 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Graph Structure Necessary for Multi-hop Reasoning?
Apr 07, 2020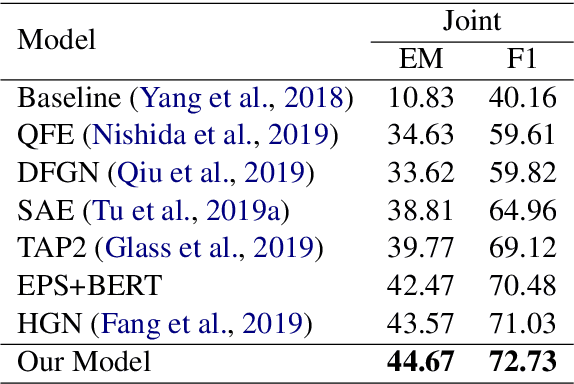
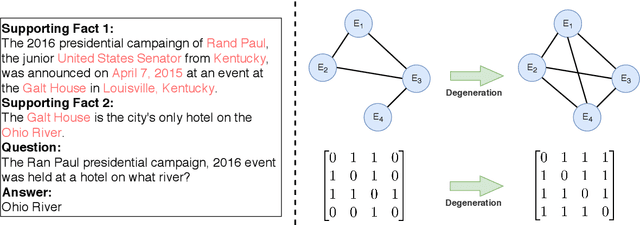
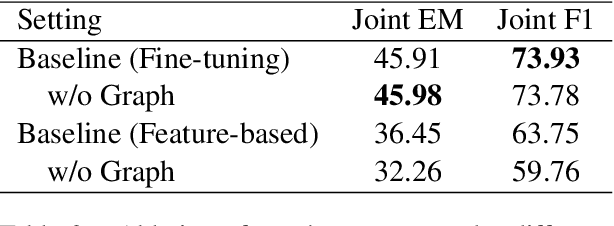
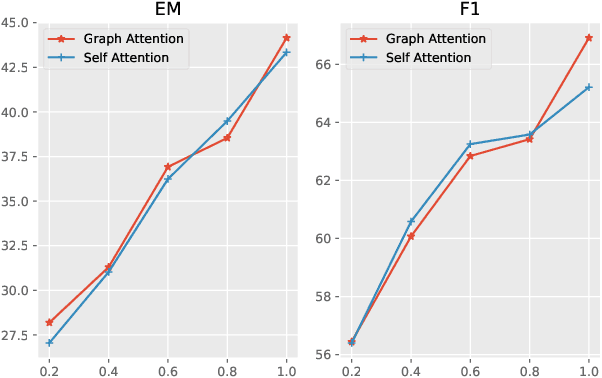
Recently, many works attempt to model texts as graph structure and introduce graph neural networks to deal with it on many NLP tasks.In this paper, we investigate whether graph structure is necessary for multi-hop reasoning tasks and what role it plays. Our analysis is centered on HotpotQA. We use the state-of-the-art published model, Dynamically Fused Graph Network (DFGN), as our baseline. By directly modifying the pre-trained model, our baseline model gains a large improvement and significantly surpass both published and unpublished works. Ablation experiments established that, with the proper use of pre-trained models, graph structure may not be necessary for multi-hop reasoning. We point out that both the graph structure and the adjacency matrix are task-related prior knowledge, and graph-attention can be considered as a special case of self-attention. Experiments demonstrate that graph-attention or the entire graph structure can be replaced by self-attention or Transformers, and achieve similar results to the previous state-of-the-art model achieved.
TextBrewer: An Open-Source Knowledge Distillation Toolkit for Natural Language Processing
Feb 28, 2020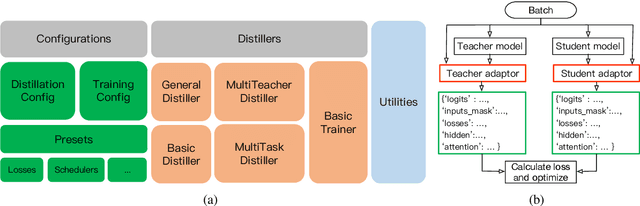

In this paper, we introduce TextBrewer, an open-source knowledge distillation toolkit designed for natural language processing. It works with different neural network models and supports various kinds of tasks, such as text classification, reading comprehension, sequence labeling. TextBrewer provides a simple and uniform workflow that enables quick setup of distillation experiments with highly flexible configurations. It offers a set of predefined distillation methods and can be extended with custom code. As a case study, we use TextBrewer to distill BERT on several typical NLP tasks. With simple configuration, we achieve results that are comparable with or even higher than the state-of-the-art performance. Our toolkit is available through: http://textbrewer.hfl-rc.com
Discriminative Sentence Modeling for Story Ending Prediction
Dec 19, 2019
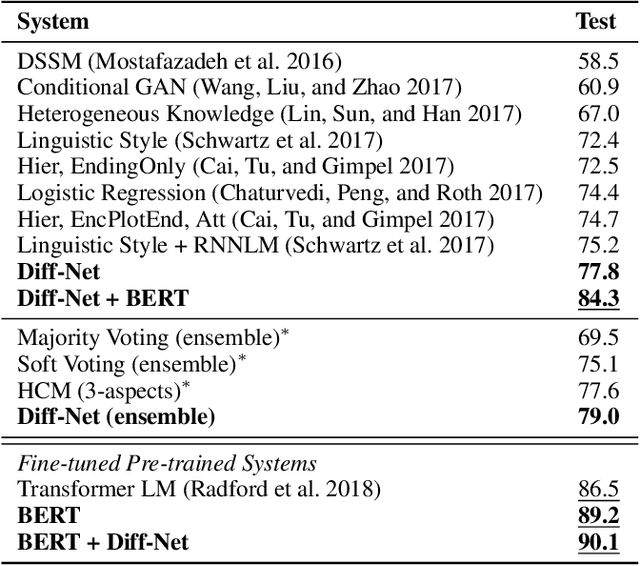
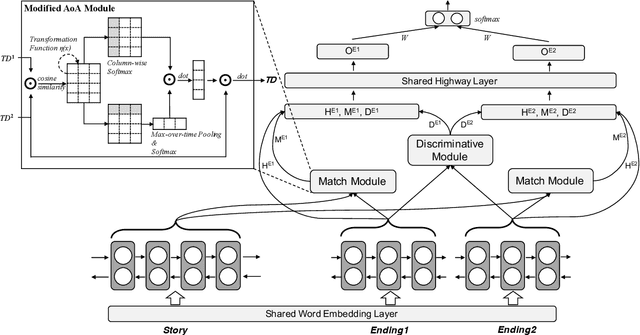
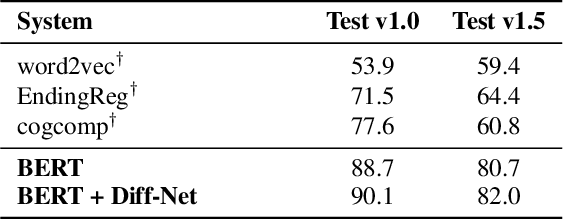
Story Ending Prediction is a task that needs to select an appropriate ending for the given story, which requires the machine to understand the story and sometimes needs commonsense knowledge. To tackle this task, we propose a new neural network called Diff-Net for better modeling the differences of each ending in this task. The proposed model could discriminate two endings in three semantic levels: contextual representation, story-aware representation, and discriminative representation. Experimental results on the Story Cloze Test dataset show that the proposed model siginificantly outperforms various systems by a large margin, and detailed ablation studies are given for better understanding our model. We also carefully examine the traditional and BERT-based models on both SCT v1.0 and v1.5 with interesting findings that may potentially help future studies.
Contextual Recurrent Units for Cloze-style Reading Comprehension
Nov 14, 2019

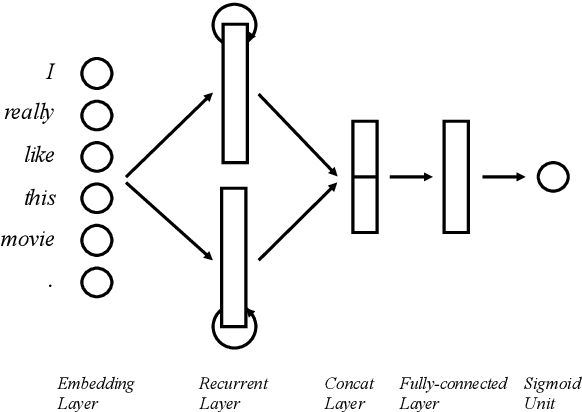
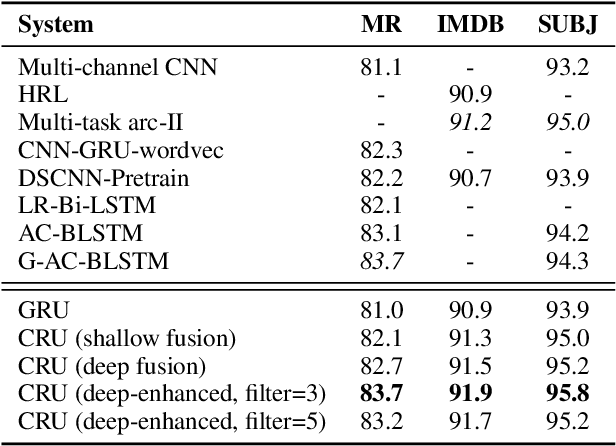
Recurrent Neural Networks (RNN) are known as powerful models for handling sequential data, and especially widely utilized in various natural language processing tasks. In this paper, we propose Contextual Recurrent Units (CRU) for enhancing local contextual representations in neural networks. The proposed CRU injects convolutional neural networks (CNN) into the recurrent units to enhance the ability to model the local context and reducing word ambiguities even in bi-directional RNNs. We tested our CRU model on sentence-level and document-level modeling NLP tasks: sentiment classification and reading comprehension. Experimental results show that the proposed CRU model could give significant improvements over traditional CNN or RNN models, including bidirectional conditions, as well as various state-of-the-art systems on both tasks, showing its promising future of extensibility to other NLP tasks as well.
Improving Machine Reading Comprehension via Adversarial Training
Nov 09, 2019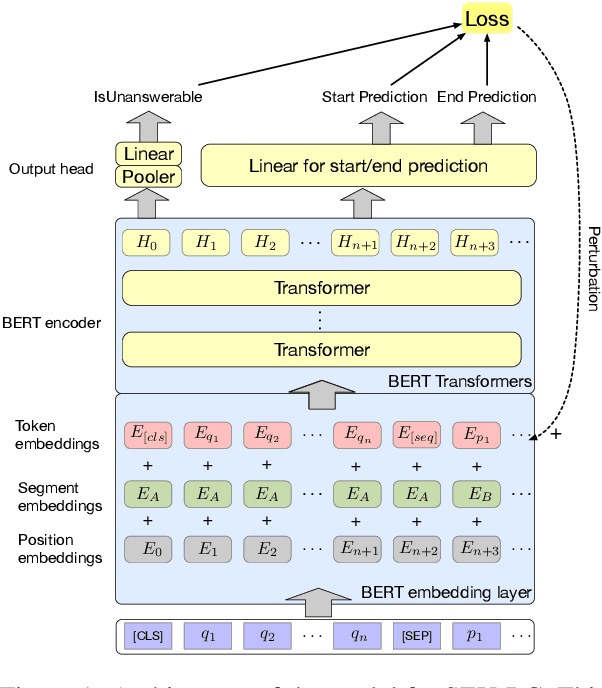
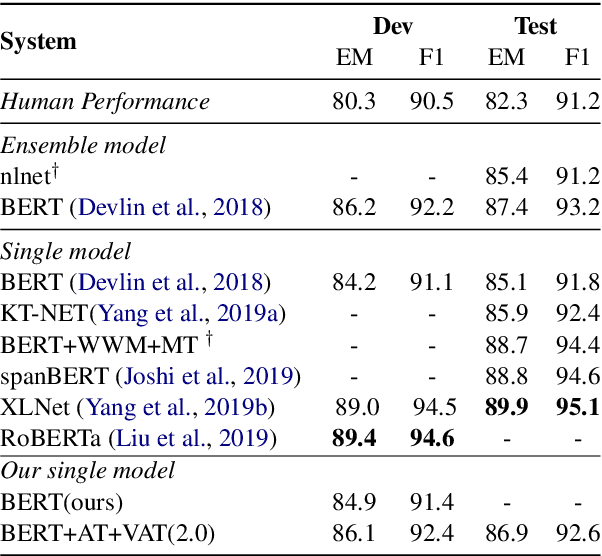
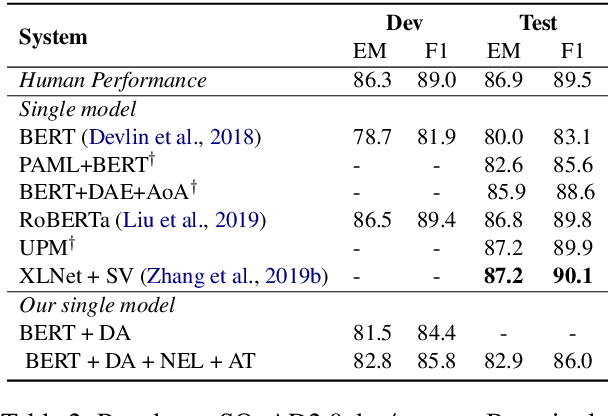
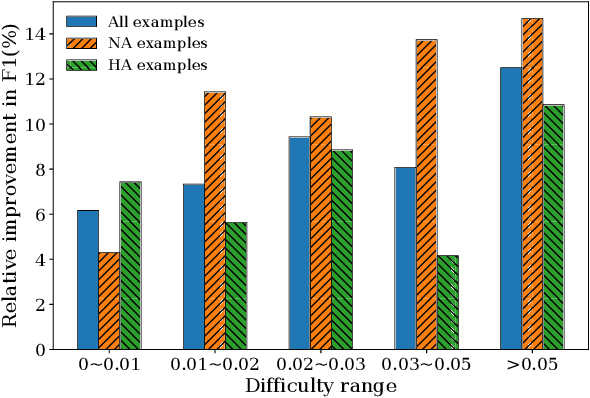
Adversarial training (AT) as a regularization method has proved its effectiveness in various tasks, such as image classification and text classification. Though there are successful applications of AT in many tasks of natural language processing (NLP), the mechanism behind it is still unclear. In this paper, we aim to apply AT on machine reading comprehension (MRC) and study its effects from multiple perspectives. We experiment with three different kinds of RC tasks: span-based RC, span-based RC with unanswerable questions and multi-choice RC. The experimental results show that the proposed method can improve the performance significantly and universally on SQuAD1.1, SQuAD2.0 and RACE. With virtual adversarial training (VAT), we explore the possibility of improving the RC models with semi-supervised learning and prove that examples from a different task are also beneficial. We also find that AT helps little in defending against artificial adversarial examples, but AT helps the model to learn better on examples that contain more low-frequency words.
TripleNet: Triple Attention Network for Multi-Turn Response Selection in Retrieval-based Chatbots
Sep 29, 2019
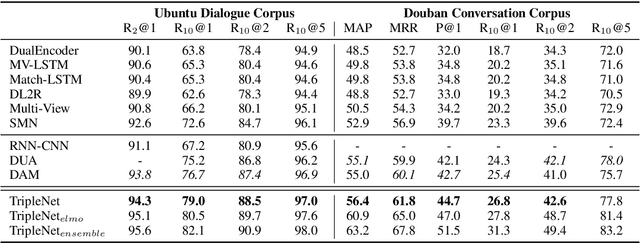
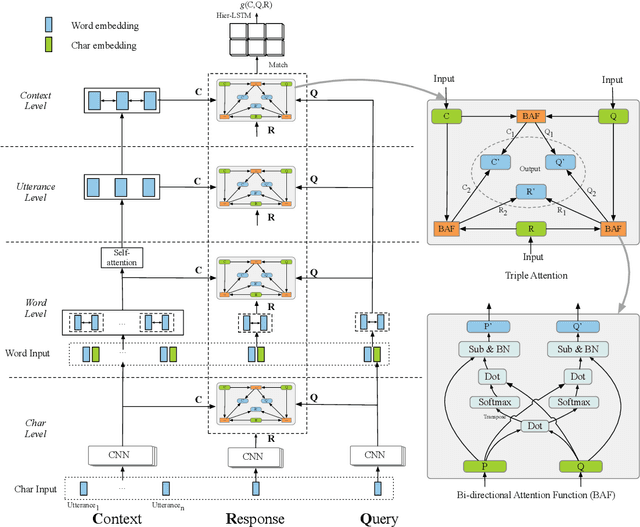

We consider the importance of different utterances in the context for selecting the response usually depends on the current query. In this paper, we propose the model TripleNet to fully model the task with the triple <context, query, response> instead of <context, response> in previous works. The heart of TripleNet is a novel attention mechanism named triple attention to model the relationships within the triple at four levels. The new mechanism updates the representation for each element based on the attention with the other two concurrently and symmetrically. We match the triple <C, Q, R> centered on the response from char to context level for prediction. Experimental results on two large-scale multi-turn response selection datasets show that the proposed model can significantly outperform the state-of-the-art methods. TripleNet source code is available at https://github.com/wtma/TripleNet
Learning Dynamic Context Augmentation for Global Entity Linking
Sep 04, 2019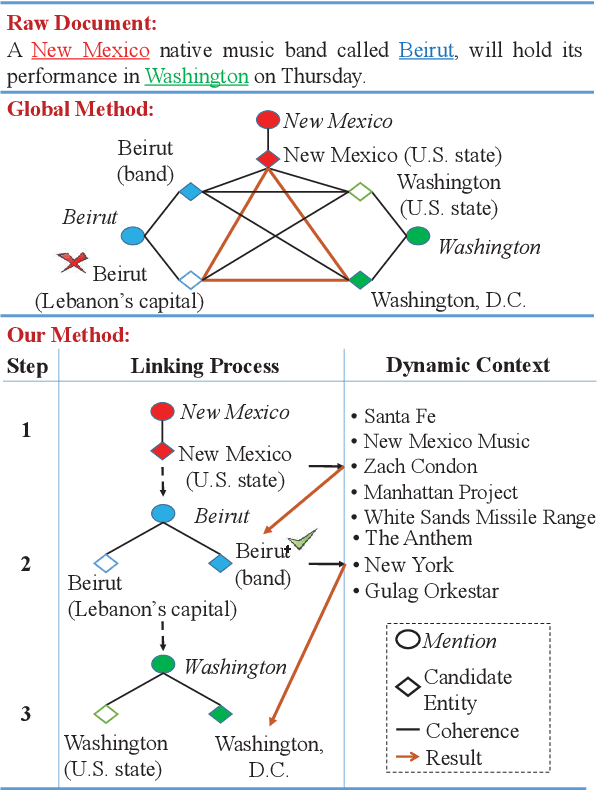
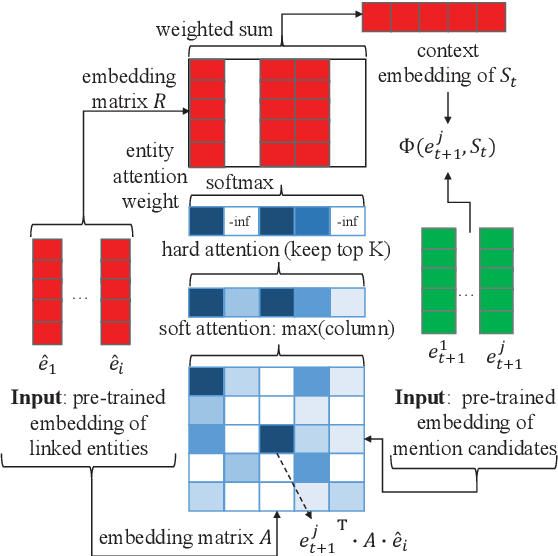
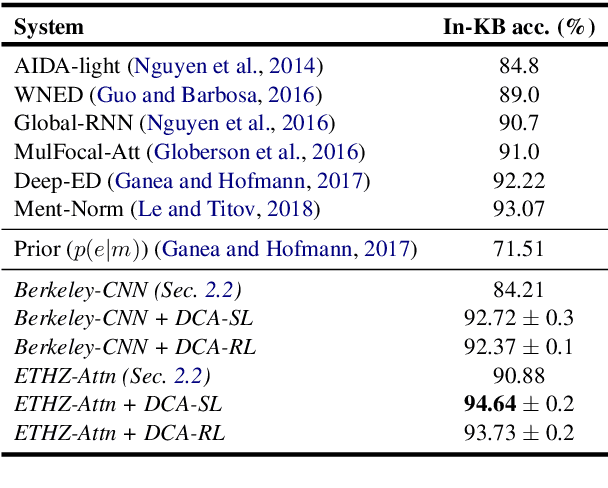
Despite of the recent success of collective entity linking (EL) methods, these "global" inference methods may yield sub-optimal results when the "all-mention coherence" assumption breaks, and often suffer from high computational cost at the inference stage, due to the complex search space. In this paper, we propose a simple yet effective solution, called Dynamic Context Augmentation (DCA), for collective EL, which requires only one pass through the mentions in a document. DCA sequentially accumulates context information to make efficient, collective inference, and can cope with different local EL models as a plug-and-enhance module. We explore both supervised and reinforcement learning strategies for learning the DCA model. Extensive experiments show the effectiveness of our model with different learning settings, base models, decision orders and attention mechanisms.
Cross-Lingual Machine Reading Comprehension
Sep 01, 2019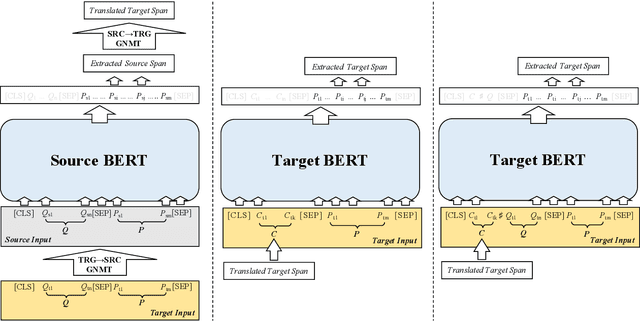
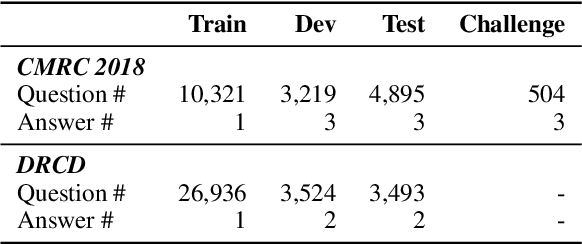
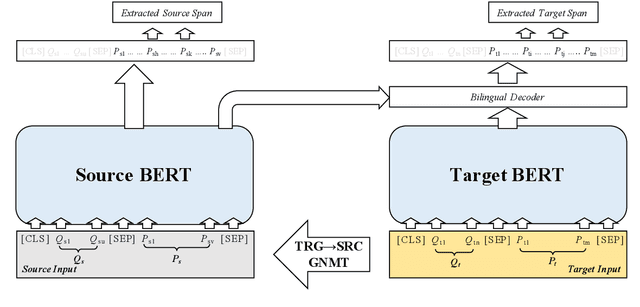
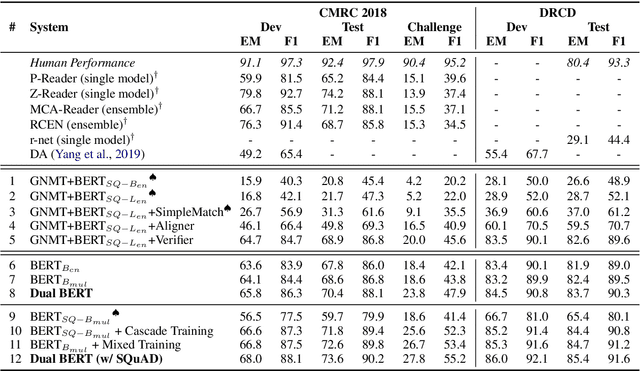
Though the community has made great progress on Machine Reading Comprehension (MRC) task, most of the previous works are solving English-based MRC problems, and there are few efforts on other languages mainly due to the lack of large-scale training data. In this paper, we propose Cross-Lingual Machine Reading Comprehension (CLMRC) task for the languages other than English. Firstly, we present several back-translation approaches for CLMRC task, which is straightforward to adopt. However, to accurately align the answer into another language is difficult and could introduce additional noise. In this context, we propose a novel model called Dual BERT, which takes advantage of the large-scale training data provided by rich-resource language (such as English) and learn the semantic relations between the passage and question in a bilingual context, and then utilize the learned knowledge to improve reading comprehension performance of low-resource language. We conduct experiments on two Chinese machine reading comprehension datasets CMRC 2018 and DRCD. The results show consistent and significant improvements over various state-of-the-art systems by a large margin, which demonstrate the potentials in CLMRC task. Resources available: https://github.com/ymcui/Cross-Lingual-MRC
Pre-Training with Whole Word Masking for Chinese BERT
Jun 19, 2019
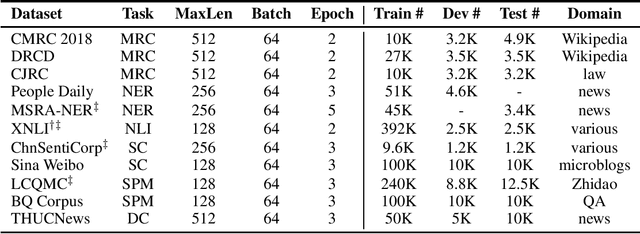


Bidirectional Encoder Representations from Transformers (BERT) has shown marvelous improvements across various NLP tasks. Recently, an upgraded version of BERT has been released with Whole Word Masking (WWM), which mitigate the drawbacks of masking partial WordPiece tokens in pre-training BERT. In this technical report, we adapt whole word masking in Chinese text, that masking the whole word instead of masking Chinese characters, which could bring another challenge in Masked Language Model (MLM) pre-training task. The model was trained on the latest Chinese Wikipedia dump. We aim to provide easy extensibility and better performance for Chinese BERT without changing any neural architecture or even hyper-parameters. The model is verified on various NLP tasks, across sentence-level to document-level, including sentiment classification (ChnSentiCorp, Sina Weibo), named entity recognition (People Daily, MSRA-NER), natural language inference (XNLI), sentence pair matching (LCQMC, BQ Corpus), and machine reading comprehension (CMRC 2018, DRCD, CAIL RC). Experimental results on these datasets show that the whole word masking could bring another significant gain. Moreover, we also examine the effectiveness of Chinese pre-trained models: BERT, ERNIE, BERT-wwm. We release the pre-trained model (both TensorFlow and PyTorch) on GitHub: https://github.com/ymcui/Chinese-BERT-wwm
KCAT: A Knowledge-Constraint Typing Annotation Tool
Jun 13, 2019
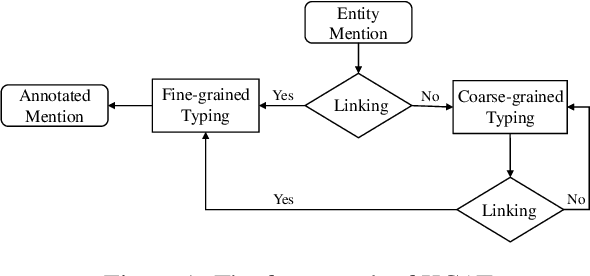
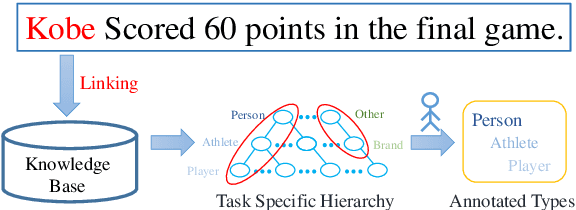
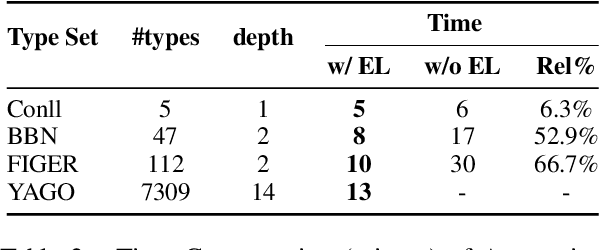
Fine-grained Entity Typing is a tough task which suffers from noise samples extracted from distant supervision. Thousands of manually annotated samples can achieve greater performance than millions of samples generated by the previous distant supervision method. Whereas, it's hard for human beings to differentiate and memorize thousands of types, thus making large-scale human labeling hardly possible. In this paper, we introduce a Knowledge-Constraint Typing Annotation Tool (KCAT), which is efficient for fine-grained entity typing annotation. KCAT reduces the size of candidate types to an acceptable range for human beings through entity linking and provides a Multi-step Typing scheme to revise the entity linking result. Moreover, KCAT provides an efficient Annotator Client to accelerate the annotation process and a comprehensive Manager Module to analyse crowdsourcing annotations. Experiment shows that KCAT can significantly improve annotation efficiency, the time consumption increases slowly as the size of type set expands.