 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCap4Video: What Can Auxiliary Captions Do for Text-Video Retrieval?
Dec 31, 2022



Most existing text-video retrieval methods focus on cross-modal matching between the visual content of offline videos and textual query sentences. However, in real scenarios, online videos are frequently accompanied by relevant text information such as titles, tags, and even subtitles, which can be utilized to match textual queries. This inspires us to generate associated captions from offline videos to help with existing text-video retrieval methods. To do so, we propose to use the zero-shot video captioner with knowledge of pre-trained web-scale models (e.g., CLIP and GPT-2) to generate captions for offline videos without any training. Given the captions, one question naturally arises: what can auxiliary captions do for text-video retrieval? In this paper, we present a novel framework Cap4Video, which makes use of captions from three aspects: i) Input data: The video and captions can form new video-caption pairs as data augmentation for training. ii) Feature interaction: We perform feature interaction between video and caption to yield enhanced video representations. iii) Output score: The Query-Caption matching branch can be complementary to the original Query-Video matching branch for text-video retrieval. We conduct thorough ablation studies to demonstrate the effectiveness of our method. Without any post-processing, our Cap4Video achieves state-of-the-art performance on MSR-VTT (51.4%), VATEX (66.6%), MSVD (51.8%), and DiDeMo (52.0%).
Bidirectional Cross-Modal Knowledge Exploration for Video Recognition with Pre-trained Vision-Language Models
Dec 31, 2022Vision-language models (VLMs) that are pre-trained on large-scale image-text pairs have demonstrated impressive transferability on a wide range of visual tasks. Transferring knowledge from such powerful pre-trained VLMs is emerging as a promising direction for building effective video recognition models. However, the current exploration is still limited. In our opinion, the greatest charm of pre-trained vision-language models is to build a bridge between visual and textual domains. In this paper, we present a novel framework called BIKE which utilizes the cross-modal bridge to explore bidirectional knowledge: i) We propose a Video Attribute Association mechanism which leverages the Video-to-Text knowledge to generate textual auxiliary attributes to complement video recognition. ii) We also present a Temporal Concept Spotting mechanism which uses the Text-to-Video expertise to capture temporal saliency in a parameter-free manner to yield enhanced video representation. The extensive studies on popular video datasets (ie, Kinetics-400 & 600, UCF-101, HMDB-51 and ActivityNet) show that our method achieves state-of-the-art performance in most recognition scenarios, eg, general, zero-shot, and few-shot video recognition. To the best of our knowledge, our best model achieves a state-of-the-art accuracy of 88.4% on challenging Kinetics-400 with the released CLIP pre-trained model.
No-Regret Learning in Two-Echelon Supply Chain with Unknown Demand Distribution
Oct 23, 2022

Supply chain management (SCM) has been recognized as an important discipline with applications to many industries, where the two-echelon stochastic inventory model, involving one downstream retailer and one upstream supplier, plays a fundamental role for developing firms' SCM strategies. In this work, we aim at designing online learning algorithms for this problem with an unknown demand distribution, which brings distinct features as compared to classic online optimization problems. Specifically, we consider the two-echelon supply chain model introduced in [Cachon and Zipkin, 1999] under two different settings: the centralized setting, where a planner decides both agents' strategy simultaneously, and the decentralized setting, where two agents decide their strategy independently and selfishly. We design algorithms that achieve favorable guarantees for both regret and convergence to the optimal inventory decision in both settings, and additionally for individual regret in the decentralized setting. Our algorithms are based on Online Gradient Descent and Online Newton Step, together with several new ingredients specifically designed for our problem. We also implement our algorithms and show their empirical effectiveness.
Improved High-Probability Regret for Adversarial Bandits with Time-Varying Feedback Graphs
Oct 04, 2022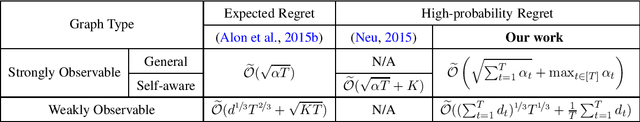
We study high-probability regret bounds for adversarial $K$-armed bandits with time-varying feedback graphs over $T$ rounds. For general strongly observable graphs, we develop an algorithm that achieves the optimal regret $\widetilde{\mathcal{O}}((\sum_{t=1}^T\alpha_t)^{1/2}+\max_{t\in[T]}\alpha_t)$ with high probability, where $\alpha_t$ is the independence number of the feedback graph at round $t$. Compared to the best existing result [Neu, 2015] which only considers graphs with self-loops for all nodes, our result not only holds more generally, but importantly also removes any $\text{poly}(K)$ dependence that can be prohibitively large for applications such as contextual bandits. Furthermore, we also develop the first algorithm that achieves the optimal high-probability regret bound for weakly observable graphs, which even improves the best expected regret bound of [Alon et al., 2015] by removing the $\mathcal{O}(\sqrt{KT})$ term with a refined analysis. Our algorithms are based on the online mirror descent framework, but importantly with an innovative combination of several techniques. Notably, while earlier works use optimistic biased loss estimators for achieving high-probability bounds, we find it important to use a pessimistic one for nodes without self-loop in a strongly observable graph.
Near-Optimal No-Regret Learning for General Convex Games
Jun 20, 2022
A recent line of work has established uncoupled learning dynamics such that, when employed by all players in a game, each player's \emph{regret} after $T$ repetitions grows polylogarithmically in $T$, an exponential improvement over the traditional guarantees within the no-regret framework. However, so far these results have only been limited to certain classes of games with structured strategy spaces -- such as normal-form and extensive-form games. The question as to whether $O(\text{polylog} T)$ regret bounds can be obtained for general convex and compact strategy sets -- which occur in many fundamental models in economics and multiagent systems -- while retaining efficient strategy updates is an important question. In this paper, we answer this in the positive by establishing the first uncoupled learning algorithm with $O(\log T)$ per-player regret in general \emph{convex games}, that is, games with concave utility functions supported on arbitrary convex and compact strategy sets. Our learning dynamics are based on an instantiation of optimistic follow-the-regularized-leader over an appropriately \emph{lifted} space using a \emph{self-concordant regularizer} that is, peculiarly, not a barrier for the feasible region. Further, our learning dynamics are efficiently implementable given access to a proximal oracle for the convex strategy set, leading to $O(\log\log T)$ per-iteration complexity; we also give extensions when access to only a \emph{linear} optimization oracle is assumed. Finally, we adapt our dynamics to guarantee $O(\sqrt{T})$ regret in the adversarial regime. Even in those special cases where prior results apply, our algorithm improves over the state-of-the-art regret bounds either in terms of the dependence on the number of iterations or on the dimension of the strategy sets.
Follow-the-Perturbed-Leader for Adversarial Markov Decision Processes with Bandit Feedback
May 26, 2022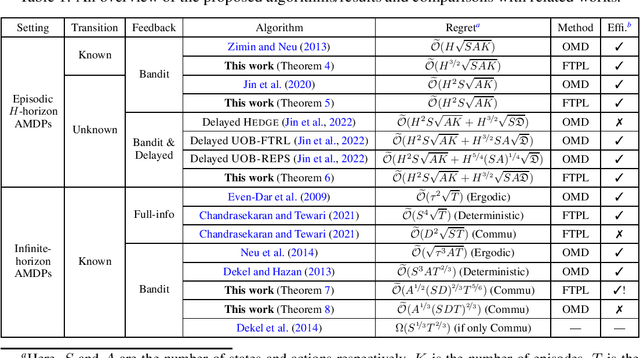
We consider regret minimization for Adversarial Markov Decision Processes (AMDPs), where the loss functions are changing over time and adversarially chosen, and the learner only observes the losses for the visited state-action pairs (i.e., bandit feedback). While there has been a surge of studies on this problem using Online-Mirror-Descent (OMD) methods, very little is known about the Follow-the-Perturbed-Leader (FTPL) methods, which are usually computationally more efficient and also easier to implement since it only requires solving an offline planning problem. Motivated by this, we take a closer look at FTPL for learning AMDPs, starting from the standard episodic finite-horizon setting. We find some unique and intriguing difficulties in the analysis and propose a workaround to eventually show that FTPL is also able to achieve near-optimal regret bounds in this case. More importantly, we then find two significant applications: First, the analysis of FTPL turns out to be readily generalizable to delayed bandit feedback with order-optimal regret, while OMD methods exhibit extra difficulties (Jin et al., 2022). Second, using FTPL, we also develop the first no-regret algorithm for learning communicating AMDPs in the infinite-horizon setting with bandit feedback and stochastic transitions. Our algorithm is efficient assuming access to an offline planning oracle, while even for the easier full-information setting, the only existing algorithm (Chandrasekaran and Tewari, 2021) is computationally inefficient.
Near-Optimal Goal-Oriented Reinforcement Learning in Non-Stationary Environments
May 25, 2022We initiate the study of dynamic regret minimization for goal-oriented reinforcement learning modeled by a non-stationary stochastic shortest path problem with changing cost and transition functions. We start by establishing a lower bound $\Omega((B_{\star} SAT_{\star}(\Delta_c + B_{\star}^2\Delta_P))^{1/3}K^{2/3})$, where $B_{\star}$ is the maximum expected cost of the optimal policy of any episode starting from any state, $T_{\star}$ is the maximum hitting time of the optimal policy of any episode starting from the initial state, $SA$ is the number of state-action pairs, $\Delta_c$ and $\Delta_P$ are the amount of changes of the cost and transition functions respectively, and $K$ is the number of episodes. The different roles of $\Delta_c$ and $\Delta_P$ in this lower bound inspire us to design algorithms that estimate costs and transitions separately. Specifically, assuming the knowledge of $\Delta_c$ and $\Delta_P$, we develop a simple but sub-optimal algorithm and another more involved minimax optimal algorithm (up to logarithmic terms). These algorithms combine the ideas of finite-horizon approximation [Chen et al., 2022a], special Bernstein-style bonuses of the MVP algorithm [Zhang et al., 2020], adaptive confidence widening [Wei and Luo, 2021], as well as some new techniques such as properly penalizing long-horizon policies. Finally, when $\Delta_c$ and $\Delta_P$ are unknown, we develop a variant of the MASTER algorithm [Wei and Luo, 2021] and integrate the aforementioned ideas into it to achieve $\widetilde{O}(\min\{B_{\star} S\sqrt{ALK}, (B_{\star}^2S^2AT_{\star}(\Delta_c+B_{\star}\Delta_P))^{1/3}K^{2/3}\})$ regret, where $L$ is the unknown number of changes of the environment.
Uncoupled Learning Dynamics with $O(\log T)$ Swap Regret in Multiplayer Games
Apr 25, 2022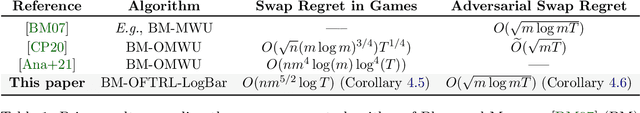
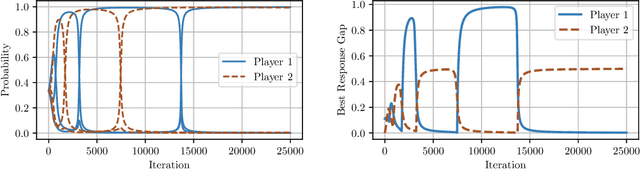
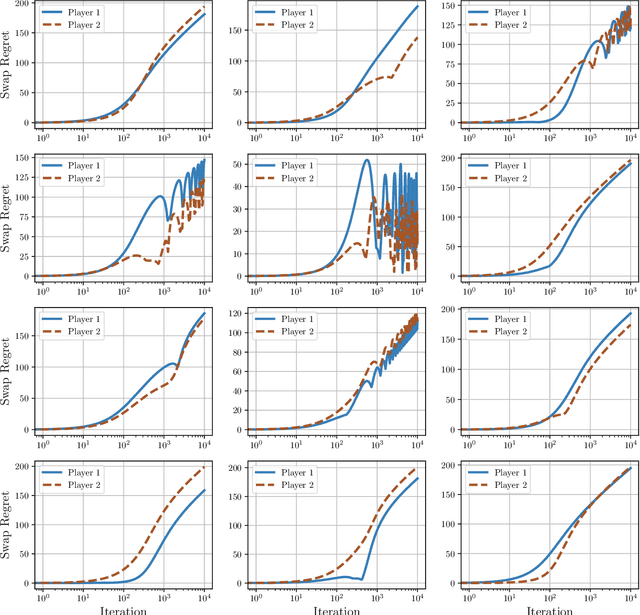
In this paper we establish efficient and \emph{uncoupled} learning dynamics so that, when employed by all players in a general-sum multiplayer game, the \emph{swap regret} of each player after $T$ repetitions of the game is bounded by $O(\log T)$, improving over the prior best bounds of $O(\log^4 (T))$. At the same time, we guarantee optimal $O(\sqrt{T})$ swap regret in the adversarial regime as well. To obtain these results, our primary contribution is to show that when all players follow our dynamics with a \emph{time-invariant} learning rate, the \emph{second-order path lengths} of the dynamics up to time $T$ are bounded by $O(\log T)$, a fundamental property which could have further implications beyond near-optimally bounding the (swap) regret. Our proposed learning dynamics combine in a novel way \emph{optimistic} regularized learning with the use of \emph{self-concordant barriers}. Further, our analysis is remarkably simple, bypassing the cumbersome framework of higher-order smoothness recently developed by Daskalakis, Fishelson, and Golowich (NeurIPS'21).
Corralling a Larger Band of Bandits: A Case Study on Switching Regret for Linear Bandits
Feb 12, 2022We consider the problem of combining and learning over a set of adversarial bandit algorithms with the goal of adaptively tracking the best one on the fly. The CORRAL algorithm of Agarwal et al. (2017) and its variants (Foster et al., 2020a) achieve this goal with a regret overhead of order $\widetilde{O}(\sqrt{MT})$ where $M$ is the number of base algorithms and $T$ is the time horizon. The polynomial dependence on $M$, however, prevents one from applying these algorithms to many applications where $M$ is poly$(T)$ or even larger. Motivated by this issue, we propose a new recipe to corral a larger band of bandit algorithms whose regret overhead has only \emph{logarithmic} dependence on $M$ as long as some conditions are satisfied. As the main example, we apply our recipe to the problem of adversarial linear bandits over a $d$-dimensional $\ell_p$ unit-ball for $p \in (1,2]$. By corralling a large set of $T$ base algorithms, each starting at a different time step, our final algorithm achieves the first optimal switching regret $\widetilde{O}(\sqrt{d S T})$ when competing against a sequence of comparators with $S$ switches (for some known $S$). We further extend our results to linear bandits over a smooth and strongly convex domain as well as unconstrained linear bandits.
Adaptive Bandit Convex Optimization with Heterogeneous Curvature
Feb 12, 2022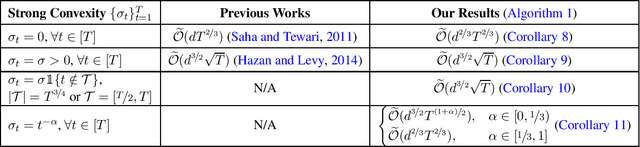
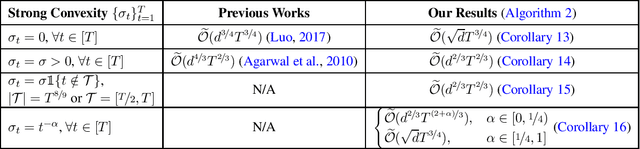
We consider the problem of adversarial bandit convex optimization, that is, online learning over a sequence of arbitrary convex loss functions with only one function evaluation for each of them. While all previous works assume known and homogeneous curvature on these loss functions, we study a heterogeneous setting where each function has its own curvature that is only revealed after the learner makes a decision. We develop an efficient algorithm that is able to adapt to the curvature on the fly. Specifically, our algorithm not only recovers or \emph{even improves} existing results for several homogeneous settings, but also leads to surprising results for some heterogeneous settings -- for example, while Hazan and Levy (2014) showed that $\widetilde{O}(d^{3/2}\sqrt{T})$ regret is achievable for a sequence of $T$ smooth and strongly convex $d$-dimensional functions, our algorithm reveals that the same is achievable even if $T^{3/4}$ of them are not strongly convex, and sometimes even if a constant fraction of them are not strongly convex. Our approach is inspired by the framework of Bartlett et al. (2007) who studied a similar heterogeneous setting but with stronger gradient feedback. Extending their framework to the bandit feedback setting requires novel ideas such as lifting the feasible domain and using a logarithmically homogeneous self-concordant barrier regularizer.