 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation from the Information Bottleneck Perspective: an Efficiency Analysis of Spatial Prepositions in Bitexts
Mar 20, 2026Efficient communication requires balancing informativity and simplicity when encoding meanings. The Information Bottleneck (IB) framework captures this trade-off formally, predicting that natural language systems cluster near an optimal accuracy-complexity frontier. While supported in visual domains such as colour and motion, linguistic stimuli such as words in sentential context remain unexplored. We address this gap by framing translation as an IB optimisation problem, treating source sentences as stimuli and target sentences as compressed meanings. This allows IB analyses to be performed directly on bitexts rather than controlled naming experiments. We applied this to spatial prepositions across English, German and Serbian translations of a French novel. To estimate informativity, we conducted a pile-sorting pilot-study (N=35) and obtained similarity judgements of pairs of prepositions. We trained a low-rank projection model (D=5) that predicts these judgements (Spearman correlation: 0.78). Attested translations of prepositions lie closer to the IB optimal frontier than counterfactual alternatives, offering preliminary evidence that human translators exhibit communicative efficiency pressure in the spatial domain. More broadly, this work suggests that translation can serve as a window into the cognitive efficiency pressures shaping cross-linguistic semantic systems.
Zero-Shot Question Generation from Knowledge Graphs for Unseen Predicates and Entity Types
Feb 19, 2018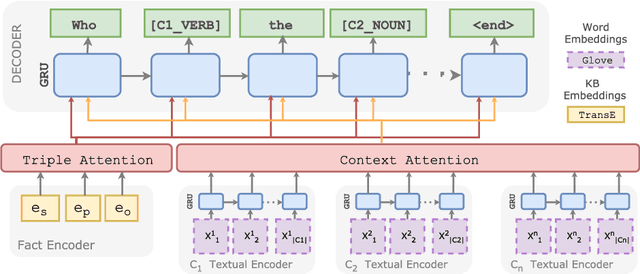
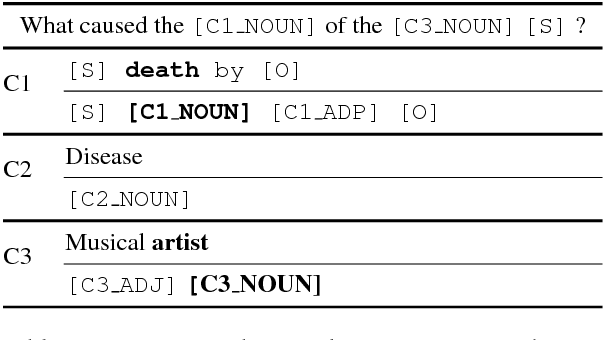

We present a neural model for question generation from knowledge base triples in a "Zero-Shot" setup, that is generating questions for triples containing predicates, subject types or object types that were not seen at training time. Our model leverages triples occurrences in the natural language corpus in an encoder-decoder architecture, paired with an original part-of-speech copy action mechanism to generate questions. Benchmark and human evaluation show that our model sets a new state-of-the-art for zero-shot QG.
Unsupervised Open Relation Extraction
Jan 22, 2018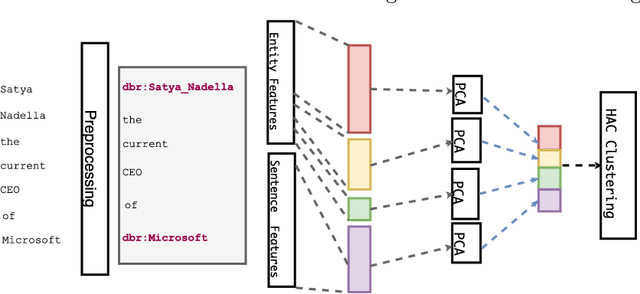

We explore methods to extract relations between named entities from free text in an unsupervised setting. In addition to standard feature extraction, we develop a novel method to re-weight word embeddings. We alleviate the problem of features sparsity using an individual feature reduction. Our approach exhibits a significant improvement by 5.8% over the state-of-the-art relation clustering scoring a F1-score of 0.416 on the NYT-FB dataset.
Neural Wikipedian: Generating Textual Summaries from Knowledge Base Triples
Nov 01, 2017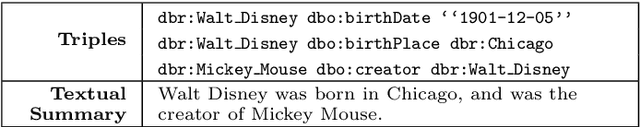
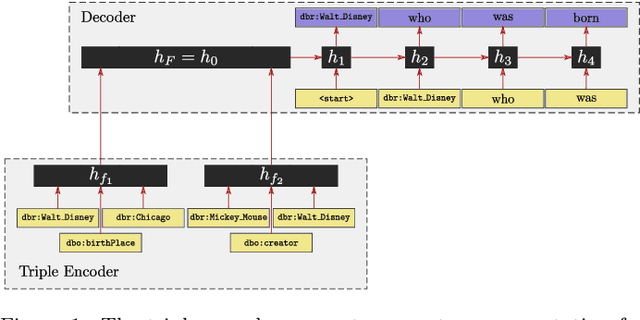
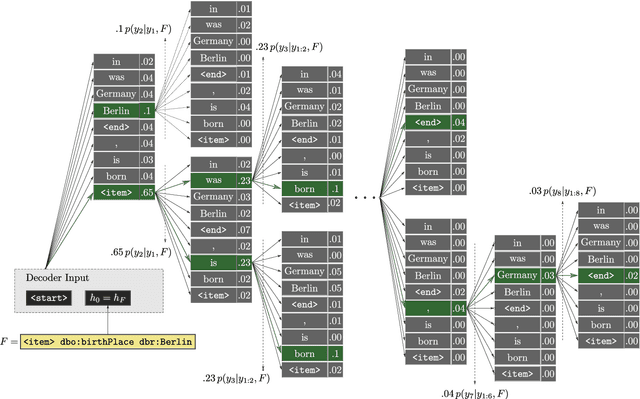

Most people do not interact with Semantic Web data directly. Unless they have the expertise to understand the underlying technology, they need textual or visual interfaces to help them make sense of it. We explore the problem of generating natural language summaries for Semantic Web data. This is non-trivial, especially in an open-domain context. To address this problem, we explore the use of neural networks. Our system encodes the information from a set of triples into a vector of fixed dimensionality and generates a textual summary by conditioning the output on the encoded vector. We train and evaluate our models on two corpora of loosely aligned Wikipedia snippets and DBpedia and Wikidata triples with promising results.