 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Control and Learning Using Generalized Action Governor
Nov 22, 2022



This paper introduces the Generalized Action Governor, which is a supervisory scheme for augmenting a nominal closed-loop system with the capability of strictly handling constraints. After presenting its theory for general systems and introducing tailored design approaches for linear and discrete systems, we discuss its application to safe online learning, which aims to safely evolve control parameters using real-time data to improve performance for uncertain systems. In particular, we propose two safe learning algorithms based on integration of reinforcement learning/data-driven Koopman operator-based control with the generalized action governor. The developments are illustrated with a numerical example.
Robust Action Governor for Uncertain Piecewise Affine Systems with Non-convex Constraints and Safe Reinforcement Learning
Jul 17, 2022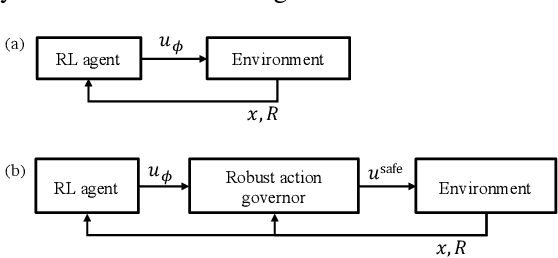
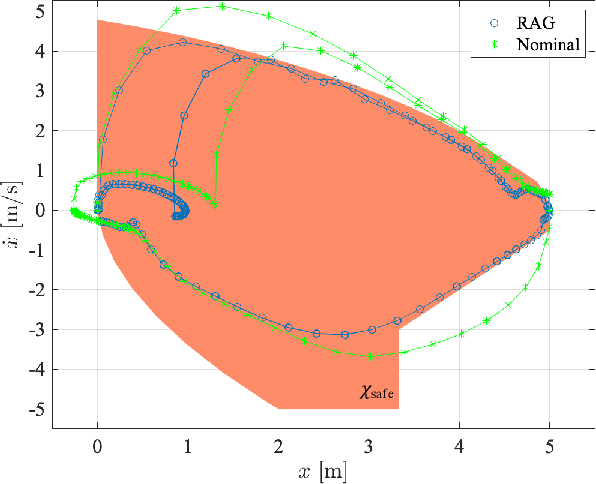
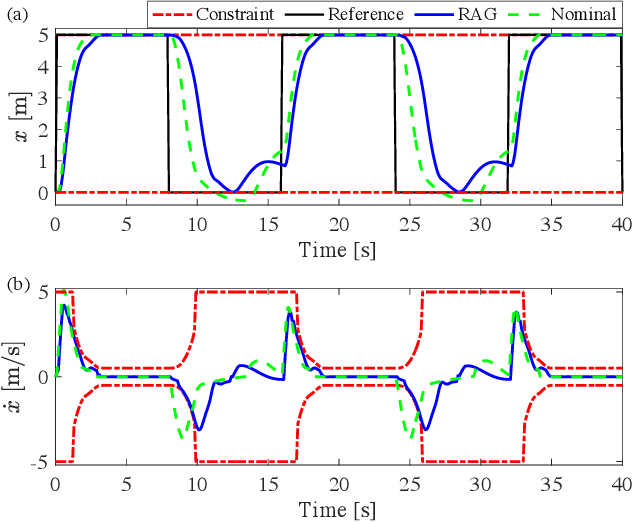
The action governor is an add-on scheme to a nominal control loop that monitors and adjusts the control actions to enforce safety specifications expressed as pointwise-in-time state and control constraints. In this paper, we introduce the Robust Action Governor (RAG) for systems the dynamics of which can be represented using discrete-time Piecewise Affine (PWA) models with both parametric and additive uncertainties and subject to non-convex constraints. We develop the theoretical properties and computational approaches for the RAG. After that, we introduce the use of the RAG for realizing safe Reinforcement Learning (RL), i.e., ensuring all-time constraint satisfaction during online RL exploration-and-exploitation process. This development enables safe real-time evolution of the control policy and adaptation to changes in the operating environment and system parameters (due to aging, damage, etc.). We illustrate the effectiveness of the RAG in constraint enforcement and safe RL using the RAG by considering their applications to a soft-landing problem of a mass-spring-damper system.
Interaction-Aware Trajectory Prediction and Planning for Autonomous Vehicles in Forced Merge Scenarios
Dec 14, 2021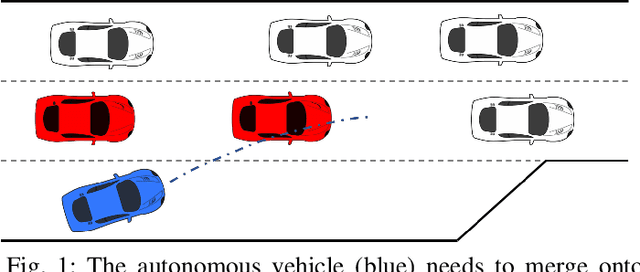
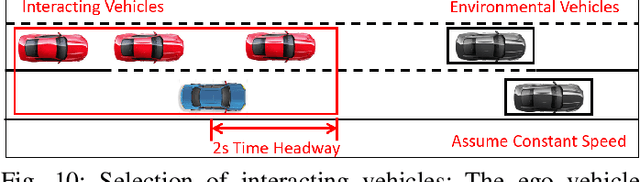
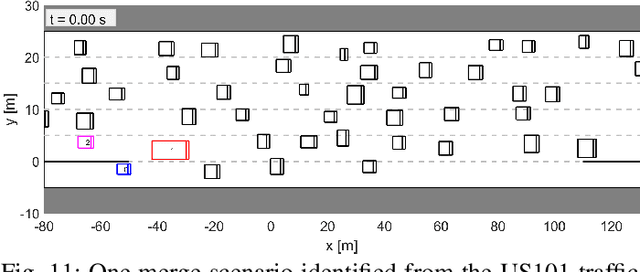

Merging is, in general, a challenging task for both human drivers and autonomous vehicles, especially in dense traffic, because the merging vehicle typically needs to interact with other vehicles to identify or create a gap and safely merge into. In this paper, we consider the problem of autonomous vehicle control for forced merge scenarios. We propose a novel game-theoretic controller, called the Leader-Follower Game Controller (LFGC), in which the interactions between the autonomous ego vehicle and other vehicles with a priori uncertain driving intentions is modeled as a partially observable leader-follower game. The LFGC estimates the other vehicles' intentions online based on observed trajectories, and then predicts their future trajectories and plans the ego vehicle's own trajectory using Model Predictive Control (MPC) to simultaneously achieve probabilistically guaranteed safety and merging objectives. To verify the performance of LFGC, we test it in simulations and with the NGSIM data, where the LFGC demonstrates a high success rate of 97.5% in merging.
Stochastic MPC with Multi-modal Predictions for Traffic Intersections
Sep 26, 2021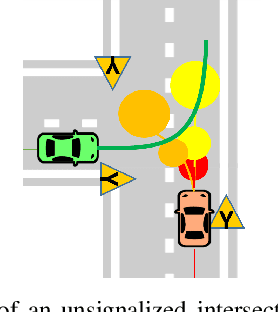
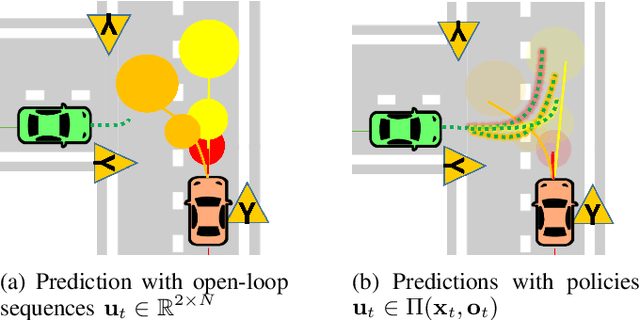
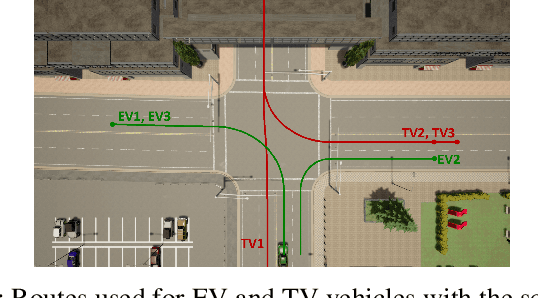
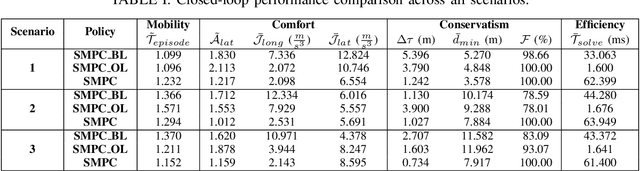
We propose a Stochastic MPC (SMPC) formulation for autonomous driving at traffic intersections which incorporates multi-modal predictions of surrounding vehicles for collision avoidance constraints. The multi-modal predictions are obtained with Gaussian Mixture Models (GMM) and constraints are formulated as chance-constraints. Our main theoretical contribution is a SMPC formulation that optimizes over a novel feedback policy class designed to exploit additional structure in the GMM predictions, and that is amenable to convex programming. The use of feedback policies for prediction is motivated by the need for reduced conservatism in handling multi-modal predictions of the surrounding vehicles, especially prevalent in traffic intersection scenarios. We evaluate our algorithm along axes of mobility, comfort, conservatism and computational efficiency at a simulated intersection in CARLA. Our simulations use a kinematic bicycle model and multimodal predictions trained on a subset of the Lyft Level 5 prediction dataset. To demonstrate the impact of optimizing over feedback policies, we compare our algorithm with two SMPC baselines that handle multi-modal collision avoidance chance constraints by optimizing over open-loop sequences.
Prior Is All You Need to Improve the Robustness and Safety for the First Time Deployment of Meta RL
Aug 19, 2021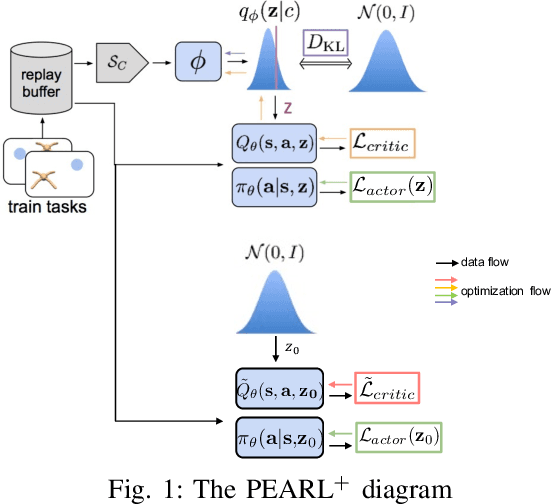

The field of Meta Reinforcement Learning (Meta-RL) has seen substantial advancements recently. In particular, off-policy methods were developed to improve the data efficiency of Meta-RL techniques. \textit{Probabilistic embeddings for actor-critic RL} (PEARL) is currently one of the leading approaches for multi-MDP adaptation problems. A major drawback of many existing Meta-RL methods, including PEARL, is that they do not explicitly consider the safety of the prior policy when it is exposed to a new task for the very first time. This is very important for some real-world applications, including field robots and Autonomous Vehicles (AVs). In this paper, we develop the PEARL PLUS (PEARL$^+$) algorithm, which optimizes the policy for both prior safety and posterior adaptation. Building on top of PEARL, our proposed PEARL$^+$ algorithm introduces a prior regularization term in the reward function and a new Q-network for recovering the state-action value with prior context assumption, to improve the robustness and safety of the trained network exposing to a new task for the first time. The performance of the PEARL$^+$ method is demonstrated by solving three safety-critical decision-making problems related to robots and AVs, including two MuJoCo benchmark problems. From the simulation experiments, we show that the safety of the prior policy is significantly improved compared to that of the original PEARL method.
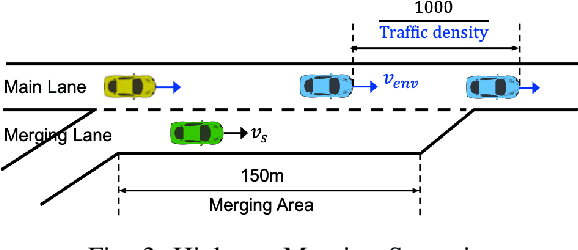
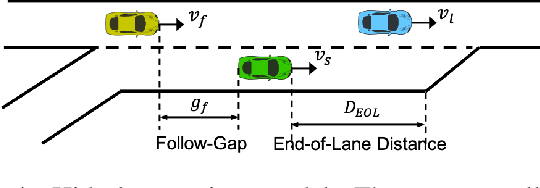
Quick Learner Automated Vehicle Adapting its Roadmanship to Varying Traffic Cultures with Meta Reinforcement Learning
Apr 18, 2021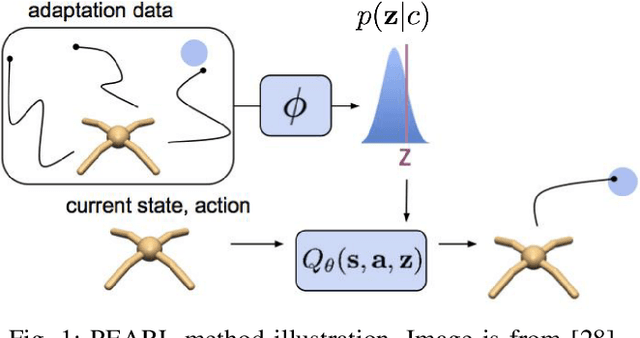

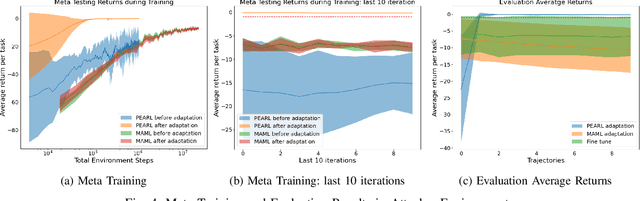
It is essential for an automated vehicle in the field to perform discretionary lane changes with appropriate roadmanship - driving safely and efficiently without annoying or endangering other road users - under a wide range of traffic cultures and driving conditions. While deep reinforcement learning methods have excelled in recent years and been applied to automated vehicle driving policy, there are concerns about their capability to quickly adapt to unseen traffic with new environment dynamics. We formulate this challenge as a multi-Markov Decision Processes (MDPs) adaptation problem and developed Meta Reinforcement Learning (MRL) driving policies to showcase their quick learning capability. Two types of distribution variation in environments were designed and simulated to validate the fast adaptation capability of resulting MRL driving policies which significantly outperform a baseline RL.
Safe Reinforcement Learning Using Robust Action Governor
Feb 21, 2021
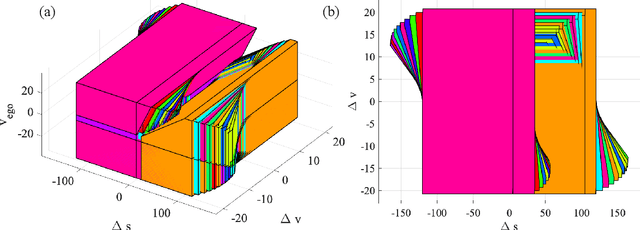
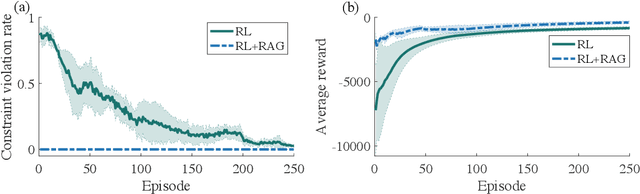
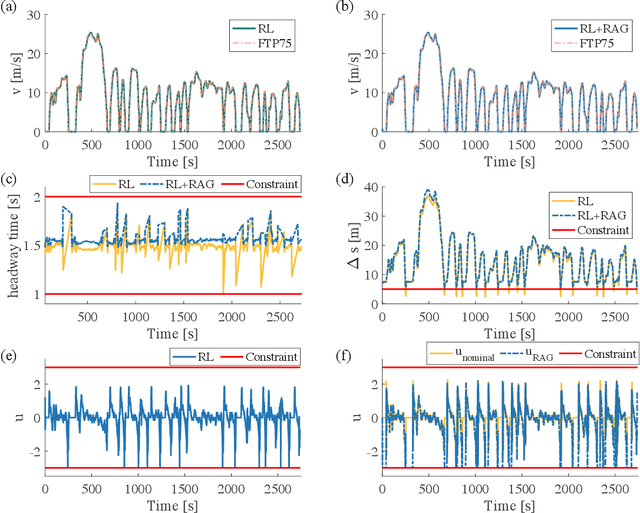
Reinforcement Learning (RL) is essentially a trial-and-error learning procedure which may cause unsafe behavior during the exploration-and-exploitation process. This hinders the applications of RL to real-world control problems, especially to those for safety-critical systems. In this paper, we introduce a framework for safe RL that is based on integration of an RL algorithm with an add-on safety supervision module, called the Robust Action Governor (RAG), which exploits set-theoretic techniques and online optimization to manage safety-related requirements during learning. We illustrate this proposed safe RL framework through an application to automotive adaptive cruise control.
A Game Theoretic Approach for Parking Spot Search with Limited Parking Lot Information
May 11, 2020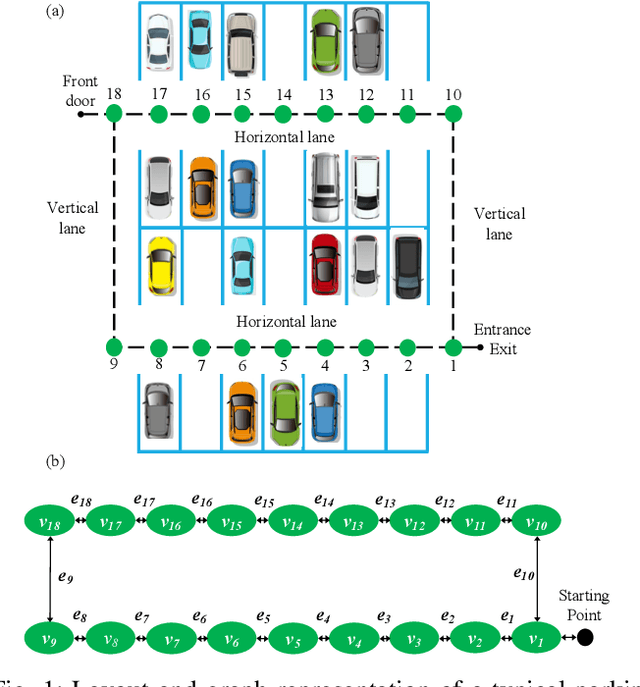
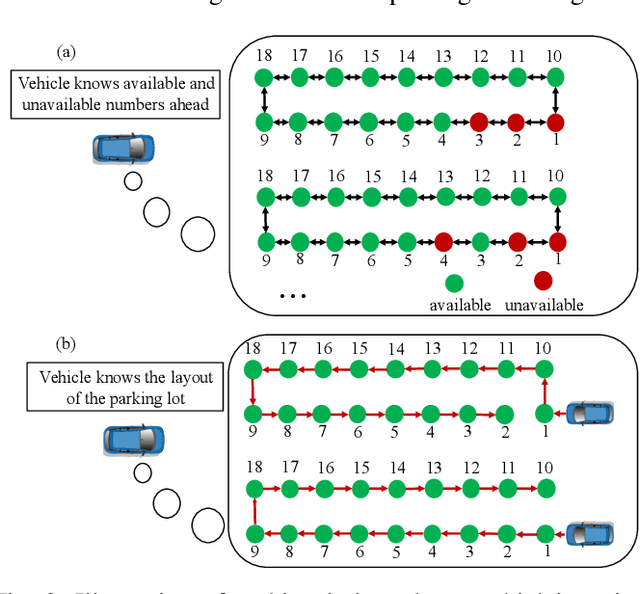


We propose a game theoretic approach to address the problem of searching for available parking spots in a parking lot and picking the ``optimal'' one to park. The approach exploits limited information provided by the parking lot, i.e., its layout and the current number of cars in it. Considering the fact that such information is or can be easily made available for many structured parking lots, the proposed approach can be applicable without requiring major updates to existing parking facilities. For large parking lots, a sampling-based strategy is integrated with the proposed approach to overcome the associated computational challenge. The proposed approach is compared against a state-of-the-art heuristic-based parking spot search strategy in the literature through simulation studies and demonstrates its advantage in terms of achieving lower cost function values.
Generating Socially Acceptable Perturbations for Efficient Evaluation of Autonomous Vehicles
Mar 18, 2020

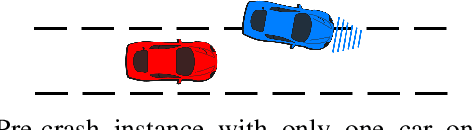
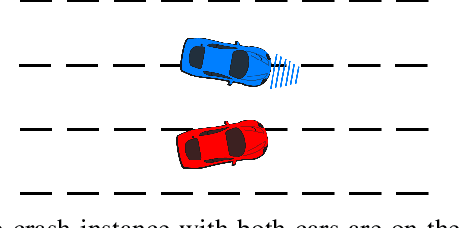
Deep reinforcement learning methods have been widely used in recent years for autonomous vehicle's decision-making. A key issue is that deep neural networks can be fragile to adversarial attacks or other unseen inputs. In this paper, we address the latter issue: we focus on generating socially acceptable perturbations (SAP), so that the autonomous vehicle (AV agent), instead of the challenging vehicle (attacker), is primarily responsible for the crash. In our process, one attacker is added to the environment and trained by deep reinforcement learning to generate the desired perturbation. The reward is designed so that the attacker aims to fail the AV agent in a socially acceptable way. After training the attacker, the agent policy is evaluated in both the original naturalistic environment and the environment with one attacker. The results show that the agent policy which is safe in the naturalistic environment has many crashes in the perturbed environment.
Deep Reinforcement Learning with Enhanced Safety for Autonomous Highway Driving
Oct 28, 2019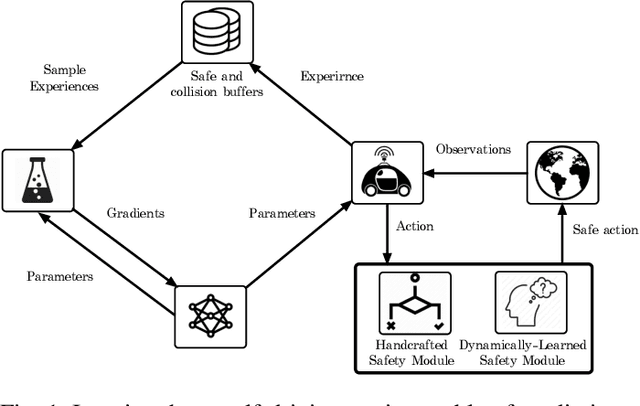
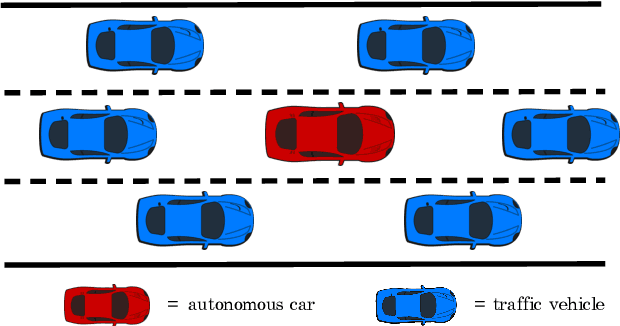
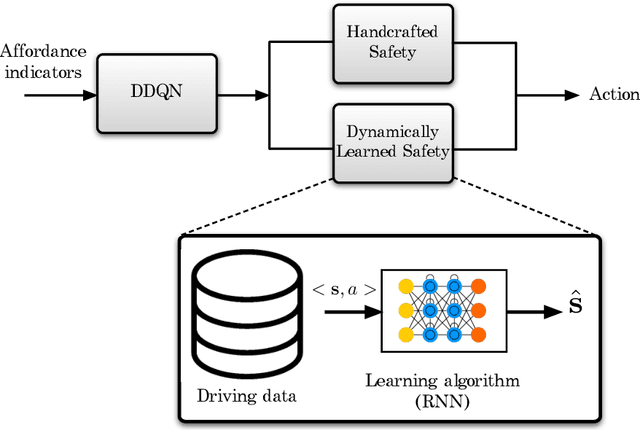
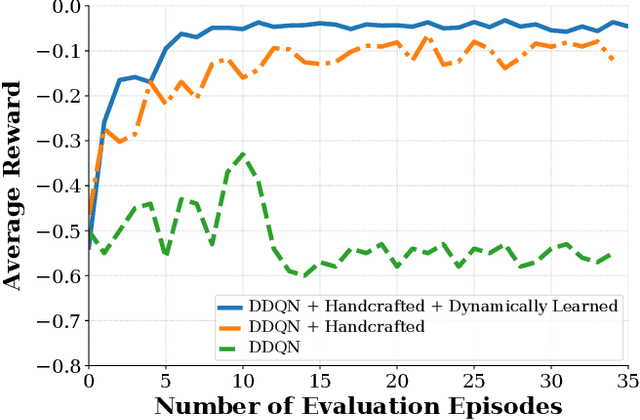
In this paper, we present a safe deep reinforcement learning system for automated driving. The proposed framework leverages merits of both rule-based and learning-based approaches for safety assurance. Our safety system consists of two modules namely handcrafted safety and dynamically-learned safety. The handcrafted safety module is a heuristic safety rule based on common driving practice that ensure a minimum relative gap to a traffic vehicle. On the other hand, the dynamically-learned safety module is a data-driven safety rule that learns safety patterns from driving data. Specifically, the dynamically-leaned safety module incorporates a model lookahead beyond the immediate reward of reinforcement learning to predict safety longer into the future. If one of the future states leads to a near-miss or collision, then a negative reward will be assigned to the reward function to avoid collision and accelerate the learning process. We demonstrate the capability of the proposed framework in a simulation environment with varying traffic density. Our results show the superior capabilities of the policy enhanced with dynamically-learned safety module.