 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Attention Unit
Oct 30, 2018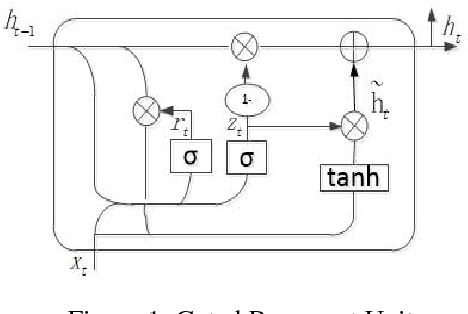
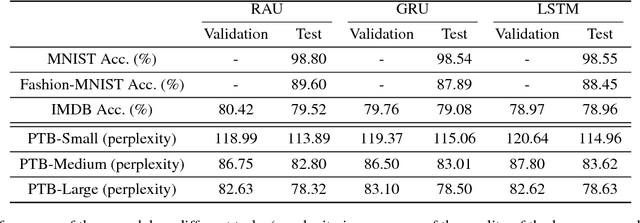
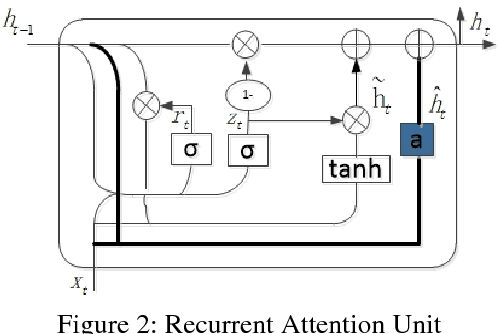
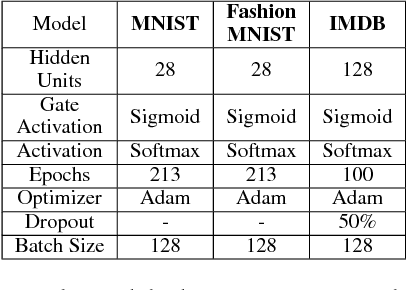
Recurrent Neural Network (RNN) has been successfully applied in many sequence learning problems. Such as handwriting recognition, image description, natural language processing and video motion analysis. After years of development, researchers have improved the internal structure of the RNN and introduced many variants. Among others, Gated Recurrent Unit (GRU) is one of the most widely used RNN model. However, GRU lacks the capability of adaptively paying attention to certain regions or locations, so that it may cause information redundancy or loss during leaning. In this paper, we propose a RNN model, called Recurrent Attention Unit (RAU), which seamlessly integrates the attention mechanism into the interior of GRU by adding an attention gate. The attention gate can enhance GRU's ability to remember long-term memory and help memory cells quickly discard unimportant content. RAU is capable of extracting information from the sequential data by adaptively selecting a sequence of regions or locations and pay more attention to the selected regions during learning. Extensive experiments on image classification, sentiment classification and language modeling show that RAU consistently outperforms GRU and other baseline methods.
Long Short-Term Attention
Oct 30, 2018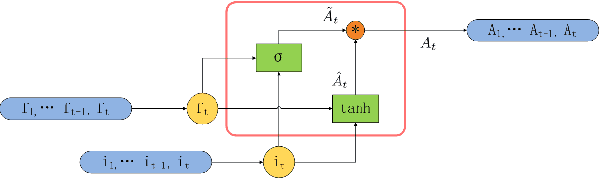
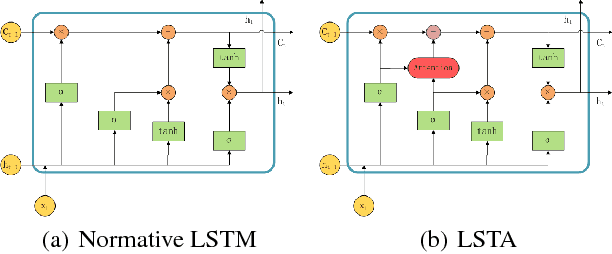
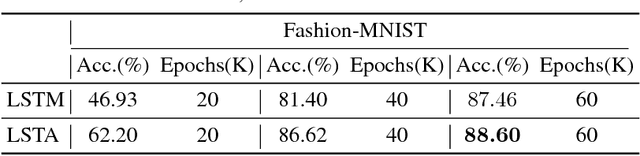
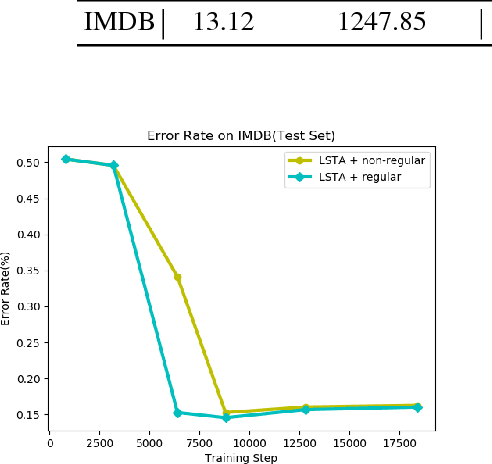
In order to learn effective features from temporal sequences, the long short-term memory (LSTM) network is widely applied. A critical component of LSTM is the memory cell, which is able to extract, process and store temporal information. Nevertheless, in LSTM, the memory cell is not directly enforced to pay attention to a part of the sequence. Alternatively, the attention mechanism can help to pay attention to specific information of data. In this paper, we present a novel neural model, called long short-term attention (LSTA), which seamlessly merges the attention mechanism into LSTM. More than processing long short term sequences, it can distill effective and valuable information from the sequences with the attention mechanism. Experiments show that LSTA achieves promising learning performance in various deep learning tasks.
Structure Learning of Deep Networks via DNA Computing Algorithm
Oct 25, 2018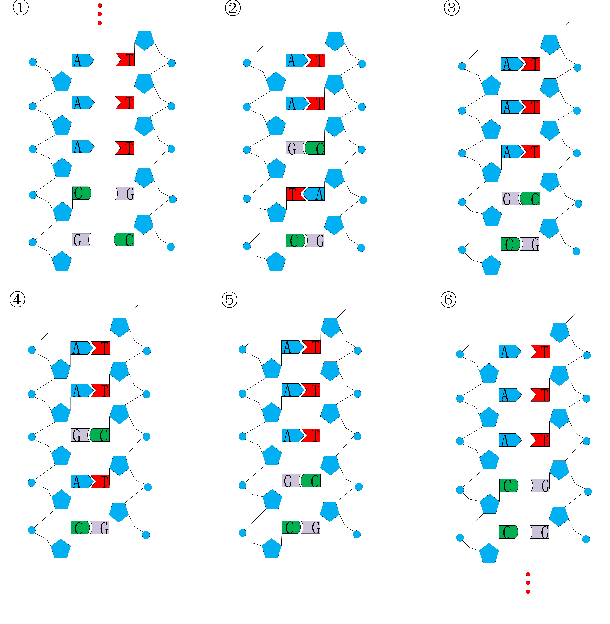
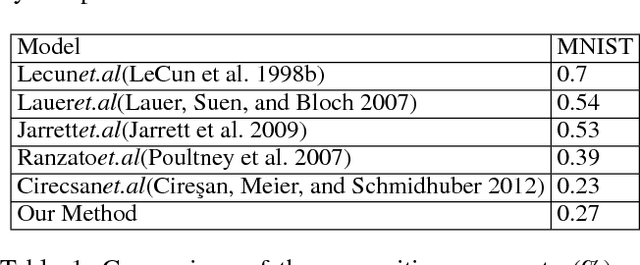
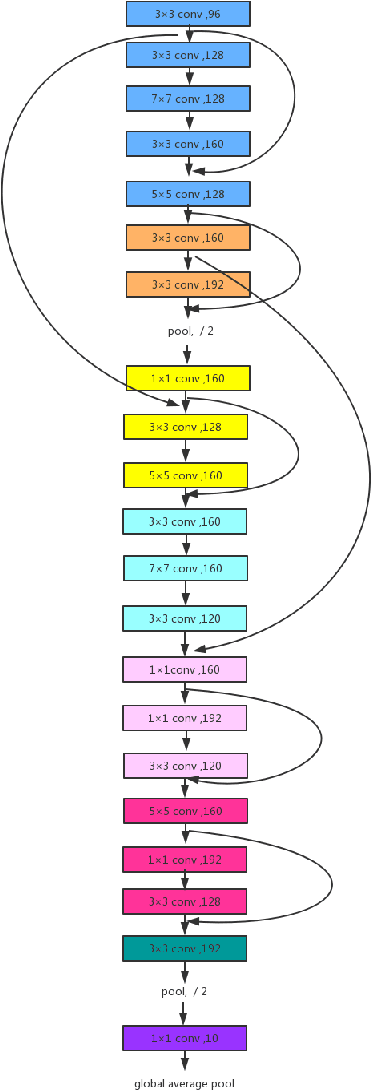
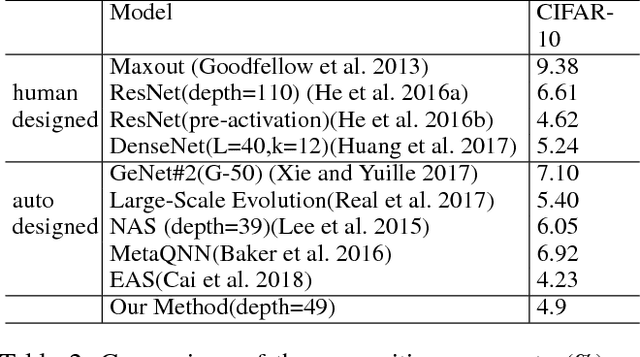
Convolutional Neural Network (CNN) has gained state-of-the-art results in many pattern recognition and computer vision tasks. However, most of the CNN structures are manually designed by experienced researchers. Therefore, auto- matically building high performance networks becomes an important problem. In this paper, we introduce the idea of using DNA computing algorithm to automatically learn high-performance architectures. In DNA computing algorithm, we use short DNA strands to represent layers and long DNA strands to represent overall networks. We found that most of the learned models perform similarly, and only those performing worse during the first runs of training will perform worse finally than others. The indicates that: 1) Using DNA computing algorithm to learn deep architectures is feasible; 2) Local minima should not be a problem of deep networks; 3) We can use early stop to kill the models with the bad performance just after several runs of training. In our experiments, an accuracy 99.73% was obtained on the MNIST data set and an accuracy 95.10% was obtained on the CIFAR-10 data set.
Generative Adversarial Networks with Decoder-Encoder Output Noise
Jul 11, 2018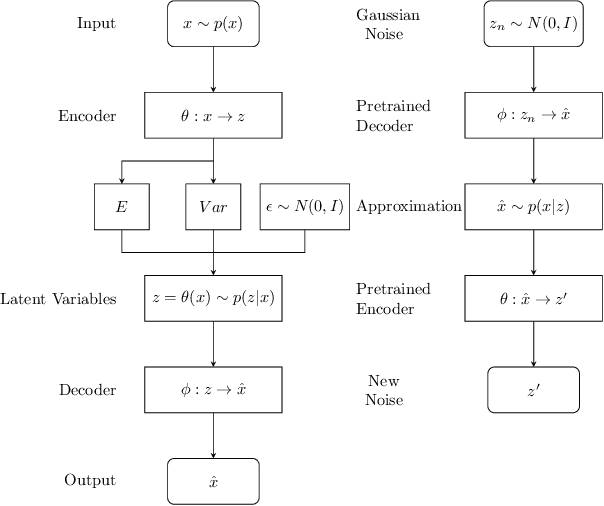

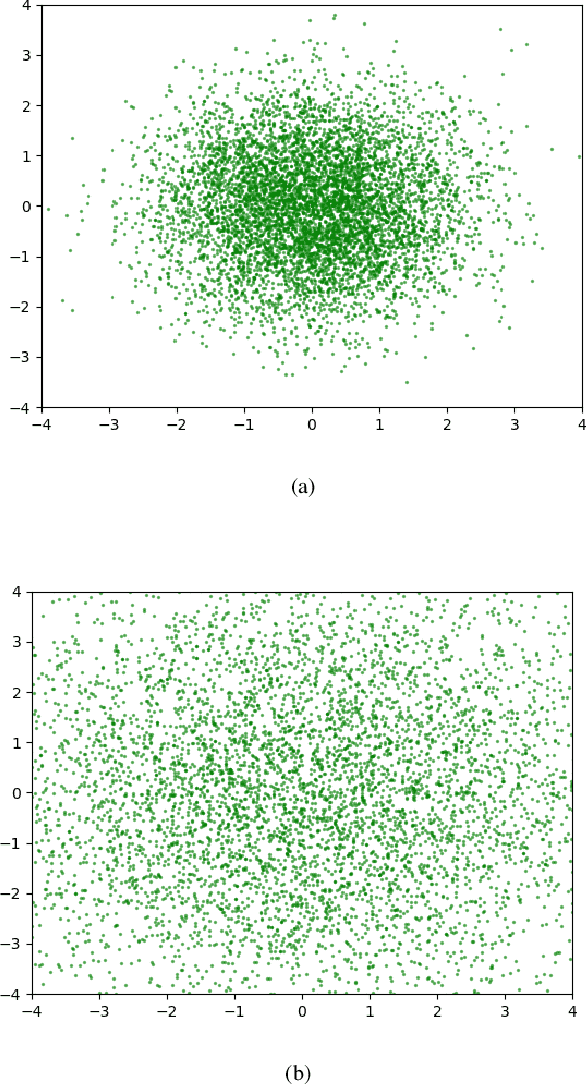
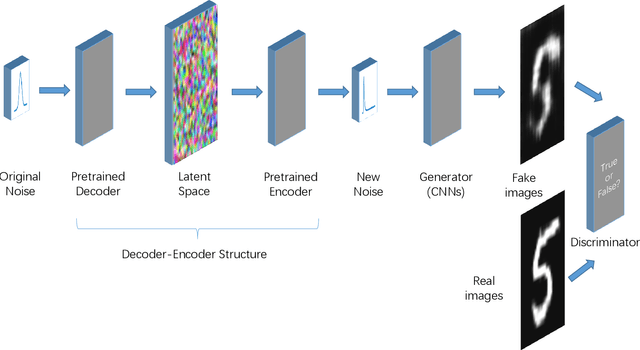
In recent years, research on image generation methods has been developing fast. The auto-encoding variational Bayes method (VAEs) was proposed in 2013, which uses variational inference to learn a latent space from the image database and then generates images using the decoder. The generative adversarial networks (GANs) came out as a promising framework, which uses adversarial training to improve the generative ability of the generator. However, the generated pictures by GANs are generally blurry. The deep convolutional generative adversarial networks (DCGANs) were then proposed to leverage the quality of generated images. Since the input noise vectors are randomly sampled from a Gaussian distribution, the generator has to map from a whole normal distribution to the images. This makes DCGANs unable to reflect the inherent structure of the training data. In this paper, we propose a novel deep model, called generative adversarial networks with decoder-encoder output noise (DE-GANs), which takes advantage of both the adversarial training and the variational Bayesain inference to improve the performance of image generation. DE-GANs use a pre-trained decoder-encoder architecture to map the random Gaussian noise vectors to informative ones and pass them to the generator of the adversarial networks. Since the decoder-encoder architecture is trained by the same images as the generators, the output vectors could carry the intrinsic distribution information of the original images. Moreover, the loss function of DE-GANs is different from GANs and DCGANs. A hidden-space loss function is added to the adversarial loss function to enhance the robustness of the model. Extensive empirical results show that DE-GANs can accelerate the convergence of the adversarial training process and improve the quality of the generated images.
Prediction of Sea Surface Temperature using Long Short-Term Memory
May 19, 2017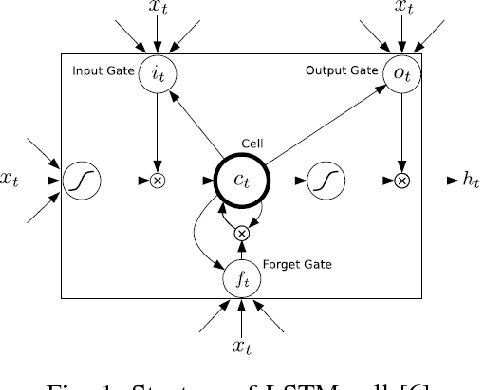
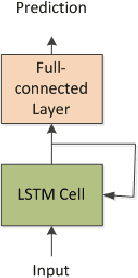
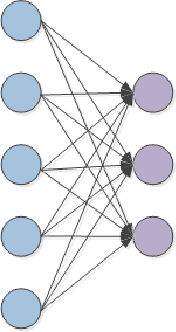
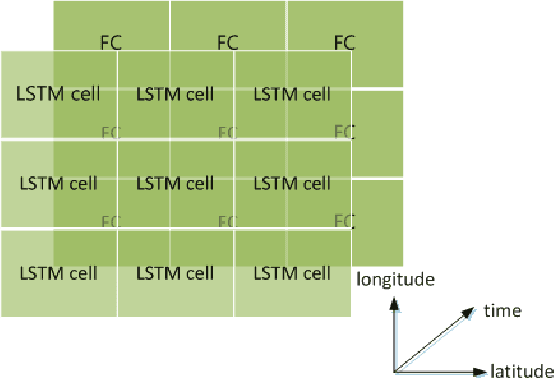
This letter adopts long short-term memory(LSTM) to predict sea surface temperature(SST), which is the first attempt, to our knowledge, to use recurrent neural network to solve the problem of SST prediction, and to make one week and one month daily prediction. We formulate the SST prediction problem as a time series regression problem. LSTM is a special kind of recurrent neural network, which introduces gate mechanism into vanilla RNN to prevent the vanished or exploding gradient problem. It has strong ability to model the temporal relationship of time series data and can handle the long-term dependency problem well. The proposed network architecture is composed of two kinds of layers: LSTM layer and full-connected dense layer. LSTM layer is utilized to model the time series relationship. Full-connected layer is utilized to map the output of LSTM layer to a final prediction. We explore the optimal setting of this architecture by experiments and report the accuracy of coastal seas of China to confirm the effectiveness of the proposed method. In addition, we also show its online updated characteristics.
Perception Driven Texture Generation
Mar 24, 2017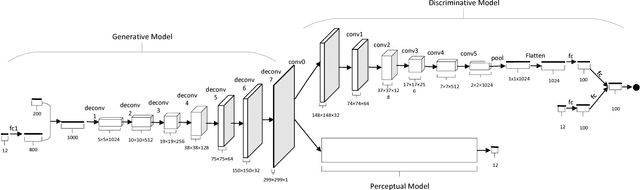
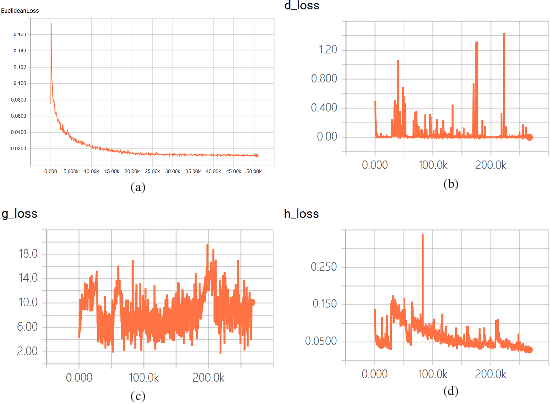


This paper investigates a novel task of generating texture images from perceptual descriptions. Previous work on texture generation focused on either synthesis from examples or generation from procedural models. Generating textures from perceptual attributes have not been well studied yet. Meanwhile, perceptual attributes, such as directionality, regularity and roughness are important factors for human observers to describe a texture. In this paper, we propose a joint deep network model that combines adversarial training and perceptual feature regression for texture generation, while only random noise and user-defined perceptual attributes are required as input. In this model, a preliminary trained convolutional neural network is essentially integrated with the adversarial framework, which can drive the generated textures to possess given perceptual attributes. An important aspect of the proposed model is that, if we change one of the input perceptual features, the corresponding appearance of the generated textures will also be changed. We design several experiments to validate the effectiveness of the proposed method. The results show that the proposed method can produce high quality texture images with desired perceptual properties.
An Overview on Data Representation Learning: From Traditional Feature Learning to Recent Deep Learning
Nov 25, 2016Since about 100 years ago, to learn the intrinsic structure of data, many representation learning approaches have been proposed, including both linear ones and nonlinear ones, supervised ones and unsupervised ones. Particularly, deep architectures are widely applied for representation learning in recent years, and have delivered top results in many tasks, such as image classification, object detection and speech recognition. In this paper, we review the development of data representation learning methods. Specifically, we investigate both traditional feature learning algorithms and state-of-the-art deep learning models. The history of data representation learning is introduced, while available resources (e.g. online course, tutorial and book information) and toolboxes are provided. Finally, we conclude this paper with remarks and some interesting research directions on data representation learning.
Banzhaf Random Forests
Jul 22, 2015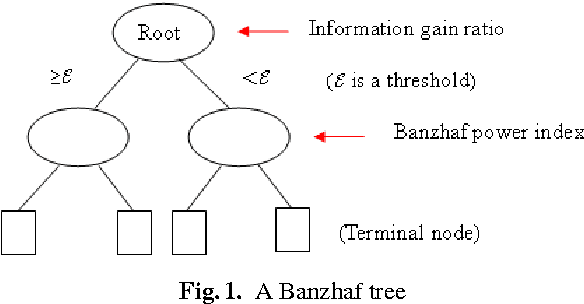
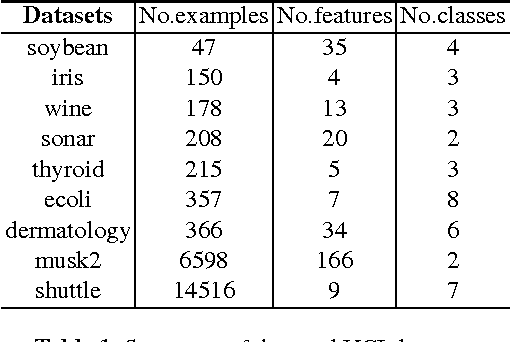
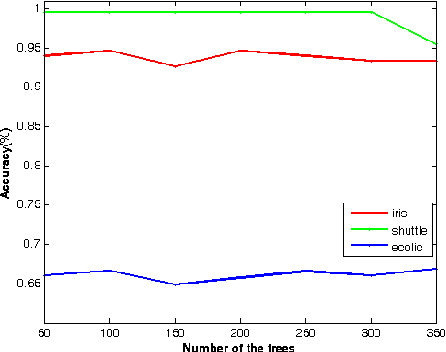
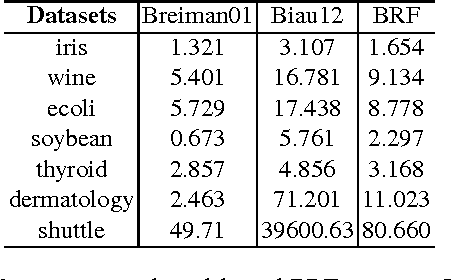
Random forests are a type of ensemble method which makes predictions by combining the results of several independent trees. However, the theory of random forests has long been outpaced by their application. In this paper, we propose a novel random forests algorithm based on cooperative game theory. Banzhaf power index is employed to evaluate the power of each feature by traversing possible feature coalitions. Unlike the previously used information gain rate of information theory, which simply chooses the most informative feature, the Banzhaf power index can be considered as a metric of the importance of each feature on the dependency among a group of features. More importantly, we have proved the consistency of the proposed algorithm, named Banzhaf random forests (BRF). This theoretical analysis takes a step towards narrowing the gap between the theory and practice of random forests for classification problems. Experiments on several UCI benchmark data sets show that BRF is competitive with state-of-the-art classifiers and dramatically outperforms previous consistent random forests. Particularly, it is much more efficient than previous consistent random forests.
A Deep Hashing Learning Network
Jul 16, 2015
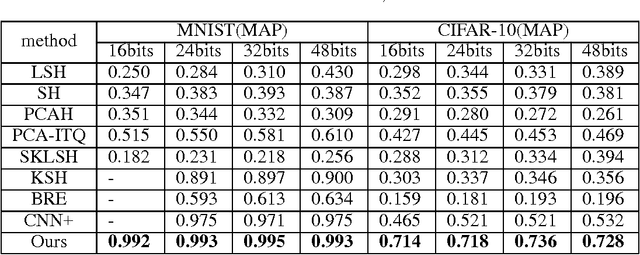
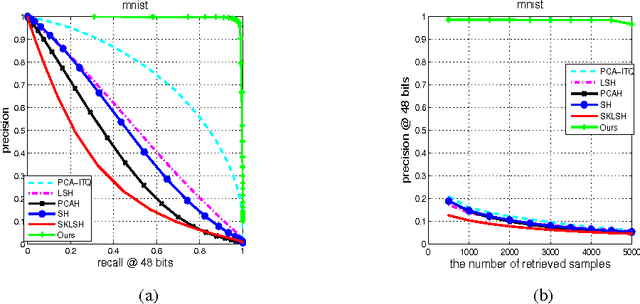
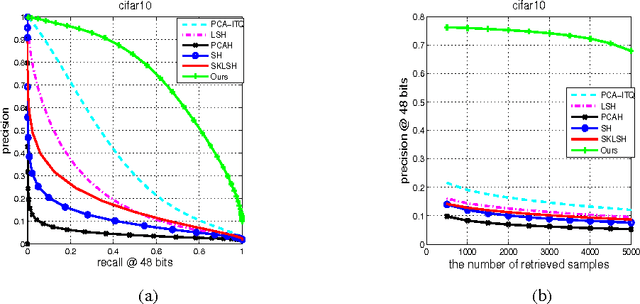
Hashing-based methods seek compact and efficient binary codes that preserve the neighborhood structure in the original data space. For most existing hashing methods, an image is first encoded as a vector of hand-crafted visual feature, followed by a hash projection and quantization step to get the compact binary vector. Most of the hand-crafted features just encode the low-level information of the input, the feature may not preserve the semantic similarities of images pairs. Meanwhile, the hashing function learning process is independent with the feature representation, so the feature may not be optimal for the hashing projection. In this paper, we propose a supervised hashing method based on a well designed deep convolutional neural network, which tries to learn hashing code and compact representations of data simultaneously. The proposed model learn the binary codes by adding a compact sigmoid layer before the loss layer. Experiments on several image data sets show that the proposed model outperforms other state-of-the-art methods.
A PCA-Based Convolutional Network
May 14, 2015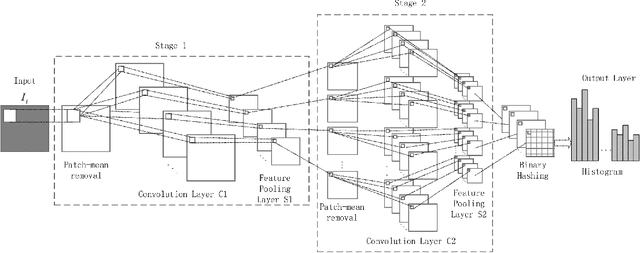
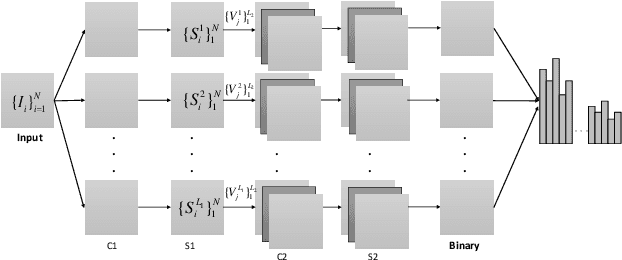
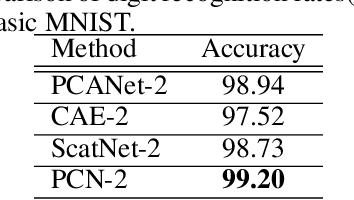
In this paper, we propose a novel unsupervised deep learning model, called PCA-based Convolutional Network (PCN). The architecture of PCN is composed of several feature extraction stages and a nonlinear output stage. Particularly, each feature extraction stage includes two layers: a convolutional layer and a feature pooling layer. In the convolutional layer, the filter banks are simply learned by PCA. In the nonlinear output stage, binary hashing is applied. For the higher convolutional layers, the filter banks are learned from the feature maps that were obtained in the previous stage. To test PCN, we conducted extensive experiments on some challenging tasks, including handwritten digits recognition, face recognition and texture classification. The results show that PCN performs competitive with or even better than state-of-the-art deep learning models. More importantly, since there is no back propagation for supervised finetuning, PCN is much more efficient than existing deep networks.