 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Online Learning in General-Sum Stackelberg Games
May 06, 2024

We study an online learning problem in general-sum Stackelberg games, where players act in a decentralized and strategic manner. We study two settings depending on the type of information for the follower: (1) the limited information setting where the follower only observes its own reward, and (2) the side information setting where the follower has extra side information about the leader's reward. We show that for the follower, myopically best responding to the leader's action is the best strategy for the limited information setting, but not necessarily so for the side information setting -- the follower can manipulate the leader's reward signals with strategic actions, and hence induce the leader's strategy to converge to an equilibrium that is better off for itself. Based on these insights, we study decentralized online learning for both players in the two settings. Our main contribution is to derive last-iterate convergence and sample complexity results in both settings. Notably, we design a new manipulation strategy for the follower in the latter setting, and show that it has an intrinsic advantage against the best response strategy. Our theories are also supported by empirical results.
S$^2$AC: Energy-Based Reinforcement Learning with Stein Soft Actor Critic
May 02, 2024Learning expressive stochastic policies instead of deterministic ones has been proposed to achieve better stability, sample complexity, and robustness. Notably, in Maximum Entropy Reinforcement Learning (MaxEnt RL), the policy is modeled as an expressive Energy-Based Model (EBM) over the Q-values. However, this formulation requires the estimation of the entropy of such EBMs, which is an open problem. To address this, previous MaxEnt RL methods either implicitly estimate the entropy, resulting in high computational complexity and variance (SQL), or follow a variational inference procedure that fits simplified actor distributions (e.g., Gaussian) for tractability (SAC). We propose Stein Soft Actor-Critic (S$^2$AC), a MaxEnt RL algorithm that learns expressive policies without compromising efficiency. Specifically, S$^2$AC uses parameterized Stein Variational Gradient Descent (SVGD) as the underlying policy. We derive a closed-form expression of the entropy of such policies. Our formula is computationally efficient and only depends on first-order derivatives and vector products. Empirical results show that S$^2$AC yields more optimal solutions to the MaxEnt objective than SQL and SAC in the multi-goal environment, and outperforms SAC and SQL on the MuJoCo benchmark. Our code is available at: https://github.com/SafaMessaoud/S2AC-Energy-Based-RL-with-Stein-Soft-Actor-Critic
Action Recognition with Multi-stream Motion Modeling and Mutual Information Maximization
Jun 13, 2023



Action recognition has long been a fundamental and intriguing problem in artificial intelligence. The task is challenging due to the high dimensionality nature of an action, as well as the subtle motion details to be considered. Current state-of-the-art approaches typically learn from articulated motion sequences in the straightforward 3D Euclidean space. However, the vanilla Euclidean space is not efficient for modeling important motion characteristics such as the joint-wise angular acceleration, which reveals the driving force behind the motion. Moreover, current methods typically attend to each channel equally and lack theoretical constrains on extracting task-relevant features from the input. In this paper, we seek to tackle these challenges from three aspects: (1) We propose to incorporate an acceleration representation, explicitly modeling the higher-order variations in motion. (2) We introduce a novel Stream-GCN network equipped with multi-stream components and channel attention, where different representations (i.e., streams) supplement each other towards a more precise action recognition while attention capitalizes on those important channels. (3) We explore feature-level supervision for maximizing the extraction of task-relevant information and formulate this into a mutual information loss. Empirically, our approach sets the new state-of-the-art performance on three benchmark datasets, NTU RGB+D, NTU RGB+D 120, and NW-UCLA. Our code is anonymously released at https://github.com/ActionR-Group/Stream-GCN, hoping to inspire the community.
Discrepancy-Guided Reconstruction Learning for Image Forgery Detection
May 03, 2023



In this paper, we propose a novel image forgery detection paradigm for boosting the model learning capacity on both forgery-sensitive and genuine compact visual patterns. Compared to the existing methods that only focus on the discrepant-specific patterns (\eg, noises, textures, and frequencies), our method has a greater generalization. Specifically, we first propose a Discrepancy-Guided Encoder (DisGE) to extract forgery-sensitive visual patterns. DisGE consists of two branches, where the mainstream backbone branch is used to extract general semantic features, and the accessorial discrepant external attention branch is used to extract explicit forgery cues. Besides, a Double-Head Reconstruction (DouHR) module is proposed to enhance genuine compact visual patterns in different granular spaces. Under DouHR, we further introduce a Discrepancy-Aggregation Detector (DisAD) to aggregate these genuine compact visual patterns, such that the forgery detection capability on unknown patterns can be improved. Extensive experimental results on four challenging datasets validate the effectiveness of our proposed method against state-of-the-art competitors.
3D Human Motion Prediction: A Survey
Mar 07, 2022
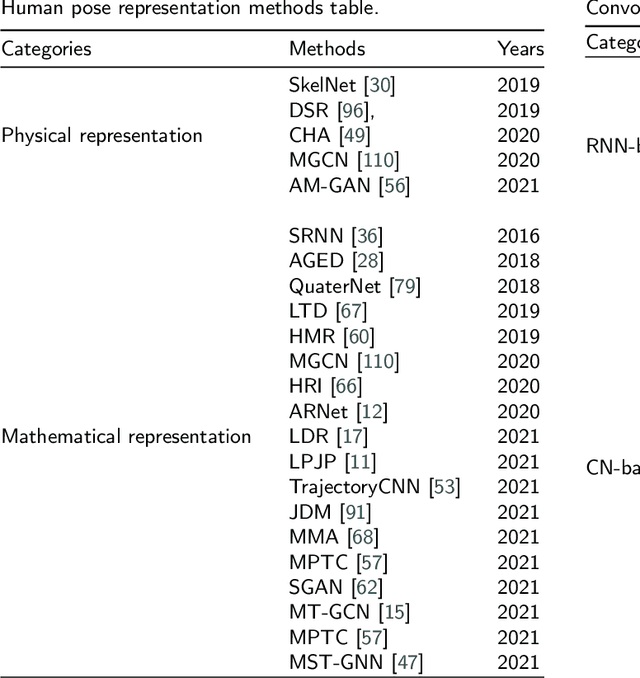
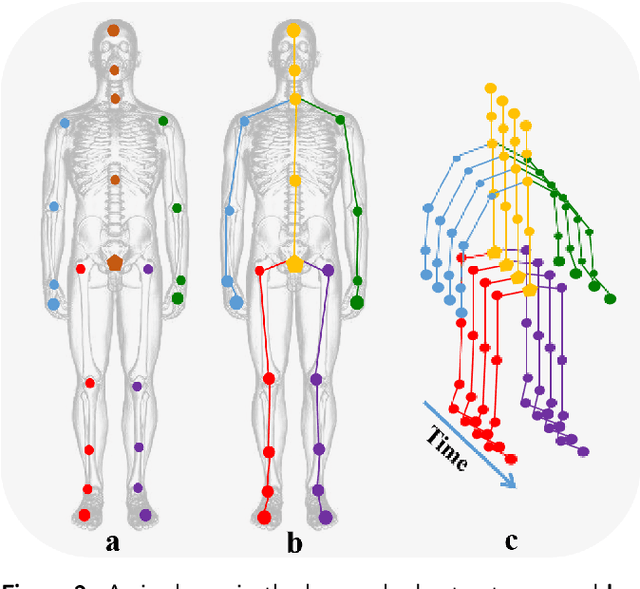
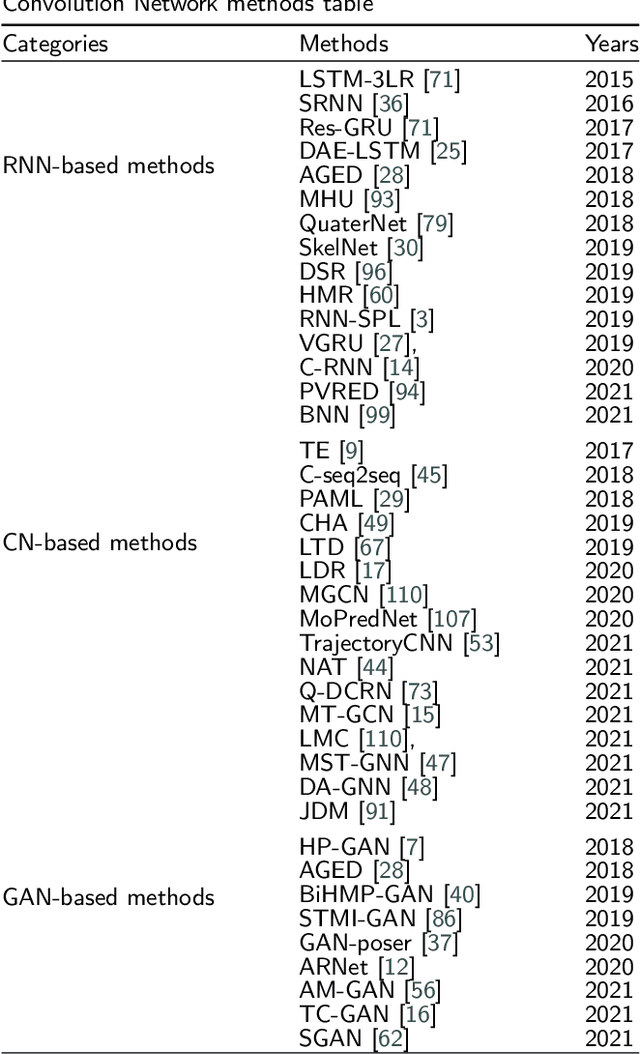
3D human motion prediction, predicting future poses from a given sequence, is an issue of great significance and challenge in computer vision and machine intelligence, which can help machines in understanding human behaviors. Due to the increasing development and understanding of Deep Neural Networks (DNNs) and the availability of large-scale human motion datasets, the human motion prediction has been remarkably advanced with a surge of interest among academia and industrial community. In this context, a comprehensive survey on 3D human motion prediction is conducted for the purpose of retrospecting and analyzing relevant works from existing released literature. In addition, a pertinent taxonomy is constructed to categorize these existing approaches for 3D human motion prediction. In this survey, relevant methods are categorized into three categories: human pose representation, network structure design, and \textit{prediction target}. We systematically review all relevant journal and conference papers in the field of human motion prediction since 2015, which are presented in detail based on proposed categorizations in this survey. Furthermore, the outline for the public benchmark datasets, evaluation criteria, and performance comparisons are respectively presented in this paper. The limitations of the state-of-the-art methods are discussed as well, hoping for paving the way for future explorations.
Learning Human Motion Prediction via Stochastic Differential Equations
Dec 21, 2021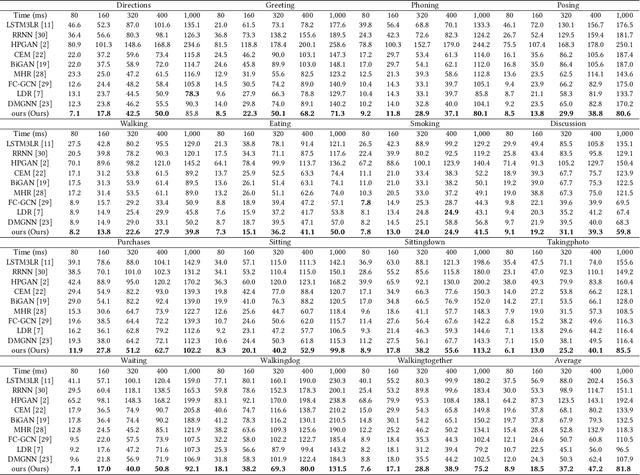
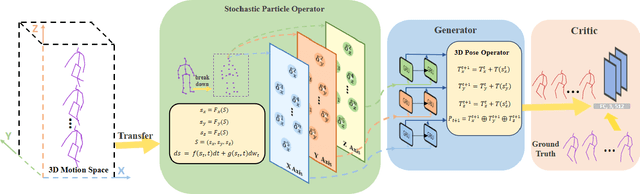
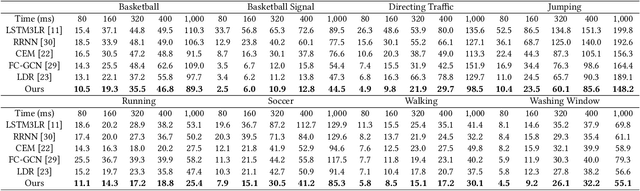
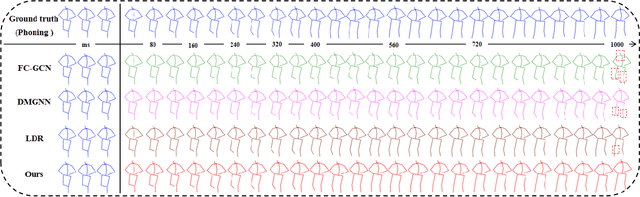
Human motion understanding and prediction is an integral aspect in our pursuit of machine intelligence and human-machine interaction systems. Current methods typically pursue a kinematics modeling approach, relying heavily upon prior anatomical knowledge and constraints. However, such an approach is hard to generalize to different skeletal model representations, and also tends to be inadequate in accounting for the dynamic range and complexity of motion, thus hindering predictive accuracy. In this work, we propose a novel approach in modeling the motion prediction problem based on stochastic differential equations and path integrals. The motion profile of each skeletal joint is formulated as a basic stochastic variable and modeled with the Langevin equation. We develop a strategy of employing GANs to simulate path integrals that amounts to optimizing over possible future paths. We conduct experiments in two large benchmark datasets, Human 3.6M and CMU MoCap. It is highlighted that our approach achieves a 12.48% accuracy improvement over current state-of-the-art methods in average.
Robust Reinforcement Learning Under Minimax Regret for Green Security
Jun 15, 2021
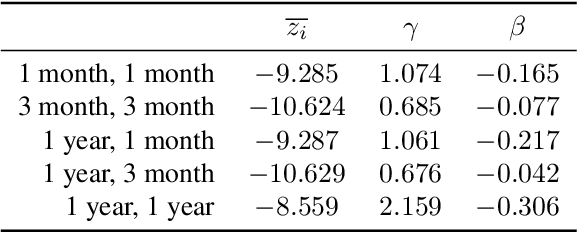
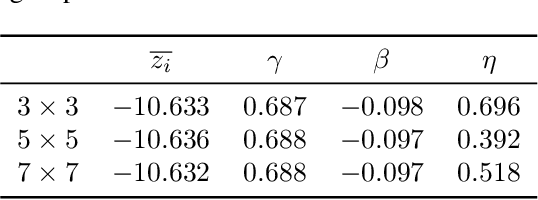
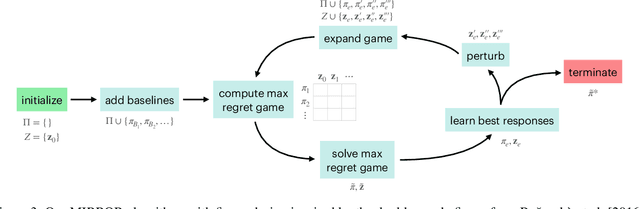
Green security domains feature defenders who plan patrols in the face of uncertainty about the adversarial behavior of poachers, illegal loggers, and illegal fishers. Importantly, the deterrence effect of patrols on adversaries' future behavior makes patrol planning a sequential decision-making problem. Therefore, we focus on robust sequential patrol planning for green security following the minimax regret criterion, which has not been considered in the literature. We formulate the problem as a game between the defender and nature who controls the parameter values of the adversarial behavior and design an algorithm MIRROR to find a robust policy. MIRROR uses two reinforcement learning-based oracles and solves a restricted game considering limited defender strategies and parameter values. We evaluate MIRROR on real-world poaching data.
Learning MDPs from Features: Predict-Then-Optimize for Sequential Decision Problems by Reinforcement Learning
Jun 14, 2021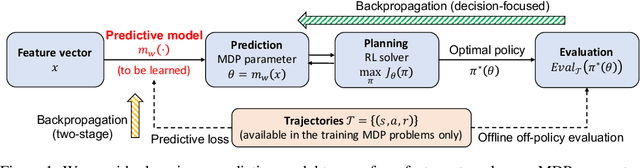
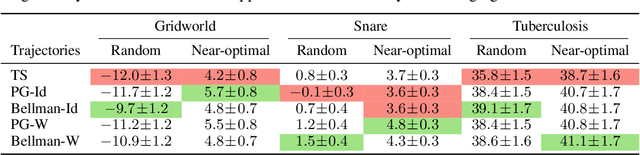
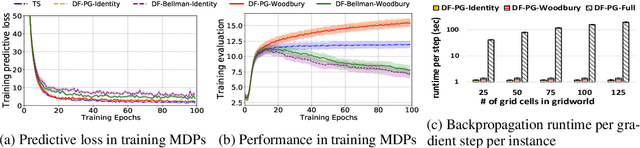
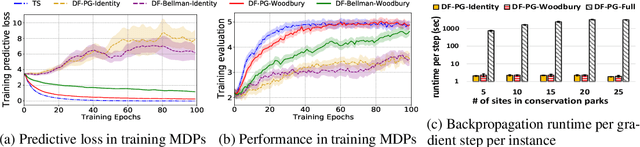
In the predict-then-optimize framework, the objective is to train a predictive model, mapping from environment features to parameters of an optimization problem, which maximizes decision quality when the optimization is subsequently solved. Recent work on decision-focused learning shows that embedding the optimization problem in the training pipeline can improve decision quality and help generalize better to unseen tasks compared to relying on an intermediate loss function for evaluating prediction quality. We study the predict-then-optimize framework in the context of sequential decision problems (formulated as MDPs) that are solved via reinforcement learning. In particular, we are given environment features and a set of trajectories from training MDPs, which we use to train a predictive model that generalizes to unseen test MDPs without trajectories. Two significant computational challenges arise in applying decision-focused learning to MDPs: (i) large state and action spaces make it infeasible for existing techniques to differentiate through MDP problems, and (ii) the high-dimensional policy space, as parameterized by a neural network, makes differentiating through a policy expensive. We resolve the first challenge by sampling provably unbiased derivatives to approximate and differentiate through optimality conditions, and the second challenge by using a low-rank approximation to the high-dimensional sample-based derivatives. We implement both Bellman--based and policy gradient--based decision-focused learning on three different MDP problems with missing parameters, and show that decision-focused learning performs better in generalization to unseen tasks.
Contingency-Aware Influence Maximization: A Reinforcement Learning Approach
Jun 13, 2021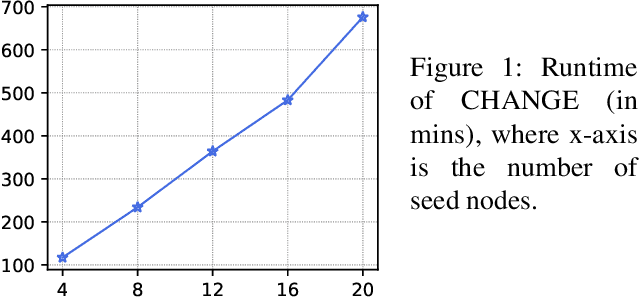
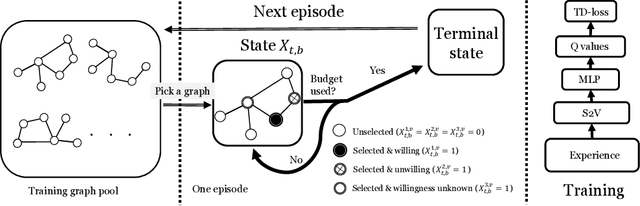


The influence maximization (IM) problem aims at finding a subset of seed nodes in a social network that maximize the spread of influence. In this study, we focus on a sub-class of IM problems, where whether the nodes are willing to be the seeds when being invited is uncertain, called contingency-aware IM. Such contingency aware IM is critical for applications for non-profit organizations in low resource communities (e.g., spreading awareness of disease prevention). Despite the initial success, a major practical obstacle in promoting the solutions to more communities is the tremendous runtime of the greedy algorithms and the lack of high performance computing (HPC) for the non-profits in the field -- whenever there is a new social network, the non-profits usually do not have the HPCs to recalculate the solutions. Motivated by this and inspired by the line of works that use reinforcement learning (RL) to address combinatorial optimization on graphs, we formalize the problem as a Markov Decision Process (MDP), and use RL to learn an IM policy over historically seen networks, and generalize to unseen networks with negligible runtime at test phase. To fully exploit the properties of our targeted problem, we propose two technical innovations that improve the existing methods, including state-abstraction and theoretically grounded reward shaping. Empirical results show that our method achieves influence as high as the state-of-the-art methods for contingency-aware IM, while having negligible runtime at test phase.
Aggregated Multi-GANs for Controlled 3D Human Motion Prediction
Mar 17, 2021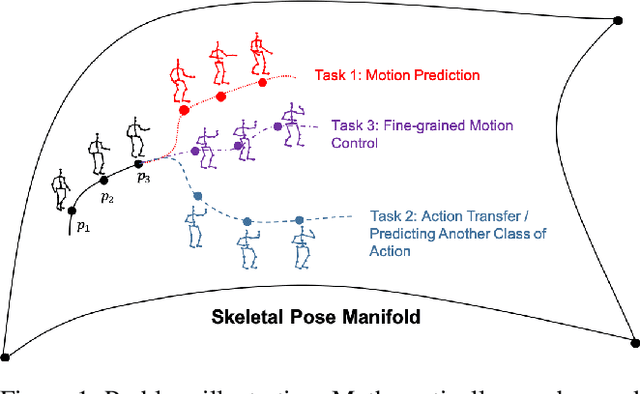
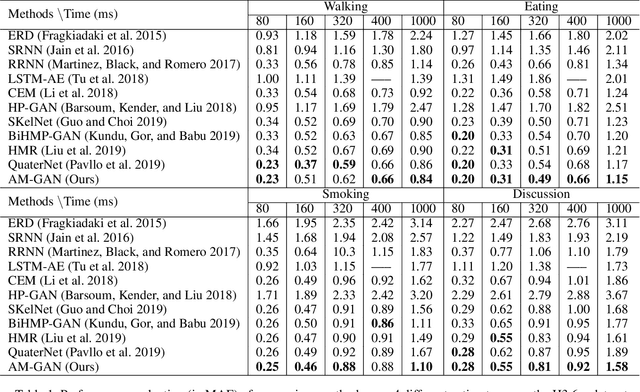
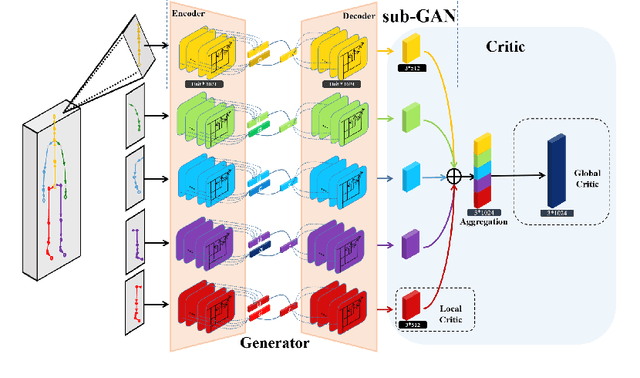
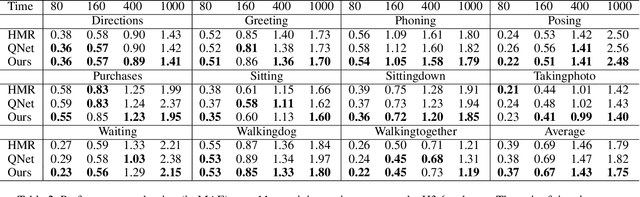
Human motion prediction from historical pose sequence is at the core of many applications in machine intelligence. However, in current state-of-the-art methods, the predicted future motion is confined within the same activity. One can neither generate predictions that differ from the current activity, nor manipulate the body parts to explore various future possibilities. Undoubtedly, this greatly limits the usefulness and applicability of motion prediction. In this paper, we propose a generalization of the human motion prediction task in which control parameters can be readily incorporated to adjust the forecasted motion. Our method is compelling in that it enables manipulable motion prediction across activity types and allows customization of the human movement in a variety of fine-grained ways. To this aim, a simple yet effective composite GAN structure, consisting of local GANs for different body parts and aggregated via a global GAN is presented. The local GANs game in lower dimensions, while the global GAN adjusts in high dimensional space to avoid mode collapse. Extensive experiments show that our method outperforms state-of-the-art. The codes are available at https://github.com/herolvkd/AM-GAN.