, their superior performance comes at the considerable cost of computational complexity, which greatly hinders their applications in many resource-constrained devices, such as mobile phones and Internet of Things (IoT) devices. Therefore, methods and techniques that are able to lift the efficiency bottleneck while preserving the high accuracy of DNNs are in great demand in order to enable numerous edge AI applications. This paper provides an overview of efficient deep learning methods, systems and applications. We start from introducing popular model compression methods, including pruning, factorization, quantization as well as compact model design. To reduce the large design cost of these manual solutions, we discuss the AutoML framework for each of them, such as neural architecture search (NAS) and automated pruning and quantization. We then cover efficient on-device training to enable user customization based on the local data on mobile devices. Apart from general acceleration techniques, we also showcase several task-specific accelerations for point cloud, video and natural language processing by exploiting their spatial sparsity and temporal/token redundancy. Finally, to support all these algorithmic advancements, we introduce the efficient deep learning system design from both software and hardware perspectives.
* Journal preprint (ACM TODAES, 2021). The first seven authors contributed equally to this work and are listed in the alphabetical order
MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning
Oct 28, 2021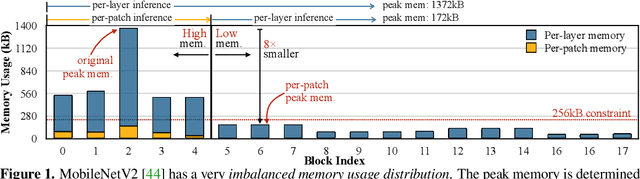

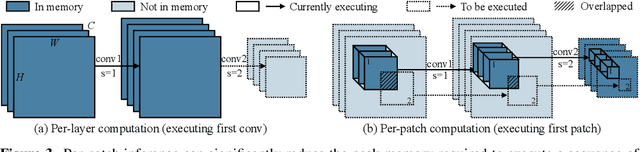

Tiny deep learning on microcontroller units (MCUs) is challenging due to the limited memory size. We find that the memory bottleneck is due to the imbalanced memory distribution in convolutional neural network (CNN) designs: the first several blocks have an order of magnitude larger memory usage than the rest of the network. To alleviate this issue, we propose a generic patch-by-patch inference scheduling, which operates only on a small spatial region of the feature map and significantly cuts down the peak memory. However, naive implementation brings overlapping patches and computation overhead. We further propose network redistribution to shift the receptive field and FLOPs to the later stage and reduce the computation overhead. Manually redistributing the receptive field is difficult. We automate the process with neural architecture search to jointly optimize the neural architecture and inference scheduling, leading to MCUNetV2. Patch-based inference effectively reduces the peak memory usage of existing networks by 4-8x. Co-designed with neural networks, MCUNetV2 sets a record ImageNet accuracy on MCU (71.8%), and achieves >90% accuracy on the visual wake words dataset under only 32kB SRAM. MCUNetV2 also unblocks object detection on tiny devices, achieving 16.9% higher mAP on Pascal VOC compared to the state-of-the-art result. Our study largely addressed the memory bottleneck in tinyML and paved the way for various vision applications beyond image classification.
Network Augmentation for Tiny Deep Learning
Oct 17, 2021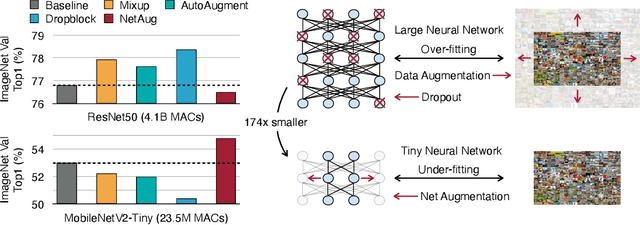

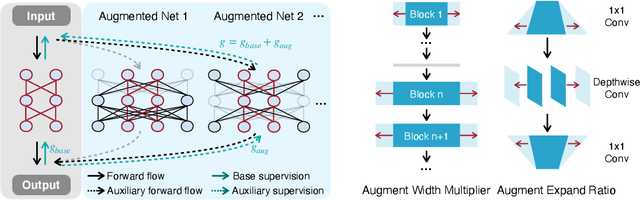
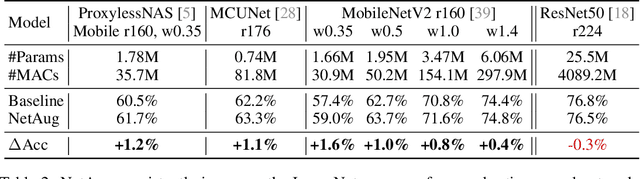
We introduce Network Augmentation (NetAug), a new training method for improving the performance of tiny neural networks. Existing regularization techniques (e.g., data augmentation, dropout) have shown much success on large neural networks (e.g., ResNet50) by adding noise to overcome over-fitting. However, we found these techniques hurt the performance of tiny neural networks. We argue that training tiny models are different from large models: rather than augmenting the data, we should augment the model, since tiny models tend to suffer from under-fitting rather than over-fitting due to limited capacity. To alleviate this issue, NetAug augments the network (reverse dropout) instead of inserting noise into the dataset or the network. It puts the tiny model into larger models and encourages it to work as a sub-model of larger models to get extra supervision, in addition to functioning as an independent model. At test time, only the tiny model is used for inference, incurring zero inference overhead. We demonstrate the effectiveness of NetAug on image classification and object detection. NetAug consistently improves the performance of tiny models, achieving up to 2.1% accuracy improvement on ImageNet, and 4.3% on Cars. On Pascal VOC, NetAug provides 2.96% mAP improvement with the same computational cost.