 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Adaptive Transformations for Weakly Supervised Point Cloud Segmentation
Jul 19, 2022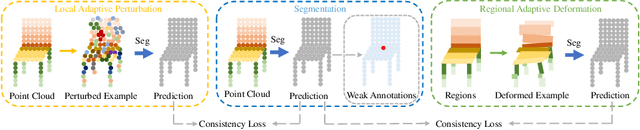
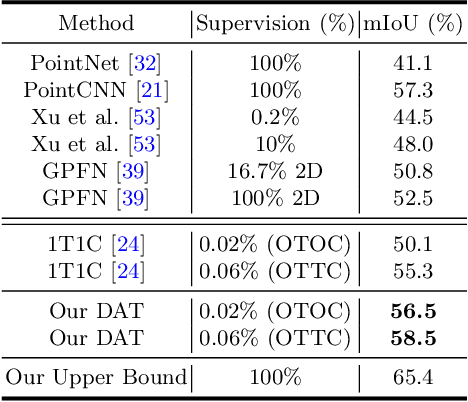
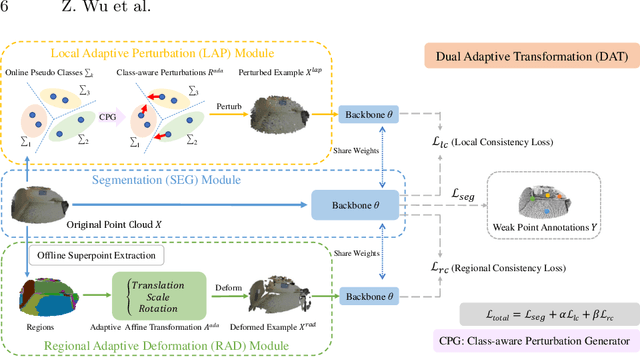

Weakly supervised point cloud segmentation, i.e. semantically segmenting a point cloud with only a few labeled points in the whole 3D scene, is highly desirable due to the heavy burden of collecting abundant dense annotations for the model training. However, existing methods remain challenging to accurately segment 3D point clouds since limited annotated data may lead to insufficient guidance for label propagation to unlabeled data. Considering the smoothness-based methods have achieved promising progress, in this paper, we advocate applying the consistency constraint under various perturbations to effectively regularize unlabeled 3D points. Specifically, we propose a novel DAT (\textbf{D}ual \textbf{A}daptive \textbf{T}ransformations) model for weakly supervised point cloud segmentation, where the dual adaptive transformations are performed via an adversarial strategy at both point-level and region-level, aiming at enforcing the local and structural smoothness constraints on 3D point clouds. We evaluate our proposed DAT model with two popular backbones on the large-scale S3DIS and ScanNet-V2 datasets. Extensive experiments demonstrate that our model can effectively leverage the unlabeled 3D points and achieve significant performance gains on both datasets, setting new state-of-the-art performance for weakly supervised point cloud segmentation.
Few-shot Open-set Recognition Using Background as Unknowns
Jul 19, 2022
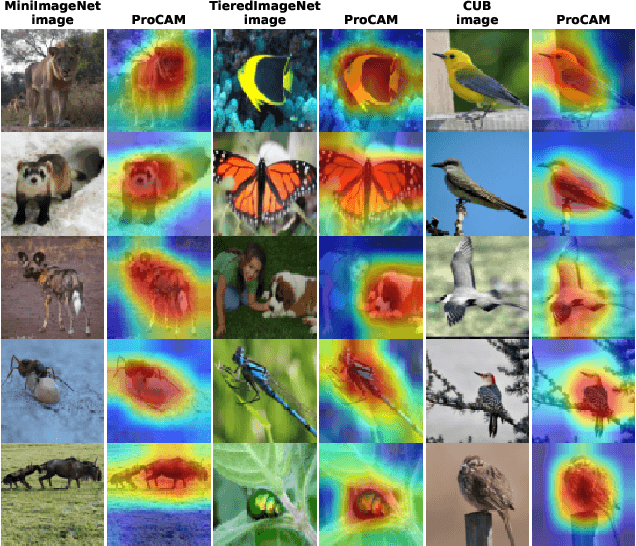
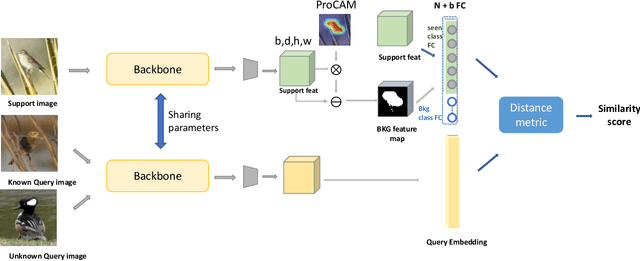
Few-shot open-set recognition aims to classify both seen and novel images given only limited training data of seen classes. The challenge of this task is that the model is required not only to learn a discriminative classifier to classify the pre-defined classes with few training data but also to reject inputs from unseen classes that never appear at training time. In this paper, we propose to solve the problem from two novel aspects. First, instead of learning the decision boundaries between seen classes, as is done in standard close-set classification, we reserve space for unseen classes, such that images located in these areas are recognized as the unseen classes. Second, to effectively learn such decision boundaries, we propose to utilize the background features from seen classes. As these background regions do not significantly contribute to the decision of close-set classification, it is natural to use them as the pseudo unseen classes for classifier learning. Our extensive experiments show that our proposed method not only outperforms multiple baselines but also sets new state-of-the-art results on three popular benchmarks, namely tieredImageNet, miniImageNet, and Caltech-USCD Birds-200-2011 (CUB).
Long-tailed Recognition by Learning from Latent Categories
Jun 02, 2022
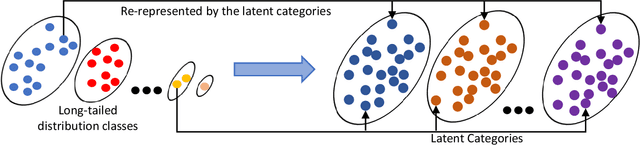
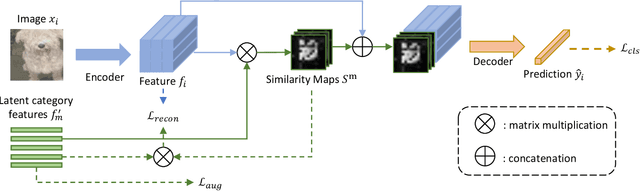

In this work, we address the challenging task of long-tailed image recognition. Previous long-tailed recognition methods commonly focus on the data augmentation or re-balancing strategy of the tail classes to give more attention to tail classes during the model training. However, due to the limited training images for tail classes, the diversity of tail class images is still restricted, which results in poor feature representations. In this work, we hypothesize that common latent features among the head and tail classes can be used to give better feature representation. Motivated by this, we introduce a Latent Categories based long-tail Recognition (LCReg) method. Specifically, we propose to learn a set of class-agnostic latent features shared among the head and tail classes. Then, we implicitly enrich the training sample diversity via applying semantic data augmentation to the latent features. Extensive experiments on five long-tailed image recognition datasets demonstrate that our proposed LCReg is able to significantly outperform previous methods and achieve state-of-the-art results.
Efficient Few-Shot Object Detection via Knowledge Inheritance
Mar 23, 2022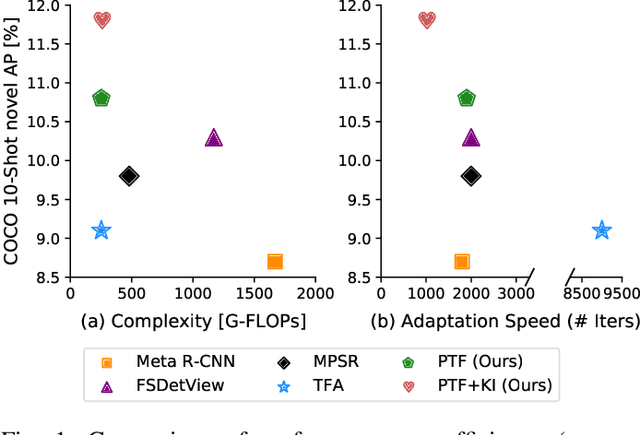
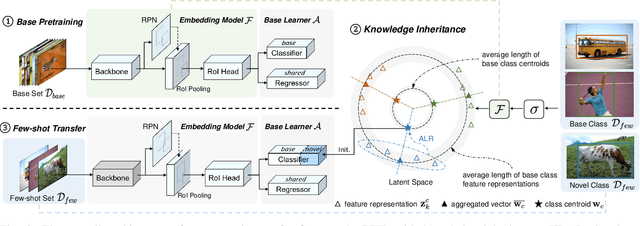
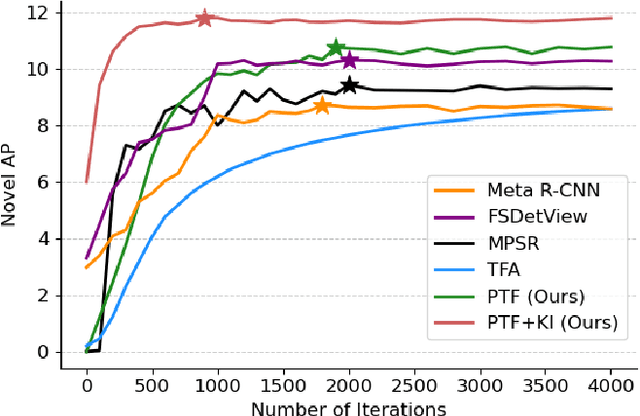
Few-shot object detection (FSOD), which aims at learning a generic detector that can adapt to unseen tasks with scarce training samples, has witnessed consistent improvement recently. However, most existing methods ignore the efficiency issues, e.g., high computational complexity and slow adaptation speed. Notably, efficiency has become an increasingly important evaluation metric for few-shot techniques due to an emerging trend toward embedded AI. To this end, we present an efficient pretrain-transfer framework (PTF) baseline with no computational increment, which achieves comparable results with previous state-of-the-art (SOTA) methods. Upon this baseline, we devise an initializer named knowledge inheritance (KI) to reliably initialize the novel weights for the box classifier, which effectively facilitates the knowledge transfer process and boosts the adaptation speed. Within the KI initializer, we propose an adaptive length re-scaling (ALR) strategy to alleviate the vector length inconsistency between the predicted novel weights and the pretrained base weights. Finally, our approach not only achieves the SOTA results across three public benchmarks, i.e., PASCAL VOC, COCO and LVIS, but also exhibits high efficiency with 1.8-9.0x faster adaptation speed against the other methods on COCO/LVIS benchmark during few-shot transfer. To our best knowledge, this is the first work to consider the efficiency problem in FSOD. We hope to motivate a trend toward powerful yet efficient few-shot technique development. The codes are publicly available at https://github.com/Ze-Yang/Efficient-FSOD.
A Unified Transformer Framework for Group-based Segmentation: Co-Segmentation, Co-Saliency Detection and Video Salient Object Detection
Mar 11, 2022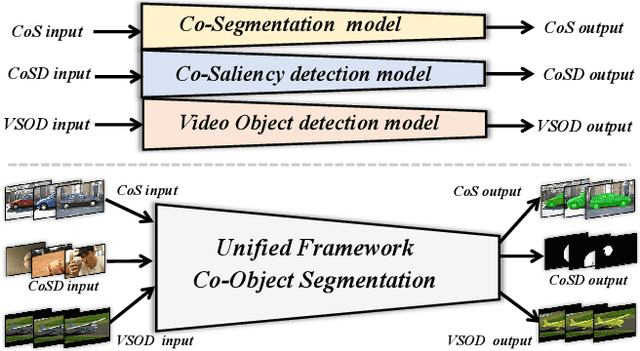
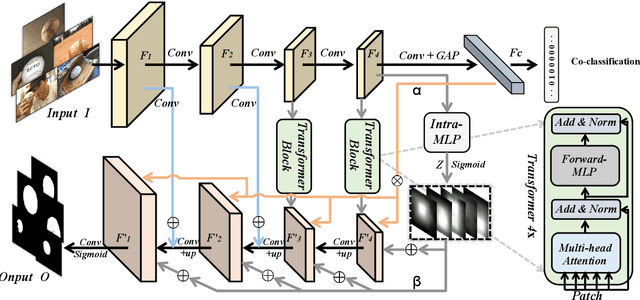
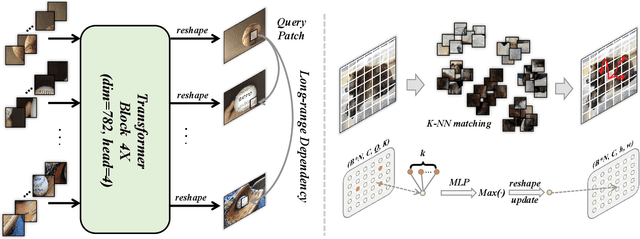
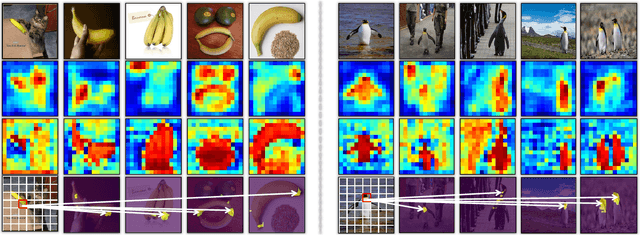
Humans tend to mine objects by learning from a group of images or several frames of video since we live in a dynamic world. In the computer vision area, many researches focus on co-segmentation (CoS), co-saliency detection (CoSD) and video salient object detection (VSOD) to discover the co-occurrent objects. However, previous approaches design different networks on these similar tasks separately, and they are difficult to apply to each other, which lowers the upper bound of the transferability of deep learning frameworks. Besides, they fail to take full advantage of the cues among inter- and intra-feature within a group of images. In this paper, we introduce a unified framework to tackle these issues, term as UFO (Unified Framework for Co-Object Segmentation). Specifically, we first introduce a transformer block, which views the image feature as a patch token and then captures their long-range dependencies through the self-attention mechanism. This can help the network to excavate the patch structured similarities among the relevant objects. Furthermore, we propose an intra-MLP learning module to produce self-mask to enhance the network to avoid partial activation. Extensive experiments on four CoS benchmarks (PASCAL, iCoseg, Internet and MSRC), three CoSD benchmarks (Cosal2015, CoSOD3k, and CocA) and four VSOD benchmarks (DAVIS16, FBMS, ViSal and SegV2) show that our method outperforms other state-of-the-arts on three different tasks in both accuracy and speed by using the same network architecture , which can reach 140 FPS in real-time.
Self-Training Vision Language BERTs with a Unified Conditional Model
Jan 06, 2022
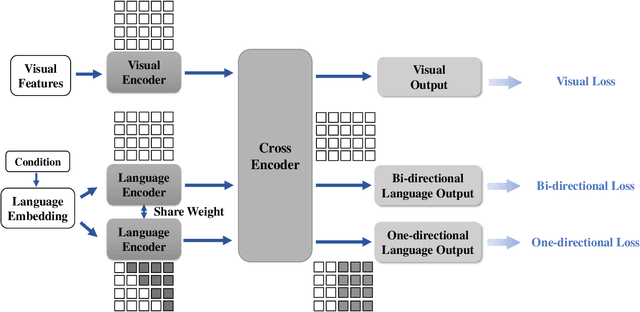
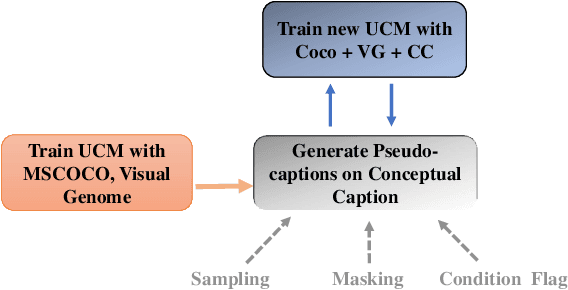

Natural language BERTs are trained with language corpus in a self-supervised manner. Unlike natural language BERTs, vision language BERTs need paired data to train, which restricts the scale of VL-BERT pretraining. We propose a self-training approach that allows training VL-BERTs from unlabeled image data. The proposed method starts with our unified conditional model -- a vision language BERT model that can perform zero-shot conditional generation. Given different conditions, the unified conditional model can generate captions, dense captions, and even questions. We use the labeled image data to train a teacher model and use the trained model to generate pseudo captions on unlabeled image data. We then combine the labeled data and pseudo labeled data to train a student model. The process is iterated by putting the student model as a new teacher. By using the proposed self-training approach and only 300k unlabeled extra data, we are able to get competitive or even better performances compared to the models of similar model size trained with 3 million extra image data.
Improving Tail-Class Representation with Centroid Contrastive Learning
Oct 19, 2021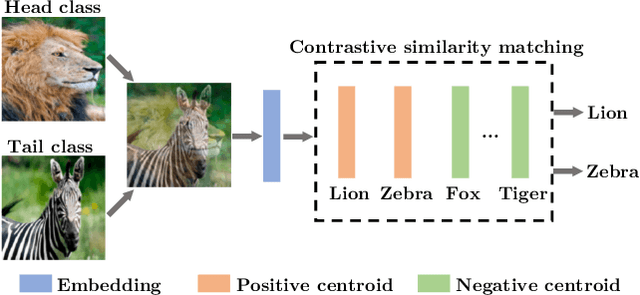
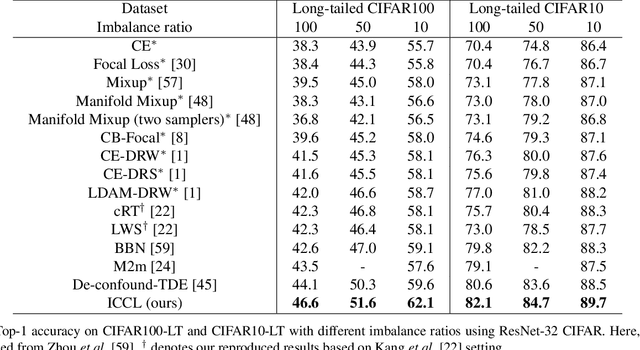
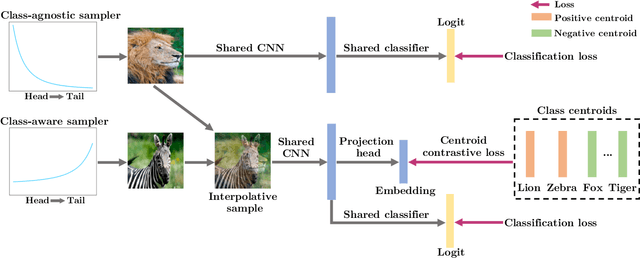
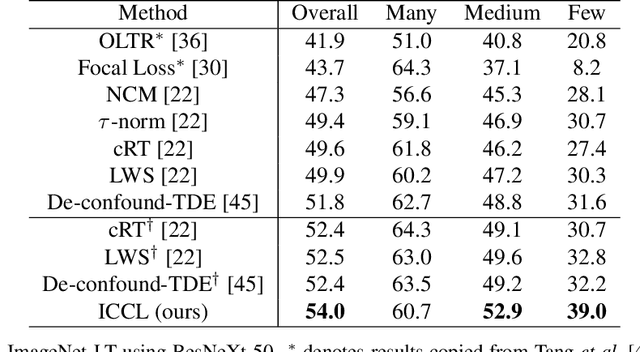
In vision domain, large-scale natural datasets typically exhibit long-tailed distribution which has large class imbalance between head and tail classes. This distribution poses difficulty in learning good representations for tail classes. Recent developments have shown good long-tailed model can be learnt by decoupling the training into representation learning and classifier balancing. However, these works pay insufficient consideration on the long-tailed effect on representation learning. In this work, we propose interpolative centroid contrastive learning (ICCL) to improve long-tailed representation learning. ICCL interpolates two images from a class-agnostic sampler and a class-aware sampler, and trains the model such that the representation of the interpolative image can be used to retrieve the centroids for both source classes. We demonstrate the effectiveness of our approach on multiple long-tailed image classification benchmarks. Our result shows a significant accuracy gain of 2.8% on the iNaturalist 2018 dataset with a real-world long-tailed distribution.
3D Pose Transfer with Correspondence Learning and Mesh Refinement
Oct 04, 2021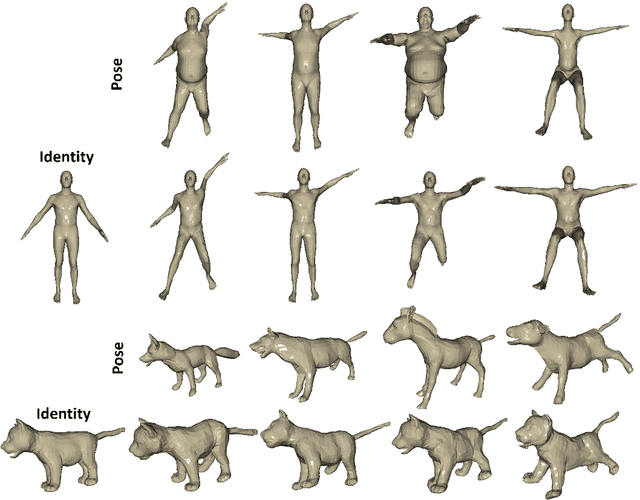
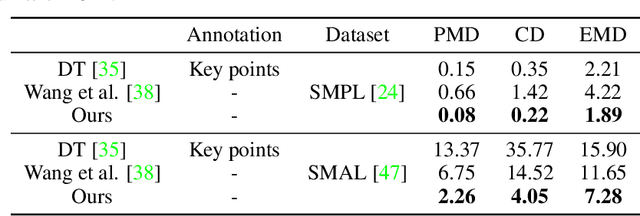
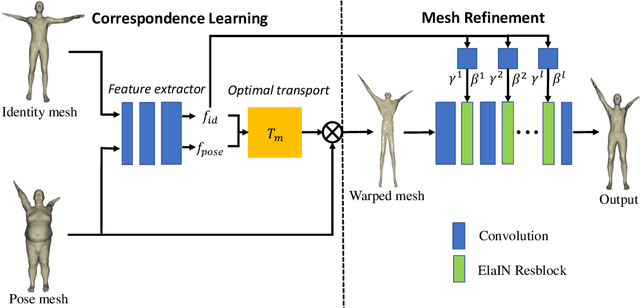

3D pose transfer is one of the most challenging 3D generation tasks. It aims to transfer the pose of a source mesh to a target mesh and keep the identity (e.g., body shape) of the target mesh. Some previous works require key point annotations to build reliable correspondence between the source and target meshes, while other methods do not consider any shape correspondence between sources and targets, which leads to limited generation quality. In this work, we propose a correspondence-refinement network to help the 3D pose transfer for both human and animal meshes. The correspondence between source and target meshes is first established by solving an optimal transport problem. Then, we warp the source mesh according to the dense correspondence and obtain a coarse warped mesh. The warped mesh will be better refined with our proposed Elastic Instance Normalization, which is a conditional normalization layer and can help to generate high-quality meshes. Extensive experimental results show that the proposed architecture can effectively transfer the poses from source to target meshes and produce better results with satisfied visual performance than state-of-the-art methods.
Learning Structural Representations for Recipe Generation and Food Retrieval
Oct 04, 2021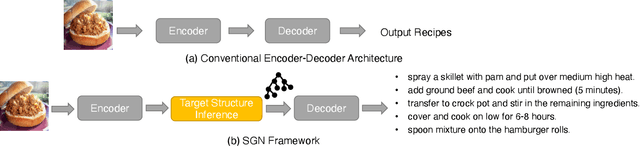
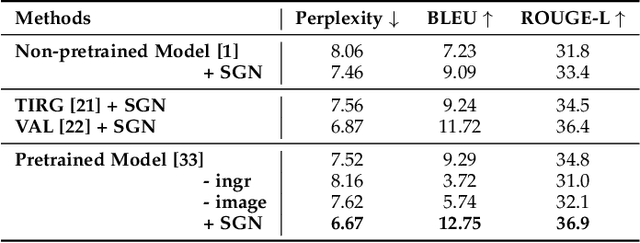
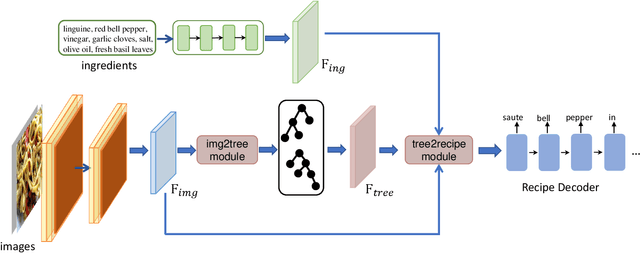
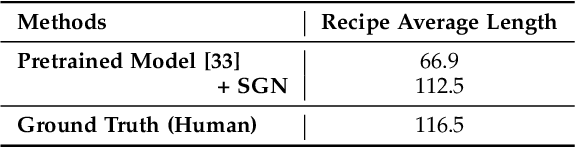
Food is significant to human daily life. In this paper, we are interested in learning structural representations for lengthy recipes, that can benefit the recipe generation and food retrieval tasks. We mainly investigate an open research task of generating cooking instructions based on food images and ingredients, which is similar to the image captioning task. However, compared with image captioning datasets, the target recipes are lengthy paragraphs and do not have annotations on structure information. To address the above limitations, we propose a novel framework of Structure-aware Generation Network (SGN) to tackle the food recipe generation task. Our approach brings together several novel ideas in a systematic framework: (1) exploiting an unsupervised learning approach to obtain the sentence-level tree structure labels before training; (2) generating trees of target recipes from images with the supervision of tree structure labels learned from (1); and (3) integrating the inferred tree structures into the recipe generation procedure. Our proposed model can produce high-quality and coherent recipes, and achieve the state-of-the-art performance on the benchmark Recipe1M dataset. We also validate the usefulness of our learned tree structures in the food cross-modal retrieval task, where the proposed model with tree representations can outperform state-of-the-art benchmark results.
Meta Navigator: Search for a Good Adaptation Policy for Few-shot Learning
Sep 13, 2021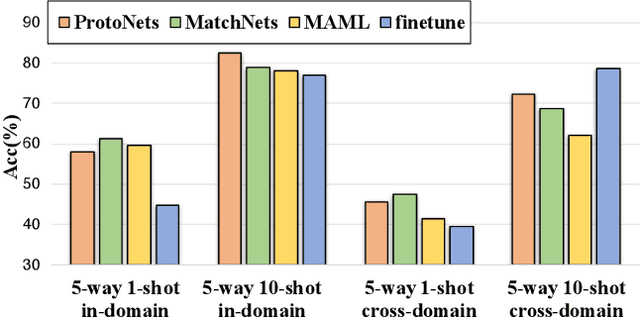
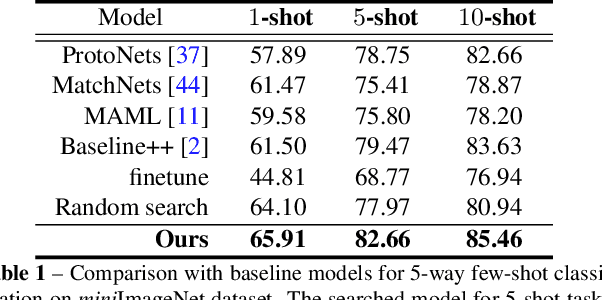
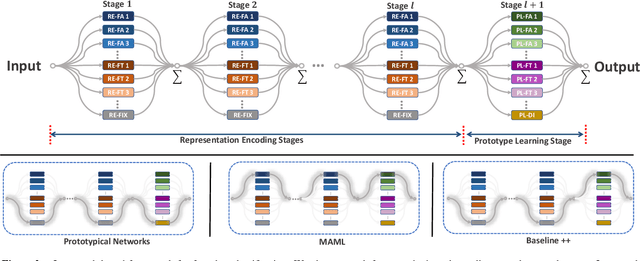
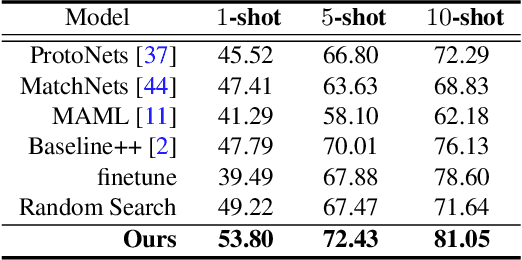
Few-shot learning aims to adapt knowledge learned from previous tasks to novel tasks with only a limited amount of labeled data. Research literature on few-shot learning exhibits great diversity, while different algorithms often excel at different few-shot learning scenarios. It is therefore tricky to decide which learning strategies to use under different task conditions. Inspired by the recent success in Automated Machine Learning literature (AutoML), in this paper, we present Meta Navigator, a framework that attempts to solve the aforementioned limitation in few-shot learning by seeking a higher-level strategy and proffer to automate the selection from various few-shot learning designs. The goal of our work is to search for good parameter adaptation policies that are applied to different stages in the network for few-shot classification. We present a search space that covers many popular few-shot learning algorithms in the literature and develop a differentiable searching and decoding algorithm based on meta-learning that supports gradient-based optimization. We demonstrate the effectiveness of our searching-based method on multiple benchmark datasets. Extensive experiments show that our approach significantly outperforms baselines and demonstrates performance advantages over many state-of-the-art methods. Code and models will be made publicly available.