 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting the Layered Intrinsic Dimensionality of Deep Models for Practical Adversarial Training
May 27, 2024



Despite being a heavily researched topic, Adversarial Training (AT) is rarely, if ever, deployed in practical AI systems for two primary reasons: (i) the gained robustness is frequently accompanied by a drop in generalization and (ii) generating adversarial examples (AEs) is computationally prohibitively expensive. To address these limitations, we propose SMAAT, a new AT algorithm that leverages the manifold conjecture, stating that off-manifold AEs lead to better robustness while on-manifold AEs result in better generalization. Specifically, SMAAT aims at generating a higher proportion of off-manifold AEs by perturbing the intermediate deepnet layer with the lowest intrinsic dimension. This systematically results in better scalability compared to classical AT as it reduces the PGD chains length required for generating the AEs. Additionally, our study provides, to the best of our knowledge, the first explanation for the difference in the generalization and robustness trends between vision and language models, ie., AT results in a drop in generalization in vision models whereas, in encoder-based language models, generalization either improves or remains unchanged. We show that vision transformers and decoder-based models tend to have low intrinsic dimensionality in the earlier layers of the network (more off-manifold AEs), while encoder-based models have low intrinsic dimensionality in the later layers. We demonstrate the efficacy of SMAAT; on several tasks, including robustifying (i) sentiment classifiers, (ii) safety filters in decoder-based models, and (iii) retrievers in RAG setups. SMAAT requires only 25-33% of the GPU time compared to standard AT, while significantly improving robustness across all applications and maintaining comparable generalization.
S$^2$AC: Energy-Based Reinforcement Learning with Stein Soft Actor Critic
May 02, 2024Learning expressive stochastic policies instead of deterministic ones has been proposed to achieve better stability, sample complexity, and robustness. Notably, in Maximum Entropy Reinforcement Learning (MaxEnt RL), the policy is modeled as an expressive Energy-Based Model (EBM) over the Q-values. However, this formulation requires the estimation of the entropy of such EBMs, which is an open problem. To address this, previous MaxEnt RL methods either implicitly estimate the entropy, resulting in high computational complexity and variance (SQL), or follow a variational inference procedure that fits simplified actor distributions (e.g., Gaussian) for tractability (SAC). We propose Stein Soft Actor-Critic (S$^2$AC), a MaxEnt RL algorithm that learns expressive policies without compromising efficiency. Specifically, S$^2$AC uses parameterized Stein Variational Gradient Descent (SVGD) as the underlying policy. We derive a closed-form expression of the entropy of such policies. Our formula is computationally efficient and only depends on first-order derivatives and vector products. Empirical results show that S$^2$AC yields more optimal solutions to the MaxEnt objective than SQL and SAC in the multi-goal environment, and outperforms SAC and SQL on the MuJoCo benchmark. Our code is available at: https://github.com/SafaMessaoud/S2AC-Energy-Based-RL-with-Stein-Soft-Actor-Critic
A3T: Accuracy Aware Adversarial Training
Nov 29, 2022Adversarial training has been empirically shown to be more prone to overfitting than standard training. The exact underlying reasons still need to be fully understood. In this paper, we identify one cause of overfitting related to current practices of generating adversarial samples from misclassified samples. To address this, we propose an alternative approach that leverages the misclassified samples to mitigate the overfitting problem. We show that our approach achieves better generalization while having comparable robustness to state-of-the-art adversarial training methods on a wide range of computer vision, natural language processing, and tabular tasks.
Impact of Adversarial Training on Robustness and Generalizability of Language Models
Nov 10, 2022



Adversarial training is widely acknowledged as the most effective defense against adversarial attacks. However, it is also well established that achieving both robustness and generalization in adversarially trained models involves a trade-off. The goal of this work is to provide an in depth comparison of different approaches for adversarial training in language models. Specifically, we study the effect of pre-training data augmentation as well as training time input perturbations vs. embedding space perturbations on the robustness and generalization of BERT-like language models. Our findings suggest that better robustness can be achieved by pre-training data augmentation or by training with input space perturbation. However, training with embedding space perturbation significantly improves generalization. A linguistic correlation analysis of neurons of the learned models reveal that the improved generalization is due to `more specialized' neurons. To the best of our knowledge, this is the first work to carry out a deep qualitative analysis of different methods of generating adversarial examples in adversarial training of language models.
DeepQAMVS: Query-Aware Hierarchical Pointer Networks for Multi-Video Summarization
May 13, 2021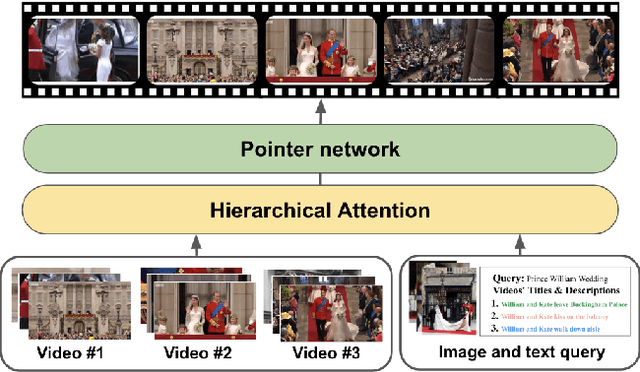
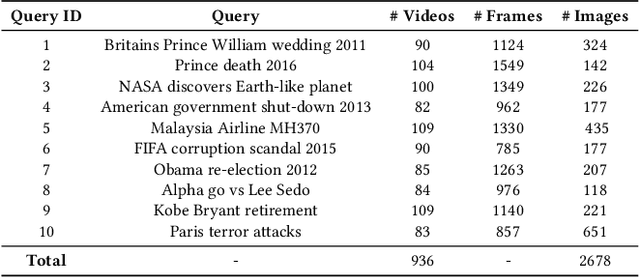
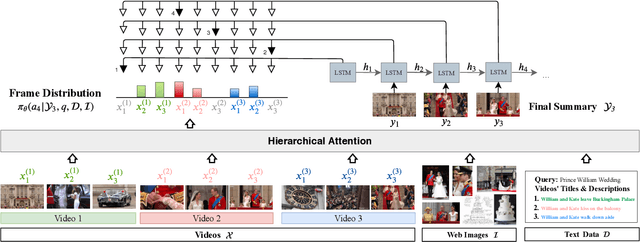
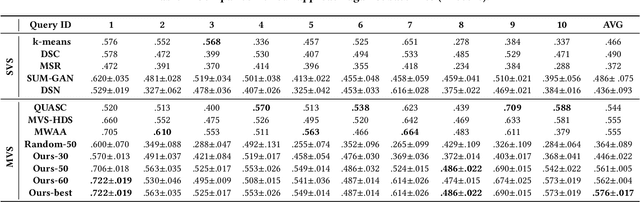
The recent growth of web video sharing platforms has increased the demand for systems that can efficiently browse, retrieve and summarize video content. Query-aware multi-video summarization is a promising technique that caters to this demand. In this work, we introduce a novel Query-Aware Hierarchical Pointer Network for Multi-Video Summarization, termed DeepQAMVS, that jointly optimizes multiple criteria: (1) conciseness, (2) representativeness of important query-relevant events and (3) chronological soundness. We design a hierarchical attention model that factorizes over three distributions, each collecting evidence from a different modality, followed by a pointer network that selects frames to include in the summary. DeepQAMVS is trained with reinforcement learning, incorporating rewards that capture representativeness, diversity, query-adaptability and temporal coherence. We achieve state-of-the-art results on the MVS1K dataset, with inference time scaling linearly with the number of input video frames.
Can We Learn Heuristics For Graphical Model Inference Using Reinforcement Learning?
May 05, 2020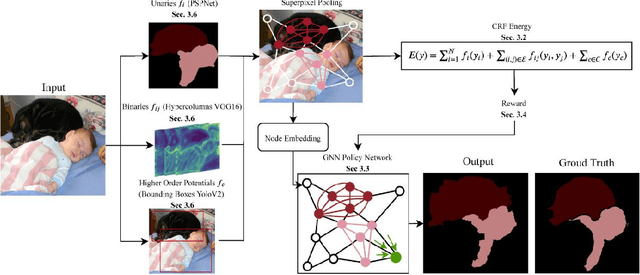

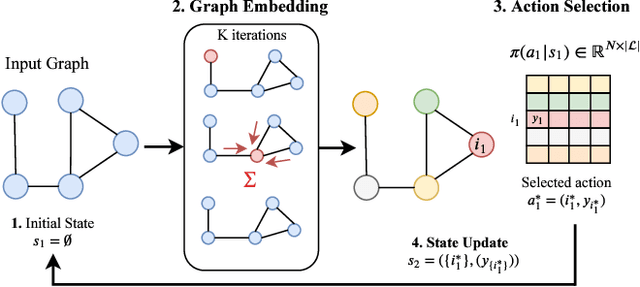
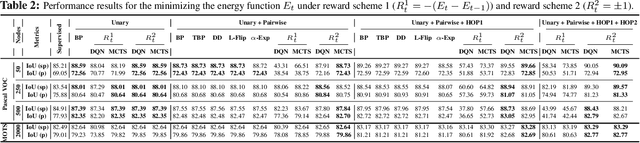
Combinatorial optimization is frequently used in computer vision. For instance, in applications like semantic segmentation, human pose estimation and action recognition, programs are formulated for solving inference in Conditional Random Fields (CRFs) to produce a structured output that is consistent with visual features of the image. However, solving inference in CRFs is in general intractable, and approximation methods are computationally demanding and limited to unary, pairwise and hand-crafted forms of higher order potentials. In this paper, we show that we can learn program heuristics, i.e., policies, for solving inference in higher order CRFs for the task of semantic segmentation, using reinforcement learning. Our method solves inference tasks efficiently without imposing any constraints on the form of the potentials. We show compelling results on the Pascal VOC and MOTS datasets.
Structural Consistency and Controllability for Diverse Colorization
Sep 06, 2018
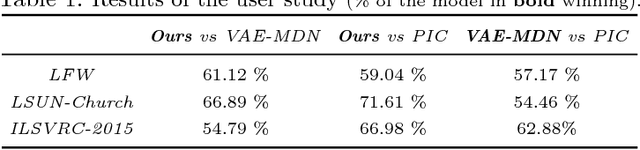

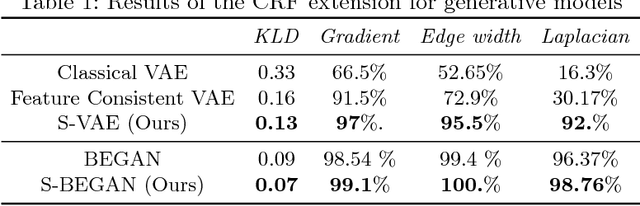
Colorizing a given gray-level image is an important task in the media and advertising industry. Due to the ambiguity inherent to colorization (many shades are often plausible), recent approaches started to explicitly model diversity. However, one of the most obvious artifacts, structural inconsistency, is rarely considered by existing methods which predict chrominance independently for every pixel. To address this issue, we develop a conditional random field based variational auto-encoder formulation which is able to achieve diversity while taking into account structural consistency. Moreover, we introduce a controllability mecha- nism that can incorporate external constraints from diverse sources in- cluding a user interface. Compared to existing baselines, we demonstrate that our method obtains more diverse and globally consistent coloriza- tions on the LFW, LSUN-Church and ILSVRC-2015 datasets.