 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning from Pre-Trained Models: A Contrastive Learning Approach
Sep 21, 2022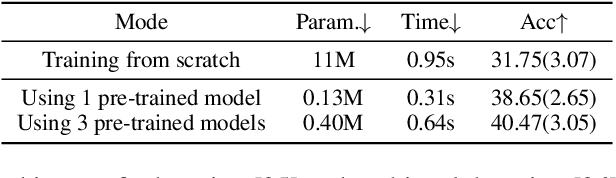
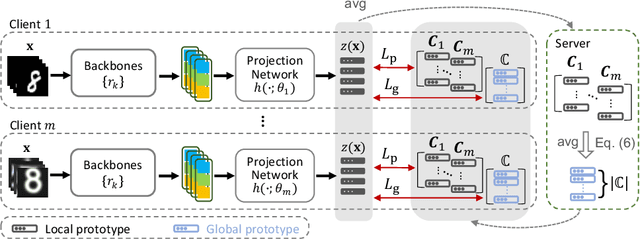
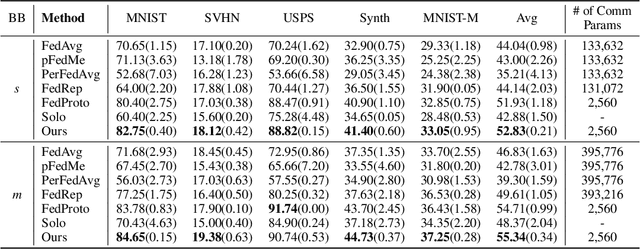
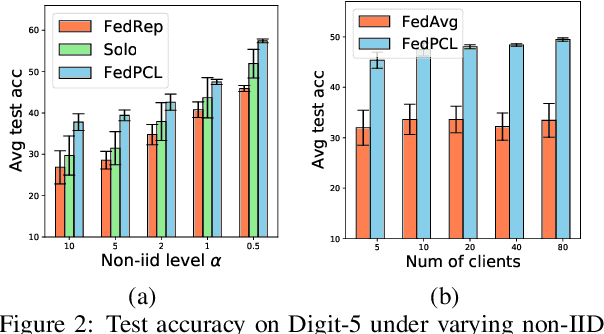
Federated Learning (FL) is a machine learning paradigm that allows decentralized clients to learn collaboratively without sharing their private data. However, excessive computation and communication demands pose challenges to current FL frameworks, especially when training large-scale models. To prevent these issues from hindering the deployment of FL systems, we propose a lightweight framework where clients jointly learn to fuse the representations generated by multiple fixed pre-trained models rather than training a large-scale model from scratch. This leads us to a more practical FL problem by considering how to capture more client-specific and class-relevant information from the pre-trained models and jointly improve each client's ability to exploit those off-the-shelf models. In this work, we design a Federated Prototype-wise Contrastive Learning (FedPCL) approach which shares knowledge across clients through their class prototypes and builds client-specific representations in a prototype-wise contrastive manner. Sharing prototypes rather than learnable model parameters allows each client to fuse the representations in a personalized way while keeping the shared knowledge in a compact form for efficient communication. We perform a thorough evaluation of the proposed FedPCL in the lightweight framework, measuring and visualizing its ability to fuse various pre-trained models on popular FL datasets.
Towards Robust Ranker for Text Retrieval
Jun 16, 2022
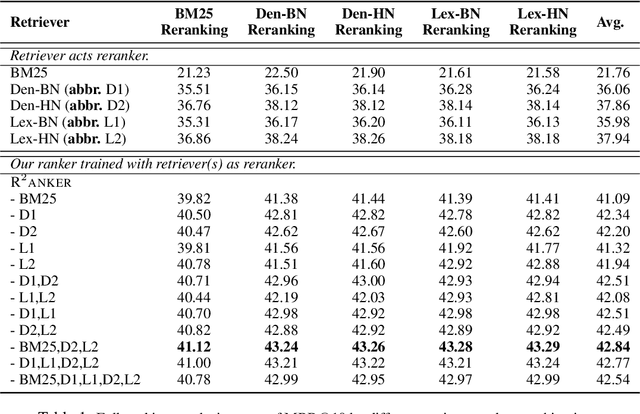
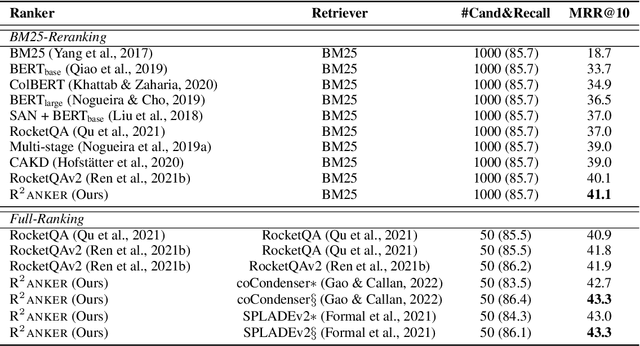
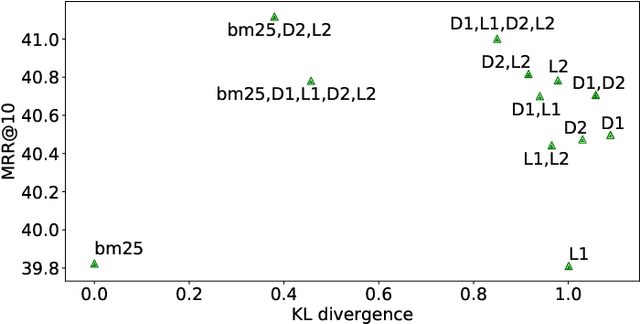
A ranker plays an indispensable role in the de facto 'retrieval & rerank' pipeline, but its training still lags behind -- learning from moderate negatives or/and serving as an auxiliary module for a retriever. In this work, we first identify two major barriers to a robust ranker, i.e., inherent label noises caused by a well-trained retriever and non-ideal negatives sampled for a high-capable ranker. Thereby, we propose multiple retrievers as negative generators improve the ranker's robustness, where i) involving extensive out-of-distribution label noises renders the ranker against each noise distribution, and ii) diverse hard negatives from a joint distribution are relatively close to the ranker's negative distribution, leading to more challenging thus effective training. To evaluate our robust ranker (dubbed R$^2$anker), we conduct experiments in various settings on the popular passage retrieval benchmark, including BM25-reranking, full-ranking, retriever distillation, etc. The empirical results verify the new state-of-the-art effectiveness of our model.
FedNoiL: A Simple Two-Level Sampling Method for Federated Learning with Noisy Labels
May 20, 2022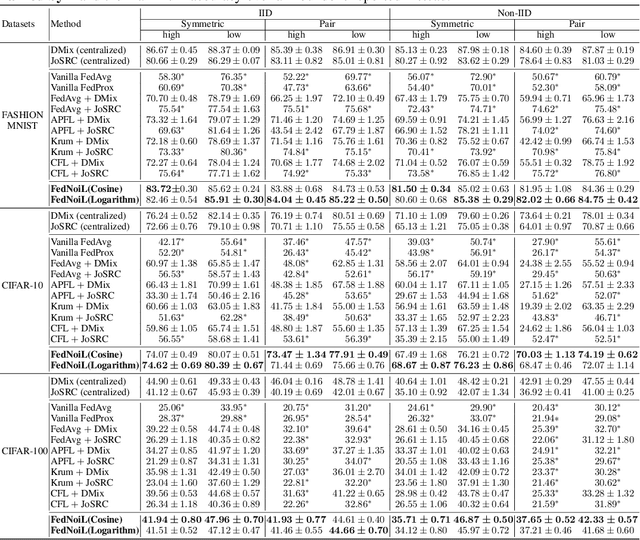
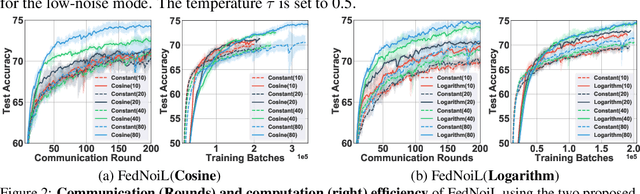
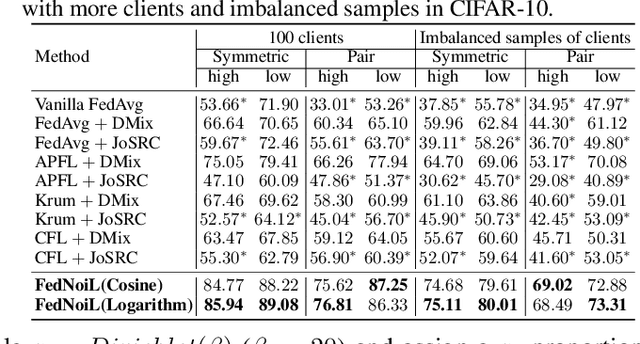
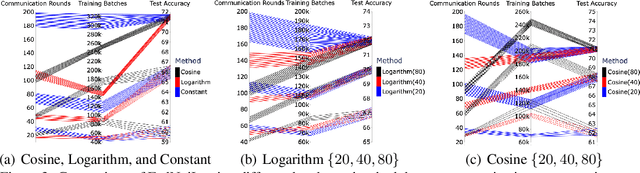
Federated learning (FL) aims at training a global model on the server side while the training data are collected and located at the local devices. Hence, the labels in practice are usually annotated by clients of varying expertise or criteria and thus contain different amounts of noises. Local training on noisy labels can easily result in overfitting to noisy labels, which is devastating to the global model through aggregation. Although recent robust FL methods take malicious clients into account, they have not addressed local noisy labels on each device and the impact to the global model. In this paper, we develop a simple two-level sampling method "FedNoiL" that (1) selects clients for more robust global aggregation on the server; and (2) selects clean labels and correct pseudo-labels at the client end for more robust local training. The sampling probabilities are built upon clean label detection by the global model. Moreover, we investigate different schedules changing the local epochs between aggregations over the course of FL, which notably improves the communication and computation efficiency in noisy label setting. In experiments with homogeneous/heterogeneous data distributions and noise ratios, we observed that direct combinations of SOTA FL methods with SOTA noisy-label learning methods can easily fail but our method consistently achieves better and robust performance.
ClarET: Pre-training a Correlation-Aware Context-To-Event Transformer for Event-Centric Generation and Classification
Mar 09, 2022
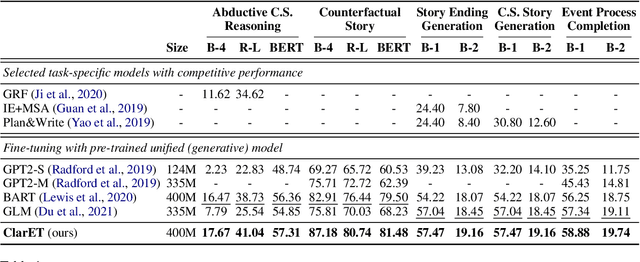
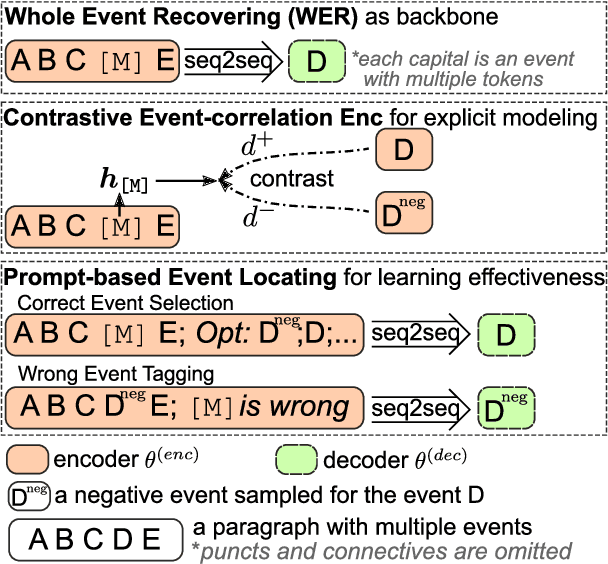
Generating new events given context with correlated ones plays a crucial role in many event-centric reasoning tasks. Existing works either limit their scope to specific scenarios or overlook event-level correlations. In this paper, we propose to pre-train a general Correlation-aware context-to-Event Transformer (ClarET) for event-centric reasoning. To achieve this, we propose three novel event-centric objectives, i.e., whole event recovering, contrastive event-correlation encoding and prompt-based event locating, which highlight event-level correlations with effective training. The proposed ClarET is applicable to a wide range of event-centric reasoning scenarios, considering its versatility of (i) event-correlation types (e.g., causal, temporal, contrast), (ii) application formulations (i.e., generation and classification), and (iii) reasoning types (e.g., abductive, counterfactual and ending reasoning). Empirical fine-tuning results, as well as zero- and few-shot learning, on 9 benchmarks (5 generation and 4 classification tasks covering 4 reasoning types with diverse event correlations), verify its effectiveness and generalization ability.
Personalized Federated Learning With Structure
Mar 08, 2022

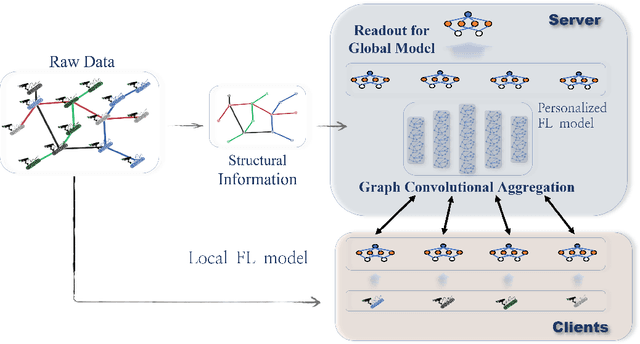
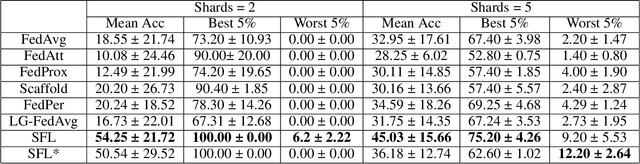
Knowledge sharing and model personalization are two key components to impact the performance of personalized federated learning (PFL). Existing PFL methods simply treat knowledge sharing as an aggregation of all clients regardless of the hidden relations among them. This paper is to enhance the knowledge-sharing process in PFL by leveraging the structural information among clients. We propose a novel structured federated learning(SFL) framework to simultaneously learn the global model and personalized model using each client's local relations with others and its private dataset. This proposed framework has been formulated to a new optimization problem to model the complex relationship among personalized models and structural topology information into a unified framework. Moreover, in contrast to a pre-defined structure, our framework could be further enhanced by adding a structure learning component to automatically learn the structure using the similarities between clients' models' parameters. By conducting extensive experiments, we first demonstrate how federated learning can be benefited by introducing structural information into the server aggregation process with a real-world dataset, and then the effectiveness of the proposed method has been demonstrated in varying degrees of data non-iid settings.
On the Convergence of Clustered Federated Learning
Feb 13, 2022
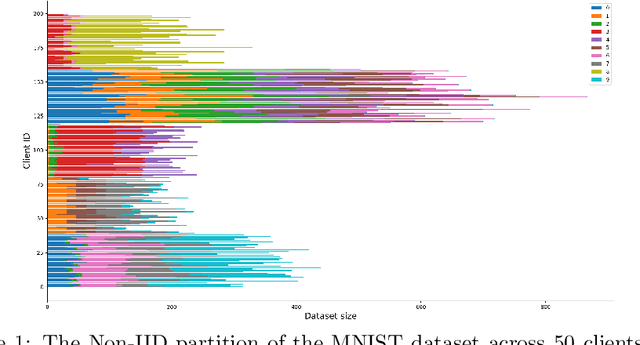
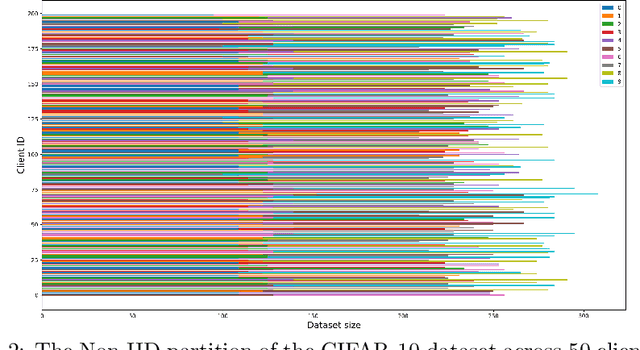
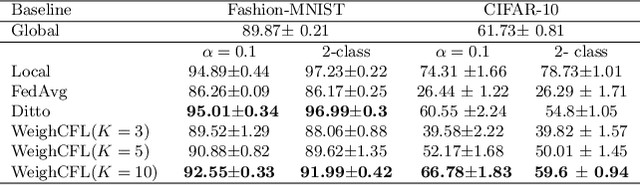
In a federated learning system, the clients, e.g. mobile devices and organization participants, usually have different personal preferences or behavior patterns, namely Non-IID data problems across clients. Clustered federated learning is to group users into different clusters that the clients in the same group will share the same or similar behavior patterns that are to satisfy the IID data assumption for most traditional machine learning algorithms. Most of the existing clustering methods in FL treat every client equally that ignores the different importance contributions among clients. This paper proposes a novel weighted client-based clustered FL algorithm to leverage the client's group and each client in a unified optimization framework. Moreover, the paper proposes convergence analysis to the proposed clustered FL method. The experimental analysis has demonstrated the effectiveness of the proposed method.
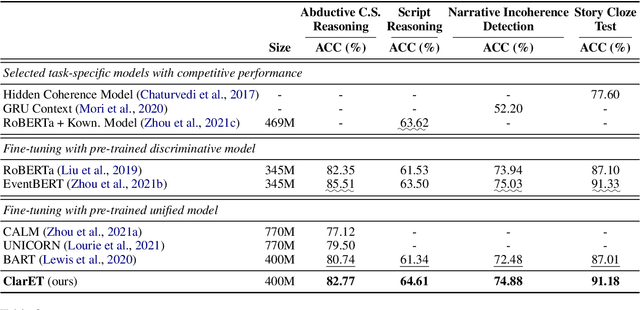
EventBERT: A Pre-Trained Model for Event Correlation Reasoning
Oct 13, 2021
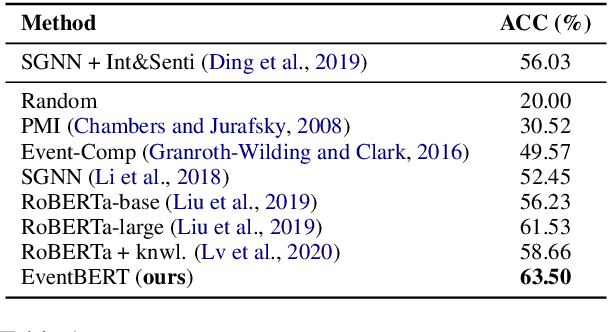
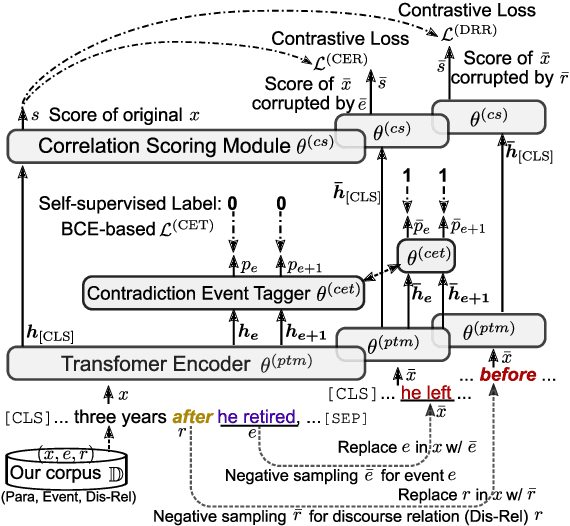
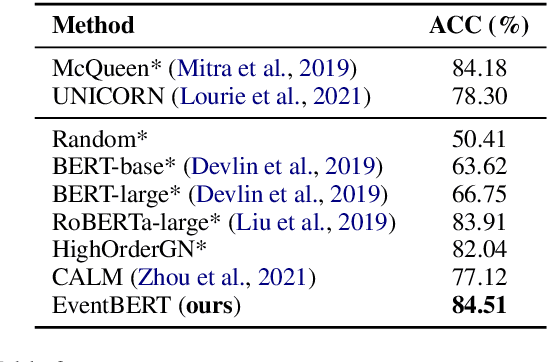
Event correlation reasoning infers whether a natural language paragraph containing multiple events conforms to human common sense. For example, "Andrew was very drowsy, so he took a long nap, and now he is very alert" is sound and reasonable. In contrast, "Andrew was very drowsy, so he stayed up a long time, now he is very alert" does not comply with human common sense. Such reasoning capability is essential for many downstream tasks, such as script reasoning, abductive reasoning, narrative incoherence, story cloze test, etc. However, conducting event correlation reasoning is challenging due to a lack of large amounts of diverse event-based knowledge and difficulty in capturing correlation among multiple events. In this paper, we propose EventBERT, a pre-trained model to encapsulate eventuality knowledge from unlabeled text. Specifically, we collect a large volume of training examples by identifying natural language paragraphs that describe multiple correlated events and further extracting event spans in an unsupervised manner. We then propose three novel event- and correlation-based learning objectives to pre-train an event correlation model on our created training corpus. Empirical results show EventBERT outperforms strong baselines on four downstream tasks, and achieves SoTA results on most of them. Besides, it outperforms existing pre-trained models by a large margin, e.g., 6.5~23%, in zero-shot learning of these tasks.
Hierarchical Relation-Guided Type-Sentence Alignment for Long-Tail Relation Extraction with Distant Supervision
Sep 19, 2021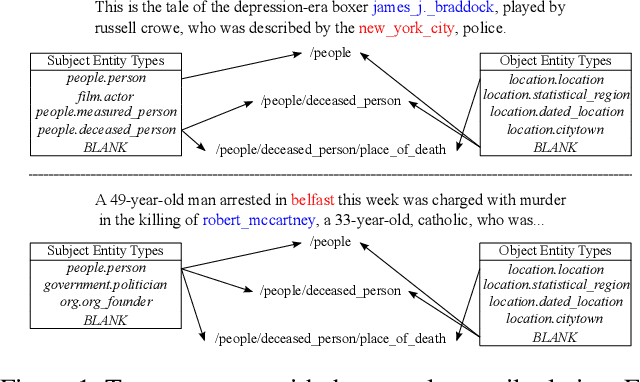
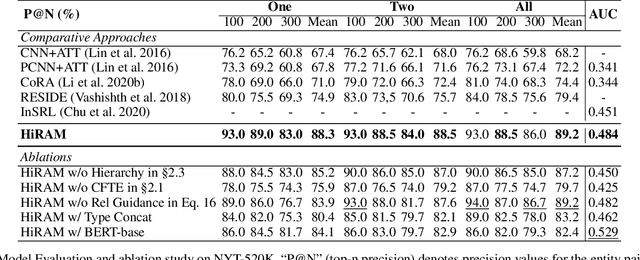
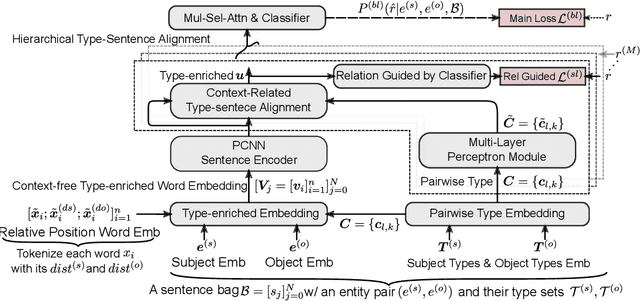
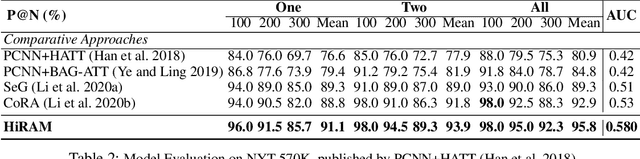
Distant supervision uses triple facts in knowledge graphs to label a corpus for relation extraction, leading to wrong labeling and long-tail problems. Some works use the hierarchy of relations for knowledge transfer to long-tail relations. However, a coarse-grained relation often implies only an attribute (e.g., domain or topic) of the distant fact, making it hard to discriminate relations based solely on sentence semantics. One solution is resorting to entity types, but open questions remain about how to fully leverage the information of entity types and how to align multi-granular entity types with sentences. In this work, we propose a novel model to enrich distantly-supervised sentences with entity types. It consists of (1) a pairwise type-enriched sentence encoding module injecting both context-free and -related backgrounds to alleviate sentence-level wrong labeling, and (2) a hierarchical type-sentence alignment module enriching a sentence with the triple fact's basic attributes to support long-tail relations. Our model achieves new state-of-the-art results in overall and long-tail performance on benchmarks.
Sequential Diagnosis Prediction with Transformer and Ontological Representation
Sep 07, 2021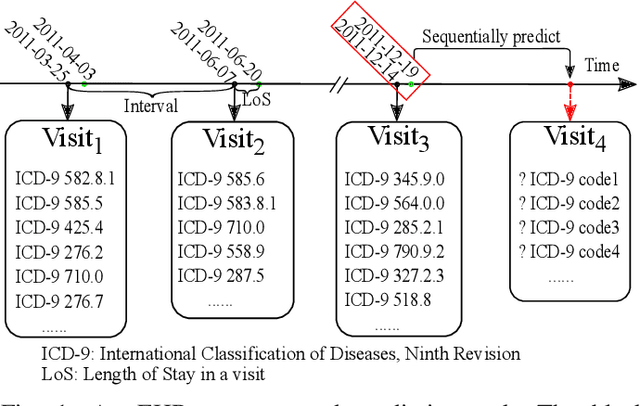
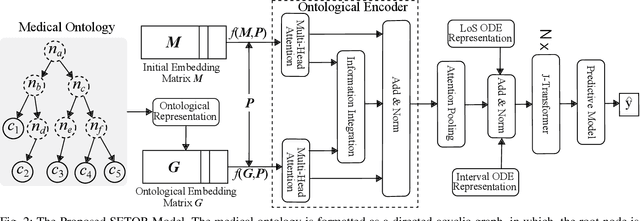
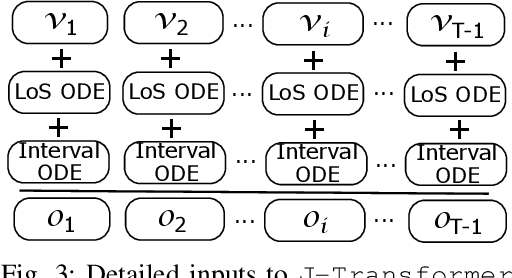
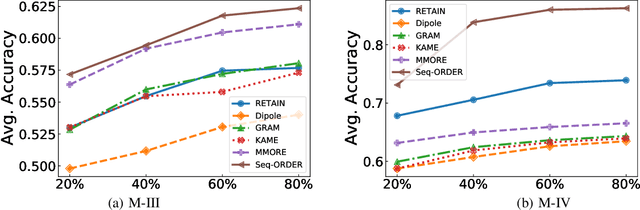
Sequential diagnosis prediction on the Electronic Health Record (EHR) has been proven crucial for predictive analytics in the medical domain. EHR data, sequential records of a patient's interactions with healthcare systems, has numerous inherent characteristics of temporality, irregularity and data insufficiency. Some recent works train healthcare predictive models by making use of sequential information in EHR data, but they are vulnerable to irregular, temporal EHR data with the states of admission/discharge from hospital, and insufficient data. To mitigate this, we propose an end-to-end robust transformer-based model called SETOR, which exploits neural ordinary differential equation to handle both irregular intervals between a patient's visits with admitted timestamps and length of stay in each visit, to alleviate the limitation of insufficient data by integrating medical ontology, and to capture the dependencies between the patient's visits by employing multi-layer transformer blocks. Experiments conducted on two real-world healthcare datasets show that, our sequential diagnoses prediction model SETOR not only achieves better predictive results than previous state-of-the-art approaches, irrespective of sufficient or insufficient training data, but also derives more interpretable embeddings of medical codes. The experimental codes are available at the GitHub repository (https://github.com/Xueping/SETOR).
Eliminating Sentiment Bias for Aspect-Level Sentiment Classification with Unsupervised Opinion Extraction
Sep 07, 2021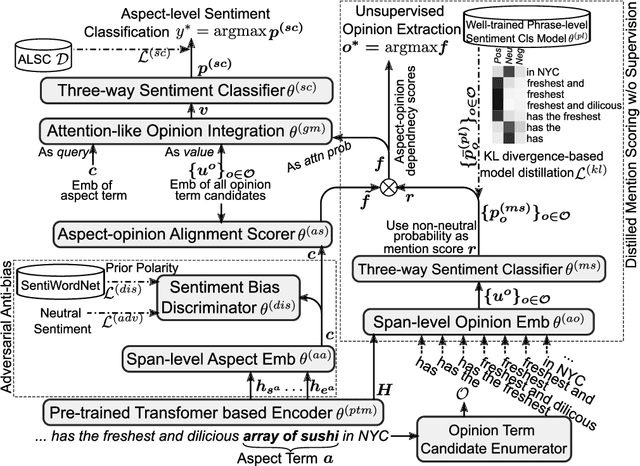
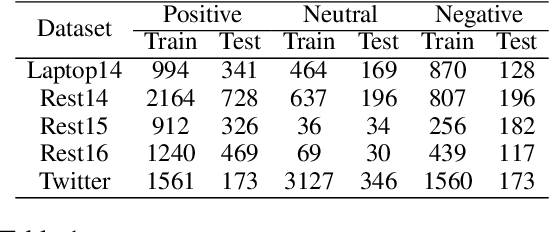

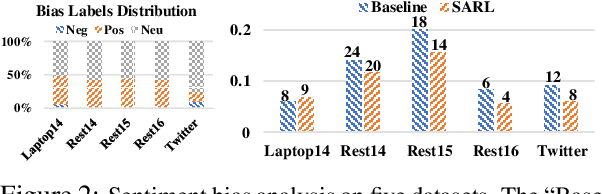
Aspect-level sentiment classification (ALSC) aims at identifying the sentiment polarity of a specified aspect in a sentence. ALSC is a practical setting in aspect-based sentiment analysis due to no opinion term labeling needed, but it fails to interpret why a sentiment polarity is derived for the aspect. To address this problem, recent works fine-tune pre-trained Transformer encoders for ALSC to extract an aspect-centric dependency tree that can locate the opinion words. However, the induced opinion words only provide an intuitive cue far below human-level interpretability. Besides, the pre-trained encoder tends to internalize an aspect's intrinsic sentiment, causing sentiment bias and thus affecting model performance. In this paper, we propose a span-based anti-bias aspect representation learning framework. It first eliminates the sentiment bias in the aspect embedding by adversarial learning against aspects' prior sentiment. Then, it aligns the distilled opinion candidates with the aspect by span-based dependency modeling to highlight the interpretable opinion terms. Our method achieves new state-of-the-art performance on five benchmarks, with the capability of unsupervised opinion extraction.