 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeamlessM4T-Massively Multilingual & Multimodal Machine Translation
Aug 23, 2023



What does it take to create the Babel Fish, a tool that can help individuals translate speech between any two languages? While recent breakthroughs in text-based models have pushed machine translation coverage beyond 200 languages, unified speech-to-speech translation models have yet to achieve similar strides. More specifically, conventional speech-to-speech translation systems rely on cascaded systems that perform translation progressively, putting high-performing unified systems out of reach. To address these gaps, we introduce SeamlessM4T, a single model that supports speech-to-speech translation, speech-to-text translation, text-to-speech translation, text-to-text translation, and automatic speech recognition for up to 100 languages. To build this, we used 1 million hours of open speech audio data to learn self-supervised speech representations with w2v-BERT 2.0. Subsequently, we created a multimodal corpus of automatically aligned speech translations. Filtered and combined with human-labeled and pseudo-labeled data, we developed the first multilingual system capable of translating from and into English for both speech and text. On FLEURS, SeamlessM4T sets a new standard for translations into multiple target languages, achieving an improvement of 20% BLEU over the previous SOTA in direct speech-to-text translation. Compared to strong cascaded models, SeamlessM4T improves the quality of into-English translation by 1.3 BLEU points in speech-to-text and by 2.6 ASR-BLEU points in speech-to-speech. Tested for robustness, our system performs better against background noises and speaker variations in speech-to-text tasks compared to the current SOTA model. Critically, we evaluated SeamlessM4T on gender bias and added toxicity to assess translation safety. Finally, all contributions in this work are open-sourced and accessible at https://github.com/facebookresearch/seamless_communication
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
What Language Model to Train if You Have One Million GPU Hours?
Nov 08, 2022



The crystallization of modeling methods around the Transformer architecture has been a boon for practitioners. Simple, well-motivated architectural variations can transfer across tasks and scale, increasing the impact of modeling research. However, with the emergence of state-of-the-art 100B+ parameters models, large language models are increasingly expensive to accurately design and train. Notably, it can be difficult to evaluate how modeling decisions may impact emergent capabilities, given that these capabilities arise mainly from sheer scale alone. In the process of building BLOOM--the Big Science Large Open-science Open-access Multilingual language model--our goal is to identify an architecture and training setup that makes the best use of our 1,000,000 A100-GPU-hours budget. Specifically, we perform an ablation study at the billion-parameter scale comparing different modeling practices and their impact on zero-shot generalization. In addition, we study the impact of various popular pre-training corpora on zero-shot generalization. We also study the performance of a multilingual model and how it compares to the English-only one. Finally, we consider the scaling behaviour of Transformers to choose the target model size, shape, and training setup. All our models and code are open-sourced at https://huggingface.co/bigscience .
On Reinforcement Learning and Distribution Matching for Fine-Tuning Language Models with no Catastrophic Forgetting
Jun 01, 2022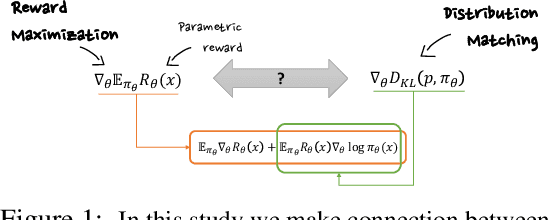
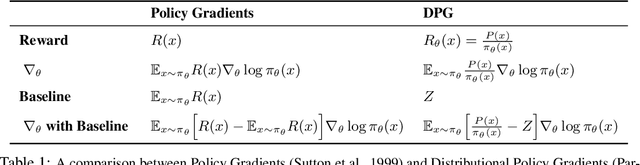
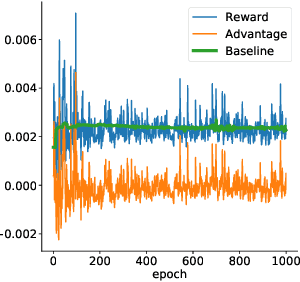

The availability of large pre-trained models is changing the landscape of Machine Learning research and practice, moving from a training-from-scratch to a fine-tuning paradigm. While in some applications the goal is to "nudge" the pre-trained distribution towards preferred outputs, in others it is to steer it towards a different distribution over the sample space. Two main paradigms have emerged to tackle this challenge: Reward Maximization (RM) and, more recently, Distribution Matching (DM). RM applies standard Reinforcement Learning (RL) techniques, such as Policy Gradients, to gradually increase the reward signal. DM prescribes to first make explicit the target distribution that the model is fine-tuned to approximate. Here we explore the theoretical connections between the two paradigms, and show that methods such as KL-control developed for RM can also be construed as belonging to DM. We further observe that while DM differs from RM, it can suffer from similar training difficulties, such as high gradient variance. We leverage connections between the two paradigms to import the concept of baseline into DM methods. We empirically validate the benefits of adding a baseline on an array of controllable language generation tasks such as constraining topic, sentiment, and gender distributions in texts sampled from a language model. We observe superior performance in terms of constraint satisfaction, stability and sample efficiency.
Documenting Geographically and Contextually Diverse Data Sources: The BigScience Catalogue of Language Data and Resources
Jan 25, 2022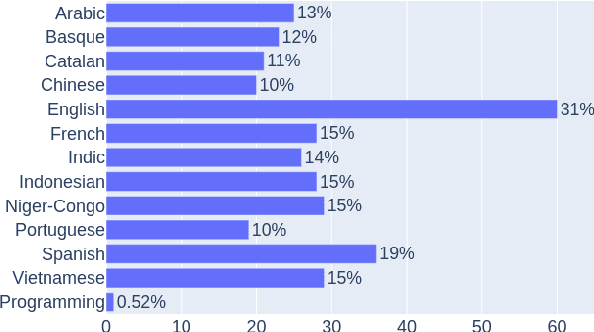
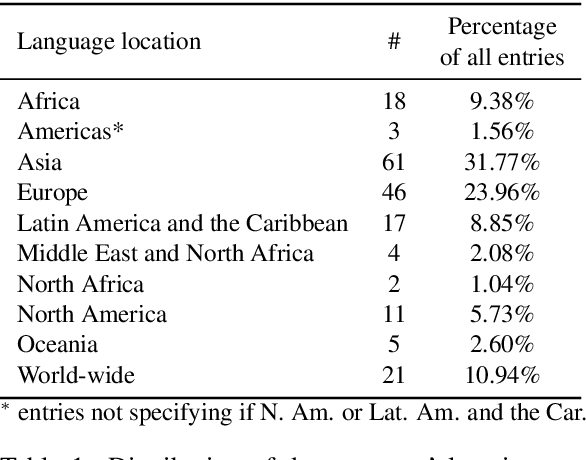
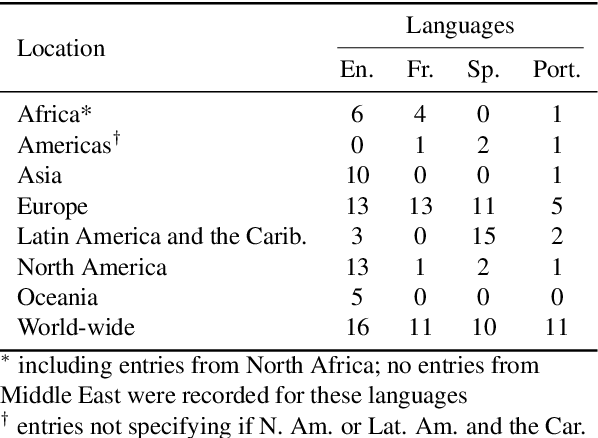
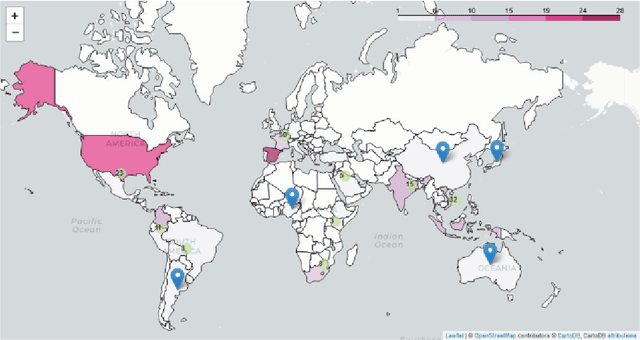
In recent years, large-scale data collection efforts have prioritized the amount of data collected in order to improve the modeling capabilities of large language models. This prioritization, however, has resulted in concerns with respect to the rights of data subjects represented in data collections, particularly when considering the difficulty in interrogating these collections due to insufficient documentation and tools for analysis. Mindful of these pitfalls, we present our methodology for a documentation-first, human-centered data collection project as part of the BigScience initiative. We identified a geographically diverse set of target language groups (Arabic, Basque, Chinese, Catalan, English, French, Indic languages, Indonesian, Niger-Congo languages, Portuguese, Spanish, and Vietnamese, as well as programming languages) for which to collect metadata on potential data sources. To structure this effort, we developed our online catalogue as a supporting tool for gathering metadata through organized public hackathons. We present our development process; analyses of the resulting resource metadata, including distributions over languages, regions, and resource types; and our lessons learned in this endeavor.
Sampling from Discrete Energy-Based Models with Quality/Efficiency Trade-offs
Dec 10, 2021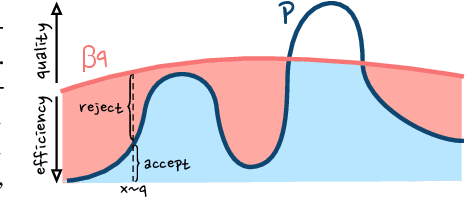

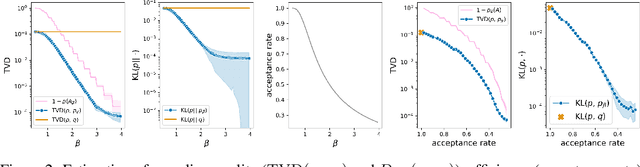
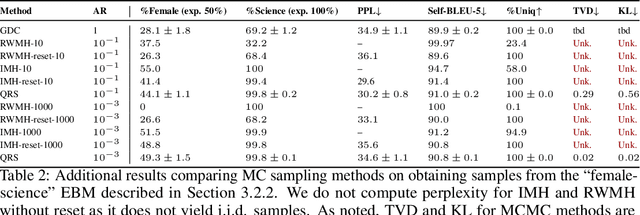
Energy-Based Models (EBMs) allow for extremely flexible specifications of probability distributions. However, they do not provide a mechanism for obtaining exact samples from these distributions. Monte Carlo techniques can aid us in obtaining samples if some proposal distribution that we can easily sample from is available. For instance, rejection sampling can provide exact samples but is often difficult or impossible to apply due to the need to find a proposal distribution that upper-bounds the target distribution everywhere. Approximate Markov chain Monte Carlo sampling techniques like Metropolis-Hastings are usually easier to design, exploiting a local proposal distribution that performs local edits on an evolving sample. However, these techniques can be inefficient due to the local nature of the proposal distribution and do not provide an estimate of the quality of their samples. In this work, we propose a new approximate sampling technique, Quasi Rejection Sampling (QRS), that allows for a trade-off between sampling efficiency and sampling quality, while providing explicit convergence bounds and diagnostics. QRS capitalizes on the availability of high-quality global proposal distributions obtained from deep learning models. We demonstrate the effectiveness of QRS sampling for discrete EBMs over text for the tasks of controlled text generation with distributional constraints and paraphrase generation. We show that we can sample from such EBMs with arbitrary precision at the cost of sampling efficiency.
Controlling Conditional Language Models with Distributional Policy Gradients
Dec 01, 2021
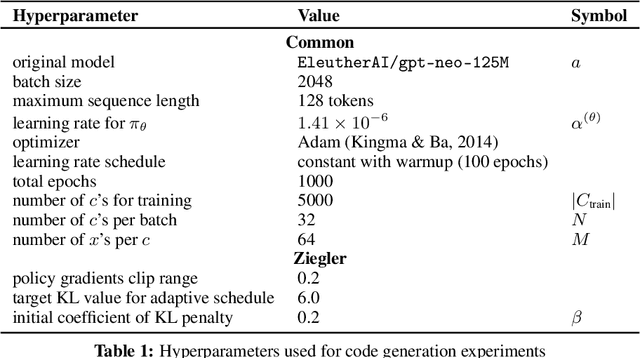
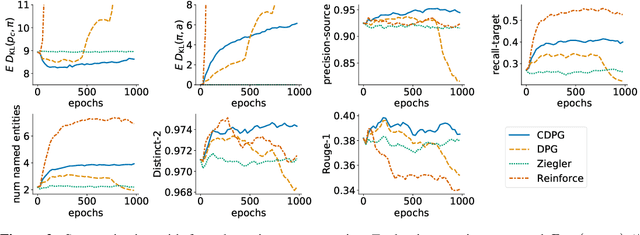
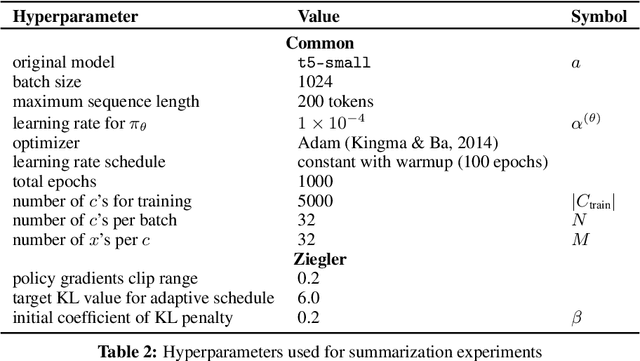
Machine learning is shifting towards general-purpose pretrained generative models, trained in a self-supervised manner on large amounts of data, which can then be applied to solve a large number of tasks. However, due to their generic training methodology, these models often fail to meet some of the downstream requirements (e.g. hallucination in abstractive summarization or wrong format in automatic code generation). This raises an important question on how to adapt pre-trained generative models to a new task without destroying its capabilities. Recent work has suggested to solve this problem by representing task-specific requirements through energy-based models (EBMs) and approximating these EBMs using distributional policy gradients (DPG). Unfortunately, this approach is limited to unconditional distributions, represented by unconditional EBMs. In this paper, we extend this approach to conditional tasks by proposing Conditional DPG (CDPG). We evaluate CDPG on three different control objectives across two tasks: summarization with T5 and code generation with GPT-Neo. Our results show that fine-tuning using CDPG robustly moves these pretrained models closer towards meeting control objectives and -- in contrast with baseline approaches -- does not result in catastrophic forgetting.
Unsupervised and Distributional Detection of Machine-Generated Text
Nov 04, 2021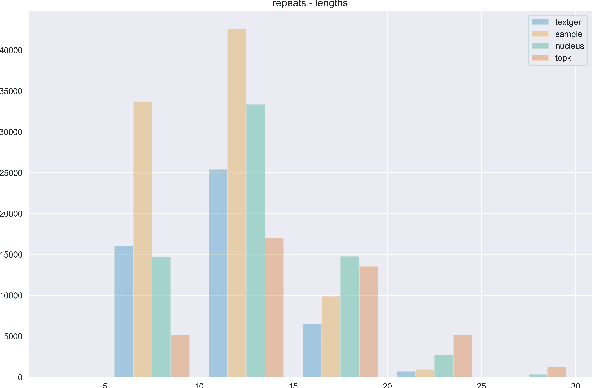
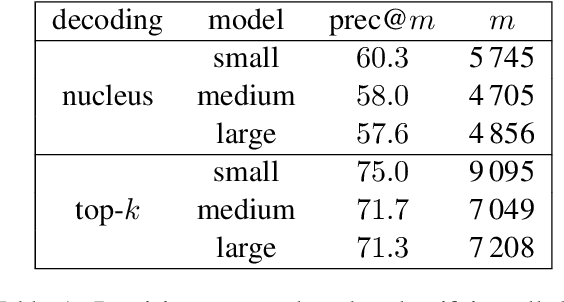

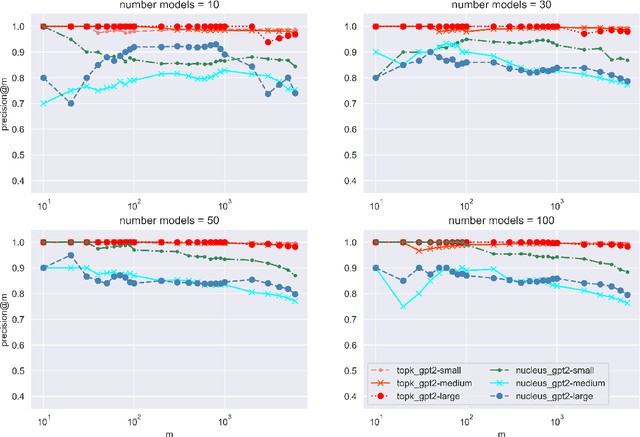
The power of natural language generation models has provoked a flurry of interest in automatic methods to detect if a piece of text is human or machine-authored. The problem so far has been framed in a standard supervised way and consists in training a classifier on annotated data to predict the origin of one given new document. In this paper, we frame the problem in an unsupervised and distributional way: we assume that we have access to a large collection of unannotated documents, a big fraction of which is machine-generated. We propose a method to detect those machine-generated documents leveraging repeated higher-order n-grams, which we show over-appear in machine-generated text as compared to human ones. That weak signal is the starting point of a self-training setting where pseudo-labelled documents are used to train an ensemble of classifiers. Our experiments show that leveraging that signal allows us to rank suspicious documents accurately. Precision at 5000 is over 90% for top-k sampling strategies, and over 80% for nucleus sampling for the largest model we used (GPT2-large). The drop with increased size of model is small, which could indicate that the results hold for other current and future large language models.
Energy-Based Models for Code Generation under Compilability Constraints
Jun 09, 2021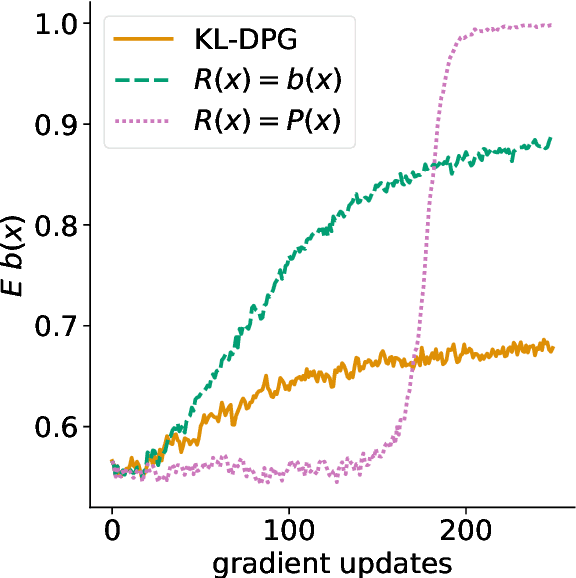
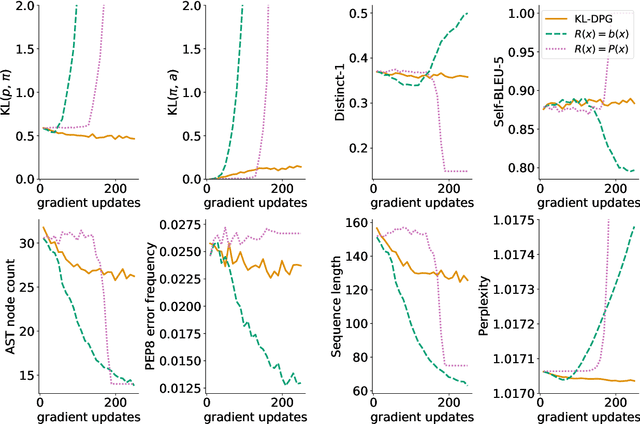

Neural language models can be successfully trained on source code, leading to applications such as code completion. However, their versatile autoregressive self-supervision objective overlooks important global sequence-level features that are present in the data such as syntactic correctness or compilability. In this work, we pose the problem of learning to generate compilable code as constraint satisfaction. We define an Energy-Based Model (EBM) representing a pre-trained generative model with an imposed constraint of generating only compilable sequences. We then use the KL-Adaptive Distributional Policy Gradient algorithm (Khalifa et al., 2021) to train a generative model approximating the EBM. We conduct experiments showing that our proposed approach is able to improve compilability rates without sacrificing diversity and complexity of the generated samples.
References in Wikipedia: The Editors' Perspective
Mar 04, 2021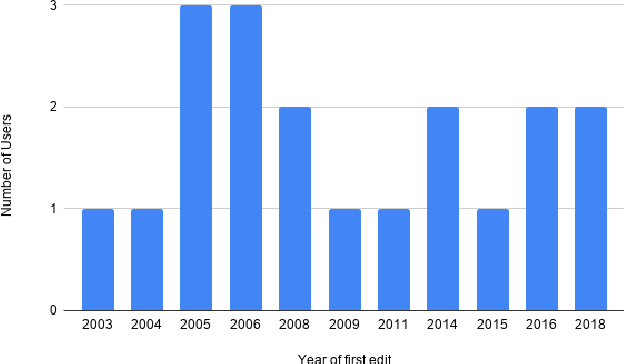
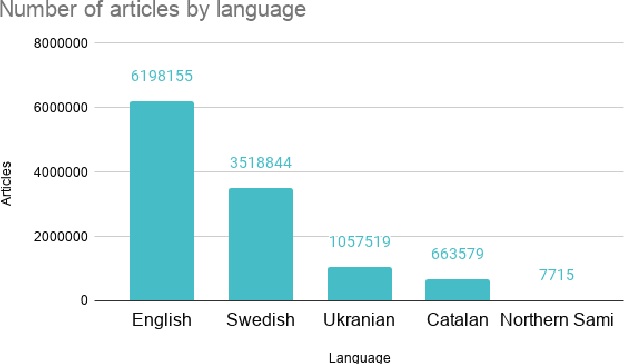
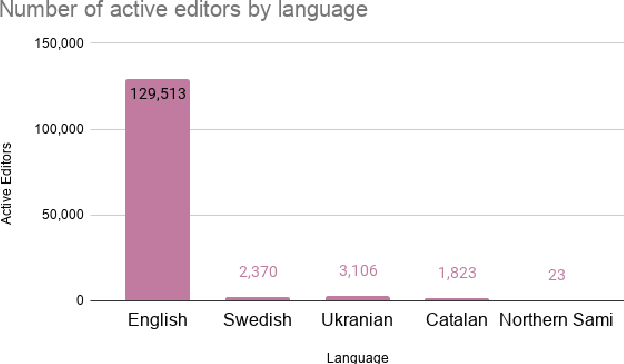
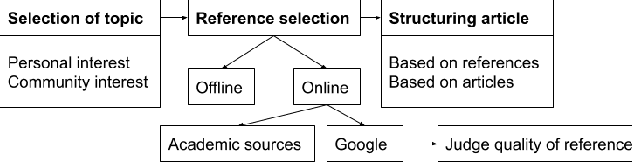
References are an essential part of Wikipedia. Each statement in Wikipedia should be referenced. In this paper, we explore the creation and collection of references for new Wikipedia articles from an editors' perspective. We map out the workflow of editors when creating a new article, emphasising how they select references.