 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecker: Double Check with Heterogeneous Knowledge for Commonsense Fact Verification
May 10, 2023Commonsense fact verification, as a challenging branch of commonsense question-answering (QA), aims to verify through facts whether a given commonsense claim is correct or not. Answering commonsense questions necessitates a combination of knowledge from various levels. However, existing studies primarily rest on grasping either unstructured evidence or potential reasoning paths from structured knowledge bases, yet failing to exploit the benefits of heterogeneous knowledge simultaneously. In light of this, we propose Decker, a commonsense fact verification model that is capable of bridging heterogeneous knowledge by uncovering latent relationships between structured and unstructured knowledge. Experimental results on two commonsense fact verification benchmark datasets, CSQA2.0 and CREAK demonstrate the effectiveness of our Decker and further analysis verifies its capability to seize more precious information through reasoning.
Attack Named Entity Recognition by Entity Boundary Interference
May 09, 2023Named Entity Recognition (NER) is a cornerstone NLP task while its robustness has been given little attention. This paper rethinks the principles of NER attacks derived from sentence classification, as they can easily violate the label consistency between the original and adversarial NER examples. This is due to the fine-grained nature of NER, as even minor word changes in the sentence can result in the emergence or mutation of any entities, resulting in invalid adversarial examples. To this end, we propose a novel one-word modification NER attack based on a key insight, NER models are always vulnerable to the boundary position of an entity to make their decision. We thus strategically insert a new boundary into the sentence and trigger the Entity Boundary Interference that the victim model makes the wrong prediction either on this boundary word or on other words in the sentence. We call this attack Virtual Boundary Attack (ViBA), which is shown to be remarkably effective when attacking both English and Chinese models with a 70%-90% attack success rate on state-of-the-art language models (e.g. RoBERTa, DeBERTa) and also significantly faster than previous methods.
Toward Adversarial Training on Contextualized Language Representation
May 08, 2023



Beyond the success story of adversarial training (AT) in the recent text domain on top of pre-trained language models (PLMs), our empirical study showcases the inconsistent gains from AT on some tasks, e.g. commonsense reasoning, named entity recognition. This paper investigates AT from the perspective of the contextualized language representation outputted by PLM encoders. We find the current AT attacks lean to generate sub-optimal adversarial examples that can fool the decoder part but have a minor effect on the encoder. However, we find it necessary to effectively deviate the latter one to allow AT to gain. Based on the observation, we propose simple yet effective \textit{Contextualized representation-Adversarial Training} (CreAT), in which the attack is explicitly optimized to deviate the contextualized representation of the encoder. It allows a global optimization of adversarial examples that can fool the entire model. We also find CreAT gives rise to a better direction to optimize the adversarial examples, to let them less sensitive to hyperparameters. Compared to AT, CreAT produces consistent performance gains on a wider range of tasks and is proven to be more effective for language pre-training where only the encoder part is kept for downstream tasks. We achieve the new state-of-the-art performances on a series of challenging benchmarks, e.g. AdvGLUE (59.1 $ \rightarrow $ 61.1), HellaSWAG (93.0 $ \rightarrow $ 94.9), ANLI (68.1 $ \rightarrow $ 69.3).
Multimodal Chain-of-Thought Reasoning in Language Models
Feb 17, 2023



Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. With Multimodal-CoT, our model under 1 billion parameters outperforms the previous state-of-the-art LLM (GPT-3.5) by 16 percentage points (75.17%->91.68% accuracy) on the ScienceQA benchmark and even surpasses human performance. Code is publicly available available at https://github.com/amazon-science/mm-cot.
Channel-aware Decoupling Network for Multi-turn Dialogue Comprehension
Jan 11, 2023



Training machines to understand natural language and interact with humans is one of the major goals of artificial intelligence. Recent years have witnessed an evolution from matching networks to pre-trained language models (PrLMs). In contrast to the plain-text modeling as the focus of the PrLMs, dialogue texts involve multiple speakers and reflect special characteristics such as topic transitions and structure dependencies between distant utterances. However, the related PrLM models commonly represent dialogues sequentially by processing the pairwise dialogue history as a whole. Thus the hierarchical information on either utterance interrelation or speaker roles coupled in such representations is not well addressed. In this work, we propose compositional learning for holistic interaction across the utterances beyond the sequential contextualization from PrLMs, in order to capture the utterance-aware and speaker-aware representations entailed in a dialogue history. We decouple the contextualized word representations by masking mechanisms in Transformer-based PrLM, making each word only focus on the words in current utterance, other utterances, and two speaker roles (i.e., utterances of sender and utterances of the receiver), respectively. In addition, we employ domain-adaptive training strategies to help the model adapt to the dialogue domains. Experimental results show that our method substantially boosts the strong PrLM baselines in four public benchmark datasets, achieving new state-of-the-art performance over previous methods.
Universal Multimodal Representation for Language Understanding
Jan 09, 2023



Representation learning is the foundation of natural language processing (NLP). This work presents new methods to employ visual information as assistant signals to general NLP tasks. For each sentence, we first retrieve a flexible number of images either from a light topic-image lookup table extracted over the existing sentence-image pairs or a shared cross-modal embedding space that is pre-trained on out-of-shelf text-image pairs. Then, the text and images are encoded by a Transformer encoder and convolutional neural network, respectively. The two sequences of representations are further fused by an attention layer for the interaction of the two modalities. In this study, the retrieval process is controllable and flexible. The universal visual representation overcomes the lack of large-scale bilingual sentence-image pairs. Our method can be easily applied to text-only tasks without manually annotated multimodal parallel corpora. We apply the proposed method to a wide range of natural language generation and understanding tasks, including neural machine translation, natural language inference, and semantic similarity. Experimental results show that our method is generally effective for different tasks and languages. Analysis indicates that the visual signals enrich textual representations of content words, provide fine-grained grounding information about the relationship between concepts and events, and potentially conduce to disambiguation.
Self-Prompting Large Language Models for Open-Domain QA
Dec 16, 2022



Open-Domain Question Answering (ODQA) requires models to answer factoid questions with no context given. The common way for this task is to train models on a large-scale annotated dataset to retrieve related documents and generate answers based on these documents. In this paper, we show that the ODQA architecture can be dramatically simplified by treating Large Language Models (LLMs) as a knowledge corpus and propose a Self-Prompting framework for LLMs to perform ODQA so as to eliminate the need for training data and external knowledge corpus. Concretely, we firstly generate multiple pseudo QA pairs with background passages and one-sentence explanations for these QAs by prompting LLMs step by step and then leverage the generated QA pairs for in-context learning. Experimental results show our method surpasses previous state-of-the-art methods by +8.8 EM averagely on three widely-used ODQA datasets, and even achieves comparable performance with several retrieval-augmented fine-tuned models.
Language Model Pre-training on True Negatives
Dec 01, 2022



Discriminative pre-trained language models (PLMs) learn to predict original texts from intentionally corrupted ones. Taking the former text as positive and the latter as negative samples, the PLM can be trained effectively for contextualized representation. However, the training of such a type of PLMs highly relies on the quality of the automatically constructed samples. Existing PLMs simply treat all corrupted texts as equal negative without any examination, which actually lets the resulting model inevitably suffer from the false negative issue where training is carried out on pseudo-negative data and leads to less efficiency and less robustness in the resulting PLMs. In this work, on the basis of defining the false negative issue in discriminative PLMs that has been ignored for a long time, we design enhanced pre-training methods to counteract false negative predictions and encourage pre-training language models on true negatives by correcting the harmful gradient updates subject to false negative predictions. Experimental results on GLUE and SQuAD benchmarks show that our counter-false-negative pre-training methods indeed bring about better performance together with stronger robustness.
Forging Multiple Training Objectives for Pre-trained Language Models via Meta-Learning
Oct 19, 2022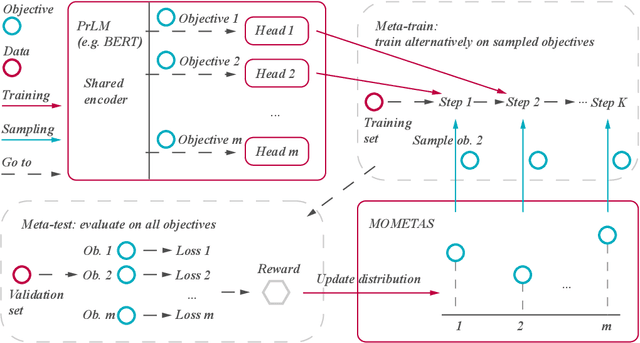
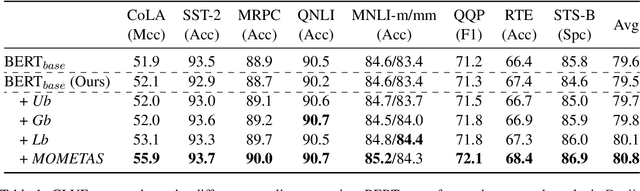
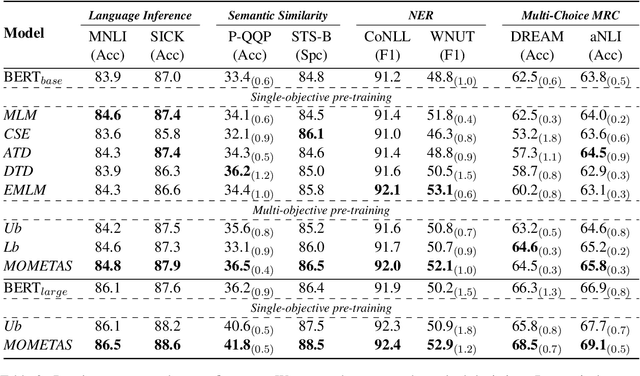
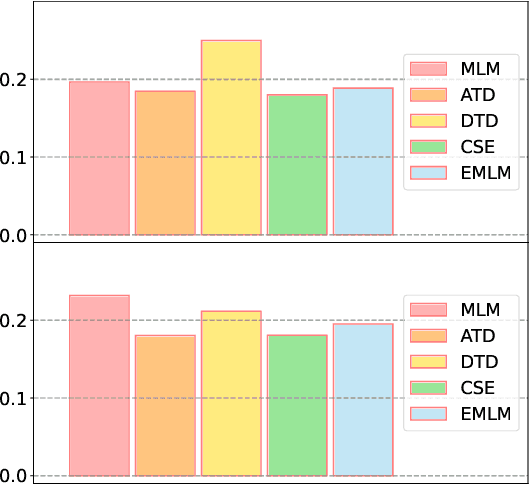
Multiple pre-training objectives fill the vacancy of the understanding capability of single-objective language modeling, which serves the ultimate purpose of pre-trained language models (PrLMs), generalizing well on a mass of scenarios. However, learning multiple training objectives in a single model is challenging due to the unknown relative significance as well as the potential contrariety between them. Empirical studies have shown that the current objective sampling in an ad-hoc manual setting makes the learned language representation barely converge to the desired optimum. Thus, we propose \textit{MOMETAS}, a novel adaptive sampler based on meta-learning, which learns the latent sampling pattern on arbitrary pre-training objectives. Such a design is lightweight with negligible additional training overhead. To validate our approach, we adopt five objectives and conduct continual pre-training with BERT-base and BERT-large models, where MOMETAS demonstrates universal performance gain over other rule-based sampling strategies on 14 natural language processing tasks.
Sentence Representation Learning with Generative Objective rather than Contrastive Objective
Oct 16, 2022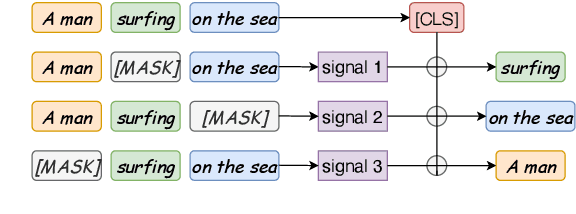
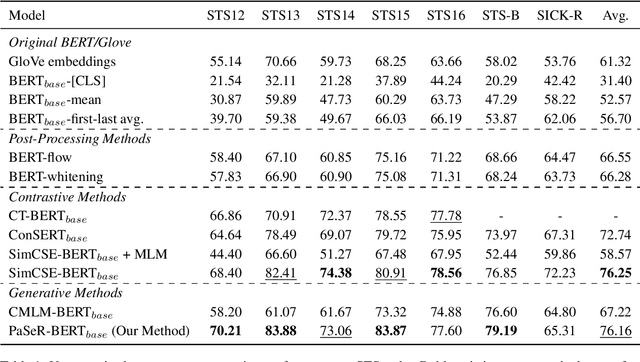
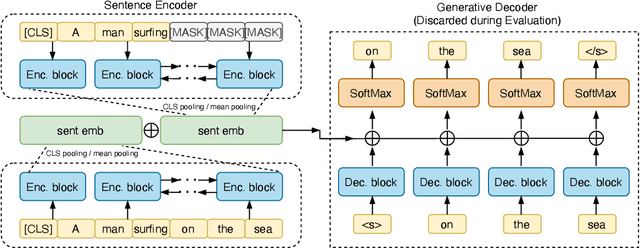
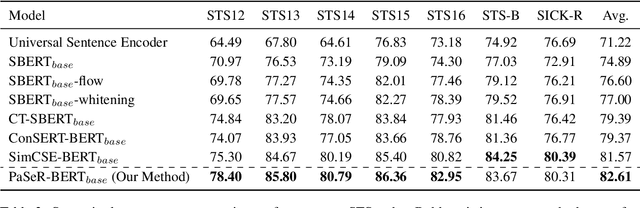
Though offering amazing contextualized token-level representations, current pre-trained language models take less attention on accurately acquiring sentence-level representation during their self-supervised pre-training. However, contrastive objectives which dominate the current sentence representation learning bring little linguistic interpretability and no performance guarantee on downstream semantic tasks. We instead propose a novel generative self-supervised learning objective based on phrase reconstruction. To overcome the drawbacks of previous generative methods, we carefully model intra-sentence structure by breaking down one sentence into pieces of important phrases. Empirical studies show that our generative learning achieves powerful enough performance improvement and outperforms the current state-of-the-art contrastive methods not only on the STS benchmarks, but also on downstream semantic retrieval and reranking tasks. Our code is available at https://github.com/chengzhipanpan/PaSeR.