 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Linear Bandits with Delay as Payoff
Feb 20, 2025
A recent work by Schlisselberg et al. (2024) studies a delay-as-payoff model for stochastic multi-armed bandits, where the payoff (either loss or reward) is delayed for a period that is proportional to the payoff itself. While this captures many real-world applications, the simple multi-armed bandit setting limits the practicality of their results. In this paper, we address this limitation by studying the delay-as-payoff model for contextual linear bandits. Specifically, we start from the case with a fixed action set and propose an efficient algorithm whose regret overhead compared to the standard no-delay case is at most $D\Delta_{\max}\log T$, where $T$ is the total horizon, $D$ is the maximum delay, and $\Delta_{\max}$ is the maximum suboptimality gap. When payoff is loss, we also show further improvement of the bound, demonstrating a separation between reward and loss similar to Schlisselberg et al. (2024). Contrary to standard linear bandit algorithms that construct least squares estimator and confidence ellipsoid, the main novelty of our algorithm is to apply a phased arm elimination procedure by only picking actions in a volumetric spanner of the action set, which addresses challenges arising from both payoff-dependent delays and large action sets. We further extend our results to the case with varying action sets by adopting the reduction from Hanna et al. (2023). Finally, we implement our algorithm and showcase its effectiveness and superior performance in experiments.
Large Language Model Enhanced Machine Learning Estimators for Classification
May 08, 2024Pre-trained large language models (LLM) have emerged as a powerful tool for simulating various scenarios and generating output given specific instructions and multimodal input. In this work, we analyze the specific use of LLM to enhance a classical supervised machine learning method for classification problems. We propose a few approaches to integrate LLM into a classical machine learning estimator to further enhance the prediction performance. We examine the performance of the proposed approaches through both standard supervised learning binary classification tasks, and a transfer learning task where the test data observe distribution changes compared to the training data. Numerical experiments using four publicly available datasets are conducted and suggest that using LLM to enhance classical machine learning estimators can provide significant improvement on prediction performance.
Collaborative Intelligence in Sequential Experiments: A Human-in-the-Loop Framework for Drug Discovery
May 07, 2024



Drug discovery is a complex process that involves sequentially screening and examining a vast array of molecules to identify those with the target properties. This process, also referred to as sequential experimentation, faces challenges due to the vast search space, the rarity of target molecules, and constraints imposed by limited data and experimental budgets. To address these challenges, we introduce a human-in-the-loop framework for sequential experiments in drug discovery. This collaborative approach combines human expert knowledge with deep learning algorithms, enhancing the discovery of target molecules within a specified experimental budget. The proposed algorithm processes experimental data to recommend both promising molecules and those that could improve its performance to human experts. Human experts retain the final decision-making authority based on these recommendations and their domain expertise, including the ability to override algorithmic recommendations. We applied our method to drug discovery tasks using real-world data and found that it consistently outperforms all baseline methods, including those which rely solely on human or algorithmic input. This demonstrates the complementarity between human experts and the algorithm. Our results provide key insights into the levels of humans' domain knowledge, the importance of meta-knowledge, and effective work delegation strategies. Our findings suggest that such a framework can significantly accelerate the development of new vaccines and drugs by leveraging the best of both human and artificial intelligence.
DDI-CoCo: A Dataset For Understanding The Effect Of Color Contrast In Machine-Assisted Skin Disease Detection
Jan 24, 2024



Skin tone as a demographic bias and inconsistent human labeling poses challenges in dermatology AI. We take another angle to investigate color contrast's impact, beyond skin tones, on malignancy detection in skin disease datasets: We hypothesize that in addition to skin tones, the color difference between the lesion area and skin also plays a role in malignancy detection performance of dermatology AI models. To study this, we first propose a robust labeling method to quantify color contrast scores of each image and validate our method by showing small labeling variations. More importantly, applying our method to \textit{the only} diverse-skin tone and pathologically-confirmed skin disease dataset DDI, yields \textbf{DDI-CoCo Dataset}, and we observe a performance gap between the high and low color difference groups. This disparity remains consistent across various state-of-the-art (SoTA) image classification models, which supports our hypothesis. Furthermore, we study the interaction between skin tone and color difference effects and suggest that color difference can be an additional reason behind model performance bias between skin tones. Our work provides a complementary angle to dermatology AI for improving skin disease detection.
CSDR-BERT: a pre-trained scientific dataset match model for Chinese Scientific Dataset Retrieval
Jan 31, 2023As the number of open and shared scientific datasets on the Internet increases under the open science movement, efficiently retrieving these datasets is a crucial task in information retrieval (IR) research. In recent years, the development of large models, particularly the pre-training and fine-tuning paradigm, which involves pre-training on large models and fine-tuning on downstream tasks, has provided new solutions for IR match tasks. In this study, we use the original BERT token in the embedding layer, improve the Sentence-BERT model structure in the model layer by introducing the SimCSE and K-Nearest Neighbors method, and use the cosent loss function in the optimization phase to optimize the target output. Our experimental results show that our model outperforms other competing models on both public and self-built datasets through comparative experiments and ablation implementations. This study explores and validates the feasibility and efficiency of pre-training techniques for semantic retrieval of Chinese scientific datasets.
FE-TCM: Filter-Enhanced Transformer Click Model for Web Search
Jan 19, 2023Constructing click models and extracting implicit relevance feedback information from the interaction between users and search engines are very important to improve the ranking of search results. Using neural network to model users' click behaviors has become one of the effective methods to construct click models. In this paper, We use Transformer as the backbone network of feature extraction, add filter layer innovatively, and propose a new Filter-Enhanced Transformer Click Model (FE-TCM) for web search. Firstly, in order to reduce the influence of noise on user behavior data, we use the learnable filters to filter log noise. Secondly, following the examination hypothesis, we model the attraction estimator and examination predictor respectively to output the attractiveness scores and examination probabilities. A novel transformer model is used to learn the deeper representation among different features. Finally, we apply the combination functions to integrate attractiveness scores and examination probabilities into the click prediction. From our experiments on two real-world session datasets, it is proved that FE-TCM outperforms the existing click models for the click prediction.
On Human Visual Contrast Sensitivity and Machine Vision Robustness: A Comparative Study
Dec 16, 2022



It is well established in neuroscience that color vision plays an essential part in the human visual perception system. Meanwhile, many novel designs for computer vision inspired by human vision have achieved success in a wide range of tasks and applications. Nonetheless, how color differences affect machine vision has not been well explored. Our work tries to bridge this gap between the human color vision aspect of visual recognition and that of the machine. To achieve this, we curate two datasets: CIFAR10-F and CIFAR100-F, which are based on the foreground colors of the popular CIFAR datasets. Together with CIFAR10-B and CIFAR100-B, the existing counterpart datasets with information on the background colors of CIFAR test sets, we assign each image based on its color contrast level per its foreground and background color labels and use this as a proxy to study how color contrast affects machine vision. We first conduct a proof-of-concept study, showing the effect of color difference and validate our datasets. Furthermore, on a broader level, an important characteristic of human vision is its robustness against ambient changes; therefore, drawing inspirations from ophthalmology and the robustness literature, we analogize contrast sensitivity from the human visual aspect to machine vision and complement the current robustness study using corrupted images with our CIFAR-CoCo datasets. In summary, motivated by neuroscience and equipped with the datasets we curate, we devise a new framework in two dimensions to perform extensive analyses on the effect of color contrast and corrupted images: (1) model architecture, (2) model size, to measure the perception ability of machine vision beyond total accuracy. We also explore how task complexity and data augmentation play a role in this setup. Our results call attention to new evaluation approaches for human-like machine perception.
No-Regret Learning in Two-Echelon Supply Chain with Unknown Demand Distribution
Oct 23, 2022

Supply chain management (SCM) has been recognized as an important discipline with applications to many industries, where the two-echelon stochastic inventory model, involving one downstream retailer and one upstream supplier, plays a fundamental role for developing firms' SCM strategies. In this work, we aim at designing online learning algorithms for this problem with an unknown demand distribution, which brings distinct features as compared to classic online optimization problems. Specifically, we consider the two-echelon supply chain model introduced in [Cachon and Zipkin, 1999] under two different settings: the centralized setting, where a planner decides both agents' strategy simultaneously, and the decentralized setting, where two agents decide their strategy independently and selfishly. We design algorithms that achieve favorable guarantees for both regret and convergence to the optimal inventory decision in both settings, and additionally for individual regret in the decentralized setting. Our algorithms are based on Online Gradient Descent and Online Newton Step, together with several new ingredients specifically designed for our problem. We also implement our algorithms and show their empirical effectiveness.
Whom to Test? Active Sampling Strategies for Managing COVID-19
Dec 25, 2020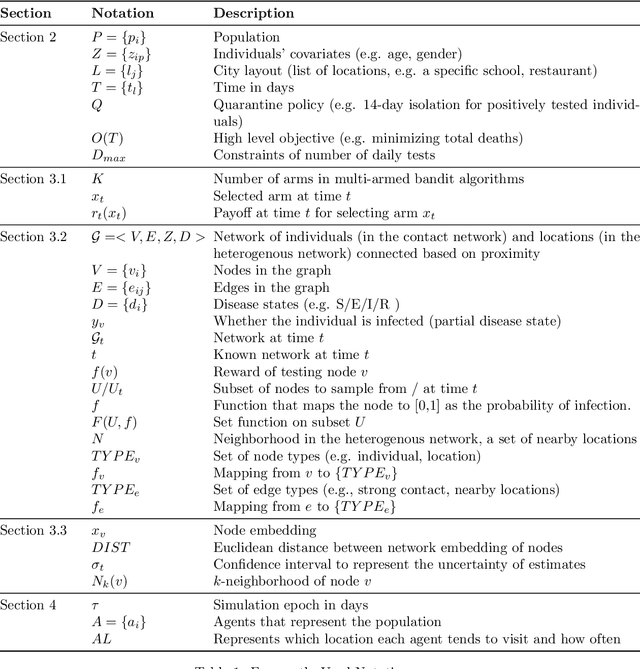
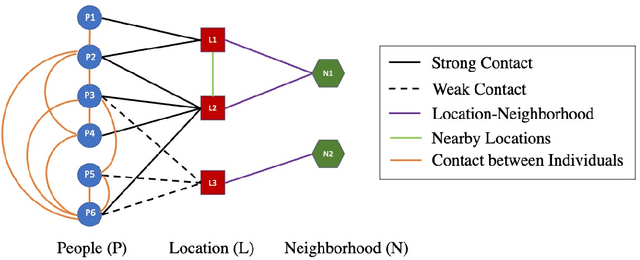
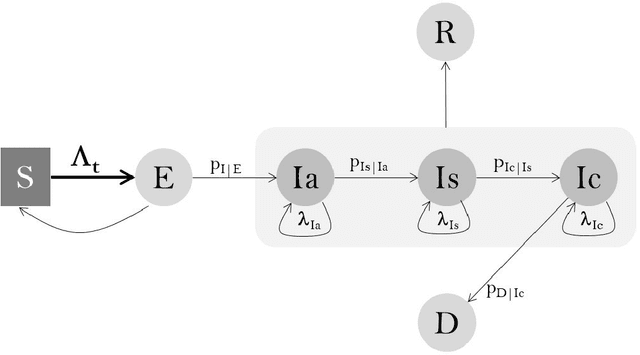
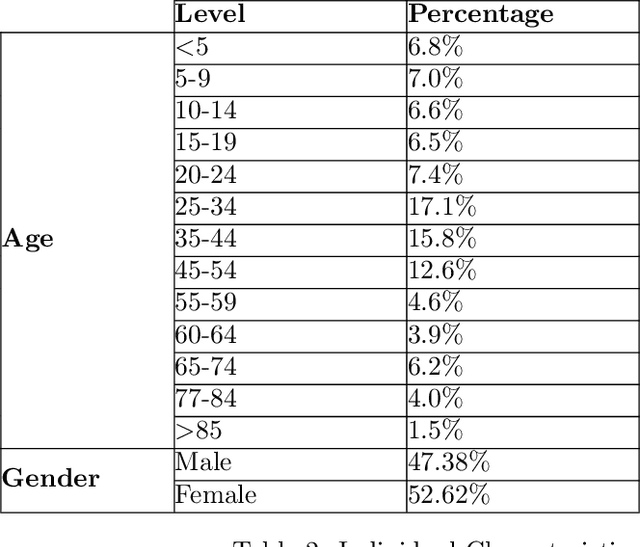
This paper presents methods to choose individuals to test for infection during a pandemic such as COVID-19, characterized by high contagion and presence of asymptomatic carriers. The smart-testing ideas presented here are motivated by active learning and multi-armed bandit techniques in machine learning. Our active sampling method works in conjunction with quarantine policies, can handle different objectives, is dynamic and adaptive in the sense that it continually adapts to changes in real-time data. The bandit algorithm uses contact tracing, location-based sampling and random sampling in order to select specific individuals to test. Using a data-driven agent-based model simulating New York City we show that the algorithm samples individuals to test in a manner that rapidly traces infected individuals. Experiments also suggest that smart-testing can significantly reduce the death rates as compared to current methods such as testing symptomatic individuals with or without contact tracing.
Spoiled for Choice? Personalized Recommendation for Healthcare Decisions: A Multi-Armed Bandit Approach
Sep 13, 2020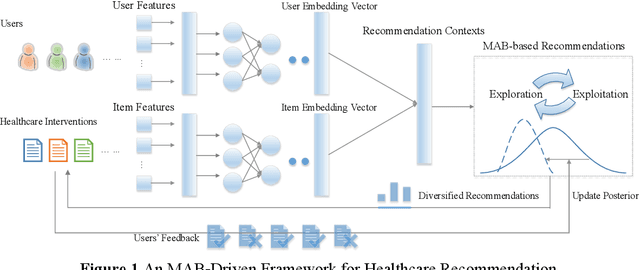
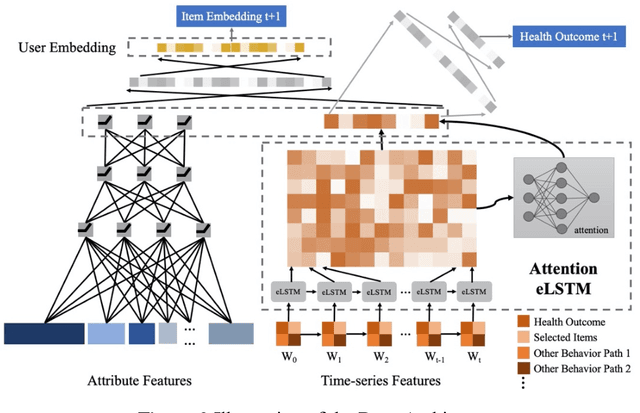

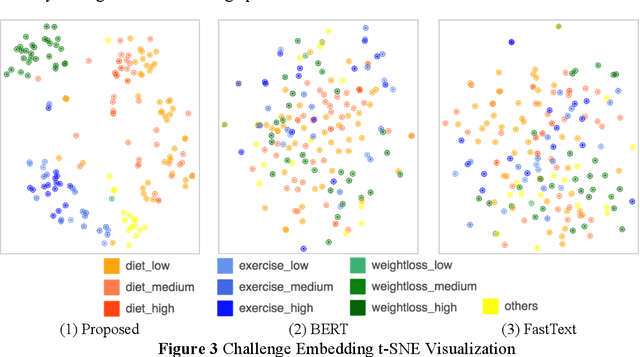
Online healthcare communities provide users with various healthcare interventions to promote healthy behavior and improve adherence. When faced with too many intervention choices, however, individuals may find it difficult to decide which option to take, especially when they lack the experience or knowledge to evaluate different options. The choice overload issue may negatively affect users' engagement in health management. In this study, we take a design-science perspective to propose a recommendation framework that helps users to select healthcare interventions. Taking into account that users' health behaviors can be highly dynamic and diverse, we propose a multi-armed bandit (MAB)-driven recommendation framework, which enables us to adaptively learn users' preference variations while promoting recommendation diversity in the meantime. To better adapt an MAB to the healthcare context, we synthesize two innovative model components based on prominent health theories. The first component is a deep-learning-based feature engineering procedure, which is designed to learn crucial recommendation contexts in regard to users' sequential health histories, health-management experiences, preferences, and intrinsic attributes of healthcare interventions. The second component is a diversity constraint, which structurally diversifies recommendations in different dimensions to provide users with well-rounded support. We apply our approach to an online weight management context and evaluate it rigorously through a series of experiments. Our results demonstrate that each of the design components is effective and that our recommendation design outperforms a wide range of state-of-the-art recommendation systems. Our study contributes to the research on the application of business intelligence and has implications for multiple stakeholders, including online healthcare platforms, policymakers, and users.